53.1 Django 模型层(models) 复杂查询详解
一般Django orm 和原生sql混合使用
1.测试文件
只单独测试django中的某一个py文件 不一定是tests.py
1.配置
在任意一个py文件中书写以下代码 应用下的tests 或者自己新建一个 import os if __name__ == "__main__": os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day53.settings") import django django.setup()
2. 解释 所有的测试脚本(from app01 import models) 必须写在配置好的文件最下方
注意 只要是queryset对象就可以无限制的调用queryset对象的方法
res = models.User.objects.filter(**kwargs).filter().filter().update()/delete()/values()
2.单表查询16太保
1. 单表查询- -16太保
注: queryset对象:列表套对象 列表套字典 列表套元组 object是单个对象
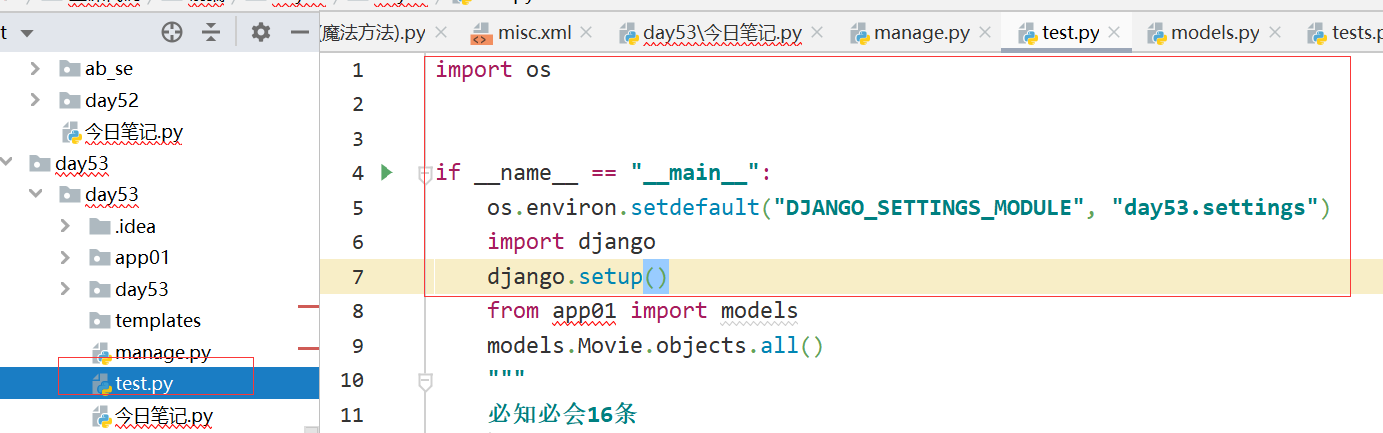
所有的querset对象都可以通过.query的形式 查询原生sql语句 :res = models.Movie.objects.all() res.query
import os
if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day53.settings")
import django
django.setup()
from app01 import models
""" 必知必会16条 1.create() 创建 2.all() 查询所有 3.filter() 过滤 4.update() 更改 5.delete() 删除 6.first() 数据对象 7.last() 数据对象 8.get() 直接获取数据对象本身 9.values() querset对象 列表套字典 10.values_list() value_list('title','price') qeryset对象 取对象的指定字段 列表套元组 11.order_by() 排序 12.count() 计数 13.exclude() 排除 14.exists() 存在 返回布尔类型 15.reverse() 反转 排序 数字 字母 16.distinct() 去重 """ # 1.create() 返回值就是当前被创建数据的对象本身 # 日期可以手动给 # models.Movie.objects.create(title='3D肉蒲团s',price=999.23,publish_time='2016-1-1') # 还可以直接传日期对象 # from datetime import date # ctime = date.today() # models.Movie.objects.create(title='西游记', price=666.23, publish_time=ctime) # 2.all() queryset对象 # res = models.Movie.objects.all() # print(res) # 3.filter() queryset对象 # res = models.Movie.objects.filter(id=1) # res = models.Movie.objects.filter(pk=1) # pk指代的就是当前表的主键字段名 自动查找非常方便 # res = models.Movie.objects.filter(pk=1,title='python入门') # 括号内可以放多个条件默认是AND关系 **************新知识点***************** # # 只要是queryset对象 就可以通过 点query 的方式查看到获取到当前对象内部sql语句 # print(res.query) # 4.get() 直接获取对象本身 不推荐使用 当查询条件不存在的时候直接报错 # res = models.Movie.objects.get(pk=1) # print(res) # print(res.title) # print(res.price) # res = models.Movie.objects.get(pk=1000) # res = models.Movie.objects.filter(pk=1000) # print(res) # 5.values() QuerySet对象 [{},{},{}] 获取指定字段对的数据 列表套字典 # res = models.Movie.objects.values('title','publish_time') # print(res) # print(res.query)
# 6.values_list() QuerySet对象 [(),(),()] 获取指定字段对的数据
# res = models.Movie.objects.values_list('title','price')
# print(res)
# 7.first() 数据对象 取第一个元素对象 # res = models.Movie.objects.filter().first() # print(res) # 8.last() 数据对象 取最后一个元素对象 # res = models.Movie.objects.last() # print(res)
# 9.update() 更新数据 返回值是受影响的行数
# res = models.Movie.objects.filter(pk=1).update(title='金瓶2')
# res = models.Movie.objects.filter(pk=1).update(title='金瓶2',price=666)
# print(res)
# 10.delete() 删除数据 返回值(1, {'app01.Movie': 1}) 受影响的表及行数
# res = models.Movie.objects.filter(pk=3).delete()
# print(res)
# 11.count() 统计数据条数
# res = models.Movie.objects.count()
# print(res)
# 12.order_by 按照指定字段排序
# res = models.Movie.objects.order_by('price') # 默认是升序
# res = models.Movie.objects.order_by('-price') # 减号就是降序
# print(res)
# 13.exclude() 排除什么什么之外 少选条件
# res = models.Movie.objects.exclude(pk=1)
# print(res)
# 14.exists() 返回的是布尔值 判断前面的对象是否有数据 了解即可
# res = models.Movie.objects.filter(pk=1000).exists()
# print(res)
# 15.reverse() 反转
# res = models.Movie.objects.order_by('price').reverse()
# print(res)
# 16.distinct() 去重:去重的前提 必须是由完全一样的数据的才可以
# res = models.Movie.objects.values('title','price').distinct()
# print(res)
2.双下划线查询: filter(字段__条件)
# 神奇的双下划线查询
# 1.查询价格大于200的电影
# res = models.Movie.objects.filter(price__gt=200)
# print(res)
# 2.查询价格小于500的电影
# res = models.Movie.objects.filter(price__lt=500)
# print(res)
# 3.查询价格大于等于876.23的电影 #python的精确度不够,后面会解决
# res = models.Movie.objects.filter(price__gte=876.23)
# print(res.query)
# 4.查询价格小于等于876.23的电影
# res = models.Movie.objects.filter(price__lte=500)
# print(res)
# 5.查询价格是123 或666 或876
# res = models.Movie.objects.filter(price__in=[123,666,876])
# print(res)
# 6.查询价格在200到900之间的电影 顾头也顾尾
# res = models.Movie.objects.filter(price__range=(200,900))
# print(res)
# 7.查询电影名中包含字母p的电影
"""
模糊查询:
关键字 like
关键符号
%
_
"""
# res = models.Movie.objects.filter(title__contains='p') # 默认是区分大小写
# res = models.Movie.objects.filter(title__icontains='p') # i忽略大小写
# print(res)
# 8.查询2014年出版的电影
# res = models.Movie.objects.filter(publish_time__year=2014)
# print(res)
# 9.查询是1月份出版的电影
# res = models.Movie.objects.filter(publish_time__month=1)
# print(res)
3.多表查询
补一张关系图
1.外键字段的增删改查 没有正反向的概念 直接通过外键字段的方式操作
注意:一对多 添加表关系没有(add,remove,set(1,),clear)方法 ,只有多对多创建外键关系才有
# 一对多 对比多对多 book_obj.authors.add(1,2) # 1.增 直接写实际的表字段 publish_id # models.Book.objects.create(title='三国演义',price=123.23,publish_id=2) # 2.增 写对象 # publish_obj = models.Publish.objects.get(pk=1) # models.Book.objects.create(title='金瓶',price=66.66,publish=publish_obj) # 查 # 改 # models.Book.objects.filter(pk=1).update(publish_id=3) # publish_obj = models.Publish.objects.get(pk=4) # models.Book.objects.filter(pk=1).update(publish=publish_obj) # 删 """ 外键字段在1.X版本中默认就是级联更新级联删除的 2.X版本中 则需要你自己手动指定 百度一大堆 """ # 多对多 add remove
两种方式 1.'对象.虚拟字段.add(主键值)':book_obj.athoutros.add(1)
2. ‘对象.虚拟字段.add(obj1,obj2)’ # 1 给书籍绑定作者关系 add # book_obj = models.Book.objects.filter(pk=1).first() # 书籍和作者的关系是由第三张表绝对 也就意味着你需要操作第三张表 # print(book_obj.authors) # book_obj.authors.add(1) # 给书籍绑定一个主键为1的作者 # book_obj.authors.add(2,3) # author_obj = models.Author.objects.get(pk=1) # author_obj1 = models.Author.objects.get(pk=3) # book_obj.authors.add(author_obj) # book_obj.authors.add(author_obj,author_obj1) """ add专门给第三张关系表添加数据 括号内即可以传数字也可以传对象 并且都支持传多个 """ # 2 移除书籍与作者的绑定关系 remove # book_obj = models.Book.objects.filter(pk=1).first() # book_obj.authors.remove(2) # book_obj.authors.remove(1,3) # author_obj = models.Author.objects.get(pk=2) # author_obj1 = models.Author.objects.get(pk=3) # book_obj.authors.remove(author_obj) # book_obj.authors.remove(author_obj,author_obj1) """ remove专门给第三张关系表移除数据 括号内即可以传数字也可以传对象 并且都支持传多个 """ # 3 修改书籍与作者的关系 set # book_obj = models.Book.objects.filter(pk=1).first() # # book_obj.authors.set((3,)) # # book_obj.authors.set((2,3)) # author_obj = models.Author.objects.get(pk=2) # author_obj1 = models.Author.objects.get(pk=3) # # book_obj.authors.set((author_obj,)) # book_obj.authors.set([author_obj,author_obj1]) """ set 修改书籍与作者的关系 set 有则修改,无则新增 括号内支持传数字和对象 但是需要是可迭代对象 """ # 4 清空书籍与作者关系 # book_obj = models.Book.objects.filter(pk=1).first() # book_obj.authors.clear() # 去第三张表中清空书籍为1的所有数据 """ clear() 清空关系 不需要任何的参数 """
2.跨表查询(******)
# 书籍对象点虚拟字段authors就类似于已经跨到书籍和作者的第三张关系表中
""" 跨表查询的方式 1.子查询 将一张表的查询结果当做另外一张表的查询条件 正常解决问题的思路 分步操作 2.链表查询 inner join left join right join union 建议:在写sql语句或者orm语句的时候 千万不要想着一次性将语句写完 一定要写一点查一点再写一点 正反向的概念 正向 跨表查询的时候 外键字段是否在当前数据对象中 如果在 查询另外一张关系表 叫正向 反向 如果不在叫反向 口诀 正向查询按外键字段 正向查不需要_set 反向查询按表名小写_set set为集合的意思,一对多,多对多 查询的结果有多个要加_set
一对一查出的结果只有一个 不需要_set
"""
1.基于对象的跨表查询(子查询) book_obj.publish 直接得到书的出版社对象
# 基于对象的跨表查询(子查询)
正向查询
# 1.查询书籍pk为1的出版社名称 一对多 对比 多表联查 models.Book.objects.filter(pk=1).vlalues(‘publish__name’) # book_obj = models.Book.objects.filter(pk=1).first() # print(book_obj.publish) 直接的 # print(book_obj.publish.name) # print(book_obj.publish.addr)
# 2.查询书籍pk为2的所有作者的姓名 多对多 # book_obj = models.Book.objects.filter(pk=2).first() # # print(book_obj.authors) # app01.Author.None # print(book_obj.authors.all()) # author_list = book_obj.authors.all() # for author_obj in author_list: # print(author_obj.name) # 3.查询作者pk为1的电话号码 一对一 # author_obj = models.Author.objects.filter(pk=1).first() # print(author_obj.author_detail) # print(author_obj.author_detail.phone) # print(author_obj.author_detail.addr) """ 正向查询的时候 当外键字段对应的数据可以有多个的时候需要加.all() 否则点外键字典即可获取到对应的数据对象 """
反向查询
# 4.查询出版社名称为东方出版社出版过的书籍 一对多 # publish_obj = models.Publish.objects.filter(name='东方出版社').first() # print(publish_obj.book_set) # app01.Book.None # print(publish_obj.book_set.all())
# 5.查询作者为jason写过的书 多对多 # author_obj = models.Author.objects.filter(name='jason').first() # print(author_obj.book_set) # app01.Book.None # print(author_obj.book_set.all()) # 6.查询手机号为120的作者姓名 一对一 # author_detail_obj = models.AuthorDetail.objects.filter(phone=120).first() # print(author_detail_obj.author) # print(author_detail_obj.author.name) # print(author_detail_obj.author.age) """ 基于对象的反向查询 表名小写是否需要加_set.all() 一对多和多对多的时候需要加 一对一不需要 """
2.基于双划线的跨表查询(链表查询)
基本语法:正向按外键字段 反向按表名小写(book_set.all())
正向:res = models.Book.objects.filter(pk=1).values('publish__name') #写外键字段的时候就已经到了publish表
反向:res= models.Publish.objects.filter(book__pk=1) #写表名的时候就已经跨到了book表
res = models.Author.objects.filter(book__pk=1).values('name','age','book__title')
# 基于双下划线跨表查询(链表查询) # 1.查询书籍pk为1的出版社名称 一对多 # 正向 # res = models.Book.objects.filter(pk=1).values('publish__name') # 写外键字段 就意味着你已经在外键字段管理的那张表中 # print(res) # 反向 # res = models.Publish.objects.filter(book__pk=1) # 拿出版过pk为1的书籍对应的出版社 # res = models.Publish.objects.filter(book__pk=1).values('name') # print(res) # 2.查询书籍pk为1的作者姓名和年龄 多对多 # 正向 # res = models.Book.objects.filter(pk=1).values('title','authors__name','authors__age') # print(res) # 反向 # res = models.Author.objects.filter(book__pk=1) # 拿出出版过书籍pk为1的作者对象 # res = models.Author.objects.filter(book__pk=1).values('name','age','book__title') # print(res) # 3.查询作者是jason的年龄和手机号 一对一 # 正向 # res = models.Author.objects.filter(name='jason').values('age','author_detail__phone') # print(res) # 反向 # res = models.AuthorDetail.objects.filter(author__name='jason') # 拿到jason的个人详情 # res = models.AuthorDetail.objects.filter(author__name='jason').values('phone','author__age') # print(res) # 查询书籍pk为的1的作者的手机号 三表联查 # res = models.Book.objects.filter(pk=1).values('authors__author_detail__phone') # print(res) # res = models.AuthorDetail.objects.filter(author__book__pk=1).values('phone') # print(res) """ 只要表之间有关系 你就可以通过正向的外键字段或者反向的表名小写 连续跨表操作 """
3.聚合查询 aggregate ( Max Min Avg Count Sum)
models.Book.objects.aggregate(Avg('price')
from django.db.models import Max,Min,Avg,Count,Sum # 查询所有书的平均价格 # res = models.Book.objects.aggregate(avg_num=Avg('price')) # print(res) # 查询价格最贵的书 # res = models.Book.objects.aggregate(max_num=Max('price')) # print(res) # 全部使用一遍 # res = models.Book.objects.aggregate(Avg("price"), Max("price"), Min("price"),Count("pk"),Sum('price')) # print(res)
4. 分组查询 annotate(默认按表名分组) 多练习以下习题
# 1.统计每一本书的作者个数 按Book分组 # res = models.Book.objects.annotate(author_num=Count('authors')).values('title','author_num') # print(res) # 2.统计出每个出版社卖的最便宜的书的价格 # res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name','min_price','book__title') # print(res) # 3.统计不止一个作者的图书 # res = models.Book.objects.annotate(author_num=Count('authors')).filter(author_num__gt=1).values('title') # print(res) # 4.查询各个作者出的书的总价格 # res = models.Author.objects.annotate(price_sum=Sum('book__price')).values('name','price_sum') # print(res) # 5.如何按照表中的某一个指定字段分组 """ res = models.Book.objects.values('price').annotate() 就是以价格分组 """
5.F与Q查询() 特例法记忆:F 同一张表中的字段相比 库存数大于卖出数 Q 改变条件关系
from django.db.models import F,Q # 1.查询库存数大于卖出数的书籍 # res = models.Book.objects.filter(kucun__gt=F('maichu')) # print(res) # 2.将所有书的价格提高100 # res = models.Book.objects.update(price=F('price') + 100) """ 帮你获取到表中某个字段对应的值 """ # Q能够改变查询的条件关系 and or not # 1.查询书的名字是python入门或者价格是1000的书籍 # res = models.Book.objects.filter(title='python入门',price=1000) # and关系 # res = models.Book.objects.filter(Q(title='python入门'),Q(price=1000)) # 逗号是and关系 # res = models.Book.objects.filter(Q(title='python入门')|Q(price=1000)) # |是or关系 # res = models.Book.objects.filter(~Q(title='python入门')|Q(price=1000)) # ~是not关系 # print(res.query) # Q的高阶用法 如何实现 以下代码 字段title 为字符串 # res = models.Book.objects.filter('title'='python入门') #伪代码 q = Q() q.connector = 'or' # q对象默认也是and关系 可以通过connector改变or q.children.append(('title','python入门')) q.children.append(('price',1000)) res = models.Book.objects.filter(q) print(res)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号