socket--接受大数据
一、简单ssh功能
1.1 实现功能
在前面的一篇博客中,我们已经实现了一个简单的类似Linux服务器ssh功能的小程序,可以输入系统命令来返回命令运行结果,今天我们也以此开始,看看socket如何来接受大量数据。
服务端:


# -*- coding: UTF-8 -*- import os import socket server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # TCP/IP协议, tcp ,如果不填写就是默认这个 server.bind(('localhost', 9999)) server.listen() while True: # 可以接受多个客户端 conn, addr = server.accept() while True: data = conn.recv(1024) if not data: # 防止当接受的客户端数据为空时,程序卡掉 print('client has lost...') break print('执行命令:', data.decode()) cmd_res = os.popen(data.decode()).read() if len(cmd_res) == 0: print('command not found') else: # 发送数据 conn.send('{}'.format(cmd_res).encode('utf-8')) print('发送完成')
客户端:
# -*- coding: UTF-8 -*- import socket client = socket.socket() client.connect(('localhost', 9999)) while True: cmd = input('>>:').strip() # 判断是否发送空数据,如果是就重新发送 if len(cmd) == 0: continue else: client.send(cmd.encode('utf-8')) receive_data = client.recv(1024) # 接受的数据是bytes类型 print(receive_data.decode('utf-8', 'ignore')) # 不加ignore在windows有时会报错
运行结果:
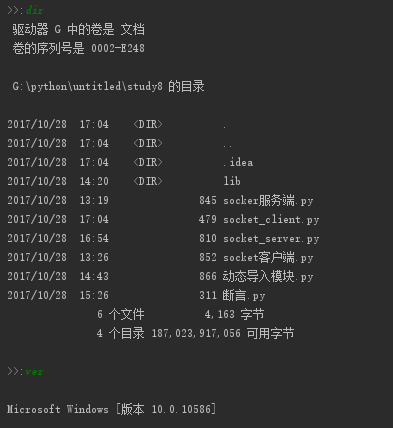
我们运行两个命令都是正常的,看起来不错,能实现命令的输入和结果的输出
1.2 出现的问题
我们接着往下看,会出现什么问题?既然是接收大量数据,那就返回的数据量大一些
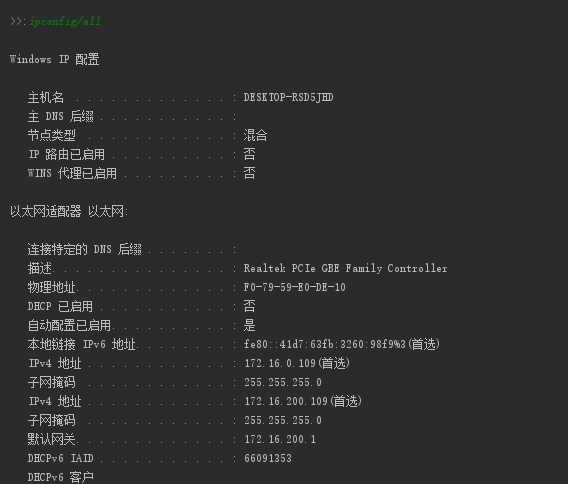
看上去也没有问题,但是我们接下来继续执行命令

显然出错了,命令dir返回的不是目录里面的信息,而是上一次ipconfig/all的部分信息,why?
二、Socket 缓冲区
2.1 什么是socket缓冲区
每个 socket 被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区。
write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP协议负责的事情。
TCP协议独立于 write()/send() 函数,数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。
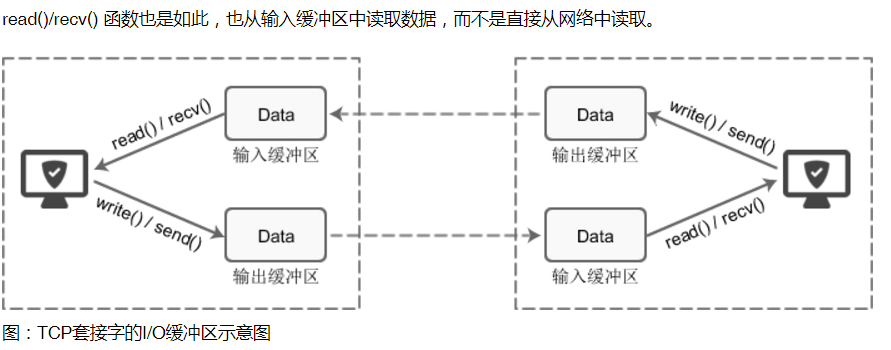
2.2 缓冲区收发数据
对于TCP套接字(默认情况下),当使用 write()/send() 发送数据时:
1) 首先会检查缓冲区,如果缓冲区的可用空间长度小于要发送的数据,那么 write()/send() 会被阻塞(暂停执行),直到缓冲区中的数据被发送到目标机器,腾出足够的空间,才唤醒 write()/send() 函数继续写入数据。
2) 如果TCP协议正在向网络发送数据,那么输出缓冲区会被锁定,不允许写入,write()/send() 也会被阻塞,直到数据发送完毕缓冲区解锁,write()/send() 才会被唤醒。
3) 如果要写入的数据大于缓冲区的最大长度,那么将分批写入。
4) 直到所有数据被写入缓冲区 write()/send() 才能返回。
当使用 read()/recv() 读取数据时:
1) 首先会检查缓冲区,如果缓冲区中有数据,那么就读取,否则函数会被阻塞,直到网络上有数据到来。
2) 如果要读取的数据长度小于缓冲区中的数据长度,那么就不能一次性将缓冲区中的所有数据读出,剩余数据将不断积压,直到有 read()/recv() 函数再次读取。
3) 直到读取到数据后 read()/recv() 函数才会返回,否则就一直被阻塞。
这就是TCP套接字的阻塞模式。所谓阻塞,就是上一步动作没有完成,下一步动作将暂停,直到上一步动作完成后才能继续,以保持同步性。
三、如何接受大量数据
3.1 解决思路
因为缓冲区的存在,我们在传输大量数据时不能一下子全部传输完毕!事实上和接受和发送数据量,即send(1024)/recv(1024)关系不大。并不是我们将这两个值设置的很大和可以解决问题了。因为socket每次接收和发送都有最大数据量限制的,毕竟网络带宽也是有限的呀,不能一次发太多,发送的数据最大量的限制 就是缓冲区能缓存的数据的最大量,这个缓冲区的最大值在不同的系统上是不一样的,不过官方的建议是不超过8k,也就是8192。
那么我们就只能从另一个角度来思考了,也就是说我要来判断一下,一个命令执行后,它返回的数据到底有没有完全传输完毕,如果没有,那么就继续传输,直到传完为止。
3.2 解决方法
简单的方法就是对比接收和传输数据量的大小,如果接收的数据量等于发送的数据量,不就是传完了么?
so,代码如下:
服务端:
# -*- coding: UTF-8 -*- import os import socket server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # TCP/IP协议, tcp ,如果不填写就是默认这个 server.bind(('localhost', 9999)) server.listen() while True: # 可以接受多个客户端 conn, addr = server.accept() while True: data = conn.recv(1024) if not data: # 防止当接受的客户端数据为空时,程序卡掉 print('client has lost...') break print('执行命令:', data.decode()) cmd_res = os.popen(data.decode()).read() if len(cmd_res) == 0: print('command not found') else: # 服务端先将数据大小发送给客户端,用于对比 cmd_res_length = len(cmd_res) # int类型 # print(len('{}'.format(cmd_res).encode('utf-8'))) # 不先对数据编码的话,会出现中文长度统计不符。用下面注释的方法传输的数据,长度比实际短 conn.send(str(len('{}'.format(cmd_res).encode('utf-8'))).encode('utf-8')) # conn.send(str(cmd_res_length).encode('utf-8')) # 发送数据 conn.send('{}'.format(cmd_res).encode('utf-8')) print('发送完成')
客户端:
# -*- coding: UTF-8 -*- import socket client = socket.socket() client.connect(('localhost', 9999)) while True: cmd = input('>>:').strip() # 判断是否发送空数据,如果是就重新发送 if len(cmd) == 0: continue else: client.send(cmd.encode('utf-8')) data_size = client.recv(1024) # 接收服务端发送的数据大小 print(data_size) data_length = int(data_size.decode()) print('返回数据大小:', data_length) # 定义已接收数据大小为0 received_length = 0 # 定义已接收数据为0 received_data = b'' while received_length < data_length: r_data = client.recv(1024) # 接受的数据是bytes类型 received_length += len(r_data) received_data += r_data else: print('接收数据大小:', received_length) print(received_data.decode('utf-8', 'ignore')) # 不加ignore在windows有时会报错 print('数据接收完毕!')
结果:
Look,问题解决了
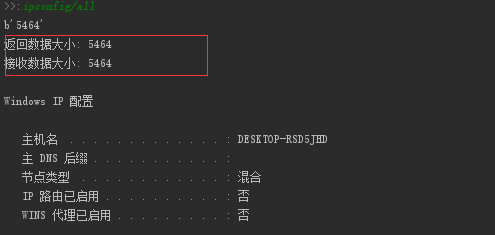
中间很长不放了
四、剩余一些问题
4.1 数据长度不一致的问题
刚才提到当字符串有中文时直接用len()函数,可能会得到不一样的长度,如下例:
# ipconfig/all 中的一段内容
data = '以太网适配器 VMware Network Adapter VMnet1:'
# 不转换成utf-8格式计算长度
length = len(data)
print(length)
# 先转码在计算长度
utf_length = len(data.encode('utf-8'))
print(utf_length)
# 输出
37
49
注:长度会比不编码时长 中文字符个数 * 2,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号