flume复习(二)
一、简介:flume是一种分布式、可靠且可用的系统,能够用于有效的从不同的源收集、聚合和移动大量的日志数据到集中式数据存储。它具有基于流数据的简单灵活的架构,它具有健壮的可靠性机制和许多故障转移和恢复机制,具有强大的容错性,使用简单的可扩展的数据模型,允许在线分析的应用程序。flume不仅能用于日志数据的收集。由于数据源是可以指定的,因此flume可用于传输大量事件数据,包括但是不限于网络流量数据,社交媒体生成的数据,电子邮件消息以及几乎任何可能的数据源
1.flume运行的核心是Agent。是以agent为最小的独立运行的单位,一个agent是一个JVM,是一个完整的数据收集工具,含有三个核心的组件,分别是source、channel、sink,通过这三个组件,Event可以从一个地方流向另外一个地方。架构图如下:
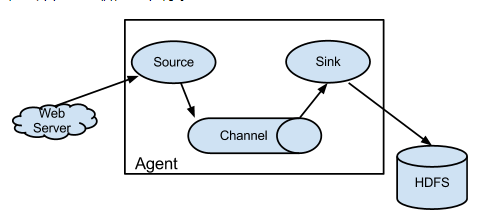
2.flume event:一个flume事件被定义为一个具有字节有效负载和可选字符串属性集的数据流单元。一个Flume agent是一个进程,承载事件从外部源流向下一个目标(跃点)的组件。即一个数据单元【由消息头和消息和消息体组成】
3.Source:是Agent的一个组件, 从数据生成器接收数据,然后将数据以flume事件的形式传递到一个或多个channel中
4.Chennel:是一个临时缓冲区,从source接收flume events(flume事件),并且缓冲它们直到它们被sink消费。在源和sink之间扮演桥梁的角色。这些channel是完全事务性的,可以跟许多source和sink协同。如JDBC通道、文件系统通道、内存通道等等。
5.Sink:存放数据到中央化存储,如HBase或者HDFS,它从channel中消费数据(event)并且将其传递到目的地,sink的目的地可能是另外一个sink或者一个中央化存储。.
6.agent:是一个独立的Flume进程,包含组件Source,Channel,Sink。(Agent使用JVM运行Flume),每台机器上运行一个agent,但是一个agent中包含多个sources和sinks。
7.复杂的流程。flume允许用户构建多跳流,其中事件在达到目的地之前经过多个代理。它还允许扇入和扇出流,上下文路由和故障跳跃备份路由。
8.可靠性。事件在每个代理(agent)的通道中进行,然后数据流中的事件传递到下一个代理(agent)或者终端存储库(如HDFS)。只有将数据存储到下一个代理(agent)的通道或者终端存储库中后,才会从通道中删除这些事件。这就是flume中的单跳消息传递语义如何提供的端到端的可靠性。flume使用事务的方法来保证事件传递的可靠性。source和sink分别在事务中封装由信道提供的事务中防止或提供的时间的存储或者检索。这可以确保事件集在流中一个点到另一个点的可靠的传输。在多跳流的情况下,来自前一跳的接收器(sink)和来自后一跳的源(source)都运行其事务以确保数据安全存储在下一条的channel中。
9.可恢复性。事件在通道中进行,该通道处理故障恢复。Flume支持由本地文件系统支持的持久文件通道。还有一个内存通道(channel),他只是将事件出处在内存的队列中,这很快。但是当进代理程死亡的时候,仍然留在内存通道这种的任何事件都无法恢复。
二、配置。
1.agent配置
flume agent的配置是存储在本地文件找中的。这是一个遵循java属性文件格式的文本文件。对于一个或者多个代理的配置可以在同一个配置文件中指定,配置文件包括在一个agent中的每一个source,sink和channel的属性,以及他们如何连接在一起形成数据流。
2.配置单个的组件。数据流中的每个组件(source,sink或者channel)都有一个特定类型和实例化名称的名字、类型和一系列的属性。比如avro source需要一个主机名(或者ip地址)以及一个端口号来接收数据。一个内存通道可以由最大的队列大小(容量),一个hdfs sink需要知道需要创建的文件系统的uri和路径,文件轮换频率等。组件的所有此类属性需要在托管flume代理的属性文件中设置。
3.将各个部分连接在一起
agent需要知道加载哪些组件以及他们如何构成流程。这是通过列出agent中的每个source,source和channel的名称,然后为每个sink和source来指定channel来完成的。
4.启动代理
使用名为flume-ng的shell脚本启动代理程序,该脚本位于Flume发行版的bin目录中。您需要在命令行上指定代理名称,config目录和配置文件:
使用名为flume-ng的shell脚本启动代理程序,该脚本位于Flume发型版本的bin目录中。需要制定代理的名称、config目录和配置文件。
bin/flume-ng agent -n $ agent_name -c conf -f conf/flume-config.properties.template
5.配置示例
(1)单点Flume部署,允许用户生成时间,然后将其记录到控制台
#命名此代理上的组件 a1.sources = r1 a1.sinks=k1 a1.channels = c1 #描述配置源 a1.sources.r1.type=netcat a1.sources.r1.bind =localhost a1.sources.r1.port=44444 #描述接收器sink,将收到的数据存储在日志中 a1.sinks.k1.type=logger #使用缓冲内存中时间的通道,缓存的channel是内存 a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #将内源和接收容器绑定到通道,将source和channel进行绑定,将sink和channel进行绑定 a1.sources.r1.channels=c1 a1.sinks.k1.channel=c1
上面的配置中定义了一个a1的agent,a1有一个侦听端口44444,侦听这个端口上数据的源,一个缓冲内存中事件数据的channel,以及将事件记录到控制台的sink。配置文件命名各种组件,然后描述他们的类型是配置参数,一个给定的配置文件可能命名多个agent,当一个给定的flume金春哥启动的时候,会传递一个标志,告诉它要现实哪个命名代理。
基于上述的配置文件,我们可以用下面的方式来启动Flume:
$ bin / flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger = INFO,console
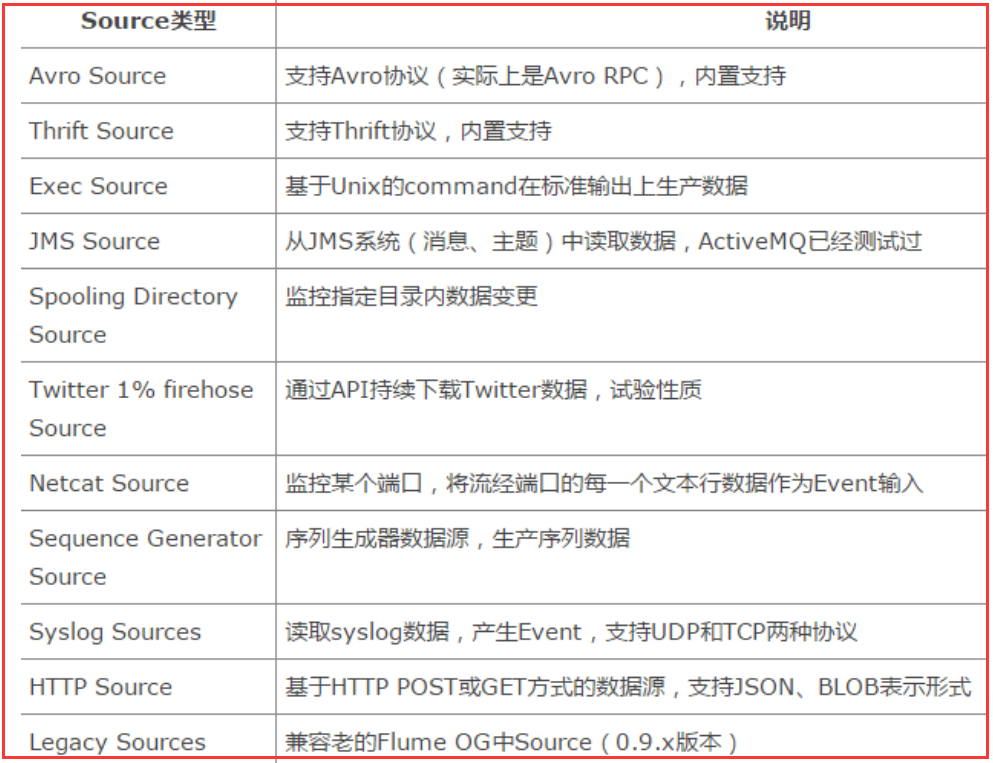
三、flume source:数据的收集端,复制将数据捕获后进行特殊的格式化,将数据封装到事件中,然后将事件推入Channel中。Flume提供了很多内置的source,支持Avro,log4j,syslog和http post(body为json格式)。可以让应用程序同已有的Source直接打交道,如AvroSource,SyslogTcpSource。 如果内置的Source无法满足需要, Flume还支持自定义Source。
 四、Chinanel
四、Chinanel
1.Channel是连接Source和Sink的组件,可以将它看做一个缓冲区(数据队列),可以将事件暂时存放到内存中,也可以持久化到本地磁盘上,直到sink处理完该事件。常用的两个Chnnel有MemoryChannel和FileChannel
2.Channel的类型

五、Sink
1.Sink从Channel中取出事件,然后将数据发到别处,可以将数据发到文件系统、数据库、HDFS,也可以发到其他agent的source中。在日志数量比较少的时候,可以将数据存储在文件系统中,并且设定一定时间间隔保存数据。
2.数据的类型

六、flume拦截器、数据流以及可靠性
1.flume拦截器:当我们对数据进行过滤的时候,除了在source、Channel和sink进行代码的修改之外,Flume为我们提供了拦截器,拦截器也是chain的形式。拦截器位于source和channel之间,当我们为souce指定拦截器之后,我们在拦截器中会得到event,根据需要我们对evnet进行保留还是抛弃,抛弃的event不会进入Channel中。

2.Flume数据流
(1)Flume的核心是把数据从数据源收集过来,然后送到目的地。为了保障输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地之后,再删除自己缓存的数据
(2)Flume传输数据的基本单位是Event,如果是文本文件,通常是一行记录,这也是事务的基本单位,Event是从source流向Channel再到Sink
(3)b本身为一个byte数组,并且可以携带headers信息。Event代表着一个数据的最小的完整单元,从外部数据源来,向外部目的地去。
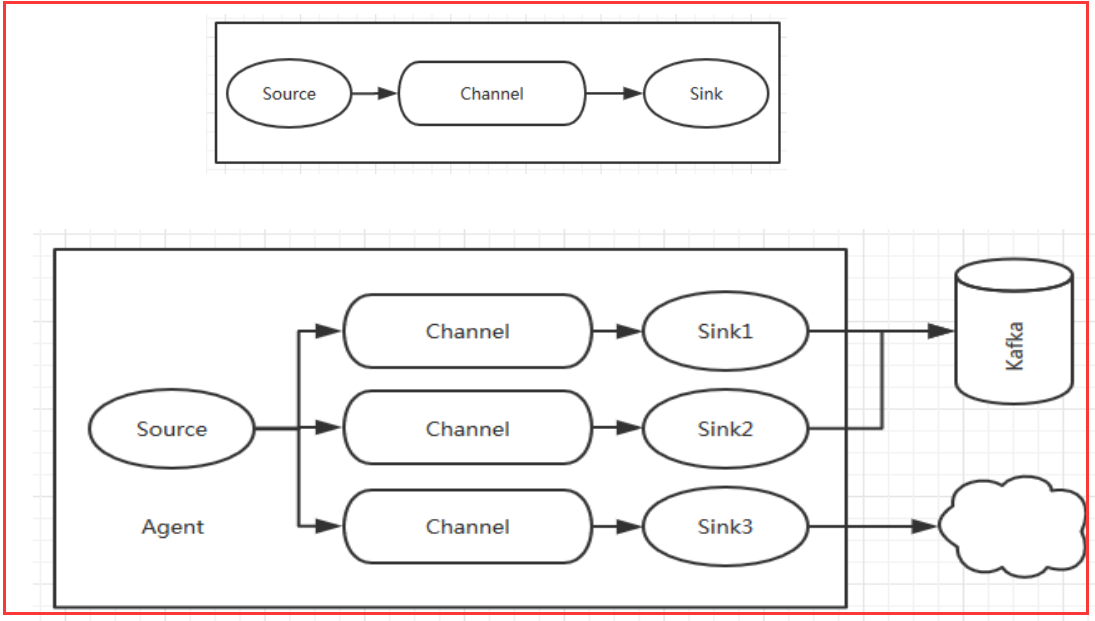
值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。
比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,
也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes,这也正是Flume强大之处。如下图所示:
七、Flume使用场景
1.多个agent顺序连接

可以将多个Agent顺序连接起来,将最初的数据源经过收集,存储到最终的存储系统中。这是最简单的情况,一般情况下,应该控制这种顺序连接的
Agent 的数量,因为数据流经的路径变长了,如果不考虑failover的话,出现故障将影响整个Flow上的Agent收集服务。
2.多个agent的数据汇聚到一个Agent上
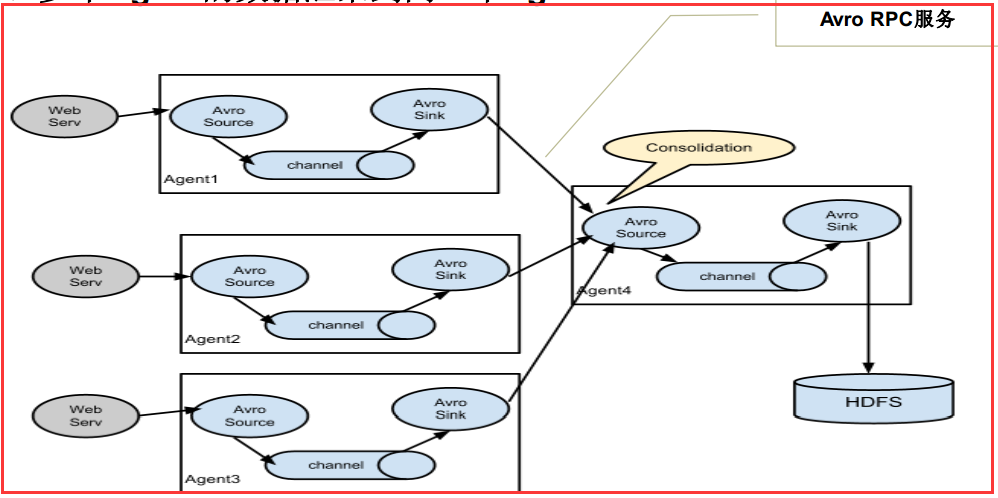
这种情况应用的场景比较多,比如要收集Web网站的用户行为日志, Web网站为了可用性使用的负载集群模式,每个节点都产生用户行为日志,可以为
每 个节点都配置一个Agent来单独收集日志数据,然后多个Agent将数据最终汇聚到一个用来存储数据存储系统,如HDFS上。
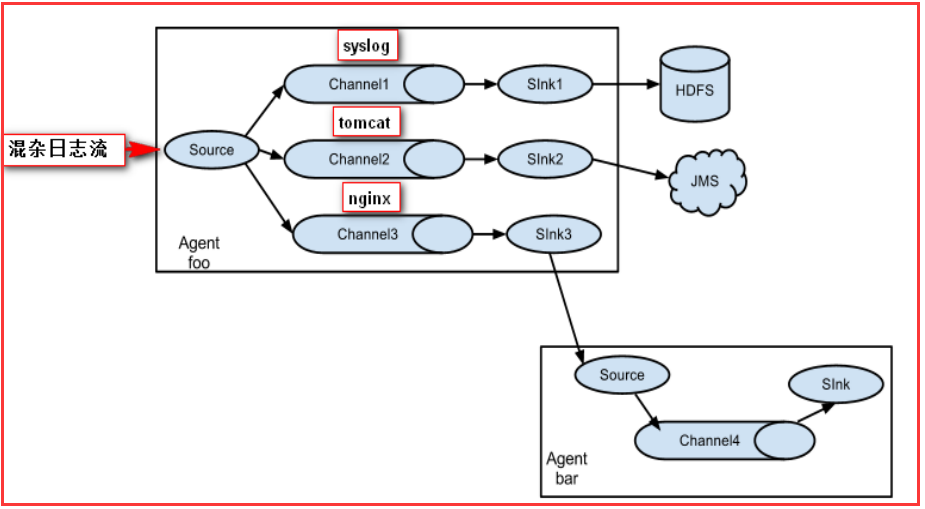
3.多级流
Flume还支持多级流,什么多级流?结合在云开发中的应用来举个例子,当syslog, java, nginx、 tomcat等混合在一起的日志流开始流入一个agent
后,可以agent中将混杂的日志流分开,然后给每种日志建立一个自己的传输通道。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号