分布式爬虫(1)
一、环境搭建
1.python 2.7
2.pip ,并设置pip源
(1)配置pip conf ,自动设置源
#mkdir ~/.pip
#vim ~/.pip/pip.conf
[gloabal]
index-url=https://pypi.tuna.tsinghua.edu.cn/simple
也可以每次安装的时候制定source
#pip install -i https://pypi.tuna.tsinghua.edu.cn.simple lxml
二、Http协议
1.OSI协议 TCP/IP协议
应用层
应用层 表示层
会话层
传输层 传输层
互联网络层 网络层
网络接口层 数据链路层
物理层
2.OSI模型
(1)物理层:电器连接
(2)数据链路层:交换机、STP、帧中继
(3)网络层:路由器、ip协议
(4)传输层:TCP、UDP协议
(5)会话层:建立通信连接,网络拨号
(6)表示层:每次连接只处理一个请求
(7)应用层:HTTP、FTP
3.HTTP协议:
(1)应用层协议;
(2)无连接:每次连接只处理一个请求
(3)无状态:每次连接传输都是独立的
4.HTTP HEADER
(1)REQUEST部分的HTTP HEADER
Accept:text/plain
Accept-Charset:utf-8
Accept-Encoding:gzip,deflate
Accept-Language:en-US
Connection:keep-alive
Content-length:348
Content-Typte:applicaltion/x-www-from-urlencoded
Date:Tue,15 Nov 1994 08:12:31 GMT
Host:en wikipedia.org:80
User-Agent:Mozilla/5.0(X11;Linux x86_64;rv:12.0)Gecko/20100101
firefox/21,0
cookie:$Version=1;Skin=new;
5.keep-alive
(1)http是一个请求<->响应模式的典型范例,即客户端向服务器发送一个请求信息,服务器来响应这个信息。在老的HTTP版本中,每个请求都被创建一个新的客户端->服务器的连接,在这个连接上发送请求,然后接受请求。这样的模式有一个很大的优点,他很简单,很容易理解和通过编程来实现;有个很大的缺点就是效率比较低,因此keep-alive被提出来解决效率低的问题。
(2)keep-alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后续请求的时候,keep-alive功能避免了建立或者重新建立连接
HTTP/1.1
默认情况下所在的HTTP1.1中所有的连接都被保持,除非在请求头或者响应头中指明要关闭:Connection:Close
RESPONSE的HTTP HEADER
Accept-Patch:text/example;charset=utf-8 Cache-COntrol:max-age=3600 Content-Encoding:gzip Last-Modified:Tue,15 Nov 1994 12:45:26 GMT Content-Language:da Content-Length:348 ETag:"737060cd8c284d8af7ad3082f209582d" Expires:Thu,01 Dec 1994 16:00:00 GMT Location:http://www.w3.org/pub/WWW/People.html Set-Cookie:UserID=JohnDoe;Max-Age=3600;Version=1 Status:200 OK
6.http响应状态码
2XX 成功
3XX 跳转
4xx 客户端错误
500 服务器错误
7.HTPP响应状态码400/500
400 Bad Request客户端请求有语法错误,不能被服务器所理解
401 Unauthorized请求未经授权,这个状态码必须和WWW-Authenticate报头一起使用
403Forbidden 服务器收到请求,但是拒绝提供服务
如果是需要登录的网站,尝试重新登录
IP被封,暂停爬取,并增加爬虫的时间,如果拨号网络,尝试重新联网更新IP
404 Not Found 请求资源不存在,eg:输入错误的URL
500 Internal Server Error服务器发生了不可预期的错误
503Server Unavailable 服务器当前不能处理客户端的请求,一段时间后可能恢复正常
5XX服务器错误,直接丢弃并计数,如果连续不成功,WARNING并停止爬取
8.网页抓取的原理
(1)宽度优先策略
(2)深度优先策略
9.选择哪种策略?
(1)重要的网页离种子站比较近
(2)万维网的深度并没有很深,一个网页有很多路径可以到达
(3)宽度优先利于多爬虫并行合作抓取
(4)深度优先于宽度优先相结合
10.不重复抓取策略
1)如何记录抓取历史?
(1)将访问过的URL保存到数据库(这样效率太低)
(2)用HashSet将访问过的URL保存起来。那只需要接近O(1)的代价就可以查询到一个URL是否被查询过 内存消耗
(3)URL经过MD5或者SHA-1等单向哈希后再保存到HashSet或者数据库
(4)Bit-Map方法。建立一个BitSet,将每一个URL经过一个哈希函数映射到某一位
2)MD5函数抓取算法
MD5签名是一个哈希函数,可以将任意长度的数据量抓换为一个固定长度的数字(通常是4个整形,128位)。计算机不可能有2的128次方那么大的内存,因此实际的哈希表都会是URL.MD5再%n(就是取模)。现实世界URL的组合必然会超过哈希表的槽位数,因此碰撞时一定存在的,一般的HASH函数,如Java的HashTable一个哈希表再跟一个链表,链表存的是碰撞的结果。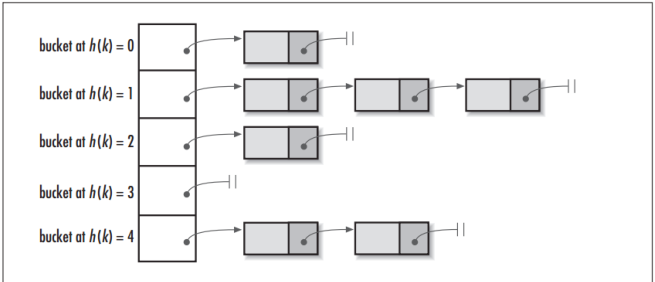
3)使BITMAP的方式来进行记录
将URL的MD5值再次进行哈希,用一个或者多个BIT位来记录一个URL
(1)确定空间的大小
(2按倍增加槽位
(3)HASH算法映射(murmurhash3,cityhash) Python:mmh3 bitarray
(4)碰撞概率增加
4)Bloom Filter:Bloom Filter使用了多个哈希函数,而不是一个。创建一个m位的BitSet,先讲所有的位初始化为0,然后选择K个不同的哈希函数。第i个哈希函数对字符串str哈希的记过为h(i,str),而且h(i,str)的范围是0到m-1,只能进行插图不能删除。用到多个比特位就降低了碰撞概率
这个方法主要是通过3个哈稀器算出三个哈希函数,如果三个哈希函数全部被置为1了,那么我们就认为这个网页已经存在了,如果只要有一个位没有置为1,那就认为不存在
11.提高存储的效率
(1)提高网站的网页数量
(2)选择合适的HASH算法和空间阈值,降低碰撞几率
(3)选择合适的存储结构和算法
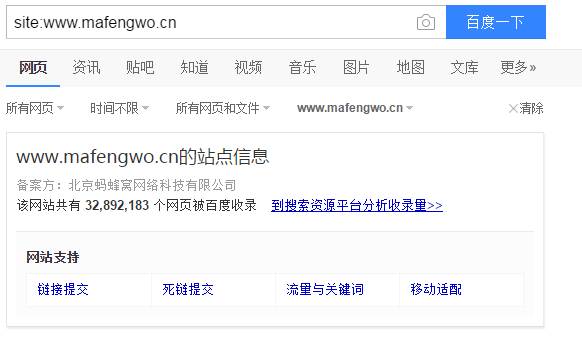
12.评估网页数量
site:www.mafengwo.cn
三、爬虫实战
1.有效抓取特定内容
1)查看Robots.txt,放在根目录下面
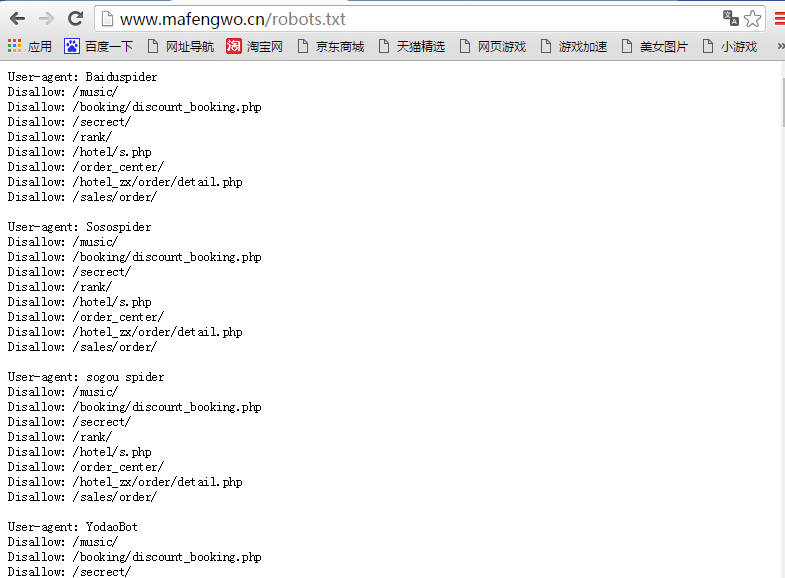
2)利用sitemap里的信息,直接对目标网页.html进行抓取
3)对网站结构进行分析
大多数网站会有明确的top-down的分类目录结构,我们可以进入特定的目录进行抓取
对于www.mafengwo.cn这个网站,所有的旅游的游记都位于www.mafebgwo.cn/mdd下面,按照城市进行分类,每个城市的游记都位于城市的首页。
城市的首页:/travel-scenic-spot/mafengwo/10774.html
游记的分页格式:/yj/10774/1-0-01.html
游记的页面:/i/3523364.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号