spark复习笔记(2)
之前工作的时候经常用,隔了段时间,现在学校要用学的东西也忘了,翻翻书谢谢博客吧。
1.什么是spark?
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
2为什么要学Spark
Spark是一个开源的类似于Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Spark中的Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
3 Spark特点
1) 快
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。

2)易用
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。

3)通用
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
4)兼容性
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。

4.spark安装
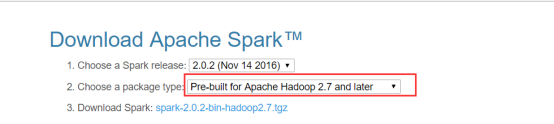
1)下载spark安装包
下载地址spark官网:http://spark.apache.org/downloads.html这里我们使用 spark-2.0.2-bin-hadoop2.7版本.
2)解压安装包
tar -zxvf spark-2.0.2-bin-hadoop2.7.tgz -C /soft
3)创建软连接
ln -s spark-2.0.2-bin-hadoop2.7.tgz spark
4)修改配置文件
(1)配置文件目录在/soft/spark/conf
nano spark-env.sh 修改文件(先把spark-env.sh.template重命名为spark-env.sh)
(2)配置spark环境变量
#指定spark老大Master的IP
export SPARK_MASTER_HOST=s201
#指定spark老大Master的端口
export SPARK_MASTER_PORT=7077
(2)nano slaves文件
先把slaves.template重命名为slaves
(3)将spark分发到其他主机
s201:8080
5)配置spark环境变量
export SPARK_HOME=/opt/bigdata/spark
export PATH=$PATH:$SPARK_HOME/bin
将spark添加到环境变量,添加以下内容到 /etc/profile
注意最后 source /etc/profile 刷新配置
6)启动spark集群
start-all.sh
7)停止spark集群
stop-all.sh
8)验证是否成功
5.体验spark
1)进入spark-shell
$>spark-shell
$scala>
2)API
(1)[SparkContext]
Spark程序的入口点,封装了整个spark程序的运行环境信息

即sc:这是spark应用上下文即sparkContext对象,spark程序的的入口点,封装spark运行环境信息。通过sc.+Tab键可以得到如下方法

(2)RDD resilient distributed dataset 弹性分布式数据集,等价于集合。
3)通过spark实现word count
(1)加载文件:val rdd1 = sc.textFile("/home/centos/test.txt"),将文件加载进入内存中
sc.textFile:def 加载之后将其转换成数组 textFile(path:String,minPartitions:Int):org.apache.spark.rdd.RDD(String)
(2)按照空格进行切割。压扁操作
val rdd2 =rdd1.map(line=>line.split(" "))
就是对第一步集合进行处理,把没一行的元素进行切割,切开之后每个元素仍然是一个数组,现在切开之后就变成了数组的集合了。
(3)在进行单词统计的时候需要在后面标1,变成一个key-value键值对的形式
flatmap()函数只能是从集合元素到map的形式
val rdd3 = flatMap(line=>line.split(" "));//压扁操作
(4)map(word=>(word,1)) //变换成对偶(k,v),将单词变换成对偶,也就是映射
(5)聚合:reduceByKey(_ + _)
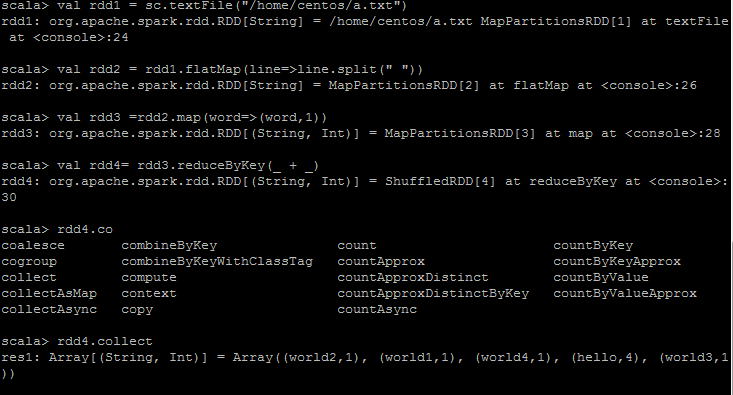
一句话写完spark


 浙公网安备 33010602011771号
浙公网安备 33010602011771号