
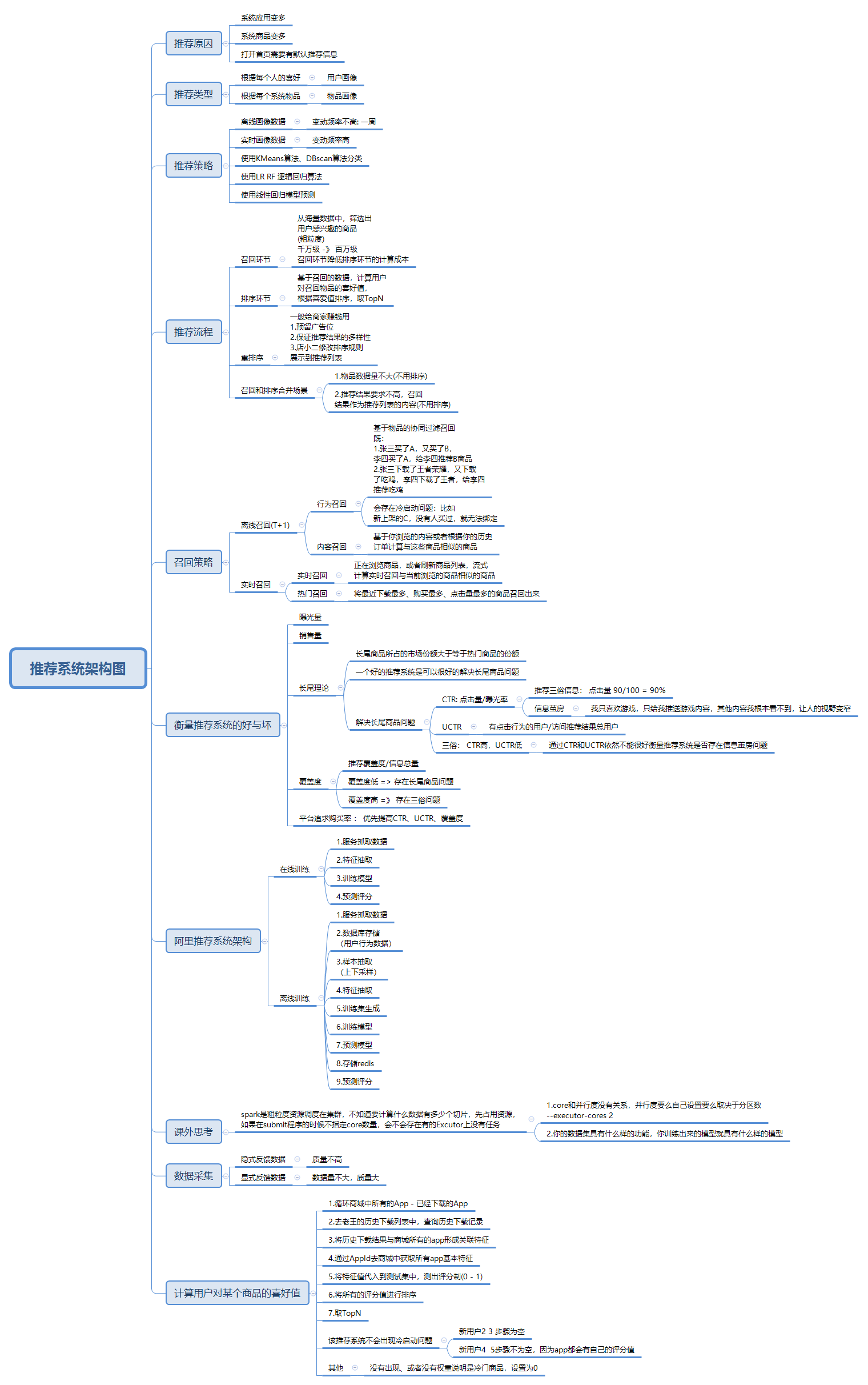
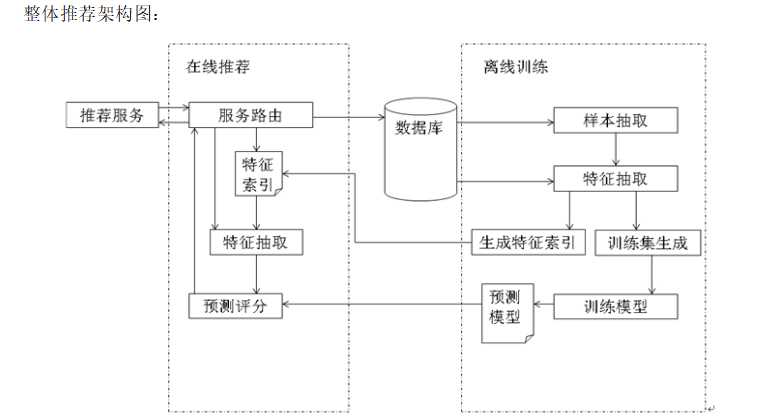
1. 将原数据导入到hive表中
// 用户有三个数据文件
1. applist.txt 商品词表:
2. sample.txt 正负例样本表()
3. userdownload.txt 用户下载历史软件
//创建表
应用词表:
CREATE EXTERNAL TABLE IF NOT EXISTS dim_rcm_hitop_id_list_ds
(
hitop_id STRING,
name STRING,
author STRING,
sversion STRING,
ischarge SMALLINT,
designer STRING,
font STRING,
icon_count INT,
stars DOUBLE,
price INT,
file_size INT,
comment_num INT,
screen STRING,
dlnum INT
)row format delimited fields terminated by '\t';
用户历史下载表:
CREATE EXTERNAL TABLE IF NOT EXISTS dw_rcm_hitop_userapps_dm
(
device_id STRING,
devid_applist STRING,
device_name STRING,
pay_ability STRING
)row format delimited fields terminated by '\t';
正负例样本表:
CREATE EXTERNAL TABLE IF NOT EXISTS dw_rcm_hitop_sample2learn_dm
(
label STRING,
device_id STRING,
hitop_id STRING,
screen STRING,
en_name STRING,
ch_name STRING,
author STRING,
sversion STRING,
mnc STRING,
event_local_time STRING,
interface STRING,
designer STRING,
is_safe INT,
icon_count INT,
update_time STRING,
stars DOUBLE,
comment_num INT,
font STRING,
price INT,
file_size INT,
ischarge SMALLINT,
dlnum INT
)row format delimited fields terminated by '\t';
//分别往三张表load数据:
商品词表:
load data local inpath '/opt/msb/recommender/data/applist.txt' into table dim_rcm_hitop_id_list_ds;
用户历史下载表:
load data local inpath '/opt/msb/recommender/data/userdownload.txt' into table dw_rcm_hitop_userapps_dm;
正负例样本表:
load data local inpath '/opt/msb/recommender/data/sample.txt' into table dw_rcm_hitop_sample2learn_dm;
//创建临时表
处理数据时所需要的临时表
CREATE TABLE IF NOT EXISTS tmp_dw_rcm_hitop_prepare2train_dm
(
device_id STRING,
label STRING,
hitop_id STRING,
screen STRING,
ch_name STRING,
author STRING,
sversion STRING,
mnc STRING,
interface STRING,
designer STRING,
is_safe INT,
icon_count INT,
update_date STRING,
stars DOUBLE,
comment_num INT,
font STRING,
price INT,
file_size INT,
ischarge SMALLINT,
dlnum INT,
idlist STRING,
device_name STRING,
pay_ability STRING
)row format delimited fields terminated by '\t';
最终保存训练集的表
CREATE TABLE IF NOT EXISTS dw_rcm_hitop_prepare2train_dm
(
label STRING,
features STRING
)row format delimited fields terminated by '\t';
首先将数据从正负例样本和用户历史下载表数据加载到临时表中
INSERT OVERWRITE TABLE tmp_dw_rcm_hitop_prepare2train_dm
SELECT
t2.device_id,
t2.label,
t2.hitop_id,
t2.screen,
t2.ch_name,
t2.author,
t2.sversion,
t2.mnc,
t2.interface,
t2.designer,
t2.is_safe,
t2.icon_count,
to_date(t2.update_time),
t2.stars,
t2.comment_num,
t2.font,
t2.price,
t2.file_size,
t2.ischarge,
t2.dlnum,
t1.devid_applist,
t1.device_name,
t1.pay_ability
FROM
(
SELECT
device_id,
devid_applist,
device_name,
pay_ability
FROM
dw_rcm_hitop_userapps_dm
) t1
RIGHT OUTER JOIN
(
SELECT
device_id,
label,
hitop_id,
screen,
ch_name,
author,
sversion,
IF (mnc IN ('00','01','02','03','04','05','06','07'), mnc,'x') AS mnc,
interface,
designer,
is_safe,
IF (icon_count <= 5,icon_count,6) AS icon_count,
update_time,
stars,
IF ( comment_num IS NULL,0,
IF ( comment_num <= 10,comment_num,11)) AS comment_num,
font,
price,
IF (file_size <= 2*1024*1024,2,
IF (file_size <= 4*1024*1024,4,
IF (file_size <= 6*1024*1024,6,
IF (file_size <= 8*1024*1024,8,
IF (file_size <= 10*1024*1024,10,
IF (file_size <= 12*1024*1024,12,
IF (file_size <= 14*1024*1024,14,
IF (file_size <= 16*1024*1024,16,
IF (file_size <= 18*1024*1024,18,
IF (file_size <= 20*1024*1024,20,21)))))))))) AS file_size,
ischarge,
IF (dlnum IS NULL,0,
IF (dlnum <= 50,50,
IF (dlnum <= 100,100,
IF (dlnum <= 500,500,
IF (dlnum <= 1000,1000,
IF (dlnum <= 5000,5000,
IF (dlnum <= 10000,10000,
IF (dlnum <= 20000,20000,20001)))))))) AS dlnum
FROM
dw_rcm_hitop_sample2learn_dm
) t2
ON (t1.device_id = t2.device_id);
//使用python处理
dw_rcm_hitop_prepare2train_dm.py
import sys
import codecs
import random
import math
import time
import datetime
if __name__ == "__main__":
random.seed(time.time())
for l in sys.stdin:
d = l.strip().split('\t')
if len(d) != 21:
continue
# Extract data from the line
label = d.pop(0)
hitop_id = d.pop(0)
screen = d.pop(0)
ch_name = d.pop(0)
author = d.pop(0)
sversion = d.pop(0)
mnc = d.pop(0)
interface = d.pop(0)
designer = d.pop(0)
icon_count = d.pop(0)
update_date = d.pop(0)
stars = d.pop(0)
comment_num = d.pop(0)
font = d.pop(0)
price = d.pop(0)
file_size = d.pop(0)
ischarge = d.pop(0)
dlnum = d.pop(0)
#下载记录
hitopids = d.pop(0)
device_name = d.pop(0)
pay_ability = d.pop(0)
# Construct feature vector
features = []
features.append(("Item.id,%s" % hitop_id, 1))
features.append(("Item.screen,%s" % screen, 1))
features.append(("Item.name,%s" % ch_name, 1))
features.append(("All,0",1))
features.append(("Item.author,%s" % author, 1))
features.append(("Item.sversion,%s" % sversion, 1))
features.append(("Item.network,%s" % mnc, 1))
features.append(("Item.dgner,%s" % designer, 1))
features.append(("Item.icount,%s" % icon_count, 1))
features.append(("Item.stars,%s" % stars, 1))
features.append(("Item.comNum,%s" % comment_num,1))
features.append(("Item.font,%s" % font,1))
features.append(("Item.price,%s" % price,1))
features.append(("Item.fsize,%s" % file_size,1))
features.append(("Item.ischarge,%s" % ischarge,1))
features.append(("Item.downNum,%s" % dlnum,1))
####User.Item and User.Item*Item
idlist = hitopids.split(',')
idCT = 0;
for id in idlist:
#为什么取前三个? 5个 全部取 效率 准确率
features.append(("User.Item*Item,%s" % id +'*'+hitop_id, 1))
idCT += 1
if idCT >= 3:
break;
#组合特征
features.append(("User.phone*Item,%s" % device_name + '*' + hitop_id,1))
#组合特征 (1)根据经验 (2)随机组合
features.append(("User.pay*Item.price,%s" % pay_ability + '*' + price,1))
# Output
output = "%s\t%s" % (label, ";".join([ "%s:%d" % (f, v) for f, v in features ]))
print output
// 注意: 在hive中 ADD FILE /tmp/bigdata/dw_rcm_hitop_prepare2train_dm.py;
// 可以通过list files;查看是不是python文件加载到了hive
2.样本抽取(这里数据选用全量数据,实际根据自己的业务进行筛选即可)
3.训练集生成
INSERT OVERWRITE TABLE dw_rcm_hitop_prepare2train_dm SELECT TRANSFORM (t.*) USING 'python code_dw_rcm_hitop_prepare2train_dm.py' AS (label,features) FROM ( SELECT label, hitop_id, screen, ch_name, author, sversion, mnc, interface, designer, icon_count, update_date, stars, comment_num, font, price, file_size, ischarge, dlnum, idlist, device_name, pay_ability FROM tmp_dw_rcm_hitop_prepare2train_dm ) t;
4. 生成训练模型、特征索引
// 下面的dict就是特征名索引集合(词袋) // 下面的模型结果主要生成权重,因为逻辑回归是w1+w2+w3越大 带入到逻辑回归公式 1/(1+e^-z) 累加权重越大 逻辑回归值越大(则约接近于1) 排序越靠前 package tuijian import java.io.PrintWriter import org.apache.log4j.{Level, Logger} import org.apache.spark.mllib.classification.{LogisticRegressionModel, LogisticRegressionWithLBFGS, LogisticRegressionWithSGD} import org.apache.spark.mllib.linalg.SparseVector import org.apache.spark.mllib.regression.LabeledPoint import org.apache.spark.rdd.RDD import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} import scala.collection.Map object test01 { def main(args: Array[String]): Unit = { Logger.getLogger("org.apache.spark").setLevel(Level.ERROR) val conf = new SparkConf().setAppName("test").setMaster("local[*]") val spark = SparkSession.builder().config(conf) getOrCreate() val dataRDD = spark.sparkContext.textFile("data/result") //加载数据,用\t分隔开 val data: RDD[Array[String]] = dataRDD.map(_.split("\t")) //得到第一列的值,也就是label val label: RDD[String] = data.map(_ (0)) //sample这个RDD中保存的是每一条记录的特征名 val sample: RDD[Array[String]] = data.map(_ (1)).map(x => { //这条记录的所有的特征名 val arr: Array[String] = x.split(";").map(_.split(":")(0)) arr }) // 特征名索引集合 变成词袋 val dict: Map[String, Long] = sample.flatMap(x => x).distinct().zipWithIndex().collectAsMap() //得到稀疏向量 val sam: RDD[SparseVector] = sample.map(sampleFeatures => { //index中保存的是,未来在构建训练集时,下面填1的索引号集合 val index: Array[Int] = sampleFeatures.map(feature => { //get出来的元素程序认定可能为空,做一个类型匹配 val rs: Long = dict.get(feature).get //非零元素下标,转int符合SparseVector的构造函数 rs.toInt }) //SparseVector创建一个向量 new SparseVector(dict.size, index, Array.fill(index.length)(1.0)) }) //mllib中的逻辑回归只认1.0和0.0,这里进行一个匹配转换 val la: RDD[LabeledPoint] = label.map(x => { x match { case "-1" => 0.0 case "1" => 1.0 } //标签组合向量得到labelPoint }).zip(sam).map(x => new LabeledPoint(x._1, x._2)) //逻辑回归训练,两个参数,迭代次数和步长,生产常用调整参数 val lr = new LogisticRegressionWithSGD() // 设置W0截距 lr.setIntercept(true) // 最大迭代次数 lr.optimizer.setNumIterations(10) // 设置梯度下降的步长,学习率 lr.optimizer.setStepSize(0.1) //权重 val model: LogisticRegressionModel = lr.run(la) //模型结果权重 val weights: Array[Double] = model.weights.toArray //将map反转,weights相应下标的权重对应map里面相应下标的特征名 val map: Map[Long, String] = dict.map(_.swap) //模型保存 // LogisticRegressionModel.load() //输出 val pw = new PrintWriter("data/model"); //遍历 for (i <- 0 until weights.length) { //通过map得到每个下标相应的特征名 val featureName = map.get(i) match { case Some(x) => x case None => "" } //特征名对应相应的权重 val str = featureName + "\t" + weights(i) pw.write(str) pw.println() } pw.flush() pw.close() } } // 结果: ------------------ sample Item.screen,screen2 Item.name,ch_name44 User.Item*Item,hitop_id45*hitop_id0 User.phone*Item,device_name63*hitop_id0 User.pay*Item.price,pay_ability0*1992 ------------------- dict (Item.price,771,51513) (User.phone*Item,device_name149*hitop_id76,56106) (User.phone*Item,device_name907*hitop_id5,59610) ------------ sam (102640,[37422,46695,4713,58838,914,7584,88618,50924,71937,38971,13460,54871,31229,14922,90500,16441,51253,27104,99400,15648,27545],[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]) (102640,[37422,46695,4713,58838,914,7584,88618,50924,71937,38971,13460,54871,31229,14922,90500,16441,1090,26098,34910,92586,43997],[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]) (102640,[14565,87974,2333,58838,60632,7584,88618,59438,71937,69238,13460,2734,34730,14922,42263,42600,18124,84934,3840,59780,81513],[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]) ------------ la (0.0,(102640,[37422,46695,4713,58838,914,7584,88618,50924,71937,38971,13460,54871,31229,14922,90500,16441,1090,26098,34910,92586,43997],[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0])) (1.0,(102640,[14565,87974,2333,58838,60632,7584,88618,59438,71937,69238,13460,2734,34730,14922,42263,42600,18124,84934,3840,59780,81513],[1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0]))
5. 数据放入redis中
import redis pool = redis.ConnectionPool(host='192.168.75.91', port='6390', db=2, password='aa123456') r = redis.Redis(connection_pool=pool) # f = open('D:\\code\\python\\test2\\data\\model_ModelFile.txt', encoding='UTF-8') # f = open('D:\\code\\python\\test2\\data\\UserItemsHistory.txt', encoding='UTF-8') f = open('D:\\code\\python\\test2\\data\\ItemList.txt', encoding='UTF-8') while True: lines = f.readlines() if not lines: break for line in lines: kv = line.split('\t') # r.hset("rcmd_features_score", kv[0], kv[1]) # r.hset('rcmd_user_history', kv[0], kv[1]) r.hset('rcmd_item_list', kv[0], kv[:-2]) f.close()
6. 服务使用
// 将所有的为1的权重进行累加,带入到逻辑回归公式 1/(1+e^-z) 累加权重越大 逻辑回归值越大(则约接近于1) 排序越靠前 1. 遍历出人为因素的权重 2. 遍历出商品自己的权重 3. 累加所有权重 4. 权重重排序 5. 拿出需要的排行榜 package com.alibaba.dubbo.demo.impl; import com.alibaba.dubbo.demo.RcmdService; import redis.clients.jedis.Jedis; import java.util.*; public class RcmdServiceImpl implements RcmdService { @Override public List<String> getRcmdList(String uid) { // 获得数据库连接 Jedis jedis = new Jedis("192.168.75.91", 6390); jedis.select(4); jedis.auth("aa123456"); // 从用户历史下载表来获取最近下载 String downloadListString = jedis.hget("rcmd_user_history", uid); String[] downloadList = downloadListString.split(","); System.out.println(uid + " downloadList:" + downloadList); // 获取所有应用ID列表 Set<String> appList = jedis.hkeys("rcmd_item_list"); // 存储总的特征分值 Map<String, Double> scores = new HashMap<String, Double>(); // 分别计算所有应用的总权重 appList商城中所有的app for (String appId : appList) { // 计算关联权重 double relativeFeatureScore = this.getRelativeFeatureScore(appId, downloadList, jedis); // 累加个人的权重 updateScoresMap(scores, appId, relativeFeatureScore); // 累计商品的权重 double basicFeatureScore = this.getBasicFeatureScore(appId, jedis); updateScoresMap(scores, appId, basicFeatureScore); } //这里将map.entrySet()转换成list List<Map.Entry<String, Double>> list = new ArrayList<Map.Entry<String, Double>>(scores.entrySet()); //然后通过比较器来实现排序 Collections.sort(list, new Comparator<Map.Entry<String, Double>>() { //升序排序 public int compare(Map.Entry<String, Double> o1, Map.Entry<String, Double> o2) { return -o1.getValue().compareTo(o2.getValue()); } }); // 打印分值 for (Map.Entry<String, Double> mapping : list) { System.out.println(mapping.getKey() + ":" + mapping.getValue()); } // 取前10个appID返回 List<String> result = new ArrayList<>(); int count = 0; for (Map.Entry<String, Double> mapping : list) { count++; result.add(mapping.getKey()); if(count==10){ break; } } jedis.close(); return result; } private void updateScoresMap(Map<String, Double> scores, String appName, double score) { if (scores.get(appName) == null) { scores.put(appName, score); } else { scores.put(appName, scores.get(appName) + score); } } //获取商品关联特征权重 private double getRelativeFeatureScore(String appId, String[] downloadList, Jedis jedis) { double score = 0.0; //得到所有的关联特征所对应的权重之和 for (String downloadAppId : downloadList) { // Item.id*Item.id@70*193 // 构成关联特征 String feature = "Item.id*Item.id@" + appId + "*" + downloadAppId; String rcmd_features_score = jedis.hget("rcmd_features_score", feature); if(rcmd_features_score!=null){ score += Double.valueOf(rcmd_features_score); } // String featurex = "Item.id*Item.id@" + downloadAppId + "*" + appId; // String rcmd_features_scorex = jedis.hget("rcmd_features_score", featurex); // if(rcmd_features_scorex!=null) { // score += Double.valueOf(rcmd_features_scorex); // } } return score; } private double getBasicFeatureScore(String appId, Jedis jedis) { // 存储基本特征分值 double basicScore = 0.0; // 从商品词表取基本特征 /* Item.id@146 软件ID Item.name@183 名字 Item.author@zhouming 作者 Item.sversion@1.3.2 版本号 Item.ischarge@1 是否收费 Item.dgner@husheng 设计者 Item.font@Consolos 字体 Item.icount@4 图片数量 Item.icount_dscrt@4 Item.stars@5 星级 Item.price 价格 Item.fsize@6 文件大小 Item.fsize_dscrt@6 Item.comNum@0 评论数量 Item.comNum_dscrt@0 Item.screen@FHD 屏幕类型 Item.downNum@200 下载数 Item.downNum_dscrt@200 */ String[] basicFeatureNames = {"Item.id", "Item.name", "Item.author", "Item.sversion", "Item.ischarge" , "Item.dgner", "Item.font", "Item.icount", "Item.icount_dscrt", "Item.stars", "Item.price" , "Item.fsize", "Item.fsize_dscrt", "Item.comNum", "Item.comNum_dscrt", "Item.screen", "Item.downNum" , "Item.downNum_dscrt"}; String rcmd_item_list = jedis.hget("rcmd_item_list", appId); String[] basicFeatures = rcmd_item_list.split("\t"); // 累加的app基本特征所对应的权重之和 for (int i = 0; i < basicFeatureNames.length; i++) { String rcmd_features_score = jedis.hget("rcmd_features_score", basicFeatureNames[i] + "@" + basicFeatures[i]); if (rcmd_features_score != null) { basicScore += Double.valueOf(rcmd_features_score); } } return basicScore; } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号