kafka复习(2)
一、简介
---------------------------------------
1.kafka是一个分布式的、可分区的、可复制的消息系统。它提供了消息系统的功能,但是有自己独特的设计。
2.名词解释:
(1)topic:kafka将罅隙以topic为单位
(2)producer:向kafka发送消息的程序
(3)consumer:将预定topics并消费的程序
(4)broker:kafka以集群的形式来运行,可以由一个或者多个服务组成,每个服务叫做一个broker
3.producer通过网络将消息发送到kafka集群,集群向消费者提供消息,如下图所示:
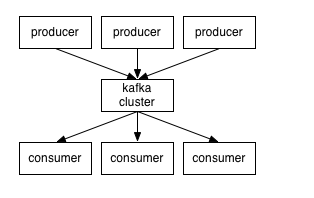
客户端和服务端通过TCP通信。Kafka提供了java客户端,并提供了多种语言的支持
4.Topics和Logs:kafka提供了一个抽象的概念:topic
一个topic是对一组消息的归纳。对每个topic,kafka对他的日志尽行了分区,如下图所示:
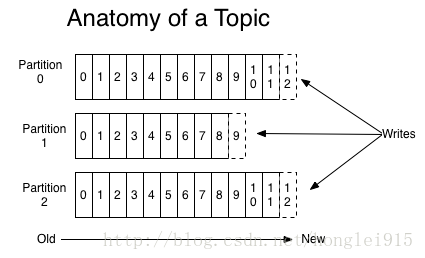
(1)每个分区都由一系列有序的、不可变的消息组成,这些消息被连续追加到分区中。分区中的每个消息都有一个连续的序列号叫做offset,用来在分区中唯一标识这个消息。
(2)在一个可以配置的时间内,kafka集群保留所有发布的消息,不管这些消息有没有被消费。比如消息的保存策略设置为2天,那么在一个消息发布的两天的时间内,他都是可以被消费的,如果没有被消费,就会保留在分区中。之后将会被丢弃来释放空间。Kafka的性能是和性能无关的常量级的,所以保留太多的数据不是问题。
(3)实际上每个consumer需要唯一维护的数据是消息在日志中的位置,也就是offset,这个offset由consumer来进行相应的维护:一般情况下随着consumer不断的读取消息,这个offset的值会不断增加,但是consumer可以任意顺序读取消息,比如可以将offset设置为一个旧的值来重读之前的消息。
(4)以上特点的结合,使得kafka consumer是一个非常的轻量级:他们可以在不对集群和其他consumer造成影响的情况下读取消息。可以使用命令行来tail消息而不会对其他正在消费的消息的consumer造成影响。
(5)日志分区可以达到以下目的:首先使得每个日志数量不会太大,可以在单个服务商保存。每个分区可以单独发布和消费,并未发布操作topic提供了一种坑能。
6.分布式
每一个分区在kafka集群的若干服务中都有副本,这样持有副本的服务可以共同处理数据和请求,副本数量是可以配置的。副本使得kafka具备了容错的能力。每个分区都由一个容器作为leader,0或者若干服务器作为flower,leader负责处理消息的读和写,flowers则则去复制leader,如果follower down了,flower中的一台会自动成为leader。集群中的每个服务器都会扮演两个角色:作为他所持有一部分分区的leader,其他分区的flowers,这样的集群就有比较哈ode均衡负载了。
7.Producers:
将消息发送到他所指定的topic中,并负责决定发布到哪个分区。通常由简单的负载均衡机制来选择分区,但是也可以通过特定的分区函数来选择哪个分区 。而我们通常使用更多的是第二种。
8.Consumers
----------------------------------------
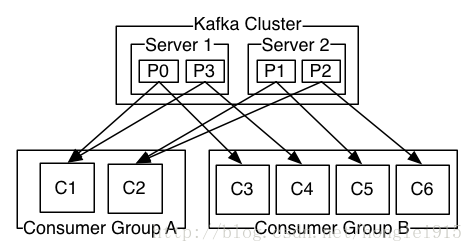
(1)发布消息的两种模式:
队列模式(queuing)和发布-订阅模式(publish-subscribe)。在队列模式中,consumer可以同时从服务器端读取消息,每个消息只被其中的一个consumer读取到;
发布-订阅模式消息:消息被广播到所有的所有的consumer中,consumers可以加入其中一个consumer组,共同竞争一个topic,topic中的消息将被分发到组中的一个成员。同一个组中的consumer可以在不同的程序中,也可以在不同的机器上面。如果所有的consumer在同一个组中,那就成为了传统的队列模式,在各个consumer中实现负载均衡。如果所有的consumer都在不同的组中,这就成为了发布-订阅模式,所有的消息都被发送到所有的consumer中,更加常见的是,每个topic都有若干数量的consumer组,每个组都是一个逻辑上的"订阅者",为了容错和更好的稳定性,每个组有若干consumer组成,这其实就是一种发布-订阅模式,只不过订阅者是个组而不是单个的consumer。
由两个机器组成的集群有4个分区(p0-p3)以及两个consumer组。A组有2个consumer,B组有4个consumer。
相比于传统的消息系统,kafka可以很好的保证有序性:传统的队列在服务器上保存有序的消息,如果有多个consumers同时从这个服务器上消费消息,那么服务器就会以消息存储的顺序向consumer分发消息。虽然服务器按顺序发布消息,但是消息被异步的分发到各个consumers上,所以当消息到达的时候可能已经失去了原来的顺序,这意味着并发消息将会导致顺序发生错乱。为了避免故障,这样的消息系统通常会使用"专用consumer"的概念,其实就是只允许一个消费者消费消息,当然这也意味着失去了消息的并发性。
在这方面kafka做的更好,通过分区的概念,Kafka可以在多个consumer组并发的情况下提供较好的有序性和负载均衡。因为有多个分区,依然可以在多个consumer组之间进行负载均衡。这个地方要注意:consumer组的数量不能多于分区的数量,也就是有多少分区就会有躲闪的并发消费者。
kafka只能保证在一个分区之内的消息有序性,在不同的分区之间是不可以的,这已经可以满足大部分的应用需求,如果需要topic中所有消息的有序性,那就只能让这个topic只有一个分区,当然只有一个consumer来消费它。
二、环境的搭建
-----------------------------------------------
1.下载kafka
tar -xzf kafka_2.9.2-0.8.1.1.tgz cd kafka_2.9.2-0.8.1.1
2.启动服务:kafka用到了zookeeper,所有首先要启动zookeeper,下面简单的启动一个zookeeper服务。可以在命令的结尾加上一个&符号,这样就可以在启动后离开控制台。
>bin/zookeeper-server-start.sh config/zookeeper.properties &
3.启动kafka
bin/kafka-server-start.sh config/server.properties [2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties) [2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties) ...
3.创建topic:创建一个叫做"test"的topic,只有一个分区,一个副本
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
删除主题:
bin/kafka-topics.sh --zookeeper s202:2181 --delete --topic test
kafka容错演示:
4.通过list命令查看创建的topic:
bin/kafka-topics.sh --list --zookeeper localhost:2181 //除了手动创建topic,还可以配置broker让它自动创建topic.
bin/kafka-topics.sh --zookeeper s202:2181 --replication-factor 2 --partitions 5 --create --topic test2 //创建主题,指定主题个数和分区数
5.发送消息.:Kafka 使用一个简单的命令行producer,从文件中或者从标准输入中读取消息并发送到服务端。默认的每条命令将发送一条消息。kafka生产者不会连接到zk集群上去
运行producer并在控制台中输一些消息,这些消息将被发送到服务端:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
6.启动consumer:Kafka也有一个命令行consumer可以读取消息并输出到标准输出
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topictest--from-beginning你在一个终端中运行consumer命令行,另一个终端中运行producer命令行,就可以在一个终端输入消息,另一个终端读取消息。这两个命令都有自己的可选参数,可以在运行的时候不加任何参数可以看到帮助信息。
7.搭建一个多个broker的集群。刚才只是启动了单个broker,现在启动有3个broker组成的集群,这些broker节点也都是在本机上的:首先为每个节点编写配置文件:
cp config/server.properties config/server-1.properties > cp config/server.properties config/server-2.properties
在拷贝出的新文件中添加以下参数:
config/server-1.properties: broker.id=1 port=9093 log.dir=/tmp/kafka-logs-1
config/server-2.properties: broker.id=2 port=9094 log.dir=/tmp/kafka-logs-2
broker.id在集群中唯一的标注一个节点,因为在同一个机器上,所以必须制定不同的端口和日志文件,避免数据被覆盖。
We already have Zookeeper and our single node started, so we just need to start the two new nodes:
刚才已经启动可Zookeeper和一个节点,现在启动另外两个节点:
bin/kafka-server-start.sh config/server-1.properties & ... > bin/kafka-server-start.sh config/server-2.properties &
8.现在我们搭建了一个集群,怎么知道每个节点的信息呢?运行“"describe topics”命令就可以了:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
下面解释一下这些输出。第一行是对所有分区的一个描述,然后每个分区都会对应一行,因为我们只有一个分区所以下面就只加了一行。
leader:负责处理消息的读和写,leader是从所有节点中随机选择的.
replicas:列出了所有的副本节点,不管节点是否在服务中.
isr:是正在服务中的节点.
在我们的例子中,节点1是作为leader运行。
向topic发送消息:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
my test message 1my test message 2^C

 浙公网安备 33010602011771号
浙公网安备 33010602011771号