
在HDFS环境基础上增加MapReduce计算程序
- 之前的HDFS环境不变
- 使用root来启动程序
环境搭建布局
| 节点 | NN | JNN | DN | ZKFC | ZK | RM |
NM |
| node01 | √ | √ | √ | ||||
| node02 | √ | √ | √ | √ | √ | √ | |
| node03 | √ | √ | √ | √ | √ | ||
| node04 | √ | √ | √ | √ |
node01:
cd $HADOOP_HOME/etc/hadoop cp mapred-site.xml.template mapred-site.xml vi mapred-site.xml vi yarn-site.xml scp mapred-site.xml yarn-site.xml node02:`pwd` scp mapred-site.xml yarn-site.xml node03:`pwd` scp mapred-site.xml yarn-site.xml node04:`pwd` vi slaves //可以不用管,搭建hdfs时候已经改过了。。。 start-yarn.sh
node03~04:
yarn-daemon.sh start resourcemanager
mapred-site.xml配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
//shuffle意思洗牌,将map之后的值传递给reduce M -shuffle> R <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>node02:2181,node03:2181,node04:2181</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>mashibing</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>node03</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>node04</value> </property>
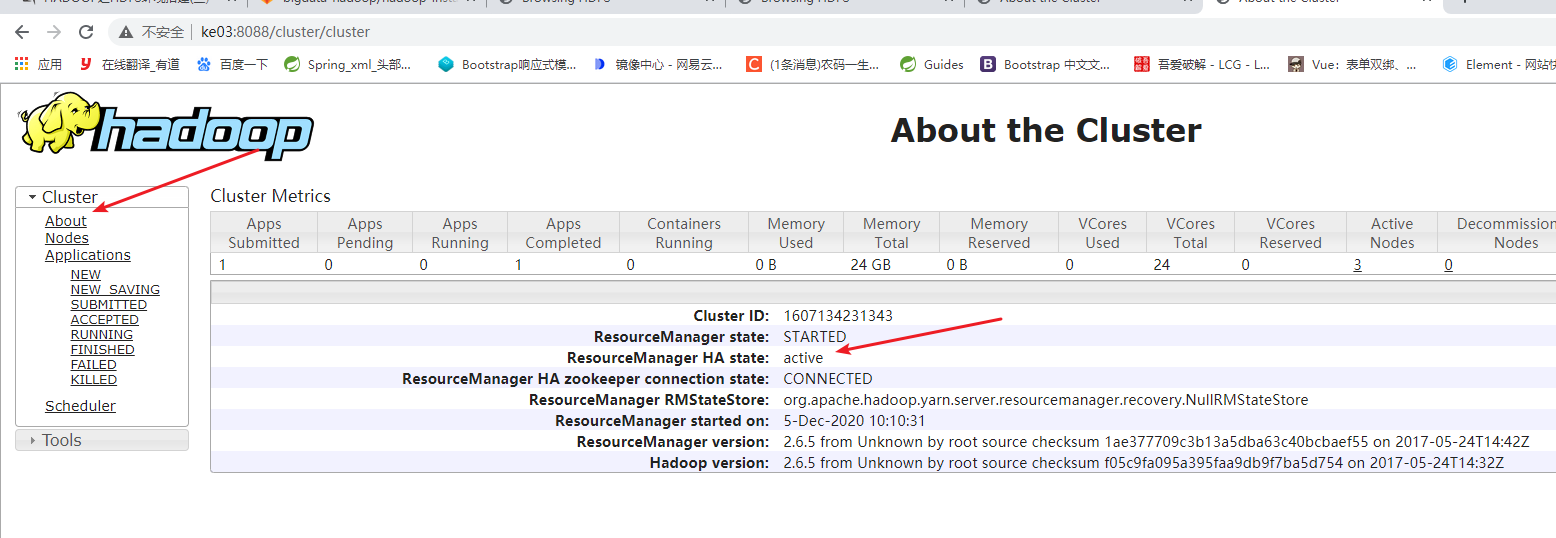
- http://node03:8088 或 http://node04:8088
![]()
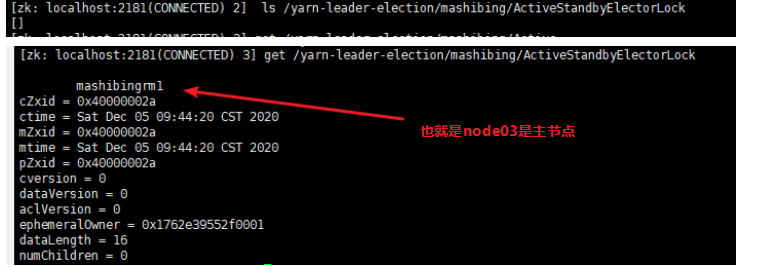
- 进组zookeeper --> zkCli.sh --> get /yarn-leader-election/mashibing/ActiveStandbyElectorLock
![]()
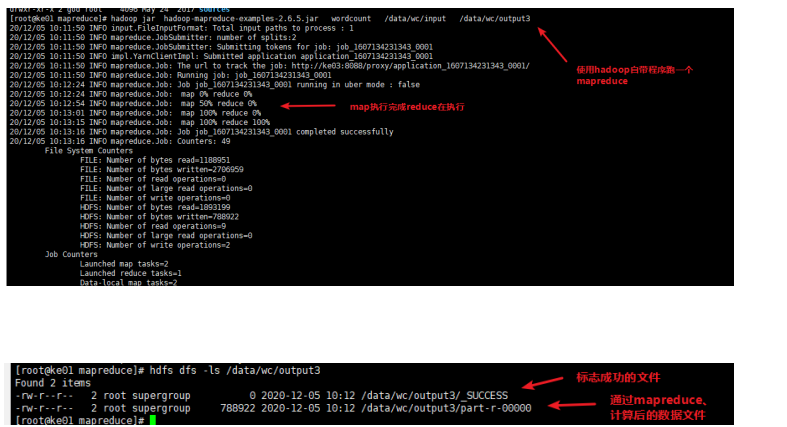
mapreduce任务启动命令和步骤
MR ON YARN 的运行方式hdfs dfs -mkdir -p /data/wc/input hdfs dfs -D dfs.blocksize=1048576 -put data.txt /data/wc/input cd $HADOOP_HOME cd share/hadoop/mapreduce hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/wc/input /data/wc/output 1)webui: 2)cli: hdfs dfs -ls /data/wc/output -rw-r--r-- 2 root supergroup 0 2019-06-22 11:37 /data/wc/output/_SUCCESS //标志成功的文件 -rw-r--r-- 2 root supergroup 788922 2019-06-22 11:37 /data/wc/output/part-r-00000 //数据文件 part-r-00000 //意思执行了 map + reduce part-m-00000 //意思只执行 map hdfs dfs -cat /data/wc/output/part-r-00000 hdfs dfs -get /data/wc/output/part-r-00000 ./ // 下载到本地看
- 图示
![]()
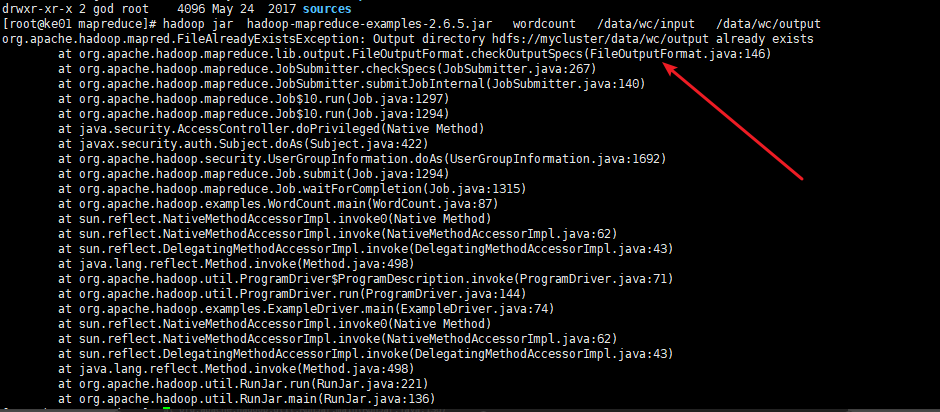
注意点:
- 输出文件目录必须不存在,否则启动任务报错
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号