容量、过拟合和欠拟合
1.泛化
在先前未观测到的输入上表现良好的能力被称为泛化(generalization)
2.训练误差(training error)
在训练集上计算的误差
3.泛化误差(generalization error)(也被称为测试误差(test error))
在测试集上计算的误差
线性回归示例
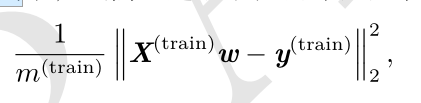
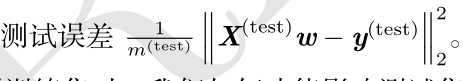
4.数据生成分布(data generating distribution),记作 p data
测试数据集和训练数据集独立同分布
5.决定机器学习算法效果是否好的因素
降低训练误差
缩小训练误差和测试误差的差距
欠拟合(underfitting)和过拟合(overfitting)
欠拟合是指模型不能在训练集上获得足够低的误差。而过拟合是指训练误差和和测试误差之间的差距太大
6.最近邻回归
7.贝叶斯误差(Bayes error)
从预先知道的真实分布 p(x,y) 预测而出现的误差
8.模型的容量是指其拟合各种函数的能力
学习算法可以从哪些函数族中选择函数。这被称为模型的表示容量(representational capacity)
9.正则化
权重衰减(weight decay)
带权重衰减的线性回归最小化训练集上的均方误差和正则项的和 J(w),其偏好于平方L 2 范数较小的权重

正则化是指我们修改学习算法,使其降低泛化误差而非训练误差

 浙公网安备 33010602011771号
浙公网安备 33010602011771号