hive面试题(免费拿走不谢)
Hive 最常见的几个面试题
1.hive 的使用, 内外部表的区别,分区作用, UDF 和 Hive 优化
(1)hive 使用:仓库、工具
(2)hive 内部表:加载数据到 hive 所在的 hdfs 目录,删除时,元数据和数据文件都删除
外部表:不加载数据到 hive 所在的 hdfs 目录,删除时,只删除表结构。
(3)分区作用:防止数据倾斜
(4)UDF 函数:用户自定义的函数 (主要解决格式,计算问题 ),需要继承 UDF 类
java 代码实现
class TestUDFHive extends UDF {
public String evalute(String str){
try{
return "hello"+str
}catch(Exception e){
return str+"error"
}
}
}
(5)sort by和order by之间的区别?
使用order by会引发全局排序;
select * from baidu_click order by click desc;
使用 distribute和sort进行分组排序
select * from baidu_click distribute by product_line sort by click desc;
distribute by + sort by就是该替代方案,被distribute by设定的字段为KEY,数据会被HASH分发到不同的reducer机器上,然后sort by会对同一个reducer机器上的每组数据进行局部排序。
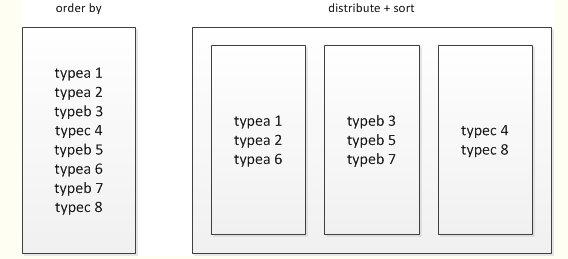
sort by的排序发生在每个reduce里,order by和sort by之间的不同点是前者保证在全局进行排序,而后者仅保证在每个reduce内排序,如果有超过1个reduce,sort by可能有部分结果有序。
注意:它也许是混乱的作为单独列排序对于sort by和cluster by。不同点在于cluster by的分区列和sort by有多重reduce,reduce内的分区数据时一致的。
(6)Hive 优化:看做 mapreduce 处理
排序优化: sort by 效率高于 order by。分区:使用静态分区 (statu_date="20160516",location="beijin") ,每个分区对应 hdfs 上的一个目录,减少 job 和 task 数量:使用表链接操作,解决 groupby 数据倾斜问题:设置hive.groupby.skewindata=true ,那么 hive 会自动负载均衡,小文件合并成大文件:表连接操作,使用 UDF 或 UDAF 函数:
面试题有点多,过几天再来更新

 浙公网安备 33010602011771号
浙公网安备 33010602011771号