

并发之痛 Thread,Goroutine,Actor
http://jolestar.com/parallel-programming-model-thread-goroutine-actor/
本文基于我在2月27日Gopher北京聚会演讲整理而成,进行了一些补充以及调整。投稿给《高可用架构》公众号首发。
聊这个话题之前,先梳理下两个概念,几乎所有讲并发的文章都要先讲这两个概念:
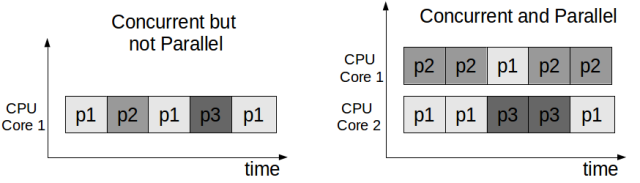
- 并发(concurrency) 并发的关注点在于任务切分。举例来说,你是一个创业公司的CEO,开始只有你一个人,你一人分饰多角,一会做产品规划,一会写代码,一会见客户,虽然你不能见客户的同时写代码,但由于你切分了任务,分配了时间片,表现出来好像是多个任务一起在执行。
- 并行(parallelism) 并行的关注点在于同时执行。还是上面的例子,你发现你自己太忙了,时间分配不过来,于是请了工程师,产品经理,市场总监,各司一职,这时候多个任务可以同时执行了。
所以总结下,并发并不要求必须并行,可以用时间片切分的方式模拟,比如单核cpu上的多任务系统,并发的要求是任务能切分成独立执行的片段。而并行关注的是同时执行,必须是多(核)cpu,要能并行的程序必须是支持并发的。本文大多数情况下不会严格区分这两个概念,默认并发就是指并行机制下的并发。
为什么并发程序这么难?
We believe that writing correct concurrent, fault-tolerant and scalable applications is too hard. Most of the time it’s because we are using the wrong tools and the wrong level of abstraction. —— Akka
Akka官方文档开篇这句话说的好,之所以写正确的并发,容错,可扩展的程序如此之难,是因为我们用了错误的工具和错误的抽象。(当然该文档本来的意思是Akka是正确的工具,但我们可以独立的看待这句话)。
那我们从最开始梳理下程序的抽象。开始我们的程序是面向过程的,数据结构+func。后来有了面向对象,对象组合了数结构和func,我们想用模拟现实世界的方式,抽象出对象,有状态和行为。但无论是面向过程的func还是面向对象的func,本质上都是代码块的组织单元,本身并没有包含代码块的并发策略的定义。于是为了解决并发的需求,引入了Thread(线程)的概念。
线程(Thread)
- 系统内核态,更轻量的进程
- 由系统内核进行调度
- 同一进程的多个线程可共享资源
线程的出现解决了两个问题,一个是GUI出现后急切需要并发机制来保证用户界面的响应。第二是互联网发展后带来的多用户问题。最早的CGI程序很简单,将通过脚本将原来单机版的程序包装在一个进程里,来一个用户就启动一个进程。但明显这样承载不了多少用户,并且如果进程间需要共享资源还得通过进程间的通信机制,线程的出现缓解了这个问题。
线程的使用比较简单,如果你觉得这块代码需要并发,就把它放在单独的线程里执行,由系统负责调度,具体什么时候使用线程,要用多少个线程,由调用方决定,但定义方并不清楚调用方会如何使用自己的代码,很多并发问题都是因为误用导致的,比如Go中的map以及Java的HashMap都不是并发安全的,误用在多线程环境就会导致问题。另外也带来复杂度:
- 竞态条件(race conditions) 如果每个任务都是独立的,不需要共享任何资源,那线程也就非常简单。但世界往往是复杂的,总有一些资源需要共享,比如前面的例子,开发人员和市场人员同时需要和CEO商量一个方案,这时候CEO就成了竞态条件。
- 依赖关系以及执行顺序 如果线程之间的任务有依赖关系,需要等待以及通知机制来进行协调。比如前面的例子,如果产品和CEO讨论的方案依赖于市场和CEO讨论的方案,这时候就需要协调机制保证顺序。
为了解决上述问题,我们引入了许多复杂机制来保证:
- Mutex(Lock) (Go里的sync包, Java的concurrent包)通过互斥量来保护数据,但有了锁,明显就降低了并发度。
- semaphore 通过信号量来控制并发度或者作为线程间信号(signal)通知。
- volatile Java专门引入了volatile关键词来,来降低只读情况下的锁的使用。
- compare-and-swap 通过硬件提供的CAS机制保证原子性(atomic),也是降低锁的成本的机制。
如果说上面两个问题只是增加了复杂度,我们通过深入学习,严谨的CodeReview,全面的并发测试(比如Go语言中单元测试的时候加上-race参数),一定程度上能解决(当然这个也是有争议的,有论文认为当前的大多数并发程序没出问题只是并发度不够,如果CPU核数继续增加,程序运行的时间更长,很难保证不出问题)。但最让人头痛的还是下面这个问题:
系统里到底需要多少线程?
这个问题我们先从硬件资源入手,考虑下线程的成本:
- 内存(线程的栈空间)
每个线程都需要一个栈(Stack)空间来保存挂起(suspending)时的状态。Java的栈空间(64位VM)默认是1024k,不算别的内存,只是栈空间,启动1024个线程就要1G内存。虽然可以用-Xss参数控制,但由于线程是本质上也是进程,系统假定是要长期运行的,栈空间太小会导致稍复杂的递归调用(比如复杂点的正则表达式匹配)导致栈溢出。所以调整参数治标不治本。 -
调度成本(context-switch)
我在个人电脑上做的一个非严格测试,模拟两个线程互相唤醒轮流挂起,线程切换成本大约6000纳秒/次。这个还没考虑栈空间大小的影响。国外一篇论文专门分析线程切换的成本,基本上得出的结论是切换成本和栈空间使用大小直接相关。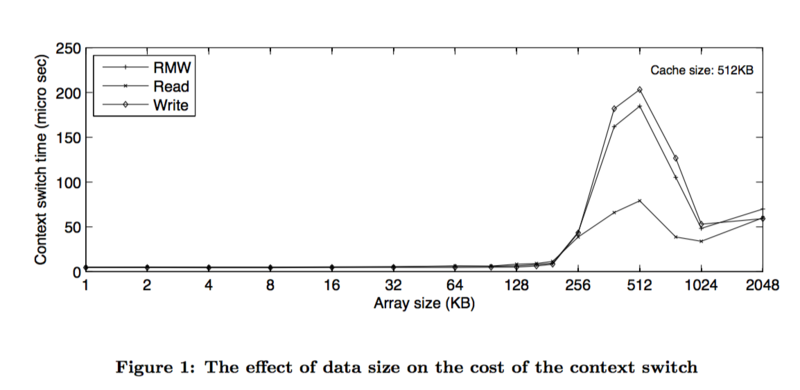
-
CPU使用率
我们搞并发最主要的一个目标就是我们有了多核,想提高CPU利用率,最大限度的压榨硬件资源,从这个角度考虑,我们应该用多少线程呢?
这个我们可以通过一个公式计算出来,100/(15+5)*4=20,用20个线程最合适。但一方面网络的时间不是固定的,另外一方面,如果考虑到其他瓶颈资源呢?比如锁,比如数据库连接池,就会更复杂。
作为一个1岁多孩子的父亲,认为这个问题的难度好比你要写个给孩子喂饭的程序,需要考虑『给孩子喂多少饭合适?』,这个问题有以下回答以及策略:
- 孩子不吃了就好了(但孩子贪玩,不吃了可能是想去玩了)
- 孩子吃饱了就好了(废话,你怎么知道孩子吃饱了?孩子又不会说话)
- 逐渐增量,长期观察,然后计算一个平均值(这可能是我们调整线程常用的策略,但增量增加到多少合适呢?)
- 孩子吃吐了就别喂了(如果用逐渐增量的模式,通过外部观察,可能会到达这个边界条件。系统性能如果因为线程的增加倒退了,就别增加线程了)
- 没控制好边界,把孩子给给撑坏了 (这熊爸爸也太恐怖了。但调整线程的时候往往不小心可能就把系统搞挂了)
通过这个例子我们可以看出,从外部系统来观察,或者以经验的方式进行计算,都是非常困难的。于是结论是:
让孩子会说话,吃饱了自己说,自己学会吃饭,自管理是最佳方案。
然并卵,计算机不会自己说话,如何自管理?
但我们从以上的讨论可以得出一个结论:
- 线程的成本较高(内存,调度)不可能大规模创建
- 应该由语言或者框架动态解决这个问题
线程池方案
Java1.5后,Doug Lea的Executor系列被包含在默认的JDK内,是典型的线程池方案。
线程池一定程度上控制了线程的数量,实现了线程复用,降低了线程的使用成本。但还是没有解决数量的问题,线程池初始化的时候还是要设置一个最小和最大线程数,以及任务队列的长度,自管理只是在设定范围内的动态调整。另外不同的任务可能有不同的并发需求,为了避免互相影响可能需要多个线程池,最后导致的结果就是Java的系统里充斥了大量的线程池。
新的思路
从前面的分析我们可以看出,如果线程是一直处于运行状态,我们只需设置和CPU核数相等的线程数即可,这样就可以最大化的利用CPU,并且降低切换成本以及内存使用。但如何做到这一点呢?
陈力就列,不能者止
这句话是说,能干活的代码片段就放在线程里,如果干不了活(需要等待,被阻塞等),就摘下来。通俗的说就是不要占着茅坑不拉屎,如果拉不出来,需要酝酿下,先把茅坑让出来,因为茅坑是稀缺资源。
要做到这点一般有两种方案:
-
异步回调方案 典型如NodeJS,遇到阻塞的情况,比如网络调用,则注册一个回调方法(其实还包括了一些上下文数据对象)给IO调度器(linux下是libev,调度器在另外的线程里),当前线程就被释放了,去干别的事情了。等数据准备好,调度器会将结果传递给回调方法然后执行,执行其实不在原来发起请求的线程里了,但对用户来说无感知。但这种方式的问题就是很容易遇到callback hell,因为所有的阻塞操作都必须异步,否则系统就卡死了。还有就是异步的方式有点违反人类思维习惯,人类还是习惯同步的方式。
-
GreenThread/Coroutine/Fiber方案 这种方案其实和上面的方案本质上区别不大,关键在于回调上下文的保存以及执行机制。为了解决回调方法带来的难题,这种方案的思路是写代码的时候还是按顺序写,但遇到IO等阻塞调用时,将当前的代码片段暂停,保存上下文,让出当前线程。等IO事件回来,然后再找个线程让当前代码片段恢复上下文继续执行,写代码的时候感觉好像是同步的,仿佛在同一个线程完成的,但实际上系统可能切换了线程,但对程序无感。
GreenThread
- 用户空间 首先是在用户空间,避免内核态和用户态的切换导致的成本。
- 由语言或者框架层调度
- 更小的栈空间允许创建大量实例(百万级别)
几个概念
- Continuation 这个概念不熟悉FP编程的人可能不太熟悉,不过这里可以简单的顾名思义,可以理解为让我们的程序可以暂停,然后下次调用继续(contine)从上次暂停的地方开始的一种机制。相当于程序调用多了一种入口。
- Coroutine 是Continuation的一种实现,一般表现为语言层面的组件或者类库。主要提供yield,resume机制。
- Fiber 和Coroutine其实是一体两面的,主要是从系统层面描述,可以理解成Coroutine运行之后的东西就是Fiber。
Goroutine
Goroutine其实就是前面GreenThread系列解决方案的一种演进和实现。
- 首先,它内置了Coroutine机制。因为要用户态的调度,必须有可以让代码片段可以暂停/继续的机制。
- 其次,它内置了一个调度器,实现了Coroutine的多线程并行调度,同时通过对网络等库的封装,对用户屏蔽了调度细节。
- 最后,提供了Channel机制,用于Goroutine之间通信,实现CSP并发模型(Communicating Sequential Processes)。因为Go的Channel是通过语法关键词提供的,对用户屏蔽了许多细节。其实Go的Channel和Java中的SynchronousQueue是一样的机制,如果有buffer其实就是ArrayBlockQueue。
Goroutine调度器
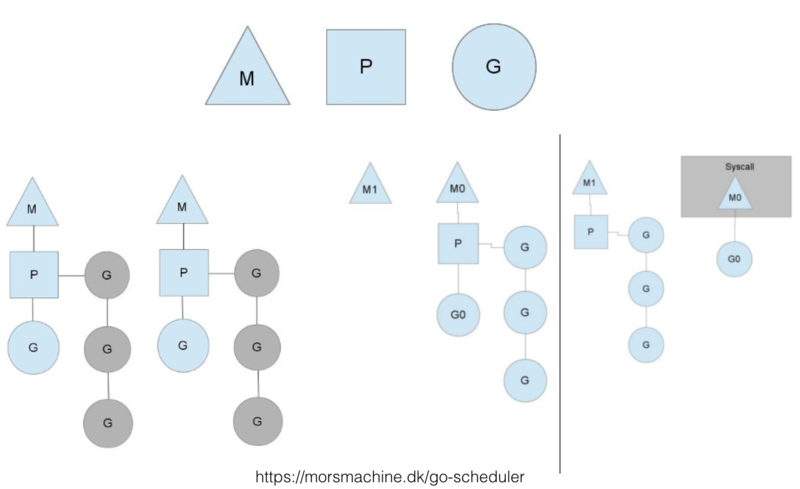
这个图一般讲Goroutine调度器的地方都会引用,想要仔细了解的可以看看原博客。这里只说明几点:
- M代表系统线程,P代表处理器(核),G代表Goroutine。Go实现了M:N的调度,也就是说线程和Goroutine之间是多对多的关系。这点在许多GreenThread/Coroutine的调度器并没有实现。比如Java1.1版本之前的线程其实是GreenThread(这个词就来源于Java),但由于没实现多对多的调度,也就是没有真正实现并行,发挥不了多核的优势,所以后来改成基于系统内核的Thread实现了。
- 某个系统线程如果被阻塞,排列在该线程上的Goroutine会被迁移。当然还有其他机制,比如M空闲了,如果全局队列没有任务,可能会从其他M偷任务执行,相当于一种rebalance机制。这里不再细说,有需要看专门的分析文章。
- 具体的实现策略和我们前面分析的机制类似。系统启动时,会启动一个独立的后台线程(不在Goroutine的调度线程池里),启动netpoll的轮询。当有Goroutine发起网络请求时,网络库会将fd(文件描述符)和pollDesc(用于描述netpoll的结构体,包含因为读/写这个fd而阻塞的Goroutine)关联起来,然后调用runtime.gopark方法,挂起当前的Goroutine。当后台的netpoll轮询获取到epoll(linux环境下)的event,会将event中的pollDesc取出来,找到关联的阻塞Goroutine,并进行恢复。
Goroutine是银弹么?
Goroutine很大程度上降低了并发的开发成本,是不是我们所有需要并发的地方直接go func就搞定了呢?
Go通过Goroutine的调度解决了CPU利用率的问题。但遇到其他的瓶颈资源如何处理?比如带锁的共享资源,比如数据库连接等。互联网在线应用场景下,如果每个请求都扔到一个Goroutine里,当资源出现瓶颈的时候,会导致大量的Goroutine阻塞,最后用户请求超时。这时候就需要用Goroutine池来进行控流,同时问题又来了:池子里设置多少个Goroutine合适?
所以这个问题还是没有从更本上解决。
Actor模型
Actor对没接触过这个概念的人可能不太好理解,Actor的概念其实和OO里的对象类似,是一种抽象。面对对象编程对现实的抽象是对象=属性+行为(method),但当使用方调用对象行为(method)的时候,其实占用的是调用方的CPU时间片,是否并发也是由调用方决定的。这个抽象其实和现实世界是有差异的。现实世界更像Actor的抽象,互相都是通过异步消息通信的。比如你对一个美女say hi,美女是否回应,如何回应是由美女自己决定的,运行在美女自己的大脑里,并不会占用发送者的大脑。
所以Actor有以下特征:
- Processing – actor可以做计算的,不需要占用调用方的CPU时间片,并发策略也是由自己决定。
- Storage – actor可以保存状态
- Communication – actor之间可以通过发送消息通讯
Actor遵循以下规则:
- 发送消息给其他的Actor
- 创建其他的Actor
- 接受并处理消息,修改自己的状态
Actor的目标:
- Actor可独立更新,实现热升级。因为Actor互相之间没有直接的耦合,是相对独立的实体,可能实现热升级。
- 无缝弥合本地和远程调用 因为Actor使用基于消息的通讯机制,无论是和本地的Actor,还是远程Actor交互,都是通过消息,这样就弥合了本地和远程的差异。
- 容错 Actor之间的通信是异步的,发送方只管发送,不关心超时以及错误,这些都由框架层和独立的错误处理机制接管。
- 易扩展,天然分布式 因为Actor的通信机制弥合了本地和远程调用,本地Actor处理不过来的时候,可以在远程节点上启动Actor然后转发消息过去。
Actor的实现:
- Erlang/OTP Actor模型的标杆,其他的实现基本上都一定程度参照了Erlang的模式。实现了热升级以及分布式。
- Akka(Scala,Java)基于线程和异步回调模式实现。由于Java中没有Fiber,所以是基于线程的。为了避免线程被阻塞,Akka中所有的阻塞操作都需要异步化。要么是Akka提供的异步框架,要么通过Future-callback机制,转换成回调模式。实现了分布式,但还不支持热升级。
- Quasar (Java) 为了解决Akka的阻塞回调问题,Quasar通过字节码增强的方式,在Java中实现了Coroutine/Fiber。同时通过ClassLoader的机制实现了热升级。缺点是系统启动的时候要通过javaagent机制进行字节码增强。
Golang CSP VS Actor
二者的格言都是:
Don’t communicate by sharing memory, share memory by communicating
通过消息通信的机制来避免竞态条件,但具体的抽象和实现上有些差异。
- CSP模型里消息和Channel是主体,处理器是匿名的。
也就是说发送方需要关心自己的消息类型以及应该写到哪个Channel,但不需要关心谁消费了它,以及有多少个消费者。Channel一般都是类型绑定的,一个Channel只写同一种类型的消息,所以CSP需要支持alt/select机制,同时监听多个Channel。Channel是同步的模式(Golang的Channel支持buffer,支持一定数量的异步),背后的逻辑是发送方非常关心消息是否被处理,CSP要保证每个消息都被正常处理了,没被处理就阻塞着。 - Actor模型里Actor是主体,Mailbox(类似于CSP的Channel)是透明的。
也就是说它假定发送方会关心消息发给谁消费了,但不关心消息类型以及通道。所以Mailbox是异步模式,发送者不能假定发送的消息一定被收到和处理。Actor模型必须支持强大的模式匹配机制,因为无论什么类型的消息都会通过同一个通道发送过来,需要通过模式匹配机制做分发。它背后的逻辑是现实世界本来就是异步的,不确定(non-deterministic)的,所以程序也要适应面对不确定的机制编程。自从有了并行之后,原来的确定编程思维模式已经受到了挑战,而Actor直接在模式中蕴含了这点。
从这样看来,CSP的模式比较适合Boss-Worker模式的任务分发机制,它的侵入性没那么强,可以在现有的系统中通过CSP解决某个具体的问题。它并不试图解决通信的超时容错问题,这个还是需要发起方进行处理。同时由于Channel是显式的,虽然可以通过netchan(原来Go提供的netchan机制由于过于复杂,被废弃,在讨论新的netchan)实现远程Channel,但很难做到对使用方透明。而Actor则是一种全新的抽象,使用Actor要面临整个应用架构机制和思维方式的变更。它试图要解决的问题要更广一些,比如容错,比如分布式。但Actor的问题在于以当前的调度效率,哪怕是用Goroutine这样的机制,也很难达到直接方法调用的效率。当前要像OO的『一切皆对象』一样实现一个『一切皆Actor』的语言,效率上肯定有问题。所以折中的方式是在OO的基础上,将系统的某个层面的组件抽象为Actor。
再扯一下Rust
Rust解决并发问题的思路是首先承认现实世界的资源总是有限的,想彻底避免资源共享是很难的,不试图完全避免资源共享,它认为并发的问题不在于资源共享,而在于错误的使用资源共享。比如我们前面提到的,大多数语言定义类型的时候,并不能限制调用方如何使用,只能通过文档或者标记的方式(比如Java中的@ThreadSafe ,@NotThreadSafe annotation)说明是否并发安全,但也只能仅仅做到提示的作用,不能阻止调用方误用。虽然Go提供了-race机制,可以通过运行单元测试的时候带上这个参数来检测竞态条件,但如果你的单元测试并发度不够,覆盖面不到也检测不出来。所以Rust的解决方案就是:
- 定义类型的时候要明确指定该类型是否是并发安全的
- 引入了变量的所有权(Ownership)概念 非并发安全的数据结构在多个线程间转移,也不一定就会导致问题,导致问题的是多个线程同时操作,也就是说是因为这个变量的所有权不明确导致的。有了所有权的概念后,变量只能由拥有所有权的作用域代码操作,而变量传递会导致所有权变更,从语言层面限制了竞态条件出现的情况。
有了这机制,Rust可以在编译期而不是运行期对竞态条件做检查和限制。虽然开发的时候增加了心智成本,但降低了调用方以及排查并发问题的心智成本,也是一种有特色的解决方案。
结论
革命尚未成功 同志任需努力
本文带大家一起回顾了并发的问题,和各种解决方案。虽然各家有各家的优势以及使用场景,但并发带来的问题还远远没到解决的程度。所以还需努力,大家也有机会啊。
最后抛个砖 构想:在Goroutine上实现Actor?
- 分布式 解决了单机效率问题,是不是可以尝试解决下分布式效率问题?
- 和容器集群融合 当前的自动伸缩方案基本上都是通过监控服务器或者LoadBalancer,设置一个阀值来实现的。类似于我前面提到的喂饭的例子,是基于经验的方案,但如果系统内和外部集群结合,这个事情就可以做的更细致和智能。
- 自管理 前面的两点最终的目标都是实现一个可以自管理的系统。做过系统运维的同学都知道,我们照顾系统就像照顾孩子一样,时刻要监控系统的各种状态,接受系统的各种报警,然后排查问题,进行紧急处理。孩子有长大的一天,那能不能让系统也自己成长,做到自管理呢?虽然这个目标现在看来还比较远,但我觉得是可以期待的。

引用以及扩展阅读
- 本文的演讲视频
- 本文的演讲pdf
- CSP model paper
- Actor model paper
- Quantifying The Cost of Context Switch
- JCSP 在Java中实现CSP模型的库
- Overview of Modern Concurrency and Parallelism Concepts
- Golang netchan 的讨论
- quasar vs akka
- golang 官方博客的 concurrency is not parallelism
- go scheduler, 文中的调度器图片来源
- handling-1-million-requests-per-minute-with-golang 一个用Goroutine的控流实践
FAQ:
高可用架构公众号网友『闯』:有个问题 想请教一下 你说1024个线程需要1G的空间作为栈空间 到时线程和进程的地址空间都是虚拟空间 当你没有真正用到这块虚地址时 是不会把物理内存页映射到虚拟内存上的 也就是说每个线程如果调用没那么深 是不会将所有栈空间关键到内存上 也就是说1024个线程实际不会消耗那么多内存
答: 你说的是对的,java的堆以及stack的内存都是虚拟内存,实际上启动一个线程不会立刻占用那么多内存。但线程是长期运行的,stack增长后,空间并不会被回收,也就是说会逐渐增加到xss的限制。这里只是说明线程的成本。另外即便是空线程(启动后就sleep),据我的测试,1核1G的服务器,启动3万多个线程左右系统就挂掉了(需要先修改系统线程最大数限制,在/proc/sys/kernel/threads-max中),和理想中的百万级别还是有很大差距的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
2015-04-02 在Sqlite中通过Replace来实现插入和更新