Antlr4 语法解析生成器(上)
简介
Spark SQL、Presto --> Antlr4 SQL 解析器
Flink SQL --> Apache Calcite(通过JavaCC 实现)
Spark SQL如何进行语法解析:
Spark SQL 最终是转换为RDD调用代码, 然后被Spark Core 执行
Antlr4起的作用就是将SQL语句解析为未解析的逻辑计划
具体流程如下:
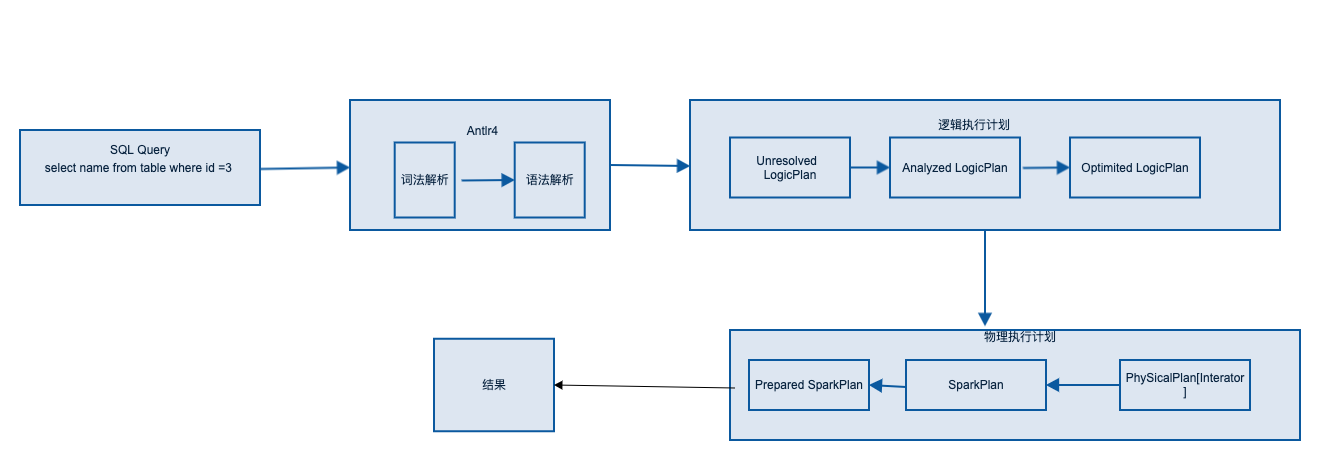
对于语法分析树有两种遍历机制:
- Listener:
我们可以自行实现ParseTreeListener来填充自己的逻辑, 每条规则都对应接口enter () 和exit() 方法
不需要显示遍历访问子节点

- vistors:
显示访问每个子节点, 每条规则对应接口中visit () 方法

Antlr4应用案例
问题: 实现识别包裹在花括号或者嵌套的花括号中的整数 {1,2,3} 和 {1,{2,3}}
实现:
1. 配置Antlr 运行环境
OS X
$ cd /usr/local/lib
$ sudo curl -O https://www.antlr.org/download/antlr-4.7.2-complete.jar
$ export CLASSPATH=".:/usr/local/lib/antlr-4.7.2-complete.jar:$CLASSPATH"
$ alias antlr4='java -jar /usr/local/lib/antlr-4.7.2-complete.jar'
$ alias grun='java org.antlr.v4.gui.TestRig'
- 定义g4 语法文件
/** Grammars always start with a grammar header. This grammar is called
* ArrayInit and must match the filename: ArrayInit.g4
*/
grammar ArrayInit;
/** A rule called init that matches comma-separated values between {...}. */
init : '{' value (',' value)* '}' ; // must match at least one value
/** A value can be either a nested array/struct or a simple integer (INT) */
value : init
| INT
;
// parser rules start with lowercase letters, lexer rules with uppercase
INT : [0-9]+ ; // Define token INT as one or more digits
WS : [ \t\r\n]+ -> skip ; // Define whitespace rule, toss it out
grammars 关键字必须与 .g4 文件同名, 如果一个语法文件太大可以拆分成多个文件,相互依赖就是依赖 import + 关键字 文件名 语句
语法分析器的规则以小写字母开头( init和value)
词法分析器的规则以大小字母开头(INT和WS)
- 执行
antlr4 ArrayInit.g4生成下列文件:
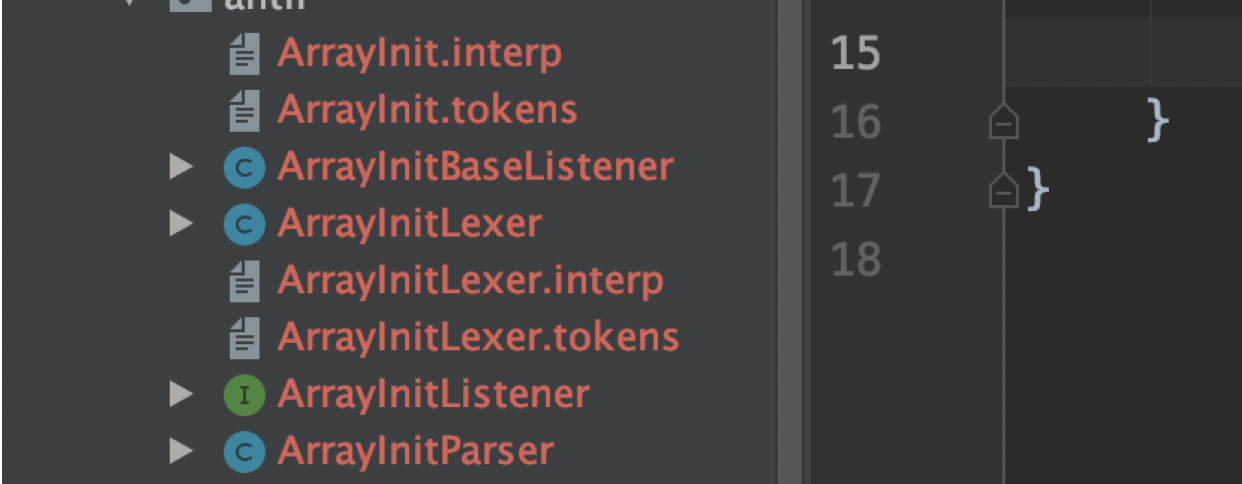
- ArrayInitLexer: 词法解析器类识别我们语法中的文法规则和词法规则
- ArrayInitParser: 语法解析器类
- ArrayInit.tokens: ANTLR会给每个我们定义的词法符号指定一个数字形式的类型
- ArrayInitListener,ArrayInitBaseListener:监听器类
- 我们实现将{1,2,3 } 识别解析成字符串 “123”, 自定义监听器:
class ShortToUnicodeString extends ArrayInitBaseListener{
/**
* {@inheritDoc }
*
* <p>The default implementation does nothing.</p>
*/
override def enterInit(ctx: ArrayInitParser.InitContext): Unit = {
print('"')
}
/**
* {@inheritDoc }
*
* <p>The default implementation does nothing.</p>
*/
override def exitInit(ctx: ArrayInitParser.InitContext): Unit = {
print('"')
}
/**
* {@inheritDoc }
*
* <p>The default implementation does nothing.</p>
*/
override def enterValue(ctx: ArrayInitParser.ValueContext): Unit = {
val value = Integer.valueOf(ctx.INT().getText)
print(value)
}
}
将监听器配置到分析树上面:
object Translate {
def main(args: Array[String]): Unit = {
val input = new ANTLRInputStream("{1,2,3}")
//新建词法分析器
val lexer = new ArrayInitLexer(input)
//新建词法缓冲区,用于存储分析器生成的词法符号
val token = new CommonTokenStream(lexer)
//新建语法分析器用于处理词法缓冲区中的内容
val parser = new ArrayInitParser(token)
//针对规则开始语法分析
val tree = parser.init(); // begin parsing at init rule
val walker = new ParseTreeWalker()
//遍历解析期间创建的树,触发回调
walker.walk(new ShortToUnicodeString, tree)
println()
}
}
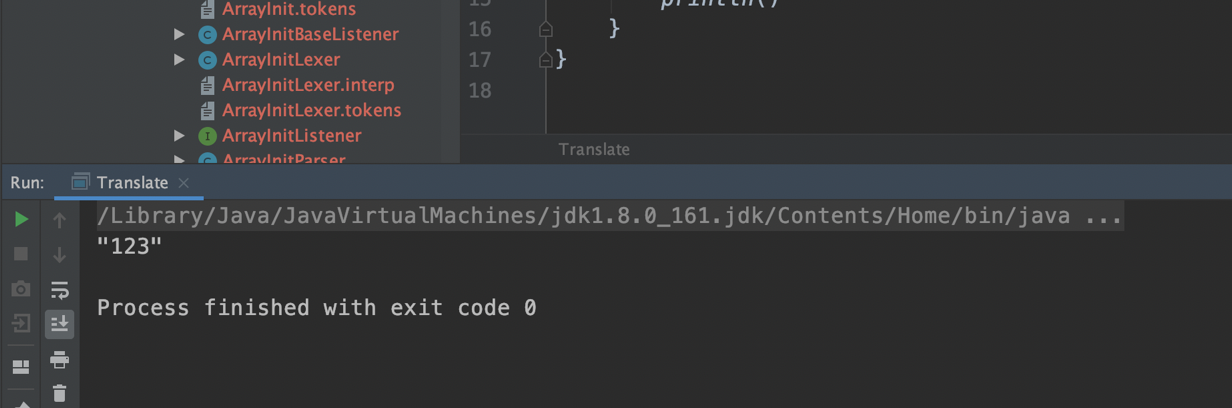
- 执行结果:
总结
本篇主要讲解了Antlr4解析器以及Spark SQL 的解析流程, 介绍了Antlr4抽象树两种遍历机制:listener 和visitor, 同时实现了一个简单的语法通过 Antlr4 listener方式遍历解析的案例.
下篇会介绍visitor 模式的案例以及实现一些语法并且会转换为Spark RDD去执行.
微信公众号

作者:chaplinthink
===> [欢迎赞赏作者, 您的赞赏,是我前进的动力🙂]
出处:https://www.cnblogs.com/bigdata1024/p/14459826.html
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
出处:https://www.cnblogs.com/bigdata1024/p/14459826.html
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
posted on 2021-02-28 17:40 chaplinthink 阅读(1893) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号