搭建EFK日志系统
Elasticsearch 是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大量日志数据,也可用于搜索许多不同类型的文档。
Elasticsearch 通常与 Kibana 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 允许你通过 web 界面来浏览 Elasticsearch 日志数据。
Fluentd是一个流行的开源数据收集器,我们将在 Kubernetes 集群节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
一、创建Elasticsearch集群
kube-logging.yaml
apiVersion: v1
kind: Namespace
metadata:
name: logging
然后通过kubectl创建该namespace,创建名为logging的命名空间
# kubectl create -f kube-logging.yaml namespace/logging created # kubectl get ns NAME STATUS AGE default Active 31d kube-node-lease Active 31d kube-public Active 31d kube-system Active 31d kubernetes-dashboard Active 28d logging Active 7s
使用3个Elasticsearch Pod来避免 高可用下多节点集群中出现的“脑裂”问题,一个关键的是您应该设置参数discover.zen.minimum_master_nodes=N/2+1,其中N是 Elasticsearch 集群中符合主节点的节点数,比如我们这里3个节点,意味着N应该设置为2。
首先创建一个名为elasticsearch的headless服务,新建文件elasticearch-svc.yaml:
apiVersion: v1 kind: Service metadata: name: elasticsearch namespace: logging labels: app: elasticsearch spec: selector: app: elasticsearch clusterIP: None ports: - port: 9200 name: rest - port: 9300 name: inter-node
定义了一个名为 elasticsearch 的 Service,指定标签app=elasticsearch,当我们将 Elasticsearch StatefulSet 与此服务关联时,服务将返回带有标签app=elasticsearch的 Elasticsearch Pods 的 DNS A 记录,然后设置clusterIP=None,将该服务设置成无头服务。最后,我们分别定义端口9200、9300,分别用于与 REST API 交互,以及用于节点间通信。
使用kubectl 直接创建资源对象:
# kubectl create -f elasticsearch-svc.yaml service/elasticsearch created # kubectl get svc -n logging NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 7s
现在我们已经为 Pod 设置了无头服务和一个稳定的域名.elasticsearch.logging.svc.cluster.local,接下来我们通过 StatefulSet 来创建具体的 Elasticsearch 的 Pod 应用。
定义elasticsearch的配置文件,elasticsearch-conf.yaml
apiVersion: v1 kind: ConfigMap metadata: name: elasticsearch namespace: logging data: elasticsearch.yml: | cluster.name: k8s-log node.name: "${POD_NAME}" network.host: 0.0.0.0 cluster.initial_master_nodes: ["es-cluster-0","es-cluster-1","es-cluster-2"] discovery.zen.ping.unicast.hosts: ["es-cluster-0.elasticsearch","es-cluster-1.elasticsearch","es-cluster-2.elasticsearch"] xpack.security.enabled: "false" bootstrap.system_call_filter: "false" discovery.zen.minimum_master_nodes: "2"
创建该configmap
# kubectl create -f elasticsearch-conf.yaml # kubectl get configmap elasticsearch -n logging -o yaml apiVersion: v1 data: elasticsearch.yml: | cluster.name: k8s-log node.name: "${POD_NAME}" network.host: 0.0.0.0 cluster.initial_master_nodes: ["es-cluster-0","es-cluster-1","es-cluster-2"] discovery.zen.ping.unicast.hosts: ["es-cluster-0.elasticsearch","es-cluster-1.elasticsearch","es-cluster-2.elasticsearch"] xpack.security.enabled: "false" bootstrap.system_call_filter: "false" discovery.zen.minimum_master_nodes: "2" kind: ConfigMap metadata: creationTimestamp: "2020-07-07T01:05:33Z" managedFields: - apiVersion: v1 fieldsType: FieldsV1 fieldsV1: f:data: .: {} f:elasticsearch.yml: {} manager: kubectl operation: Update time: "2020-07-07T01:05:33Z" name: elasticsearch namespace: logging resourceVersion: "5924749" selfLink: /api/v1/namespaces/logging/configmaps/elasticsearch uid: 2224da1f-78ac-47e7-bcda-814952bbb776
-
cluster.name:Elasticsearch 集群的名称,我们这里命名成 k8s-logs。
-
node.name:节点的名称,通过
metadata.name来获取。这将解析为 es-cluster-[0,1,2],取决于节点的指定顺序。 -
discovery.zen.ping.unicast.hosts:此字段用于设置在 Elasticsearch 集群中节点相互连接的发现方法。我们使用 unicastdiscovery 方式,它为我们的集群指定了一个静态主机列表。由于我们之前配置的无头服务,我们的 Pod 具有唯一的 DNS 域
es-cluster-[0,1,2].elasticsearch.logging.svc.cluster.local,因此我们相应地设置此变量。由于都在同一个 namespace 下面,所以我们可以将其缩短为es-cluster-[0,1,2].elasticsearch。要了解有关 Elasticsearch 发现的更多信息,请参阅 Elasticsearch 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery.html。 -
discovery.zen.minimum_master_nodes:我们将其设置为
(N/2) + 1,N是我们的群集中符合主节点的节点的数量。我们有3个 Elasticsearch 节点,因此我们将此值设置为2(向下舍入到最接近的整数)。要了解有关此参数的更多信息,请参阅官方 Elasticsearch 文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html#split-brain。
Kubernetes StatefulSet 允许我们为 Pod 分配一个稳定的标识和持久化存储,Elasticsearch 需要稳定的存储来保证 Pod 在重新调度或者重启后的数据依然不变,所以需要使用 StatefulSet 来管理 Pod。
新建名为 elasticsearch-statefulset.yaml 的资源清单文件:
apiVersion: apps/v1 kind: StatefulSet metadata: name: es-cluster namespace: logging spec: serviceName: elasticsearch replicas: 3 selector: matchLabels: app: elasticsearch template: metadata: labels: app: elasticsearch
该内容中,我们定义了一个名为 es-cluster 的 StatefulSet 对象,然后定义serviceName=elasticsearch和前面创建的 Service 相关联,这可以确保使用以下 DNS 地址访问 StatefulSet 中的每一个 Pod:es-cluster-[0,1,2].elasticsearch.logging.svc.cluster.local,其中[0,1,2]对应于已分配的 Pod 序号。
然后指定3个副本,将 matchLabels 设置为app=elasticsearch,所以 Pod 的模板部分.spec.template.metadata.lables也必须包含app=elasticsearch标签。
然后定义 Pod 模板部分内容:
--- spec: containers: - name: elasticsearch image: elasticsearch:7.5.0 imagePullPolicy: IfNotPresent resources: limits: cpu: 1000m requests: cpu: 100m ports: - containerPort: 9200 name: rest protocol: TCP - containerPort: 9300 name: inter-node protocol: TCP volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: ES_JAVA_OPTS value: "-Xms512m -Xmx512m" volumeMounts: - name: elasticsearch-config mountPath: /usr/share/elasticsearch/config/elasticsearch.yml subPath: elasticsearch.yml volumes: - name: elasticsearch-config configMap: name: elasticsearch
-
ES_JAVA_OPTS:这里我们设置为
-Xms512m -Xmx512m,告诉JVM使用512 MB的最小和最大堆。您应该根据群集的资源可用性和需求调整这些参数。要了解更多信息,请参阅设置堆大小的相关文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html。
接下来添加关于 initContainer 的内容:
--- initContainers: - name: fix-permissions image: registry.cn-hangzhou.aliyuncs.com/google_containers/busybox imagePullPolicy: IfNotPresent command: ['sh','-c','chown -R 1000.1000 /usr/share/elasticsearch/data'] securityContext: privileged: true volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data - name: increase-vm-max-map image: registry.cn-hangzhou.aliyuncs.com/google_containers/busybox imagePullPolicy: IfNotPresent command: ['sysctl','-w','vm.max_map_count=262144'] securityContext: privileged: true - name: increase-fd-ulimit image: busybox command: ['sh','-c','ulimit -n 65535'] securityContext: privileged: true
第一个名为 fix-permissions 的容器用来运行 chown 命令,将 Elasticsearch 数据目录的用户和组更改为1000:1000(Elasticsearch 用户的 UID)。因为默认情况下,Kubernetes 用 root 用户挂载数据目录,这会使得 Elasticsearch 无法方法该数据目录,可以参考 Elasticsearch 生产中的一些默认注意事项相关文档说明:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#_notes_for_production_use_and_defaults。
第二个名为 increase-vm-max-map 的容器用来增加操作系统对mmap计数的限制,默认情况下该值可能太低,导致内存不足的错误,要了解更多关于该设置的信息,可以查看 Elasticsearch 官方文档说明:https://www.elastic.co/guide/en/elasticsearch/reference/current/vm-max-map-count.html。
最后一个初始化容器是用来执行ulimit命令增加打开文件描述符的最大数量的。
此外
现在我们已经定义了主应用容器和它之前运行的 Init Containers 来调整一些必要的系统参数,接下来我们可以添加数据目录的持久化相关的配置,在 StatefulSet 中,使用 volumeClaimTemplates 来定义 volume 模板即可:
... volumeClaimTemplates: - metadata: name: data labels: app: elasticsearch spec: accessModes: [ "ReadWriteOnce" ] storageClassName: es-data-db resources: requests: storage: 50Gi
这里使用 volumeClaimTemplates 来定义持久化模板,Kubernetes 会使用它为 Pod 创建 PersistentVolume,设置访问模式为ReadWriteOnce,这意味着它只能被 mount 到单个节点上进行读写,然后最重要的是使用了一个名为 es-data-db 的 StorageClass 对象,新建一个 elasticsearch-storageclass.yaml 的文件,文件内容如下:
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: es-data-db provisioner: kubernetes.io/glusterfs parameters: resturl: http://192.168.10.106:18080
最后,完整的 Elasticsearch StatefulSet 资源清单文件内容如下:
apiVersion: apps/v1 kind: StatefulSet metadata: name: es-cluster namespace: logging spec: serviceName: elasticsearch replicas: 3 selector: matchLabels: app: elasticsearch template: metadata: labels: app: elasticsearch spec: containers: - name: elasticsearch image: elasticsearch:7.5.0 imagePullPolicy: IfNotPresent resources: limits: cpu: 1000m requests: cpu: 100m ports: - containerPort: 9200 name: rest protocol: TCP - containerPort: 9300 name: inter-node protocol: TCP volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: ES_JAVA_OPTS value: "-Xms512m -Xmx512m" volumeMounts: - name: elasticsearch-config mountPath: /usr/share/elasticsearch/config/elasticsearch.yml subPath: elasticsearch.yml volumes: - name: elasticsearch-config configMap: name: elasticsearch initContainers: - name: fix-permissions image: registry.cn-hangzhou.aliyuncs.com/google_containers/busybox imagePullPolicy: IfNotPresent command: ['sh','-c','chown -R 1000.1000 /usr/share/elasticsearch/data'] securityContext: privileged: true volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data - name: increase-vm-max-map image: registry.cn-hangzhou.aliyuncs.com/google_containers/busybox imagePullPolicy: IfNotPresent command: ['sysctl','-w','vm.max_map_count=262144'] securityContext: privileged: true - name: increase-fd-ulimit image: busybox command: ['sh','-c','ulimit -n 65535'] securityContext: privileged: true volumeClaimTemplates: - metadata: name: data labels: app: elasticsearch spec: accessModes: [ "ReadWriteOnce" ] storageClassName: es-data-db resources: requests: storage: 2Gi
部署
# kubectl create -f elasticsearch-storageclass.yaml storageclass.storage.k8s.io "es-data-db" created # kubectl create -f elasticsearch-statefulset.yaml statefulset.apps/es-cluster created
查看
# kubectl get sts -n logging NAME READY AGE es-cluster 3/3 7m37s # kubectl get pods -n logging NAME READY STATUS RESTARTS AGE es-cluster-0 1/1 Running 0 7m44s es-cluster-1 1/1 Running 0 6m20s es-cluster-2 1/1 Running 0 5m1s # kubectl get svc -n logging NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE elasticserch ClusterIP None <none> 9200/TCP,9300/TCP 3h1m
Pods 部署完成后,我们可以通过请求一个 REST API 来检查 Elasticsearch 集群是否正常运行。使用下面的命令将本地端口9200转发到 Elasticsearch 节点(如es-cluster-0)对应的端口:
# kubectl port-forward es-cluster-0 9200:9200 --namespace=logging Forwarding from 127.0.0.1:9200 -> 9200 Forwarding from [::1]:9200 -> 9200
然后,在另外的终端窗口中,执行如下请求:
# curl http://localhost:9200/_cluster/state?pretty | more % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0{ "cluster_name" : "k8s-log", "cluster_uuid" : "iXCjUz9jS_2ndq1VHQhptg", "version" : 18, "state_uuid" : "BGVTBoDGTSmnM2BXdJVlbw", "master_node" : "aL-lsgOIQJ64EMP9T_IRqA", "blocks" : { }, "nodes" : { "aL-lsgOIQJ64EMP9T_IRqA" : { "name" : "es-cluster-0", "ephemeral_id" : "8TGAhf9xQ9id2yqImo7y9A", "transport_address" : "10.32.0.2:9300", "attributes" : { "ml.machine_memory" : "2983755776", "xpack.installed" : "true", "ml.max_open_jobs" : "20" } }, "NbVg-sSYQFuMx0gyyu0ugw" : { "name" : "es-cluster-2", "ephemeral_id" : "IGDXyo33S5GV779CJgl4fQ", "transport_address" : "10.38.0.3:9300", "attributes" : { "ml.machine_memory" : "2983759872", "ml.max_open_jobs" : "20", "xpack.installed" : "true" } }, "26cjOCdeSwiOIZaNP095Dw" : { "name" : "es-cluster-1", "ephemeral_id" : "RtSL9qqHQya_m2VAYkTJRA", "transport_address" : "10.34.0.1:9300", "attributes" : { ...
看到上面的信息就表明我们名为 k8s-logs 的 Elasticsearch 集群成功创建了3个节点:es-cluster-0,es-cluster-1,和es-cluster-2,当前主节点是 es-cluster-0。
二、创建Kibana服务
Elasticsearch 集群启动成功了,接下来我们可以来部署 Kibana 服务,新建一个名为 kibana.yaml 的文件,对应的文件内容如下:
--- apiVersion: v1 kind: Service metadata: name: kibana namespace: logging labels: app: kibana spec: selector: app: kibana type: NodePort ports: - port: 5601 --- apiVersion: apps/v1 kind: Deployment metadata: name: kibana namespace: logging labels: app: kibana spec: selector: matchLabels: app: kibana template: metadata: labels: app: kibana spec: containers: - name: kibana image: kibana:7.5.0 resources: limits: cpu: 1000m requests: cpu: 100m env: - name: ELASTICSEARCH_URL value: http://elasticsearch:9200 ports: - containerPort: 5601
创建
# kubectl create -f kibana.yaml # kubectl get svc -n logging NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kibana NodePort 10.97.159.197 <none> 5601:32092/TCP 15m
如果 Pod 已经是 Running 状态了,证明应用已经部署成功了,然后可以通过 NodePort 来访问 Kibana 这个服务,在浏览器中打开http://<任意节点IP>:32092即可,如果看到如下欢迎界面证明 Kibana 已经成功部署到了 Kubernetes集群之中。
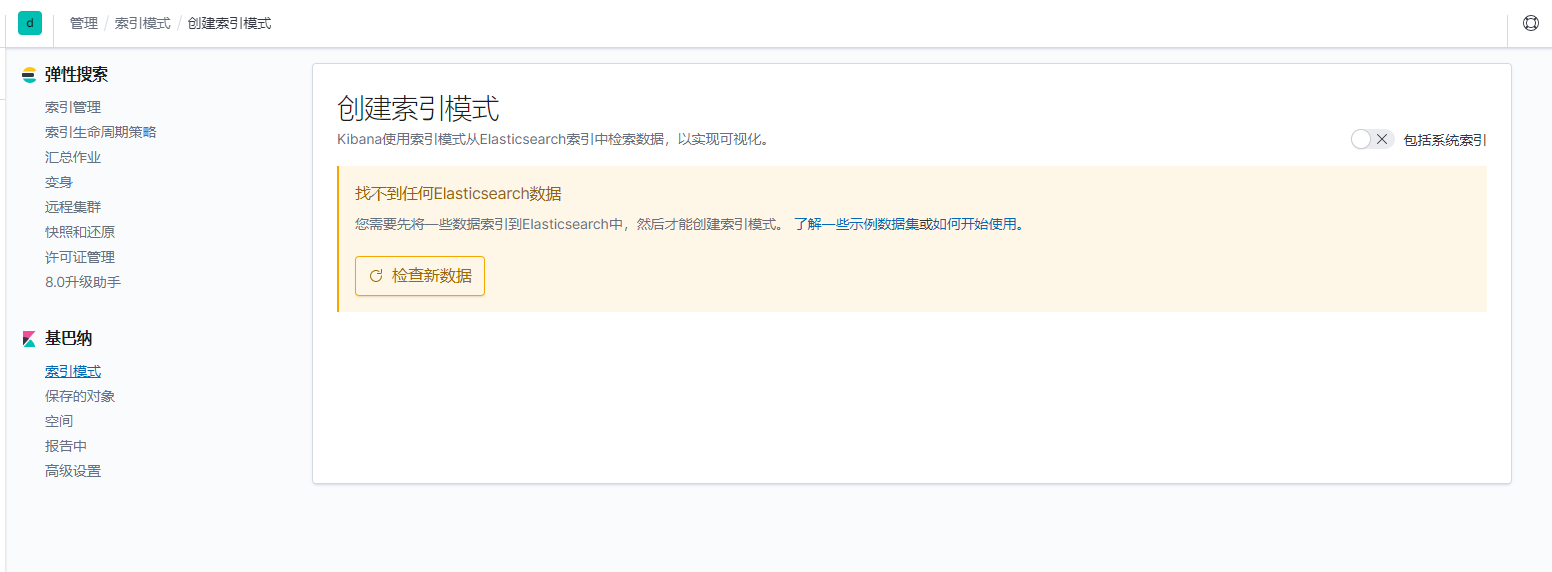
部署Fluentd
Fluentd 是一个高效的日志聚合器,是用 Ruby 编写的,并且可以很好地扩展。对于大部分企业来说,Fluentd 足够高效并且消耗的资源相对较少,另外一个工具Fluent-bit更轻量级,占用资源更少,但是插件相对 Fluentd 来说不够丰富,所以整体来说,Fluentd 更加成熟,使用更加广泛,所以我们这里也同样使用 Fluentd 来作为日志收集工具。
工作原理
Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储等等。Fluentd 支持超过300个日志存储和分析服务,所以在这方面是非常灵活的。主要运行步骤如下:
-
首先 Fluentd 从多个日志源获取数据
-
结构化并且标记这些数据
-
然后根据匹配的标签将数据发送到多个目标服务去

配置
一般来说我们是通过一个配置文件来告诉 Fluentd 如何采集、处理数据的
日志源配置
比如我们这里为了收集 Kubernetes 节点上的所有容器日志,就需要做如下的日志源配置:
<source> @id fluentd-containers.log @type tail path /var/log/containers/*.log pos_file /var/log/fluentd-containers.log.pos time_format %Y-%m-%dT%H:%M:%S.%NZ tag raw.kubernetes.* format json read_from_head true </source>
上面配置部分参数说明如下:
-
id:表示引用该日志源的唯一标识符,该标识可用于进一步过滤和路由结构化日志数据
-
type:Fluentd 内置的指令,
tail表示 Fluentd 从上次读取的位置通过 tail 不断获取数据,另外一个是http表示通过一个 GET 请求来收集数据。 -
path:
tail类型下的特定参数,告诉 Fluentd 采集/var/log/containers目录下的所有日志,这是 docker 在 Kubernetes 节点上用来存储运行容器 stdout 输出日志数据的目录。 -
pos_file:检查点,如果 Fluentd 程序重新启动了,它将使用此文件中的位置来恢复日志数据收集。
-
tag:用来将日志源与目标或者过滤器匹配的自定义字符串,Fluentd 匹配源/目标标签来路由日志数据。
路由配置
上面是日志源的配置,接下来看看如何将日志数据发送到 Elasticsearch:
<match **> @id elasticsearch @type elasticsearch @log_level info include_tag_key true type_name fluentd host "#{ENV['OUTPUT_HOST']}" port "#{ENV['OUTPUT_PORT']}" logstash_format true <buffer> @type file path /var/log/fluentd-buffers/kubernetes.system.buffer flush_mode interval retry_type exponential_backoff flush_thread_count 2 flush_interval 5s retry_forever retry_max_interval 30 chunk_limit_size "#{ENV['OUTPUT_BUFFER_CHUNK_LIMIT']}" queue_limit_length "#{ENV['OUTPUT_BUFFER_QUEUE_LIMIT']}" overflow_action block </buffer>
-
match:标识一个目标标签,后面是一个匹配日志源的正则表达式,我们这里想要捕获所有的日志并将它们发送给 Elasticsearch,所以需要配置成
**。 -
id:目标的一个唯一标识符。
-
type:支持的输出插件标识符,我们这里要输出到 Elasticsearch,所以配置成 elasticsearch,这是 Fluentd 的一个内置插件。
-
log_level:指定要捕获的日志级别,我们这里配置成
info,表示任何该级别或者该级别以上(INFO、WARNING、ERROR)的日志都将被路由到 Elsasticsearch。 -
host/port:定义 Elasticsearch 的地址,也可以配置认证信息,我们的 Elasticsearch 不需要认证,所以这里直接指定 host 和 port 即可。
-
logstash_format:Elasticsearch 服务对日志数据构建反向索引进行搜索,将 logstash_format 设置为
true,Fluentd 将会以 logstash 格式来转发结构化的日志数据。 -
Buffer: Fluentd 允许在目标不可用时进行缓存,比如,如果网络出现故障或者 Elasticsearch 不可用的时候。缓冲区配置也有助于降低磁盘的 IO。
安装
要收集 Kubernetes 集群的日志,直接用 DasemonSet 控制器来部署 Fluentd 应用,这样,它就可以从 Kubernetes 节点上采集日志,确保在集群中的每个节点上始终运行一个 Fluentd 容器。当然可以直接使用 Helm 来进行一键安装,为了能够了解更多实现细节,我们这里还是采用手动方法来进行安装。
首先,我们通过 ConfigMap 对象来指定 Fluentd 配置文件,新建 fluentd-configmap.yaml 文件,文件内容如下:
(这个配置貌似没效果,直接再daemonset中设置)
apiVersion: v1 kind: ConfigMap metadata: name: fluentd-config namespace: logging labels: addonmanager.kubernetes.io/mode: Reconcile data: system.conf: |- <system> root_dir /tmp/fluentd-buffers/ </system> containers.input.conf: |- <source> @id fluentd-containers.log @type tail path /var/log/containers/*.log pos_file /var/log/es-containers.log.pos time_format %Y-%m-%dT%H:%M:%S.%NZ localtime tag raw.kubernetes.* format json read_from_head true </source> # Detect exceptions in the log output and forward them as one log entry. <match raw.kubernetes.**> @id raw.kubernetes @type detect_exceptions remove_tag_prefix raw message log stream stream multiline_flush_interval 5 max_bytes 500000 max_lines 1000 </match> system.input.conf: |- # Logs from systemd-journal for interesting services. <source> @id journald-docker @type systemd filters [{ "_SYSTEMD_UNIT": "docker.service" }] <storage> @type local persistent true </storage> read_from_head true tag docker </source> <source> @id journald-docker @type systemd filters [{ "_SYSTEMD_UNIT": "docker.service" }] <storage> @type local persistent true </storage> read_from_head true tag docker </source> forward.input.conf: |- # Takes the messages sent over TCP <source> @type forward </source> output.conf: |- # Enriches records with Kubernetes metadata <filter kubernetes.**> @type kubernetes_metadata </filter> <match **> @id elasticsearch @type elasticsearch @log_level info include_tag_key true host elasticsearch port 9200 logstash_format true request_timeout 30s <buffer> @type file path /var/log/fluentd-buffers/kubernetes.system.buffer flush_mode interval retry_type exponential_backoff flush_thread_count 2 flush_interval 5s retry_forever retry_max_interval 30 chunk_limit_size 2M queue_limit_length 8 overflow_action block </buffer> </match>
上面配置文件中我们配置了 docker 容器日志目录以及 docker、kubelet 应用的日志的收集,收集到数据经过处理后发送到 elasticsearch:9200 服务。
然后新建一个 fluentd-daemonset.yaml 的文件,文件内容如下:
apiVersion: v1 kind: ServiceAccount metadata: name: fluentd-es namespace: logging labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups: - "" resources: - "namespaces" - "pods" verbs: - "get" - "watch" - "list" --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile subjects: - kind: ServiceAccount name: fluentd-es namespace: logging #apiGroup: "" roleRef: kind: ClusterRole name: fluentd-es apiGroup: rbac.authorization.k8s.io --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd-es namespace: logging labels: k8s-app: fluentd-es #version: v2.0.4 kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile spec: selector: matchLabels: k8s-app: fluentd-es #version: v2.0.4 template: metadata: labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" # version: v2.0.4 # This annotation ensures that fluentd does not get evicted if the node # supports critical pod annotation based priority scheme. # Note that this does not guarantee admission on the nodes (#40573). annotations: scheduler.alpha.kubernetes.io/critical-pod: '' spec: serviceAccount: fluentd-es containers: - name: fluentd-es #image: cnych/fluentd-elasticsearch:v2.0.4 image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1 env: - name: FLUENTD_ARGS value: --no-supervisor -q - name: FLUENT_ELASTICSEARCH_HOST value: "elasticsearch.logging.svc.cluster.local" - name: FLUENT_ELASTICSEARCH_PORT value: "9200" - name: FLUENT_ELASTICSEARCH_SCHEME value: "http" - name: FLUENTD_SYSTEMD_CONF value: disable resources: limits: memory: 500Mi requests: memory: 100Mi cpu: 100m volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true nodeSelector: beta.kubernetes.io/fluentd-ds-ready: "true" tolerations: - key: node-role.kubernetes.io/master operator: Exists effect: NoSchedule terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers
我们将上面创建的 fluentd-config 这个 ConfigMap 对象通过 volumes 挂载到了 Fluentd 容器中,另外为了能够灵活控制哪些节点的日志可以被收集,所以我们这里还添加了一个 nodSelector 属性:
nodeSelector: beta.kubernetes.io/fluentd-ds-ready: "true"
先给kubernetes集群打标签
# kubectl label nodes node1 beta.kubernetes.io/fluentd-ds-ready=true node/node1 labeled #类似所有节点打上label
另外由于我们的集群使用的是 kubeadm 搭建的,默认情况下 master 节点有污点,所以要想也收集 master 节点的日志,则需要添加上容忍:
tolerations: - key: node-role.kubernetes.io/master operator: Exists effect: NoSchedule
创建flunetd
# kubectl create -f fluentd-daemonset.yaml serviceaccount/fluentd-es created clusterrole.rbac.authorization.k8s.io/fluentd-es created clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created daemonset.apps/fluentd-es created
启动后查看kibana,点击discover
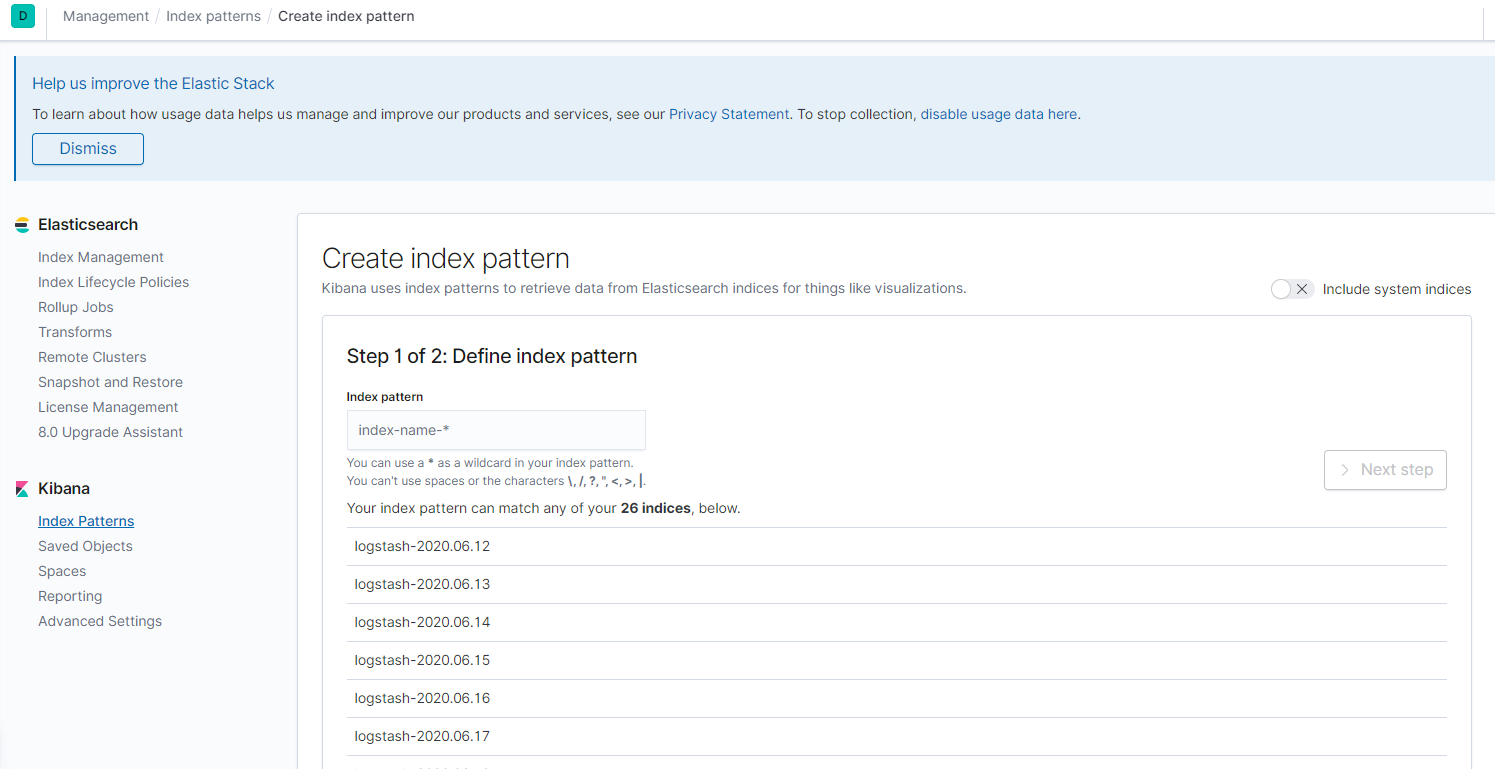
如果创建的index无法保存,总是要重新创建,建议重启elasticsearch和kibana
# kubectl scale statefulset es-cluster -n logging --replicas=0 # kubectl scale deployment kibana -n logging --replicas=0 # kubectl scale statefulset es-cluster -n logging --replicas=3 # kubectl scale deployment kibana -n logging --replicas=1
新建index pattern: logstash-*, 时间过滤日志数据,在下拉列表中,选择@timestamp字段
最后显示:
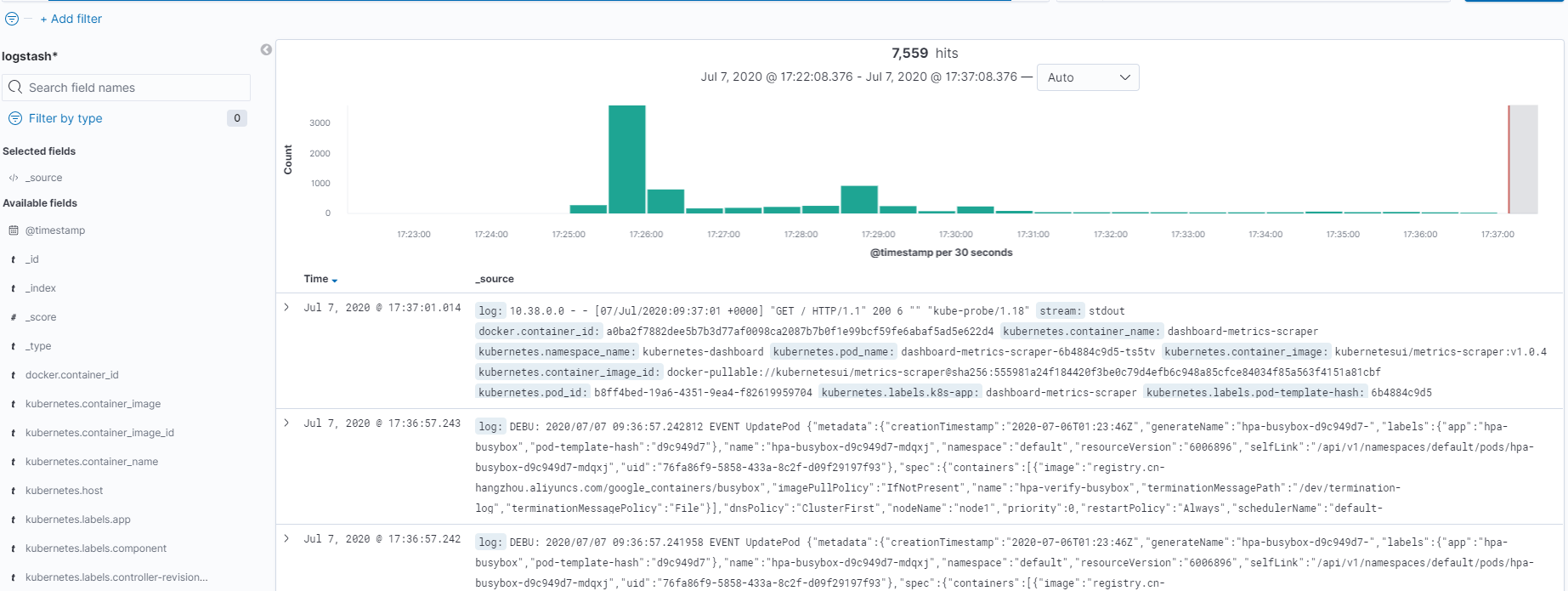

 浙公网安备 33010602011771号
浙公网安备 33010602011771号