
前提:四台机器都要有java环境、hadoop环境、
node01:
cd $HADOOP/etc/hadoop
#NN角色 vi core-site.xml 不需要改
# 配置HDFS 副本数为2 nn目录 dn目录 secondary_namenode启动节点以及目录 vi hdfs-site.xml <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/var/bigdata/hadoop/full/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/var/bigdata/hadoop/full/dfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node02:50090</value> </property> <property> <name>dfs.namenode.checkpoint.dir</name> <value>/var/bigdata/hadoop/full/dfs/secondary</value> </property>
vi slaves node02 node03 node04
分发:
cd /opt
scp -r ./bigdata/ node02:`pwd`
scp -r ./bigdata/ node03:`pwd`
scp -r ./bigdata/ node04:`pwd`
格式化启动
hdfs namenode -format
start-dfs.sh
node01 :NameNode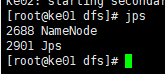

node02 :SecondaryNameNode、DataNode
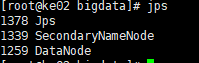

node03 :DataNode
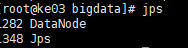

node04 :DataNode


NN问题: client找NN进行创建文件、上传文件操作,DN要给NN汇报block信息。NN会有压力,如果挂掉整体不可用。
解决思路:
1.主从集群(相当于三个zookeeper,选主,每次只有一台工作)
主从集群:结构相对简单,主与从协作 主:单点,数据一致好掌握 问题: 单点故障,集群整体不可用 压力过大,内存受限
2.主备(HDFS使用)
单点故障解决方式: 高可用方案:HA(High Available) 多个NN,主备切换,主压力过大,内存受限: 联帮机制: Federation(元数据分片) 多个NN,管理不同的元数据 HADOOP 2.x 只支持HA的一主一备,3.x支持一主多备
3.HDFS-HA解决方案

图分两部分看
下半部,手动HA,包含: client、NNactive、NN Standby、3台主从JN、 4台DN(主要是保证数据同步) 1.DN会向两台NN同时汇报,所有DN数据是同步的。 2.client只能向NNactive汇报,当NNactive挂掉,链接另外一台NN,那么存在数据丢失,所以需要增加JN,来持久化数据,既:clinet向NNactive写入数据,NNactive会同时写入JN,当NNactive挂掉,另外一台升级为active,会从JN中获取数据。 上半部,自动HA,包含:NNactive、NN Standby、FC active、FC Standby、三台ZK (选主active) 1.当NNactive挂掉、FC active会与ZK解锁、同时回调FC Standby、FC Standby 1.去ZK抢锁,2.访问原来的NNactive状态是否挂掉 3.升级NN Standby 为active 2.当FC active挂掉、 与zk断开连接,同时临时锁断开、同时回调FC Standby、FC Standby 1.去ZK抢锁,2.访问原来的NNactive状态、如果是active,则降级为standby 3.升级NN Standby 为active 3.当NNactive、FC active 状态ok ,与ZK访问不通、锁断开、FC Standby 1.抢锁 2.访问原来的NNactive状态,发现不通,处于脑裂,这种问题基本属于网络设计问题
4.HDFS-HA解决方案
CAP原则:
- 一致性 : 多个节点数据是一致的
- 可用性 : 每个节点数据都是可用的
- 分区容忍性 : 当某一节点挂掉时,允许服务可用,可以往其他节点写入
注意
- 分布式:强一致性破坏可用性,就是其中一台挂掉,那么其他就必须阻塞,不能写入数据。
ZK和JN区别
- zk和JN技术相同 但是解决不同问题
- zk解决选主、加锁问题
- JN解决多台机器数据同步问题
解决NN压力过大、内存受限问题
元数据分治,复用DN存储 元数据访问隔离性 DN目录隔离block
比如:a部门、b部门、c部门。
1.正常情况下,我们提供一个接口,所有部门都访问一个NN,造成改NN压力过大。
2.我们可以在搞三台NN分别:NNA、NNB、NNC,每个部门一个NN,在datanode里面建设三个文件目录,用来隔离部门之间不同的数据。
3.如果再来一个部门,需要查看所有部门的数据,我们可以在所有NN之上抽象一层,只需遍历对应NN,就可以查询所有数据
