决策树
1.简介
决策树(decision tree):是一种基本的分类与回归方法
决策树学习的目标:根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类
决策树学习的本质:从训练集中归纳出一组分类规则,或者说是由训练数据集估计条件概率模型
决策树学习的损失函数:正则化的极大似然函数
决策树学习的测试:最小化损失函数
决策树学习的目标:在损失函数的意义下,选择最优决策树的问题
决策树原理和问答猜测结果游戏相似,根据一系列数据,然后给出游戏的答案
2.决策树通常有三个步骤:
特征选择、决策树的生成、决策树的修剪
3.信息增益
划分数据集的大原则是:将无序数据变得更加有序
在划分数据集前后信息发生的变化称为信息增益
集合信息的度量方式称为香农熵,或者简称熵
熵定义为信息的期望值,如果待分类的事物可能划分在多个类之中,则符号xi
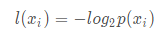
熵
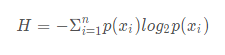
经验熵(empirical entropy)
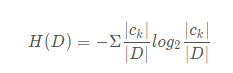
条件熵
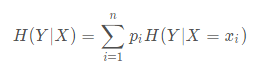
信息增益:信息增益是相对于特征而言的
特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即:
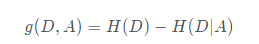
一般地,熵H(D)与条件熵H(D|A)之差成为互信息(mutual information)
信息增益比:特征A对训练数据集D的信息增益比gR(D,A) 与训练数据集D的经验熵之比
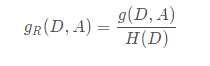
4.决策树的构建
ID3算法:
ID3算法的核心是在决策树各个结点上对应信息增益准则选择特征,递归地构建决策树
1)从根结点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征
2)由该特征的不同取值建立子节点,再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止
3)最后得到一个决策树。
C4.5的生成算法:
将信息增益比作为选择特征的标准

 浙公网安备 33010602011771号
浙公网安备 33010602011771号