深度学习中的正则化
1.深度学习中的正则化
提高泛化能力,防止过拟合
大多数正则化策略都会对估计进行正则化,估计的正则化以偏差的增加换取方差的减少
正则化方法是在训练数据不够多时,或者over training时,常常会导致过拟合(overfitting)。这时向原始模型引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称
2.参数范数惩罚
许多正则化方法通过对目标函数 J 添加一个参数范数惩罚 Ω(θ),限制模型(如神经网络、线性回归或逻辑回归)的学习能力。我们将正则化后的目标函数记为
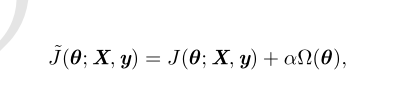
其中 α ∈ [0,∞) 是权衡范数惩罚项 Ω 和标准目标函数 J(X;θ) 相对贡献的超参数。将 α 设为 0 表示没有正则化。α 越大,对应正则化惩罚越大
神经网络中我们通常只对每一层仿射变换的权重做惩罚而不对偏置做正则惩罚
L 2 参数正则化
权重衰减(weight decay)的 L 2 参数范数惩罚
向目标函数添加一个正则项 Ω(θ) =1/2(||w||2)2使权重更加接近原点

L 1 参数正则化
对模型参数 w 的 L 1 正则化被定义为
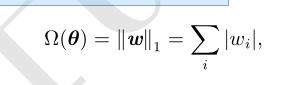
对应的梯度 (实际上是次梯度)
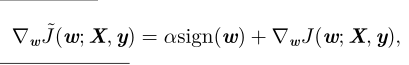
weights = tf.constant([[1., -2.], [-3., 4.]])
with tf.Session() as sess:
print(sess.run(tf.contrib.layers.l1_regularizer(0.5)(weights)))
# (1+2+3+4)*.5 ⇒ 5
print(sess.run(tf.contrib.layers.l2_regularizer(0.5)(weights)))
# (1+4+9+16)*.5*.5 ⇒ 7.5
3.作为约束的范数惩罚
4.Dropout
tf.nn.dropout是TensorFlow里面为了防止或减轻过拟合而使用的函数,它一般用在全连接层
tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None,name=None)
改变神经网络本身的结构
对于同一组训练数据,利用不同的神经网络训练之后,求其输出的平均值可以减少overfitting
5.数据集增强
6.提前终止

 浙公网安备 33010602011771号
浙公网安备 33010602011771号