


Flink API介绍
1.Stateful Stream Processing 最低级的抽象接口是状态化的数据流接口 2.DataStream/DataSet API 是 Flink 提供的核心 API ,DataSet 处理 有界的数据集,DataStream 处理有界或者无界的数据流。 3.Table API 4.SQL
Dataflows数据流图
Flink Dataflows是由三部分组成,分别是:source、transformation、sink结束 1.source数据源会源源不断的产生数据 2.transformation将产生的数据进行各种业务逻辑的数据处理 3.由sink输出到外部(console、kafka、redis、DB......)
下图中这段代码和流程图就是一个Dataflows
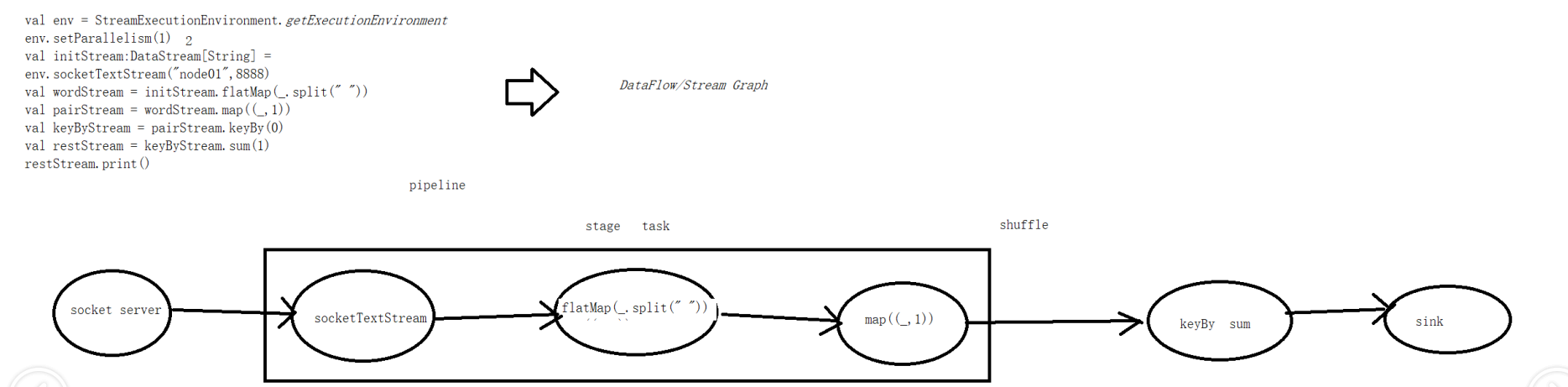
flink上的Dataflow
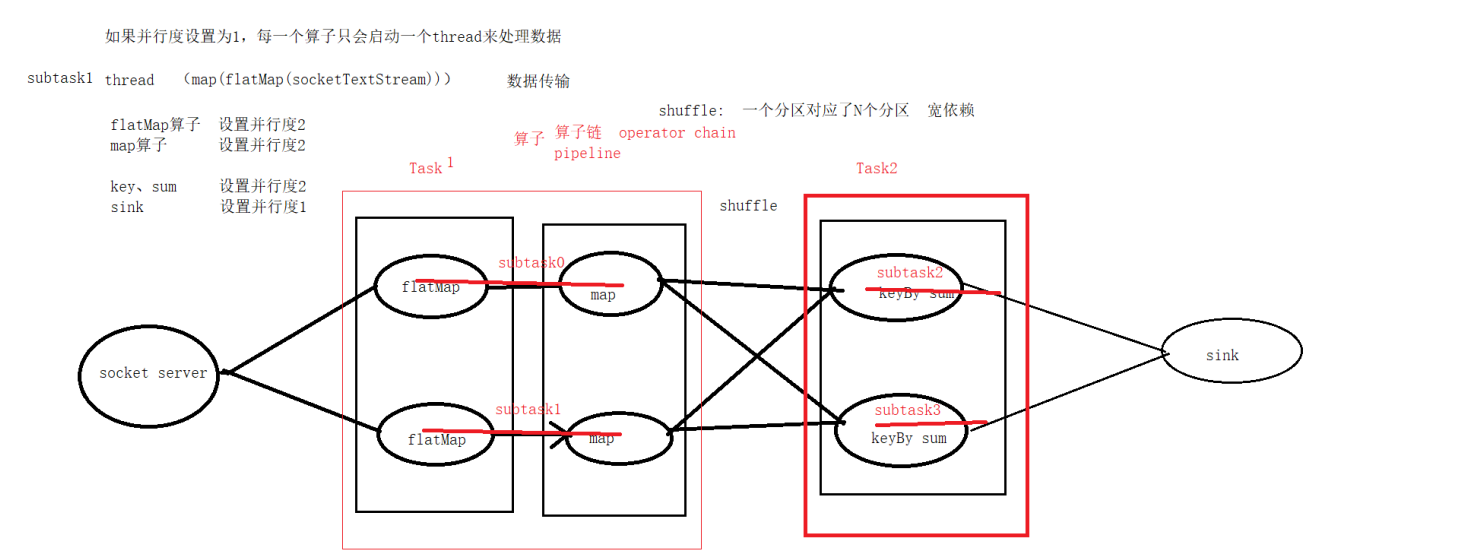
当并行度如下设置,Dataflow如下流程
| spark | flink | |
| pipeline | 算子链 operator chain | |
| stage | task | |
| task | 线程 |
1对一 窄依赖
1对多 宽依赖
1. stage(spark) = task(flink)
2. pipeline(spark) = 算子链operator chain(flink)
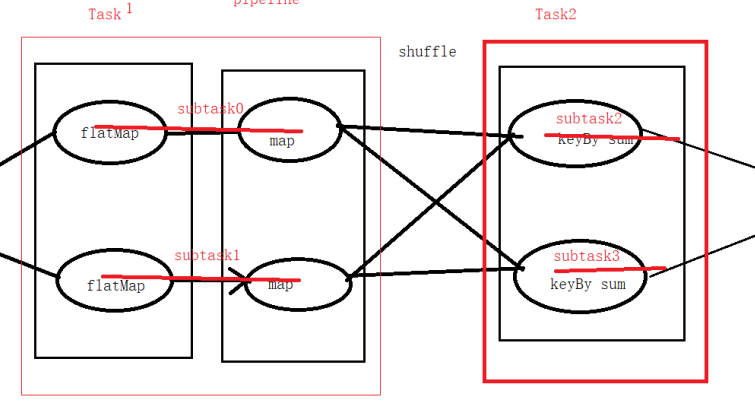
3. Task(spark)是shuffle切开的
4. Task中的子任务对应的是thread (subTask0=subTask1, subTask2 = subTask3)
设置并行度如下

设置算子并行度方式4种
1.配置文件设置,系统全局 parallelism.default: 1 2.在提交job的时候,通过-p选项来设置 3.在代码中通过环境变量来设置 代码全局 env.setParallelism(1) 4. 直接在算子上设置 val wordStream = initStream.flatMap(_.split(" ")).setParallelism(2)
Show plan
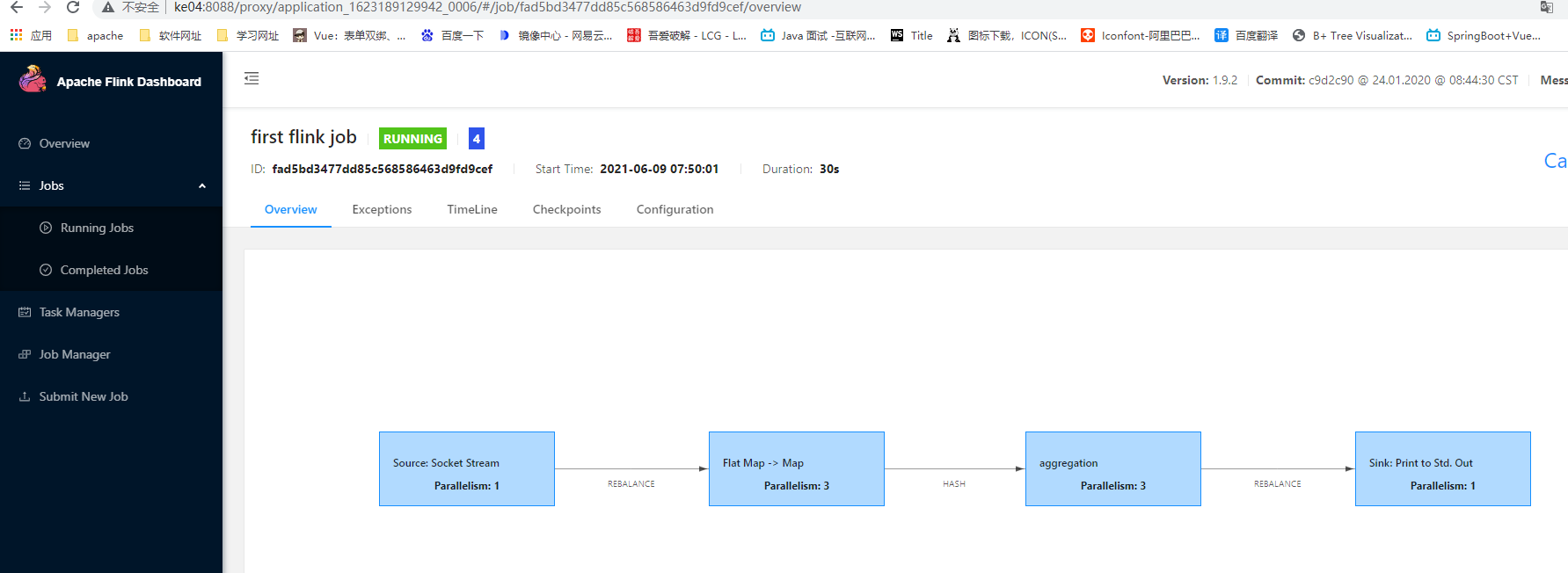
val env = StreamExecutionEnvironment.getExecutionEnvironment val initStream: DataStream[String] = env.socketTextStream("192.168.75.85", 8888) val wordStream = initStream.flatMap(_.split(" ")).setParallelism(3) val pairStream = wordStream.map((_, 1)).setParallelism(2) val keyByStream = pairStream.keyBy(0) val restStream = keyByStream.sum(1).setParallelism(3) restStream.print() env.execute("first flink job")

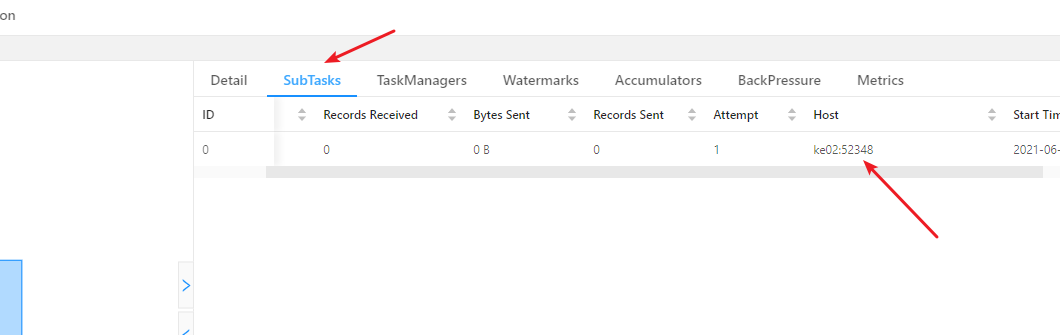
点击对应的算子,在点击SubTask可以查看当前算子在那个机器上运行
停掉任务有两种方式
1.在页面点击Cancel Job 2.命令:flink canel id
startNewChain()和disableChaining()提高执行效率
1.业务逻辑简单,使用startNewChain提高效率 2.业务逻辑复杂,通过提高并行度+disableChaining提高执行效率 如: val wordStream = initStream.flatMap(_.split(" ")).startNewChain() val pairStream = wordStream.map((_, 1)) 如: val wordStream = initStream.flatMap(_.split(" ")).setParallelism(100).disableChaining() val pairStream = wordStream.map((_, 1)) 特例:如果并行度改变,则会发生shuffle,startNewChain和disableChaining不起作用 val wordStream = initStream.flatMap(_.split(" ")).setParallelism(2).startNewChain() val pairStream = wordStream.map((_, 1)).setParallelism(3)
因: task slot内存隔离,CPU不隔离 要提高效率,则: TaskManager上有(subtask0, subtask2),这样就可以内存不隔离,提高效率 既: 可以提高本地化级别 问:TaskManager上是否可以放(subtask0,1, 2, 3) 答: 不可以,也不行 flink分发Task规律 1. 不同Task的subtask要分发到同一个task slot中(降低数据传输、提高执行效率) 2. 相同Task的subtask要分发到不同的task slot中(充分利用集群资源)
so:
Task slot 个数 决定了 job未来执行的并行度
并行度设置为2
val env = StreamExecutionEnvironment.getExecutionEnvironment val initStream: DataStream[String] = env.socketTextStream("192.168.75.85", 8888) val wordStream = initStream.flatMap(_.split(" ")).setParallelism(2) val pairStream = wordStream.map((_, 1)).setParallelism(2) val keyByStream = pairStream.keyBy(0) val restStream = keyByStream.sum(1).setParallelism(2) restStream.print() //这里没有设置默认为1 env.execute("first flink job") 结果: socket:ke03:41726 flatMap: ke03:41726 ke03:41726 aggregation: ke03:41726 ke03:41726 Sink: ke03:41726
并行度设置为4
val env = StreamExecutionEnvironment.getExecutionEnvironment val initStream: DataStream[String] = env.socketTextStream("192.168.75.85", 8888) val wordStream = initStream.flatMap(_.split(" ")).setParallelism(4) val pairStream = wordStream.map((_, 1)).setParallelism(4) val keyByStream = pairStream.keyBy(0) val restStream = keyByStream.sum(1).setParallelism(4) restStream.print() //这里没有设置默认为1 env.execute("first flink job") 结果: Socket : ke03:41726 Flat Map: ke03:38944 ke03:38944 ke04:41726 ke04:41726 aggregation: ke03:38944 ke03:38944 ke04:41726 ke04:41726 Sink: ke03:41726
设置并行度为50
因为每台机器只有2个槽,3台机器6个槽 task slot,则启动失败 1.启动设置并行度-p 或者页面设置 2.代码中restStream.print() 没有这只并行度,在启动的时候设置会给这里加并行度为50,因为没有这么多槽位,则status过一会会失败
以上代码导包和打包maven_pom
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.9.2</version>
</dependency>
<build>
<plugins>
<!-- 在maven项目中既有java又有scala代码时配置 maven-scala-plugin 插件打包时可以将两类代码一起打包 -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- maven 打jar包需要插件 -->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4</version>
<configuration>
<!-- 设置false后是去掉 MySpark-1.0-SNAPSHOT-jar-with-dependencies.jar 后的 “-jar-with-dependencies” -->
<!--<appendAssemblyId>false</appendAssemblyId>-->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
从HDFS上读取文件
//在算子转换的时候,会将数据转换成Flink内置的数据类型,所以需要将隐式转换导入进来,才能自动进行类型转换 import org.apache.flink.streaming.api.scala._ val env = StreamExecutionEnvironment.getExecutionEnvironment // readTextFile 只读一次 val textStream = env.readTextFile("hdfs://ke01:8020/xiaoke002/two") textStream.print() env.execute() 结果: 6> 1,小明 8> 2,小红 11> 3,小柯 2> 4,wang readTextFile底层代码:调用readFile,传入了 FileProcessingMode.PROCESS_ONCE(只允许一次)
so: 需要持续读取数据需要自己写readFile()方法, 使用FileProcessingMode.PROCESS_CONTINUOUSLY持续读入
val env = StreamExecutionEnvironment.getExecutionEnvironment
val filePath = "hdfs://ke01:8020/xiaoke002/two"
val textInputFormat = new TextInputFormat(new Path(filePath))
// 每隔10s中读取 hdfs上新增文件内容
val textStream = env.readFile(textInputFormat, filePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 10)
textStream.print()
env.execute()
结果:持续运行,每次有新数据进来,都会全部读一遍
12> 1,小明
5> 3,小柯
8> 4,wang
2> 2,小红
hdfs dfs -appendToFile test /xiaoke002/two
3> 3,小柯
6> aa bb
7> cc dd
5> 4,wang
1> 2,小红
12> 1,小明
9> e
