分布式爬虫(3)
一、CSS定位器
1.什么是CSS
(1)CSS=Cascading Style Sheets
(2)样式定义如何显示HTML元素
(3)想想为什么不直接使用属性设置元素
(4)CSS与JS
2.CSS基础语法
(1)CSS规则:选择器,以及一条或者多条的声明
selector {declaration1;....;desclarationN}
(2)每条声明由一个属性和一个值组成
property:value
(3)例子
h1{color:red;font-size:14px}
(4)元素选择器
直接选择文档元素
比如head,p
(5)类选择器
元素的class属性,比如<h1 class="important">
类名就是Important
.important选择所有有这个属性的元素
可以结合元素选择器,比如p.important
(6)ID选择器
元素的id属性,比如<h1 id="intro">
id就是intro
#intro用于选择id=intro的元素
可以结合元素选择器,比如p.#intro
与类选择器的异同
ID一个文档只出现一次
ID选择器不能使用单词列表
与类选择器一样,都区分大小写
(7)属性选择器
选择有某个属性的元素,而不论是什么
*[title]选择包含title属性的元素
a[href]选择所有带有href属性的锚元素
还可以选择多个属性,比如:a[href][title],注意这里是要同时满足的
限定值:a[href="www.so.com"]
(8)后代选择器
选择某个元素的后代元素
选择h1元素的em元素:h1 em
(9)子元素选择器
范围限制在子元素
选择h1元素的子元素strong:h1>strong
<h1>
<em>.....</em>
<body>
<em></em>
</body>
</h1>
(9)子代元素选择器
范围限制在子元素
选择h1元素的子元素strong:h1>stong
二、XPath简介
1.什么是Xpath
(1)使用路径表达式在XML文档中进行导航
(2)包含一个标准数据库
(3)是XSLT的主要元素
(4)是一个W3C标准
2.XPath语法
(1)谓语
嵌在[]中用来查找某个特定节点或包含某个特定值的节点
/bookstore/book[1]第一个book元素
/bookstore/book[last()]最后一个book元素
/bookstore/book[position()<3]选择前2个元素
//title[@lang]选择所拥有有名为lang的属性的title元素
/bookstore/book[price>35.00] 条件过滤
(2)七种基本节点
元素、属性、文本
命名空间、处理指令、注释以及根节点
(3)节点之间的关系
父、子、同胞(兄弟)、先辈、后代
(4)路径表达式
nodename选取此节点的所有子节点
/从根节点选取
//从匹配的当前节点选择文档中的节点,而不考虑他们的位置
.选取当前节点
..选取当前节点的父节点
@选取属性
在DOM树,以路径的方式查询节点,通过@符号来选取属性
<a rel="nofollow" class="external text" href="http://google.ac">google<wbr/>.ac</a>
rel class ref 都是属性,都可以通过"//*[@class='external text']"来选取对应元素
=符号要求属性完全匹配,可以用contains方法来部分匹配,例如
"//*[contains(@class,'external')]"可以进行匹配,而"//*[@class='external']"则不能进行匹配
import lxml from lxml import etree s='<a class="hask">Yes</a>' tr=etree.HTML(s) tr.xpath('//a') tr.xpath('//p') tr.xpath('//a')[0] tr.xpath('//a')[0].attrib tr.xpath('//*@class="hask"')[0].attrib
tr.xpath('//*[@class="hask"]')[0].attrib
#
s='<a class="hask" href="http://www.tabobao.com">Yes</a>'
tr=etree.HTML(s)
tr.xpath('//a')[0].attrib #打印出attrib属性,这个地方可以打印出两个属性
一个是连接,另外一个是类属性{'class': 'hask', 'href': 'http://www.taobao.com'}
>>> tr.xpath('//*[@href="http://www.taobao.com"]')[0].attrib
{'class': 'hask', 'href': 'http://www.taobao.com'}
>>> tr.xpath('//*[@href="http://www.taobao.com"]')[0]
<Element a at 0x2cc5108>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learn XML</title>
<price>75</price>
</book>
</bookstore>
(5)运算符
and和or运算符
选择p或者span或者h1标签的元素
soup=tree.xpath('//td[@class="editor bbsDetailContainer"]*[self::p or self::span or self::h1]')
选择class 为editor或者tag的元素,通过or将3中标签全部提取出来
soup=tree.xpath('//td[@class="editor" or @class="tag"]')
3.正则表达式
(1)正则表达式是对字符串操作的一种逻辑公式,就是事先定义好的一些特定字符串、以及这些特定的字符串的组合,组成一个"规律字符串"买这个"规律字符串"用来表达对字符窜的一种过滤逻辑
(2)在爬虫的解析中,经常讲正则表达式与Dom选择器结合使用。正则表达死适用于字符串特征比较明显的情况,但是同样的正则表达式可能在HTML源码里出现多次;而DOM选择器可以通过class一级id来精确找到DOM块,从而缩小查找范围
(3)正则表达式常用规则
\转义字符 例如\?
^字符串起始
$字符串结束
*匹配前面子表达式0次或者多次
+匹配前面子表达式1次或者多次
?匹配前面子表达式0次或者1次
{n,m}至少匹配n次,最多m次
.匹配除\n之外的单个字符串
(pattern)匹配并获取这个匹配,例如匹配ab(cd)e正则表达式只返回cd
[xyz]字符集合,匹配任意集合里的字符,[abc]既能匹配a,也能匹配b,也可以匹配c
[^xyz]排除集合中的字符,不能进行任何的匹配
\d匹配一个数字,等价[0-9]
(4)获取标签下的文本:'<th[^>]*>(.*?)</th>' //[^>]不包含>符号 *表示匹配0-n次 <th href ="....">匹配的限制条件 (.*?)中间这个是我们需要取到的内容
(5)查找特定类别的连接,例如/wiki/不包含Category目录:
'<a href="/wiki"/(?!Category:)[^/>]*>(.*?)<'
(6)
eg:https://item.jd.com/27394669614.html
正则表达式:https://item.jd.com/\d{7}.html \d{7}重复匹配7次数字
(7)查找淘宝的商品信息,'或者"开始及结尾
'href=[\"\']{1}(//detail.taobao.com/item.html[^>\"\'\s]+?)"'
(8)贪婪模式以及非贪婪模式
?该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。
非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式尽可能多的匹配所搜索的字符串
三、Json
1、Json=JavaScript Object Notation
2.类似于XML,但是比XML更小、更快、更易于解析。
3.使用json库处理json,编码与解码
import json obj={'one':1,'two':2,'three':[1,2,3]} encoded=json.dumps(obj) print(encoded)
#
{"one": 1, "two": 2, "three": [1, 2, 3]}#字典不保证元素的顺序的
四、网站结构分析及案例:马蜂窝
1、网站对爬虫的限制

2、利用sitemap来分析网站结构和估算目标网页的规
(1)进入www.mafengwo.cn/robots.txt

(2)进入http://www.mafengwo.cn/sitemapIndex.xml
<sitemap>标签里面包含了所有的文章以及上一次的更新时间
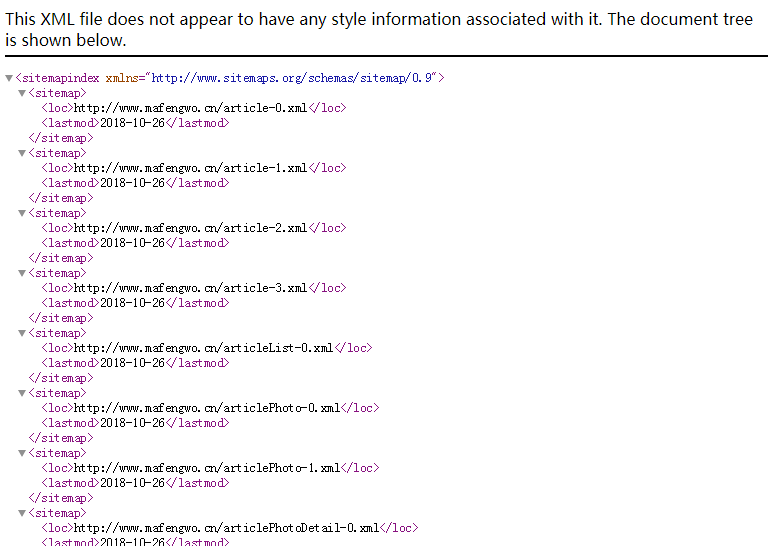
(3)进入http://www.mafengwo.cn/article-0.xml
这里包含每篇文章更新的时间和频率以及优先级
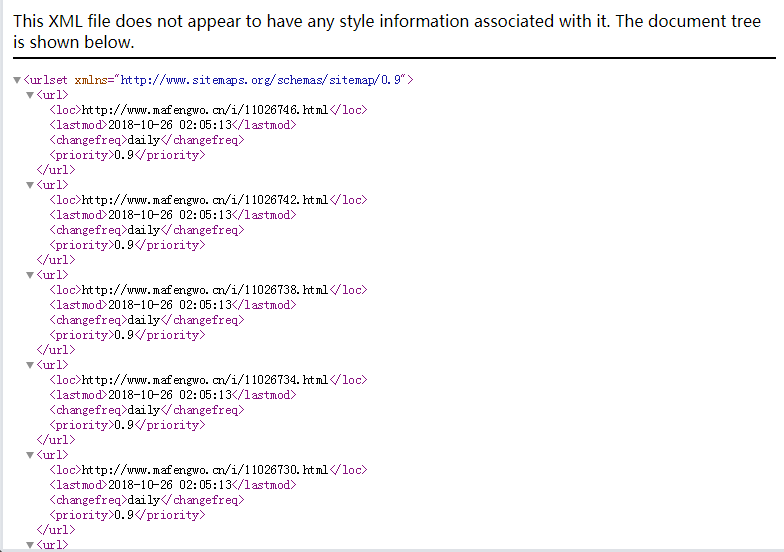
(4)进入http://www.mafengwo.cn/i/11026746.html
<a class="pi" href="/yj/12141/1-0-2.html" title="第2页">2</a>
www.mafengwo.cn/yj/12121/1-0-2.html获取到第二页的页面
(5)有效率抓取特定内容
直接对.html进行抓取
对网站结构进行分析:
大多数网站都会存在明确的top-down的分类目录结构,我们可以进入特定的目录进行抓取。对于www.mafengwo.cn这个网站,所有游记都位于www.mafengwo.cn/mdd下面,按照城市进行了分类,每个城市的游记都位于城市的首页
城市的首页:/travel-scenic-spot/mafengwo/10774.html
游记的分页格式:/yj/10774/1-0-01.html
游记的页面:/i/3522264.html
五、动态网页
1.动态网页的使用场景
(1)单页模式
单页模式是指不需要外部跳转的网页,例如个人设置中心经常就是单页模式
(2)页面交互多的场景
一部分网页上,有很多的用户交互接口,例如去哪儿买机票的选择网页,用户可以反复查询的参数
(3)内容以及模块丰富的网页
有一些的网页内容很丰富,一次加载完成对服务器压力很大,而且这种方式延时也会很差,用户往往也不会查看所有的内容
(4)对于爬虫:简单下载HTML已经不行了,必须要有一个WEB容器来运行HTML的脚本;
增加了爬取的时间;增加了计算机的CPI、内存的资源消耗;增加了爬取的不确定性
(5)对于网站:为了配合搜索引擎的爬取,与搜索相关的信息会采用静态的方式;与搜索无关的信息,例如商品的价格、评论,仍然会采用动态的形式进行加载
2.抓取动态网页---分析:打打开网页后,直接右键点击,只保存HTML
3.Python Web引擎
(1)PyQt PySide:基于QT的python web引擎,需要图形界面的支持,需要安装大量的依赖,安装配置比较=复杂,尤其是安装图形系统,对于服务器来说代价很大
(2)Selenium:一个自动化的Web测试工具,可以支持包括Firefox,chrom,PhatomJS,IE等多种浏览器的安装与测试
(3)PhantonJs:一个机遇Webkit的Headless的web引擎,支持JavaScript。相比于PyQt等方案,phamtoms可以部署在没有UI的服务器上
(4)PhantomJS+Selenium网页自动化的测试。
(5)Selenium安装:pip install selenium
(6)PhantomJS安装:
先安装nodejs yum install nodejs
为了加速,将NPM的源改为国内的淘宝
$npm install -g cnpm --registry=https://registry.npm.taobao.org
利用NPM的Package Manager安装 phantomjs
$npm -g install phantomjs-prebuilt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号