
mysql 索引 慢查询优化 && 数据库性能优化
1. 为什么要使用索引
对一个应用来说,对数据库的读写比例基本上是10:1,即读多写少
而且对于写来说极少出现性能问题,大多数问题都是慢查询到加速查,就必须用索引
2. 什么是索引
索引相当于书的目录,是mysql一种专门的数据结构,称为key,
索引的本质不断的缩小查询范围来降低IO次数来提升性能
强调:一旦为表创建了索引,以后的查询就会先查索引,再根据定位的结果查询数据
pramary key / uique key / index key
3.索引的影响
1.在表中有大量数据的情况下,创建索引的速度会很慢,一般在创建表的时候,预测哪个字段使
用频率较高创建索引
2.创建索引后,查询效率会大幅提升,但是写入的效率会降低
4.聚集索引(primary key)
特点:叶子节点存放的一整条数据
5.辅助索引(unique,index)
特点: 如果按照名字这个节点创建索引 那么叶子节点存放的是{名字:名字所在那条记录的主键值} 覆盖索引: 只在辅助的叶子节点中就找到了我们想要的数据 select name from where name=’egon‘ select sex from where name = ’egon‘
6.创建索引
alter table student add primary key(id)
create index index_name on student(name)
7.索引原理(B+树)
原理:
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。 通过减少IO来优化查询效率
相似的例子还有:查字典,查火车车次,飞机航班等
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,
也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
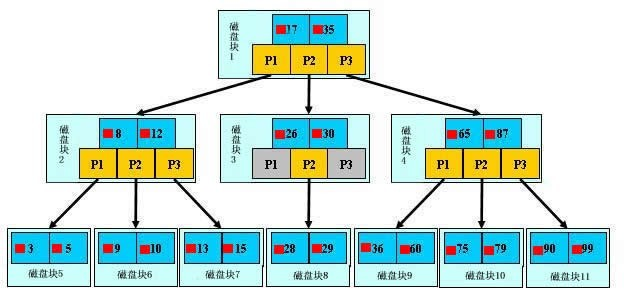
索引的数据结构(B+树): 类似二分法
结构:根节点/树干节点/叶子节点 叶子节点存放真实数据
层级称为树的高度: 高度越低 IO次数越少
b+树的特性:
1.索引字段要尽量的小
2.索引的最左匹配特性: name like '%xxx' 索引无效 name like 'xxx%' 有效
如何使树的高度变低? 叶子节点以更少的磁盘块存放更多的数据项,存放的数据类型 字节越小越好 如:id int
适合建索引的字段:表字段区分度高,重复的少,适合建索引
不适合建索引的字段:如果区分度低树高度会变大 IO次数会变大 如: name字段重复量很大,树会变成单杆,变得很高
3.使用索引的注意点
- 避免使用select * - count(1)或count(列) 代替 count(*) - 创建表时尽量时 char 代替 varchar - 表的字段顺序固定长度的字段优先 - 组合索引代替多个单列索引(经常使用多个条件查询时) - 尽量使用短索引 - 使用连接(JOIN)来代替子查询(Sub-Queries) - 连表时注意条件类型需一致 - 索引散列值(重复少)不适合建索引,例:性别不适合
4.索引的正确使用
一. 索引未命中
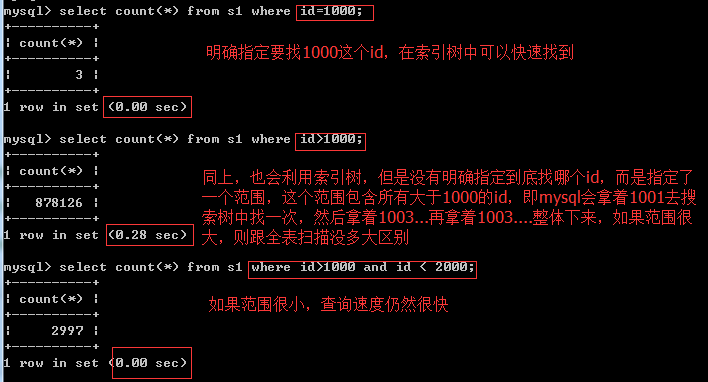
1. 范围问题,或者说条件不明确,条件中出现这些符号或关键字:>、>=、<、<=、!= 、between...and...、like、
范围很大和不加索引差不多
大于号/小于号
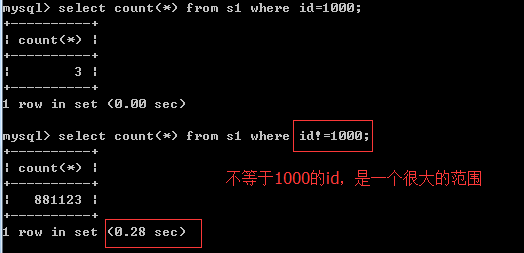
不等于!=
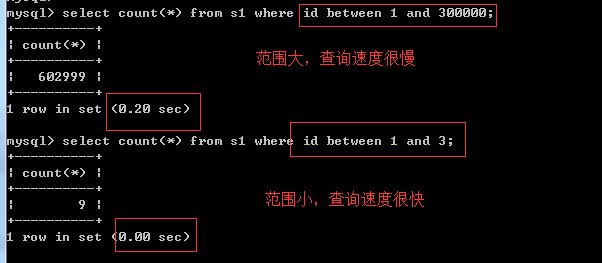
between ...and...
like
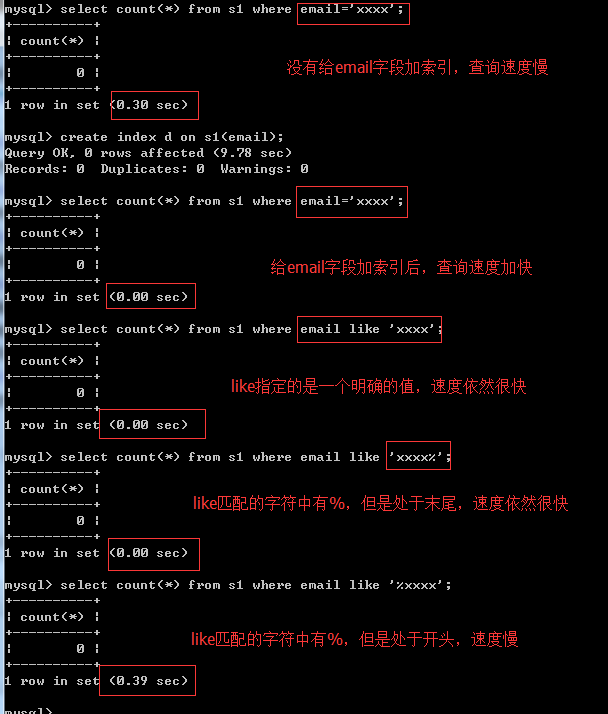
2 .尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,
而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录

原因:表中name叫作egon 的数据很多,区分度很低,name 为xxx的就一个区分度很高
and/or
#1、and与or的逻辑 条件1 and 条件2:所有条件都成立才算成立,但凡要有一个条件不成立则最终结果不成立 条件1 or 条件2:只要有一个条件成立则最终结果就成立 #2、and的工作原理 条件: a = 10 and b = 'xxx' and c > 3 and d =4 索引: 制作联合索引(d,a,b,c) 工作原理: 对于连续多个and:mysql会按照联合索引,从左到右的顺序找一个区分度高的索引字段(这样便可以快速锁定很小的范围),加速查询,即按照d—>a->b->c的顺序 #3、or的工作原理 条件: a = 10 or b = 'xxx' or c > 3 or d =4 索引: 制作联合索引(d,a,b,c) 工作原理: 对于连续多个or:mysql会按照条件的顺序,从左到右依次判断,即a->b->c->d
数据库性能优化
1.详解:https://blog.csdn.net/weixin_39106371/article/details/82117148
另有参考 http://my.oschina.net/xianggao/blog/87448 数据库性能优化之SQL语句优化2
http://my.oschina.net/xianggao/blog/87450 数据库性能优化之SQL语句优化3
http://my.oschina.net/xianggao/blog/87453 数据库性能优化之SQL语句优化4
http://my.oschina.net/xianggao/blog/87223 关于如何形成一个好的数据库设计
详解 简摘
1.数据库访问优化法则
要正确的优化SQL,我们需要快速定位能性的瓶颈点,也就是说快速找到我们SQL主要的开销在哪里?而大多数情况性能最慢的设备会是瓶颈点,如下载时网络速度可能会是瓶颈点,本地复制文件时硬盘可能会是瓶颈点,为什么这些一般的工作我们能快速确认瓶颈点呢,因为我们对这些慢速设备的性能数据有一些基本的认识,如网络带宽是2Mbps,硬盘是每分钟7200转等等。因此,为了快速找到SQL的性能瓶颈点,我们也需要了解我们计算机系统的硬件基本性能指标,下图展示的当前主流计算机性能指标数据
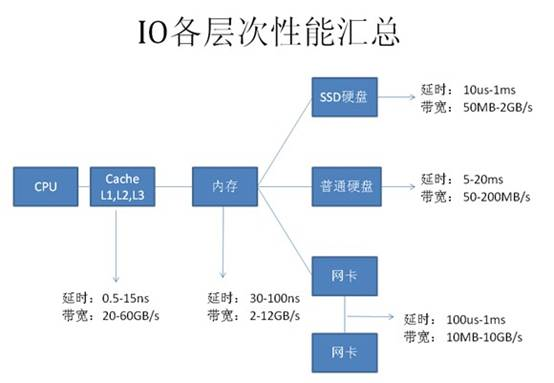
从图上可以看到基本上每种设备都有两个指标:
延时(响应时间):表示硬件的突发处理能力;
带宽(吞吐量):代表硬件持续处理能力。
必知数据据库优化---漏斗法则
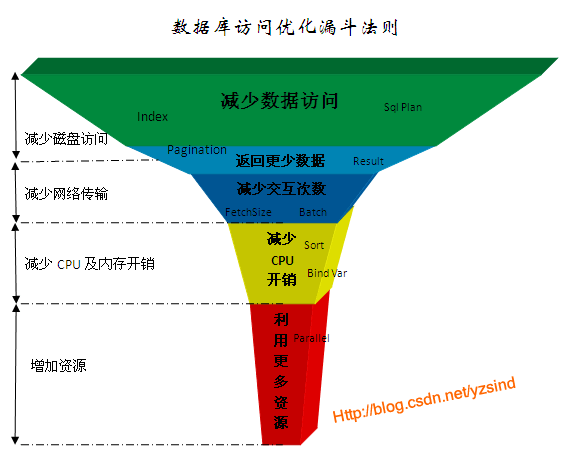
这个优化法则归纳为5个层次:
1、 减少数据访问(减少磁盘访问) index(索引) sql plan
2、 返回更少数据(减少网络传输或磁盘访问) 尽量避免使用select* 分页limit
3、 减少交互次数(减少网络传输) 接口能写在一起就写在一起 尽量减少请求次数 或者使用存储过程 Fetchsize Result
4、 减少服务器CPU开销(减少CPU及内存开销) Sort Bind Var 使用变量 减少与cpu的交互
5、 利用更多资源(增加资源)
sql语句优化
内连效率高,left jion 数据量少的在左边,减少数据量
where 与 having 尽量把数据在where 条件过滤掉之后再group by
业务优化:if then 语句 把数据量小的作为if的条件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号