机器学习之信息熵
1.
(1)熵的概念的引入,首先在热力学中,用来表述热力学第二定律。由玻尔兹曼研究得到,热力学熵与微 观状态数目的对数之间存在联系,公式如下:
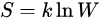
信息熵的定义与热力学熵的定义虽然不是一个东西,但是有一定的联系,熵在信息论中表示随机变量不确定度的度量。一个离散随机变量X与熵H(X)的定义为:
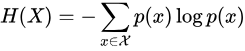
(2)为了便于理解,举个例子:直觉上,信息量等于传输该信息所用的代价,这个也是通信中考虑最多的问题。比如说:在赌马比赛中,有4匹马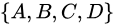 ,获胜的概率分别为:
,获胜的概率分别为: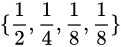 。
。
接下来,让我们将哪一匹马获胜视为一个随机变量 。假定我们需要用尽可能少的二元问题来确定随机变量
的取值。
例如:问题1:A获胜了吗?问题2:B获胜了吗?问题3:C获胜了吗?最后我们可以通过最多3个二元问题,来确定 的取值,即哪一匹马赢了比赛。
如果 ,那么需要问1次(问题1:是不是A?),概率为
;
如果 ,那么需要问2次(问题1:是不是A?问题2:是不是B?),概率为
;
如果 ,那么需要问3次(问题1,问题2,问题3),概率为
;
如果 ,那么同样需要问3次(问题1,问题2,问题3),概率为
;
那么很容易计算,在这种问法下,为确定 取值的二元问题数量为:
那么我们回到信息熵的定义,会发现通过之前的信息熵公式,神奇地得到了:
在二进制计算机中,一个比特为0或1,其实就代表了一个二元问题的回答。也就是说,在计算机中,我们给哪一匹马夺冠这个事件进行编码,所需要的平均码长为1.75个比特。
平均码长的定义为:
很显然,为了尽可能减少码长,我们要给发生概率 较大的事件,分配较短的码长
。这个问题深入讨论,可以得出霍夫曼编码的概念。
那么 四个实践,可以分别由
表示,那么很显然,我们要把最短的码
分配给发生概率最高的事件
,以此类推。而且得到的平均码长为1.75比特。如果我们硬要反其道而行之,给事件
分配最长的码
,那么平均码长就会变成2.625比特。
霍夫曼编码就是利用了这种大概率事件分配短码的思想,而且可以证明这种编码方式是最优的。我们可以证明上述现象:
- 为了获得信息熵为
的随机变量
的一个样本,平均需要抛掷均匀硬币(或二元问题)
次(参考猜赛马问题的案例)
- 信息熵是数据压缩的一个临界值(参考码长部分的案例)。
这可能是信息熵在实际工程中,信息熵最最重要且常见的一个用处。
最后,解释下信息熵公式的由来:
信息论之父克劳德·香农,总结出了信息熵的三条性质:
- 单调性,即发生概率越高的事件,其所携带的信息熵越低。极端案例就是“太阳从东方升起”,因为为确定事件,所以不携带任何信息量。从信息论的角度,认为这句话没有消除任何不确定性。
- 非负性,即信息熵不能为负。这个很好理解,因为负的信息,即你得知了某个信息后,却增加了不确定性是不合逻辑的。
- 累加性,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和。写成公式就是:
事件 同时发生,两个事件相互独立
,
那么信息熵 。
香农从数学上,严格证明了满足上述三个条件的随机变量不确定性度量函数具有唯一形式:
其中的 为常数,我们将其归一化为
即得到了信息熵公式。
补充一下,如果两个事件不相互独立,那么满足
,其中
是互信息(mutual information),代表一个随机变量包含另一个随机变量信息量的度量,这个概念在通信中用处很大。
比如一个点到点通信系统中,发送端信号为 ,通过信道后,接收端接收到的信号为
,那么信息通过信道传递的信息量就是互信息
。根据这个概念,香农推出了一个十分伟大的公式,香农公式,给出了临界通信传输速率的值,即信道容量:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号