

SQL:窗口函数
通常我们提到SQL函数都能根据名字对函数功能猜个大概,但想必很多人第一次听到窗口函数的时候都是有点蒙圈,不知所云,而实际了解过后,叫窗口函数听起来有点变扭,但也还算说的过去。
通常情况下,SQL操作数据是基于同行(row)或者同列(column)的。无论是where条件还是还是函数聚合,默认都是同一行的不同列,或者是同一列的不同行进行。而现实的数据分析需求很大一部分都是要基于“前因后果”的,因此在数据整合的操作过程中,就无法避免要面对“位移”的逻辑处理,所谓位移就是参考点和观察点的偏移量。比如,我们在做留存分析时,通常会非常关注日注册用户的留存率,例如1-7日留存率(如下表),也就是用户注册后过1天、2天....到第7天里,每一天还剩多少比例的活跃(即有过登录或浏览)用户量。
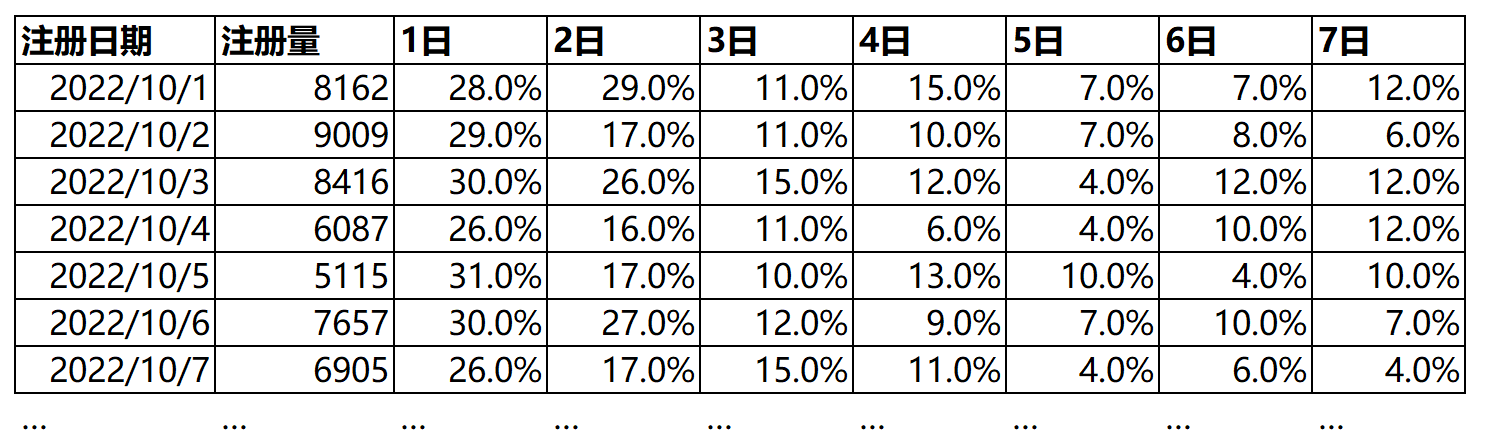
对于上表的统计,用常规的SQL语法就显得非常的力不从心了,想想就头大,我们需要把行为日志表进行多次自拼接,来计算注册时间与后续的活跃行为的时间差值,从而确定是否是对应日期的活跃留存。这种类型的统计在数据分析非常普遍,如果用寻常的SQL语句实现起来非常冗长反复,相似的步骤重复多次才能实现,无论是脚本编写还是脚本的运行都耗时耗力。此时想必很多人就想考虑用其他办法来实现数据的整合,比如用python程序迭代,而即便如此,且不说时效,就过程而言显得就不那么流畅了(相当于要维护两套系统),而过程的流畅性对后期的数据报表修改和维护是多么的重要,但凡经历过的数据分析师都懂!而窗口函数就是专门解决这类问题,虽然窗口函数很吃内存,在时效上感觉提升不是太大,但是脚本的简洁度、过程流畅性,几乎说是完美。
前面废话了那么多,开始正题吧!
窗口函数实际上分两个部分,即函数和开窗。
通常情况下无论是查现成的库表、还是执行select语句得到的都是没有内部位置关系的二维表。所谓内部位置关系,即系统底层不存储这个二维表的行与行之间的位置关系,自然无法实现跨行之间的运算;而窗口函数的开窗部分则是专门用来指明行与行之间的位置关系,而函数部分则是指定运算方式。
先假定一张订单表,表名为 order_detail ;字段为 ( acount_id ,用户账户id, user_id 用户id, product 产品类型 ,amount 订单金额,paid_time 支付时间,utmsource 订单渠道)
如下就是窗口函数的一般格式:

第1部分是函数类型,函数根据over后面的开窗限制,把数据汇总到当前行;
第2、3、4部分放在一个括号内,为一个整体即开窗部分,定义视窗样式,分别为:
第2部分PARTION BY:按指定的字段分组,可以指定多个字段,类似group by 的作用,但是partion by 只作分组、不改变原表行数,group by则是分组聚合;
第3部ORDER BY:基于PARTION BY 的分组,在各组内按指定的字段依次排序,默认asc升序,可使用desc 改为降序;
第4部分则是指定函数的作用范围,这部分也叫窗口子句(截取窗口),表示基于当前行往上以及往下框定一个区间范围,这个范围限定不局限与分组内部,可以贯通整个二维表。
从2、3、4 部分看,所谓的开窗就是通过 分组 + 排序 + 范围限定(窗口子句) 来定义二维表内部行与行之间的位置关系,就像体育课上男女分列、高矮排队一样,一旦这种分组排序完成,每个人之间的前后关系就确定了。具体可以理解为partion by 把原二维表(即一个整体的view)按规则划分成n个区块,order by 则在每个区块内进行排序确定前后关系,而窗口子句则是进一步给定一个灵活的范围切片,三个步骤是逐次完成的。开窗并不改变原二维表的行列数量,而是根据数据本身给定一个行与行之间的排列关系,就像二维表的行列标签一样,从而实现行与行之间的数据操作。
以下是 窗口子句“ROWS BETWEEN AND ”几种组合形式的含义:
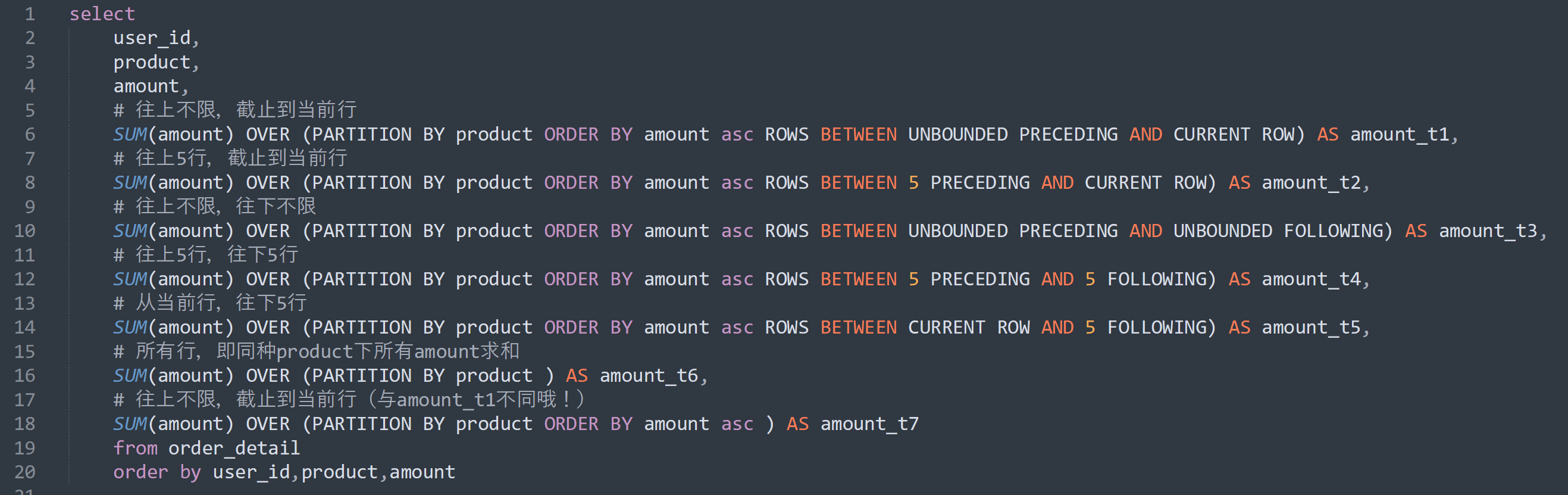
其中第6行amount_t1和第18行amount_7的结果是不同的,开窗的三个部分对函数的结果都有之接的影响,具体需要小伙伴自己去验证了,会有意想不到的收获哦!
窗口子句ROWS BETWEEN AND 的关键字含义 :
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:无界限(起点或终点)
UNBOUNDED PRECEDING:表示从前面的起点
UNBOUNDED FOLLOWING:表示到后面的终点
常用的窗口函数:
1、聚合函数类:sum/count/max/min/avg/median...等 都可以作为窗口函数使用,调用逻辑与通常无差别,只是在开窗给定的范围内作聚合,
如下表:统计订单月销售金额及截止到各有的累计销售金额。
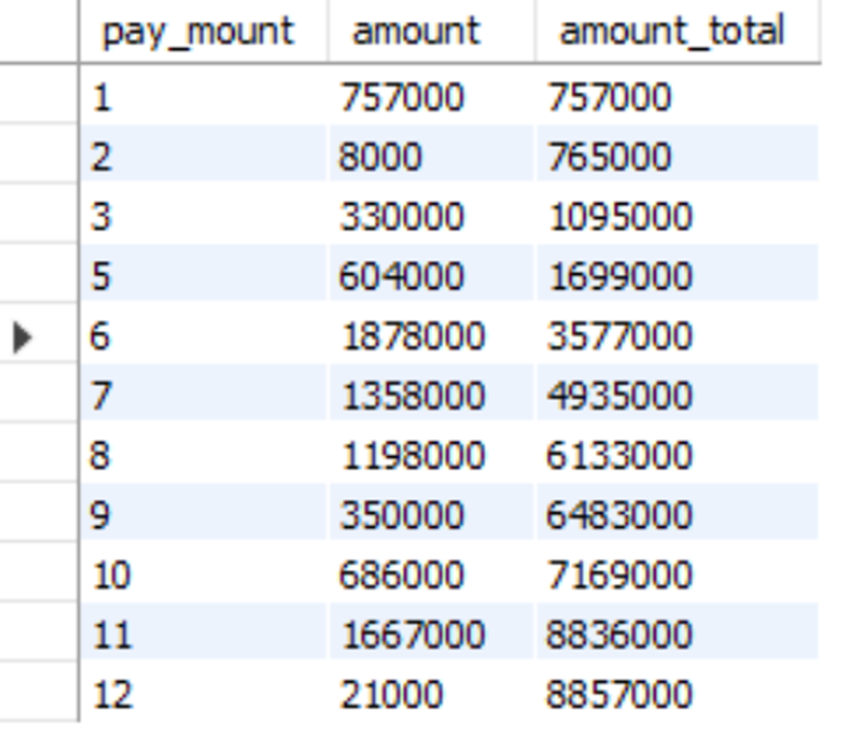
SQL如下:
select month(pay_time) pay_mount, sum(amount) amount, sum(sum(amount )) OVER (ORDER BY month(pay_time) asc ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS amount_total from order_detail group by pay_mount order by pay_mount
并且可以在聚合函数内进一步使用case when 等条件语句,如:
count(case when amount>10000 then amount else null end ) OVER (PARTITION BY product ORDER BY amount asc ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS amount_cnt # MySQL8.0支持窗口函数,但是MySQL的窗口函数貌似不支持distinct,感兴趣的可以自行验证一下。
2、FIRST_VALUE(col):取分组内排序后,截止到当前行,col列的第一个值
3、LAST_VALUE(col): 取分组内排序后,截止到当前行,col列的最后一个值
4、LEAD(col,n,DEFAULT) :取窗口内 col列往下第n(默认1)行的值,第三个参数为给定默认值,即当往下第n行为NULL时候,取默认值,如不指定,则为NULL。
5、LAG(col,n,DEFAULT) :与lead相同,区别是往上第n行值。可以通过改变排序方式,让两个函数得到相同的效果。
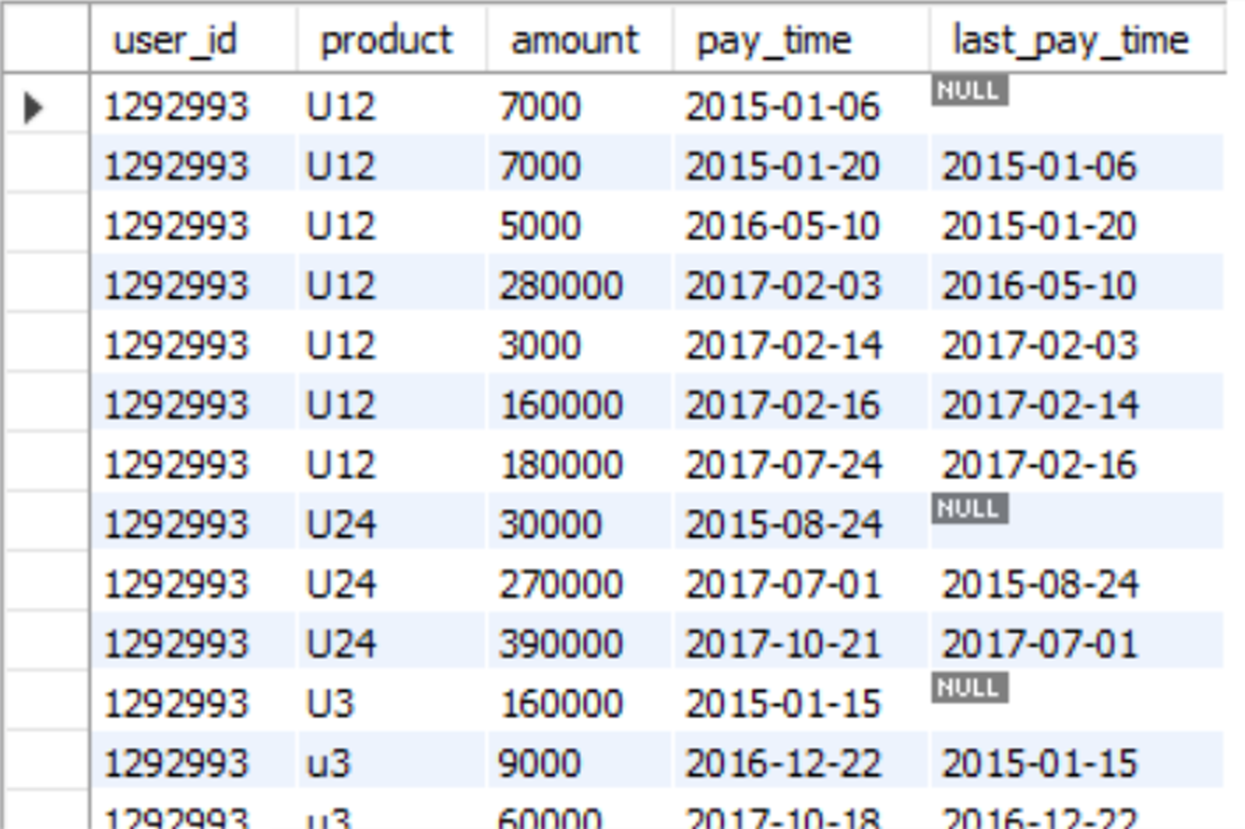
LEAD与LAG 函数在数据分析上使用非常频繁,如计算两个事件之间的时差,对比类型关系等,如下通过对同类产品的分组,获取pay_time 和last_pay_time,计算用户在相邻两次购买同类产品的日期差,从而进一步分析用户在产品上的使用频率和消费习惯,为产品运营提供支持。
select user_id,product,amount,pay_time,
lag(pay_time) over (PARTITION BY user_id,product ORDER BY pay_time ) last_pay_time from order_detail
order by user_id,product
结果如下:
分析函数:
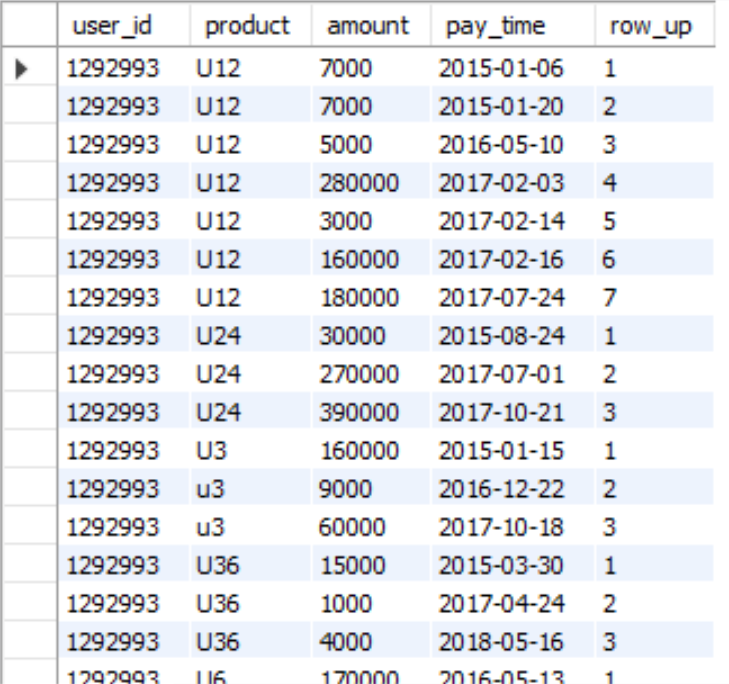
6、ROW_NUMBER(): 给二维表生成一个排序字段,排序的方式为分别在每个组内从1开始生成排序记录。这应该是使用频率最高的窗口函数,有了这个排序字段,就可以使用常规函数对数据进行各种需要的操作,比如取用户首次/末次消费产品时间,类型等。比如:
select user_id,product,amount,pay_time, row_number() over (PARTITION BY user_id,product ORDER BY pay_time ) row_up from order_detail order by user_id,product
输出结果:
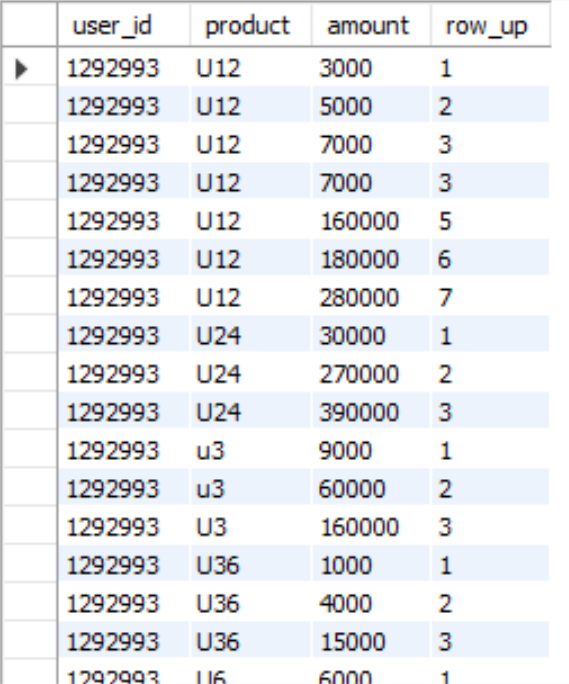
7、RANK(): 生成数据项在分组中的排名,排名相同名次并列,且名次中留下空位
rank() over (PARTITION BY user_id,product ORDER BY amount ) rank
输出结果:
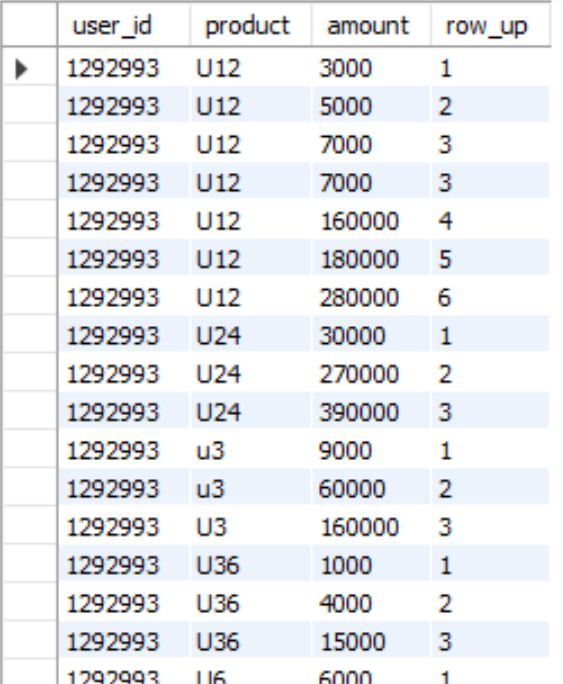
8、DENSE_RANK(): 在分组生成排名数据项,排名相同名次并列,名次中不会留下空位
dense_rank() over (PARTITION BY user_id,product ORDER BY amount ) ds_rank
输出结果:
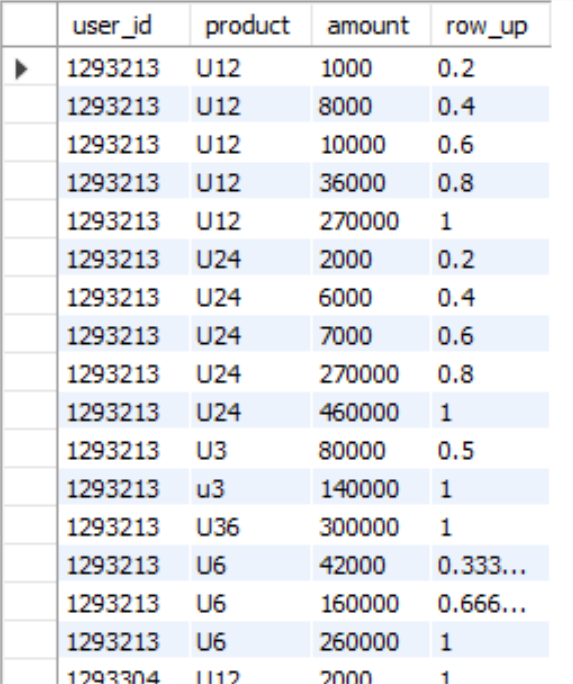
9、CUME_DIST :行数/分组内总行数,相当于百分位。比如,统计小于等于当前薪水的人数,所占总人数的比例
cume_dist() over (PARTITION BY user_id,product ORDER BY amount) c_dist
输出结果:
10、PERCENT_RANK(): 计算当前行的百分比排名,分组内当前行的RANK值-1/分组内总行数-1,不需要参数。
select user_id,product,amount,pay_time, perent_rank() over (PARTITION BY user_id,product ORDER BY pay_time ) p_rank from order_detail order by user_id,product
输出结果:
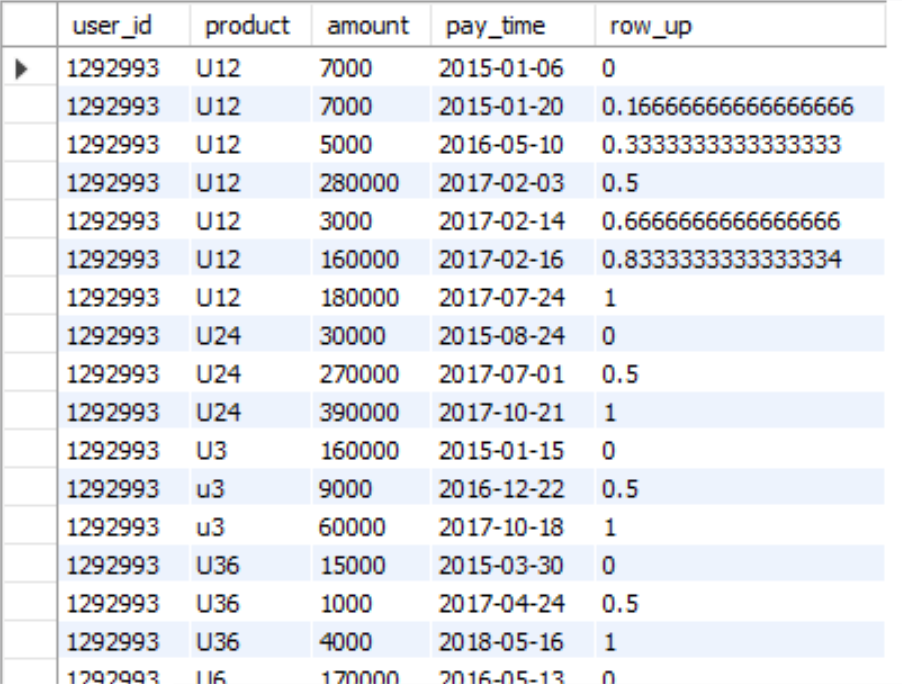
NTILE(n) :用于将分组数据均匀切片分n组,生成一个分组字段,每组依次标注1-n的序号,返回当前切片值,如果切片不均匀,默认增加第一个切片的分布,常用来随机抽样。
NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)。

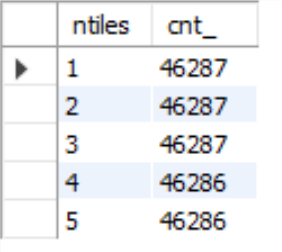
select ntiles,count(1) cnt_ from (select user_id,roduct,amount,
# 随机分成5组
ntile(5) over (order by rand() ) ntiles from order_detail ) a group by ntiles
输出结果:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具