

c++ 移动语义 move
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | // complex constructor example#include <iostream> // std::cout#include <complex> // std::complexusing namespace std;using Complex = std::complex<double>;Complex& SumComplex_by_reference(const Complex& a, const Complex& b){ Complex result; result = Complex(a + b); return result;}//不通过引用返回,而是值返回,编译器会自动用返回值优化,有move的构造会被调用Complex SumComplex_not_reference(const Complex& a, const Complex& b){ return Complex(a + b);}int main(){ std::complex<double> a(2.0, 2.0); std::complex<double> b(a); std::complex<long double> third(b); Complex& by_ref = SumComplex_by_reference(a, b); std::cout <<"异常,用了已经释放的栈内存" << by_ref << '\n'; Complex sum = SumComplex_not_reference(a, b); std::cout <<"值返回ok" << sum << '\n'; return 0;} |
引用返回时当心栈内变量
转自:C++ moves for people who don’t know or care what rvalues are 🏘️
Moves in C++ don’t require understanding of deep technical juju to get a grasp on.
Topher Winward
Jan 17, 2019·8 min read
When I was first learning about move semantics in C++, I kept reading articles that explained in terms of other scary sounding jargon — lvalues, rvalue references, memcpy, ownership. None of these things are strictly necessary to know about to understand the core of move semantics. (Though, the more you learn about them, the greater your understanding of move semantics will become.)
You may have heard of move semantics, and may know that they’re “faster”, but not why, or even how to move something. (Here “moves” and “move semantics” mean the same thing.)
This article will deliberately simplify or ignore some concepts (like constructors, rvalue references, stack vs heap) to make the core idea of moving easier to follow, so don’t worry if you already know this stuff and see something that isn’t technically correct. I’ll mark clarifications for these with a number. This article is aimed at those writing everyday (non-library) code, with little to no existing understanding of move semantics, to help get over the initial conceptual hurdle.
Now let’s look at the most important thing about moves in C++:
The most important thing about moves in C++ 🎉
#1: Moving a value doesn’t “move” anything.
There. That is by far the biggest hurdle to overcome. In its simplest form, a move is just a copy. In its best form, a move is an optimized way to copy values that you don’t want to keep around any more.
Things to have a basic understanding of before we go forward:
You will need to be aware of:
- Pointers (that they are memory addresses, that are dereferenced)
- C style arrays (think of a block of letters next to each other in memory)
- The stack vs the heap (local function variables, vs variables that live across functions)
- Class constructors (that you can write them yourself, and that “copy constructors” exist)
A humble integer 🔧
In this very simple case, the value of a is copied into b. In memory, that would look like this animation:


Note that most of these images going forwards are animated, so don’t whiz past them.
Let’s move it!
But nothing different happened?
Exactly.
#2: Unless the type has special operations for moving object, a move is just a copy.
All primitive types — your integers, floats, pointers, and some others— do not explicitly “move”. There is no way to move a primitive that is quicker than copying it.
What’s std::move doing?
std::move takes in any value, and says “Hey — mark this as movable for now!”¹
A slightly less humble String class 🎻
Strings are incredibly difficult to get right in programming languages. We’re going to implement a dumb simple string class, that consists of a pointer to some block of chars in memory, and a length.
To save on unnecessary complexity, I won’t be sharing code for the constructor or other parts yet— they’d only distract from the main point.
Let’s see what this looks like in memory:


Stack? Heap? 📚
As a quick refresher, variables within a function live on the stack in memory. Anything created behind the new keyword will live on the heap, which exists across all function calls.²
We used new to get enough space to put 5 different char values, and then put the values h, e, l, l, o in those spaces.
Let’s copy the string
To be clear: We want to make an entirely new copy, that we can edit and do what we want to, without affecting the first. In fact, we’ll update our copied version to say “jello” instead of “hello”.
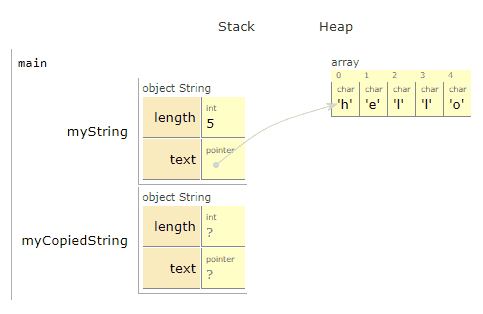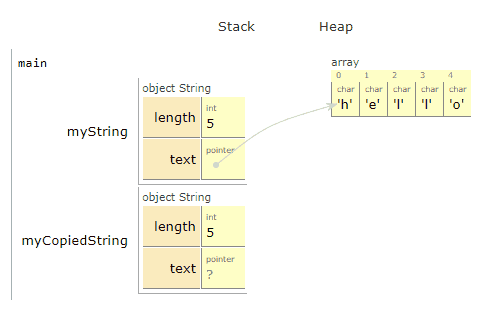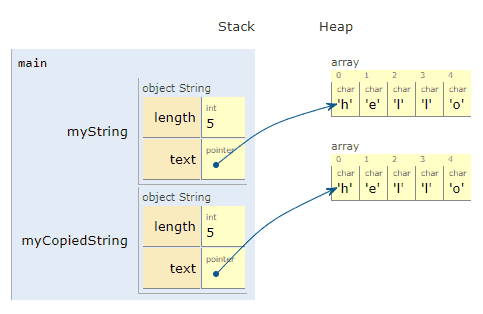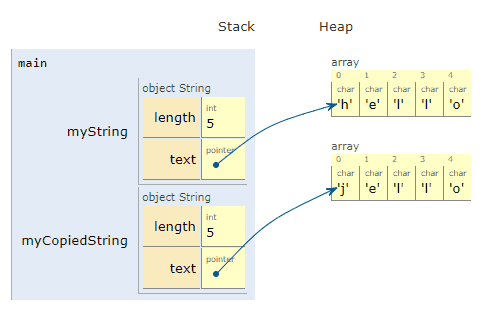
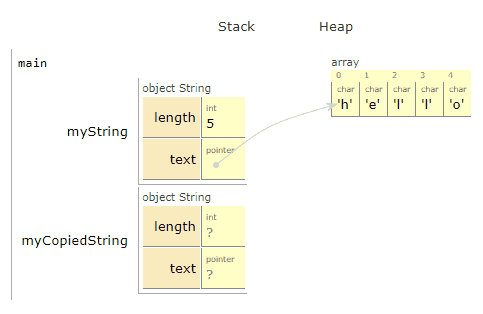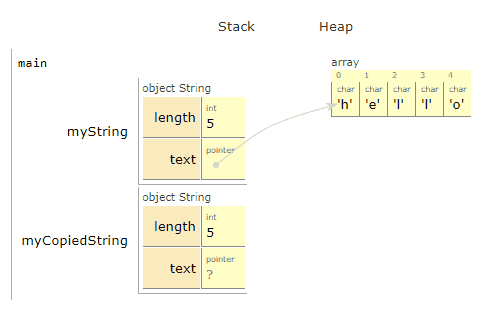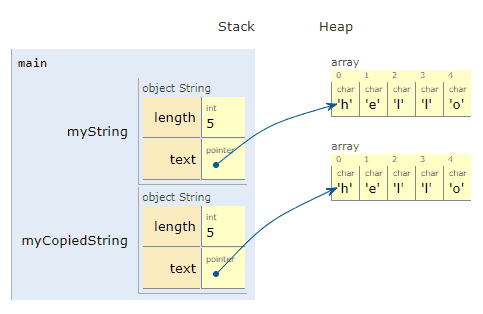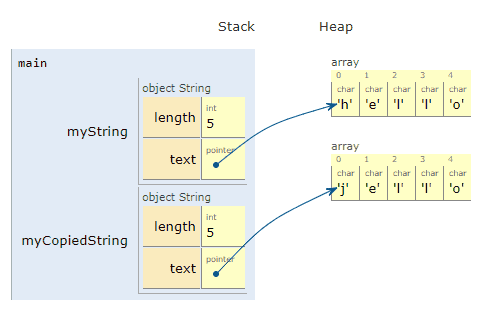
Awesome! We created a new object³, myCopiedString, on the stack. We then created a new array of characters for it on the heap, and copied each of the characters one by one from *myString.text to *myCopiedString.text.
Note, in order to do all this, I had to implement a custom copy constructor on the String class. I’ll link to this code later, as it’s not required to see right now.
Let’s move it!
Before we do, it is important to know that I have also implemented a move constructor onto String now. This is different from the copy constructor above. Without a move constructor, our code will fallback to the copy constructor.
Again, it is not important to see the code for the move constructor yet, just know that it will be called if the type is marked as movable. As above, simply wrapping the value in std::move() will do the trick.

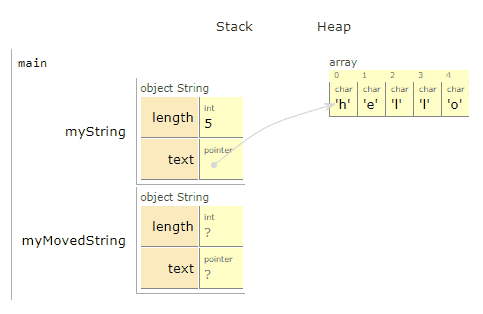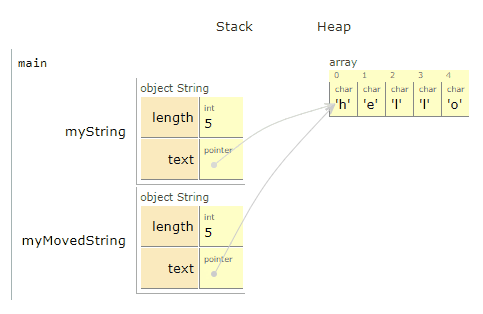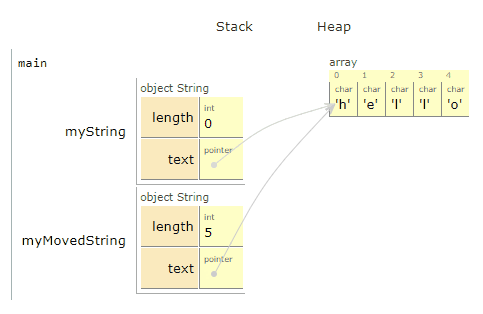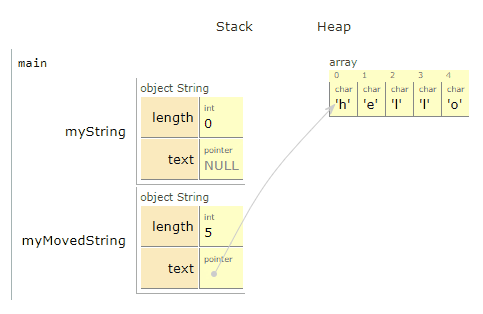
A lot happened 🔊
The key thing to note here is that "hello" never moved or got copied itself. We did not copy all 5 characters over to a new place in memory this time. Instead, we made myMovedString.text point directly at myString.text.
You may also have noticed that myString.length was then set to 0, and myString.text to nullptr. This is important to the point of moves.
#3: Use an explicit move to say “I won’t use this object after this move.”
I regularly no longer need variables — should I move them all?
No.
There are some cases where moving can actually stop certain compiler optimizations. In particular, do NOT wrap your return value in std::move in a function — in many cases, this is actually slower than returning directly.
I don’t understand why we care about the cost of copying 5 measly characters
You’re right, doing a copy of "hello" will take a negligible amount of time. But what if instead of copying that, we had to copy the entire text value of The Lord Of The Rings when we didn’t need to?
Or if instead of a String class, we had an array of LargeExpensiveToCopyObjects? In these cases, simply copying a pointer and updating a length value is clearly much faster.
Another case to consider is while copying 5 characters once may not seem a lot, it’s easy to copy 5 characters across 100 places in a codebase. Using moves where we know it is safe to do so can help save us from “death by a thousand cuts” style performance issues.
Why did myString get set to zero and null? 0️⃣
We didn’t have to touch myString at all, however we explicitly set it to some clearly incorrect state⁴. This is because we have moved it, essentially saying to the compiler and other programmers “I never want to use this variable again.”
Importantly, we have to consider double deletion of pointers. Long story short, calling delete on the same piece of memory twice will crash your program. If we have two Strings pointing at the same piece of memory, and both destruct and try to delete their own pointers — boom, you have a double delete and a crash.
Also consider nulling as a signal to other programmers. If someone else were now to accidentally use myString, they’d likely very quickly crash and realize they weren’t meant to. If we hadn’t set it to an incorrect state, we would now have two separate editable Strings pointing at the same piece of memory. Some very weird and hard to track down bugs would likely arise from this being the case.
Where are move semantics used?
Mostly where-ever ownership of an object needs to be transferred. If this sounds like a wishy-washy answer, I’m sorry I can’t (read: won’t for brevity) go into much further detail about ownership here, but I encourage you explore and learn about ownership and lifetimes.⁵
Unique pointers are a good example of something that “owns” some piece of heap memory, and that ownership can only be transferred elsewhere by moving it.
Efficient sorting algorithms like those provided by the C++ standard library will also make use of moves internally for faster swaps.
In some specific cases, having move constructors on expensive objects can aid performance, as the standard library and compiler can spot places to best use a move rather than a copy. As always, don’t rely on this blindly and profile your code if you need to be faster.
If you’re not sure whether to use a move or not, at least of one of these two cases will be true:
- 1) Not using a move will always be safe, just potentially less performant.
- 2) Your compiler will complain you’re trying to copy a movable-only object (like a unique_ptr) and you’ll have to move anyway (or you didn’t want a unique_ptr in the first place!)
#4: Use moves to transfer ownership of an object, either for semantic or performance reasons.
What is std::move really doing?
I never promised I wouldn’t mention rvalue references. This is where superscript¹ points to.
You can consider std::move(myString) to be loosely equivalent to static_cast<String&&>(myString) — it casts from type T to type T&&. This is known as an rvalue reference. When I said movable earlier, I actually just meant it was an rvalue reference type. I won’t explain more here, but hopefully this provides a good starting point for you. Here’s a neat short explanation of them.
To conclude ☄️
Move semantics as a concept are simpler than the jargon around them would suggest. I hope this explanation has given you a grounding in what move semantics are for and how they work. Further areas to explore after this might be std::swap, return value optimization (RVO), and the rule of five.
To recap:
- Moving a value doesn’t “move” anything.
- Unless the type has special operations for moving object, a move is just a copy.
- Use an explicit move to say “I won’t use this value after this move.”
- Use moves to transfer ownership of an object, either for semantic or performance reasons.
Thanks to Simon Brand, Jon Holmes and James Thomas for proofreading and providing invaluable feedback & help 😍
All visualizations were created in the fantastic PythonTutor for C++ web tool. You can see the tool visualizing this example here. Note how it uses a special emoji to signify already deleted data.
You can find the code used to perform the copy and move here:
Footnotes
- 1: As seen above, movable actually refers to rvalue references. This guide has more information on them.
- 2: The stack is known as automatic storage. The heap is dynamic storage. The new keyword does not always allocate with dynamic storage, though that is the usual implementation. More.
- 3: The term object in C++ has a specific definition, that at a high level just means “a variable”. We don’t mean object in the “object oriented” sense.
- 4: I say a moved object will be in an incorrect state afterwards. Specifically, it will be in a valid but unspecified state — it will still be part of correct, well defined behavior C++ code, but the value might just now be semantically useless.
- 5: Ownership (in my own experience at least) is a concept that seems nebulous and imprecise until you suddenly “get” it. I like this article on the subject. It clicked for me while I was learning Rust, which has very strict and explicitly defined lifetime and ownership semantics.
C++ ownership semantics
When I started programming C++ (around 1998-1999 I think) one of the most annoying things were (and in a sense, still is) memory management. It's also one of the hardest things to get right, even today.
At the time, I usually tried to stick to some hard rules, the most important one being: don't allocate things on the heap if you don't have too. Basically, if the following suits your purpose:
// Stack-allocated auto-variable. No need for manual cleanup MyType t;
... Then don't do this:
// Heap-allocation - Needs to be deleted at some point MyType* t = new MyType();
However, sometimes (certainly when working with polymorphic types) we actually need to use pointers and initialize them using new. At that point, it becomes a question of whose responsibility it is to delete the actual pointer when we're done. Because yes - someone must have that responsibility if you want to avoid memory leaks.
The stack is awesome in the sense that stack-allocated variables are easily cleaned up at the end of their defining scope. The usual way to utilize this is through smart pointers. The general idea around smart pointers is easy: Encapsulate a raw pointer inside a stack-allocated type and delete the pointer in the destructor.
There's a bunch of smart pointers out there, both in the Boost C++ library and in the standard library. I'm not going to rant about auto_ptr from C++ 03 here - there's plenty of articles describing the faulty behaviour of auto_ptr out there. It's broken, and we all know it. I'm actually not going to rant at all, but rather point out (no pun intended) some ideas around the semantics of these pointers. The reason is that I've (more than once) come across the misconception that raw pointers should never ever be used under any circumstances at all. Ever. You should only use smart pointers. I get what people are usually saying when they make that claim, but I think that a standpoint such as that one obscures the idea around ownership. I'm somewhat guilty of giving a half-assed view of this myself in a previous blogpost, where I wrote something along the lines of "Bottom line: avoid raw pointers, use smart pointers". It's not entirely wrong, but it's a lot deeper than that.
Determining ownership
It's not that raw pointers are bad, per se. It's just that they make it hard for the programmer to actually tell who the owner is. To illustrate this point, consider the class interfaces below. Since I'm in the midst of writing a 3D-renderer right now, I'll use some rendereresque class examples:| class Device | |
| { | |
| public: | |
| Device(); | |
| ~Device(); | |
| VertexBuffer* CreateVertexBuffer(const VertexDescription& desc); | |
| // ... | |
| }; | |
| class VertexBuffer | |
| { | |
| public: | |
| virtual ~VertexBuffer() {}; | |
| int VertexCount() const = 0; | |
| void Lock() = 0; | |
| void Unlock() = 0; | |
| // ... | |
| }; | |
| class Mesh | |
| { | |
| public: | |
| Mesh(VertexBuffer* const buffer); | |
| ~Mesh(); | |
| // ... | |
| }; |
The Device-class presumably creates a VertexBuffer and returns a pointer to the instance through CreateVertexBuffer. This can then be passed to another class (such as the Mesh-class through the constructor). So, we might use these classes in something resembling the following code snippet:
| Device device = new Device(); | |
| VertexBuffer* buffer = device->CreateVertexBuffer(); | |
| Mesh* mesh = new Mesh(buffer); | |
| // ... |
The problem with raw pointers becomes painfully apparent after writing a bunch of code in this style for a while. For instance, who OWNS the VertexBuffer-pointer? Who is responsible for actually cleaning up after it? Is the lifetime of the buffer-variable bound to the lifetime of the device-variable? In other words, will it be removed in the destructor of the Device class? Or is it up to you, the consumer of this instance to actually delete the pointer? At least let's hope that it's not the Mesh-destructor that removes it. That would be REALLY bad since we could actually have passed the same pointer to several Mesh-instances, leaving every other Mesh with a dangling pointer inside.
If you were to assume that the Device class handles this internally and you never delete the VertexBuffer-pointer, as shown below then one of two things will happen
| int main() | |
| { | |
| // Create the device, buffer and a mesh | |
| auto device = new Device(); | |
| auto buffer = device->CreateVertexBuffer(); | |
| auto mesh = new Mesh(buffer); | |
| // ... Doing a bunch of stuff | |
| // Cleanup | |
| delete mesh; | |
| delete device; // Assuming that the device class deletes the buffer | |
| return 0; | |
| } |
- You were correct in your assumption and the program works as expected.
- Your guess was wrong - The pointer was never deleted, and now you have a memory leak.
| int main() | |
| { | |
| // Create the device, buffer and a mesh | |
| auto device = new Device(); | |
| auto buffer = device->CreateVertexBuffer(); | |
| auto mesh = new Mesh(buffer); | |
| // ... Doing a bunch of stuff | |
| // Cleanup | |
| delete mesh; | |
| delete buffer; // Assuming that device doesn't remove this pointer | |
| delete device; | |
| return 0; | |
| } |
- You were correct in your assumption and the program works as expected.
- Your guess was wrong - The device class WILL try and delete the pointer. But since you've already done that, it'll try to delete a dangling pointer, and your program would most likely crash.
Smart pointers
The ones I'm going to focus on are the two widely used unique_ptr and shared_ptr. I tend to use unique_ptr in a lot more places than I do with shared_ptr - I'll try to explain why in a while. A short description of these pointers is in place:
- unique_ptr encapsulates a raw pointer and can't be copied. Trying to assign one unique_ptr to another will give a compile error. It basically replaces the deprecated auto_ptr, but which much clearer semantics. A pointer of this type CAN be moved though, meaning that it gives up ownership of its inner pointer to another unique_ptr instance. This has to be done explicitly by the developer by using std::move
- As opposed to unique_ptr, shared_ptr can be copied. It involves somewhat more overhead since it relies on reference counting. Everytime a shared_ptr runs out of scope, the reference counter goes down. Or, in the case of 0 references, the pointer is deleted.
| #include <memory> | |
| class Device | |
| { | |
| public: | |
| Device(); | |
| ~Device(); | |
| std::unique_ptr<VertexBuffer> CreateVertexBuffer(const VertexDescription& desc); | |
| }; |
Basically, the Device type is now telling us that WE are the sole owners of the buffer. It's in our control and it's up to us what will happen from this point forward. Now, it's easy to think that this unique_ptr is only useful in one scope only, since it is apparently unique and can't be copied. But I have to pass a VertexBuffer* to the Mesh implementation, and obviously I can't change the signature to take a unique_ptr and pass the unique_ptr I obtained from Device on - That would be a copy operation.
And no - I'm not going to tell you to use a shared_ptr instead, even though it would work. Since we are then doing reference counting instead, we actually can't claim to have "sole ownership" anymore. A shared_ptr more or less means shared ownership. So here is the thing: I don't really think that leaving the Mesh interface as-is is a bad thing in this case, simply because it is not the owner! Let's look at a snippet of code again, assuming that we're now returning a unique_ptr from Device. I'll also use a unique_ptr to create my Device and Mesh (I'll explain my reasons for this later on)
| #include <memory> | |
| int main() | |
| { | |
| // Create the device, buffer and a mesh | |
| auto device = std::unique_ptr<Device>(new Device()); | |
| auto buffer = device->CreateVertexBuffer(); | |
| auto mesh = std::unique_ptr<Mesh>(new Mesh(buffer.get())); | |
| // ... Doing a bunch of stuff | |
| // No cleanup necessary | |
| return 0; | |
| } |
Finally - There's still the option to use the shared_ptr and its reference counter. It also has a corresponding weak_ptr that lets you model a temporary ownership (and to break circular references of shared_ptr). As I said before, I usually prefer the unique_ptr, and the reason is simply because it's much clearer in its ownership semantics. Using a shared_ptr by default implies a shared ownership of a pointer, which muddles the boundaries of ownership. When talking to people about shared pointers, I sometimes get the distinct feeling that some programmer's uses them to mimic the way they would write code in a garbage collected language, such as C# or Java. However, just a ref-counter does not a GC make, and we shouldn't suddenly pretend that we can use a shared_ptr and do away with memory issues.
Don't get me wrong - There are times when the shared_ptr is just the thing to use. I just think those times are far apart.
Anyway - This is basically my interpretation of the whole RAII-idiom and the usage of smart pointers. I think smart pointers are a great help in memory management, but not ONLY for the simple reason that they "get cleaned up automatically". I think it all comes down to semantics and understanding how your code is partitioned, and not necessarily on "smart pointers vs. raw pointers", which a lot of debates (but not all of them) seem to focus on.
My take on this might of course be flawed, and I'm always up for discussion. So please, do comment ;)
什么是move
find it easiest to understand move semantics with example code. Let's start with a very simple string class which only holds a pointer to a heap-allocated block of memory:
#include <cstring> #include <algorithm> class string { char* data; public: string(const char* p) { size_t size = std::strlen(p) + 1; data = new char[size]; std::memcpy(data, p, size); }
Since we chose to manage the memory ourselves, we need to follow the rule of three. I am going to defer writing the assignment operator and only implement the destructor and the copy constructor for now:
~string() { delete[] data; } string(const string& that) { size_t size = std::strlen(that.data) + 1; data = new char[size]; std::memcpy(data, that.data, size); }
The copy constructor defines what it means to copy string objects. The parameter const string& that binds to all expressions of type string which allows you to make copies in the following examples:
string a(x); // Line 1 string b(x + y); // Line 2 string c(some_function_returning_a_string()); // Line 3
Now comes the key insight into move semantics. Note that only in the first line where we copy x is this deep copy really necessary, because we might want to inspect x later and would be very surprised if x had changed somehow. Did you notice how I just said x three times (four times if you include this sentence) and meant the exact same object every time? We call expressions such as x "lvalues".
The arguments in lines 2 and 3 are not lvalues, but rvalues, because the underlying string objects have no names, so the client has no way to inspect them again at a later point in time. rvalues denote temporary objects which are destroyed at the next semicolon (to be more precise: at the end of the full-expression that lexically contains the rvalue). This is important because during the initialization of b and c, we could do whatever we wanted with the source string, and the client couldn't tell a difference!
C++0x introduces a new mechanism called "rvalue reference" which, among other things, allows us to detect rvalue arguments via function overloading. All we have to do is write a constructor with an rvalue reference parameter. Inside that constructor we can do anything we want with the source, as long as we leave it in some valid state:
string(string&& that) // string&& is an rvalue reference to a string { data = that.data; that.data = nullptr; }
What have we done here? Instead of deeply copying the heap data, we have just copied the pointer and then set the original pointer to null (to prevent 'delete[]' from source object's destructor from releasing our 'just stolen data'). In effect, we have "stolen" the data that originally belonged to the source string. Again, the key insight is that under no circumstance could the client detect that the source had been modified. Since we don't really do a copy here, we call this constructor a "move constructor". Its job is to move resources from one object to another instead of copying them.
Congratulations, you now understand the basics of move semantics! Let's continue by implementing the assignment operator. If you're unfamiliar with the copy and swap idiom, learn it and come back, because it's an awesome C++ idiom related to exception safety.
string& operator=(string that) { std::swap(data, that.data); return *this; } };
Huh, that's it? "Where's the rvalue reference?" you might ask. "We don't need it here!" is my answer :)
Note that we pass the parameter that by value, so that has to be initialized just like any other string object. Exactly how is that going to be initialized? In the olden days of C++98, the answer would have been "by the copy constructor". In C++0x, the compiler chooses between the copy constructor and the move constructor based on whether the argument to the assignment operator is an lvalue or an rvalue.
So if you say a = b, the copy constructor will initialize that (because the expression b is an lvalue), and the assignment operator swaps the contents with a freshly created, deep copy. That is the very definition of the copy and swap idiom -- make a copy, swap the contents with the copy, and then get rid of the copy by leaving the scope. Nothing new here.
But if you say a = x + y, the move constructor will initialize that (because the expression x + y is an rvalue), so there is no deep copy involved, only an efficient move. that is still an independent object from the argument, but its construction was trivial, since the heap data didn't have to be copied, just moved. It wasn't necessary to copy it because x + y is an rvalue, and again, it is okay to move from string objects denoted by rvalues.
To summarize, the copy constructor makes a deep copy, because the source must remain untouched. The move constructor, on the other hand, can just copy the pointer and then set the pointer in the source to null. It is okay to "nullify" the source object in this manner, because the client has no way of inspecting the object again.
I hope this example got the main point across. There is a lot more to rvalue references and move semantics which I intentionally left out to keep it simple. If you want more details please see my supplementary answer.
My first answer was an extremely simplified introduction to move semantics, and many details were left out on purpose to keep it simple. However, there is a lot more to move semantics, and I thought it was time for a second answer to fill the gaps. The first answer is already quite old, and it did not feel right to simply replace it with a completely different text. I think it still serves well as a first introduction. But if you want to dig deeper, read on :)
Stephan T. Lavavej took the time to provide valuable feedback. Thank you very much, Stephan!
Introduction
Move semantics allows an object, under certain conditions, to take ownership of some other object's external resources. This is important in two ways:
-
Turning expensive copies into cheap moves. See my first answer for an example. Note that if an object does not manage at least one external resource (either directly, or indirectly through its member objects), move semantics will not offer any advantages over copy semantics. In that case, copying an object and moving an object means the exact same thing:
class cannot_benefit_from_move_semantics { int a; // moving an int means copying an int float b; // moving a float means copying a float double c; // moving a double means copying a double char d[64]; // moving a char array means copying a char array // ... }; -
Implementing safe "move-only" types; that is, types for which copying does not make sense, but moving does. Examples include locks, file handles, and smart pointers with unique ownership semantics. Note: This answer discusses
std::auto_ptr, a deprecated C++98 standard library template, which was replaced bystd::unique_ptrin C++11. Intermediate C++ programmers are probably at least somewhat familiar withstd::auto_ptr, and because of the "move semantics" it displays, it seems like a good starting point for discussing move semantics in C++11. YMMV.
What is a move?
The C++98 standard library offers a smart pointer with unique ownership semantics called std::auto_ptr<T>. In case you are unfamiliar with auto_ptr, its purpose is to guarantee that a dynamically allocated object is always released, even in the face of exceptions:
{ std::auto_ptr<Shape> a(new Triangle); // ... // arbitrary code, could throw exceptions // ... } // <--- when a goes out of scope, the triangle is deleted automatically
The unusual thing about auto_ptr is its "copying" behavior:
auto_ptr<Shape> a(new Triangle); +---------------+ | triangle data | +---------------+ ^ | | | +-----|---+ | +-|-+ | a | p | | | | | +---+ | +---------+ auto_ptr<Shape> b(a); +---------------+ | triangle data | +---------------+ ^ | +----------------------+ | +---------+ +-----|---+ | +---+ | | +-|-+ | a | p | | | b | p | | | | | +---+ | | +---+ | +---------+ +---------+
Note how the initialization of b with a does not copy the triangle, but instead transfers the ownership of the triangle from a to b. We also say "a is moved into b" or "the triangle is moved from a to b". This may sound confusing because the triangle itself always stays at the same place in memory.
To move an object means to transfer ownership of some resource it manages to another object.
The copy constructor of auto_ptr probably looks something like this (somewhat simplified):
auto_ptr(auto_ptr& source) // note the missing const { p = source.p; source.p = 0; // now the source no longer owns the object }
Dangerous and harmless moves
The dangerous thing about auto_ptr is that what syntactically looks like a copy is actually a move. Trying to call a member function on a moved-from auto_ptr will invoke undefined behavior, so you have to be very careful not to use an auto_ptr after it has been moved from:
auto_ptr<Shape> a(new Triangle); // create triangle auto_ptr<Shape> b(a); // move a into b double area = a->area(); // undefined behavior
But auto_ptr is not always dangerous. Factory functions are a perfectly fine use case for auto_ptr:
auto_ptr<Shape> make_triangle() { return auto_ptr<Shape>(new Triangle); } auto_ptr<Shape> c(make_triangle()); // move temporary into c double area = make_triangle()->area(); // perfectly safe
Note how both examples follow the same syntactic pattern:
auto_ptr<Shape> variable(expression); double area = expression->area();
And yet, one of them invokes undefined behavior, whereas the other one does not. So what is the difference between the expressions a and make_triangle()? Aren't they both of the same type? Indeed they are, but they have different value categories.
Value categories
Obviously, there must be some profound difference between the expression a which denotes an auto_ptr variable, and the expression make_triangle() which denotes the call of a function that returns an auto_ptr by value, thus creating a fresh temporary auto_ptr object every time it is called. a is an example of an lvalue, whereas make_triangle() is an example of an rvalue.
Moving from lvalues such as a is dangerous, because we could later try to call a member function via a, invoking undefined behavior. On the other hand, moving from rvalues such as make_triangle() is perfectly safe, because after the copy constructor has done its job, we cannot use the temporary again. There is no expression that denotes said temporary; if we simply write make_triangle() again, we get a different temporary. In fact, the moved-from temporary is already gone on the next line:
auto_ptr<Shape> c(make_triangle()); ^ the moved-from temporary dies right here
Note that the letters l and r have a historic origin in the left-hand side and right-hand side of an assignment. This is no longer true in C++, because there are lvalues that cannot appear on the left-hand side of an assignment (like arrays or user-defined types without an assignment operator), and there are rvalues which can (all rvalues of class types with an assignment operator).
An rvalue of class type is an expression whose evaluation creates a temporary object. Under normal circumstances, no other expression inside the same scope denotes the same temporary object.
Rvalue references
We now understand that moving from lvalues is potentially dangerous, but moving from rvalues is harmless. If C++ had language support to distinguish lvalue arguments from rvalue arguments, we could either completely forbid moving from lvalues, or at least make moving from lvalues explicit at call site, so that we no longer move by accident.
C++11's answer to this problem is rvalue references. An rvalue reference is a new kind of reference that only binds to rvalues, and the syntax is X&&. The good old reference X& is now known as an lvalue reference. (Note that X&& is not a reference to a reference; there is no such thing in C++.)
If we throw const into the mix, we already have four different kinds of references. What kinds of expressions of type X can they bind to?
lvalue const lvalue rvalue const rvalue --------------------------------------------------------- X& yes const X& yes yes yes yes X&& yes const X&& yes yes
In practice, you can forget about const X&&. Being restricted to read from rvalues is not very useful.
An rvalue reference
X&&is a new kind of reference that only binds to rvalues.
Implicit conversions
Rvalue references went through several versions. Since version 2.1, an rvalue reference X&& also binds to all value categories of a different type Y, provided there is an implicit conversion from Y to X. In that case, a temporary of type X is created, and the rvalue reference is bound to that temporary:
void some_function(std::string&& r); some_function("hello world");
In the above example, "hello world" is an lvalue of type const char[12]. Since there is an implicit conversion from const char[12] through const char* to std::string, a temporary of type std::string is created, and r is bound to that temporary. This is one of the cases where the distinction between rvalues (expressions) and temporaries (objects) is a bit blurry.
Move constructors
A useful example of a function with an X&& parameter is the move constructor X::X(X&& source). Its purpose is to transfer ownership of the managed resource from the source into the current object.
In C++11, std::auto_ptr<T> has been replaced by std::unique_ptr<T> which takes advantage of rvalue references. I will develop and discuss a simplified version of unique_ptr. First, we encapsulate a raw pointer and overload the operators -> and *, so our class feels like a pointer:
template<typename T> class unique_ptr { T* ptr; public: T* operator->() const { return ptr; } T& operator*() const { return *ptr; }
The constructor takes ownership of the object, and the destructor deletes it:
explicit unique_ptr(T* p = nullptr) { ptr = p; } ~unique_ptr() { delete ptr; }
Now comes the interesting part, the move constructor:
unique_ptr(unique_ptr&& source) // note the rvalue reference { ptr = source.ptr; source.ptr = nullptr; }
This move constructor does exactly what the auto_ptr copy constructor did, but it can only be supplied with rvalues:
unique_ptr<Shape> a(new Triangle); unique_ptr<Shape> b(a); // error unique_ptr<Shape> c(make_triangle()); // okay
The second line fails to compile, because a is an lvalue, but the parameter unique_ptr&& source can only be bound to rvalues. This is exactly what we wanted; dangerous moves should never be implicit. The third line compiles just fine, because make_triangle() is an rvalue. The move constructor will transfer ownership from the temporary to c. Again, this is exactly what we wanted.
The move constructor transfers ownership of a managed resource into the current object.
Move assignment operators
The last missing piece is the move assignment operator. Its job is to release the old resource and acquire the new resource from its argument:
unique_ptr& operator=(unique_ptr&& source) // note the rvalue reference { if (this != &source) // beware of self-assignment { delete ptr; // release the old resource ptr = source.ptr; // acquire the new resource source.ptr = nullptr; } return *this; } };
Note how this implementation of the move assignment operator duplicates logic of both the destructor and the move constructor. Are you familiar with the copy-and-swap idiom? It can also be applied to move semantics as the move-and-swap idiom:
unique_ptr& operator=(unique_ptr source) // note the missing reference { std::swap(ptr, source.ptr); return *this; } };
Now that source is a variable of type unique_ptr, it will be initialized by the move constructor; that is, the argument will be moved into the parameter. The argument is still required to be an rvalue, because the move constructor itself has an rvalue reference parameter. When control flow reaches the closing brace of operator=, source goes out of scope, releasing the old resource automatically.
The move assignment operator transfers ownership of a managed resource into the current object, releasing the old resource. The move-and-swap idiom simplifies the implementation.
Moving from lvalues
Sometimes, we want to move from lvalues. That is, sometimes we want the compiler to treat an lvalue as if it were an rvalue, so it can invoke the move constructor, even though it could be potentially unsafe. For this purpose, C++11 offers a standard library function template called std::move inside the header <utility>. This name is a bit unfortunate, because std::move simply casts an lvalue to an rvalue; it does not move anything by itself. It merely enables moving. Maybe it should have been named std::cast_to_rvalue or std::enable_move, but we are stuck with the name by now.
Here is how you explicitly move from an lvalue:
unique_ptr<Shape> a(new Triangle); unique_ptr<Shape> b(a); // still an error unique_ptr<Shape> c(std::move(a)); // okay
Note that after the third line, a no longer owns a triangle. That's okay, because by explicitly writing std::move(a), we made our intentions clear: "Dear constructor, do whatever you want with a in order to initialize c; I don't care about a anymore. Feel free to have your way with a."
std::move(some_lvalue)casts an lvalue to an rvalue, thus enabling a subsequent move.
Xvalues
Note that even though std::move(a) is an rvalue, its evaluation does not create a temporary object. This conundrum forced the committee to introduce a third value category. Something that can be bound to an rvalue reference, even though it is not an rvalue in the traditional sense, is called an xvalue (eXpiring value). The traditional rvalues were renamed to prvalues (Pure rvalues).
Both prvalues and xvalues are rvalues. Xvalues and lvalues are both glvalues (Generalized lvalues). The relationships are easier to grasp with a diagram:
expressions / \ / \ / \ glvalues rvalues / \ / \ / \ / \ / \ / \ lvalues xvalues prvalues
Note that only xvalues are really new; the rest is just due to renaming and grouping.
C++98 rvalues are known as prvalues in C++11. Mentally replace all occurrences of "rvalue" in the preceding paragraphs with "prvalue".
Moving out of functions
So far, we have seen movement into local variables, and into function parameters. But moving is also possible in the opposite direction. If a function returns by value, some object at call site (probably a local variable or a temporary, but could be any kind of object) is initialized with the expression after the return statement as an argument to the move constructor:
unique_ptr<Shape> make_triangle() { return unique_ptr<Shape>(new Triangle); } \-----------------------------/ | | temporary is moved into c | v unique_ptr<Shape> c(make_triangle());
Perhaps surprisingly, automatic objects (local variables that are not declared as static) can also be implicitly moved out of functions:
unique_ptr<Shape> make_square() { unique_ptr<Shape> result(new Square); return result; // note the missing std::move }
How come the move constructor accepts the lvalue result as an argument? The scope of result is about to end, and it will be destroyed during stack unwinding. Nobody could possibly complain afterward that result had changed somehow; when control flow is back at the caller, result does not exist anymore! For that reason, C++11 has a special rule that allows returning automatic objects from functions without having to write std::move. In fact, you should never use std::move to move automatic objects out of functions, as this inhibits the "named return value optimization" (NRVO).
Never use
std::moveto move automatic objects out of functions.
Note that in both factory functions, the return type is a value, not an rvalue reference. Rvalue references are still references, and as always, you should never return a reference to an automatic object; the caller would end up with a dangling reference if you tricked the compiler into accepting your code, like this:
unique_ptr<Shape>&& flawed_attempt() // DO NOT DO THIS! { unique_ptr<Shape> very_bad_idea(new Square); return std::move(very_bad_idea); // WRONG! }
Never return automatic objects by rvalue reference. Moving is exclusively performed by the move constructor, not by
std::move, and not by merely binding an rvalue to an rvalue reference.
Moving into members
Sooner or later, you are going to write code like this:
class Foo { unique_ptr<Shape> member; public: Foo(unique_ptr<Shape>&& parameter) : member(parameter) // error {} };
Basically, the compiler will complain that parameter is an lvalue. If you look at its type, you see an rvalue reference, but an rvalue reference simply means "a reference that is bound to an rvalue"; it does not mean that the reference itself is an rvalue! Indeed, parameter is just an ordinary variable with a name. You can use parameter as often as you like inside the body of the constructor, and it always denotes the same object. Implicitly moving from it would be dangerous, hence the language forbids it.
A named rvalue reference is an lvalue, just like any other variable.
The solution is to manually enable the move:
class Foo { unique_ptr<Shape> member; public: Foo(unique_ptr<Shape>&& parameter) : member(std::move(parameter)) // note the std::move {} };
You could argue that parameter is not used anymore after the initialization of member. Why is there no special rule to silently insert std::move just as with return values? Probably because it would be too much burden on the compiler implementors. For example, what if the constructor body was in another translation unit? By contrast, the return value rule simply has to check the symbol tables to determine whether or not the identifier after the return keyword denotes an automatic object.
You can also pass the parameter by value. For move-only types like unique_ptr, it seems there is no established idiom yet. Personally, I prefer to pass by value, as it causes less clutter in the interface.
Special member functions
C++98 implicitly declares three special member functions on demand, that is, when they are needed somewhere: the copy constructor, the copy assignment operator, and the destructor.
X::X(const X&); // copy constructor X& X::operator=(const X&); // copy assignment operator X::~X(); // destructor
Rvalue references went through several versions. Since version 3.0, C++11 declares two additional special member functions on demand: the move constructor and the move assignment operator. Note that neither VC10 nor VC11 conforms to version 3.0 yet, so you will have to implement them yourself.
X::X(X&&); // move constructor X& X::operator=(X&&); // move assignment operator
These two new special member functions are only implicitly declared if none of the special member functions are declared manually. Also, if you declare your own move constructor or move assignment operator, neither the copy constructor nor the copy assignment operator will be declared implicitly.
What do these rules mean in practice?
If you write a class without unmanaged resources, there is no need to declare any of the five special member functions yourself, and you will get correct copy semantics and move semantics for free. Otherwise, you will have to implement the special member functions yourself. Of course, if your class does not benefit from move semantics, there is no need to implement the special move operations.
Note that the copy assignment operator and the move assignment operator can be fused into a single, unified assignment operator, taking its argument by value:
X& X::operator=(X source) // unified assignment operator { swap(source); // see my first answer for an explanation return *this; }
This way, the number of special member functions to implement drops from five to four. There is a tradeoff between exception-safety and efficiency here, but I am not an expert on this issue.
Forwarding references (previously known as Universal references)
Consider the following function template:
template<typename T> void foo(T&&);
You might expect T&& to only bind to rvalues, because at first glance, it looks like an rvalue reference. As it turns out though, T&& also binds to lvalues:
foo(make_triangle()); // T is unique_ptr<Shape>, T&& is unique_ptr<Shape>&& unique_ptr<Shape> a(new Triangle); foo(a); // T is unique_ptr<Shape>&, T&& is unique_ptr<Shape>&
If the argument is an rvalue of type X, T is deduced to be X, hence T&& means X&&. This is what anyone would expect. But if the argument is an lvalue of type X, due to a special rule, T is deduced to be X&, hence T&& would mean something like X& &&. But since C++ still has no notion of references to references, the type X& && is collapsed into X&. This may sound confusing and useless at first, but reference collapsing is essential for perfect forwarding (which will not be discussed here).
T&& is not an rvalue reference, but a forwarding reference. It also binds to lvalues, in which case
TandT&&are both lvalue references.
If you want to constrain a function template to rvalues, you can combine SFINAE with type traits:
#include <type_traits> template<typename T> typename std::enable_if<std::is_rvalue_reference<T&&>::value, void>::type foo(T&&);
Implementation of move
Now that you understand reference collapsing, here is how std::move is implemented:
template<typename T> typename std::remove_reference<T>::type&& move(T&& t) { return static_cast<typename std::remove_reference<T>::type&&>(t); }
As you can see, move accepts any kind of parameter thanks to the forwarding reference T&&, and it returns an rvalue reference. The std::remove_reference<T>::type meta-function call is necessary because otherwise, for lvalues of type X, the return type would be X& &&, which would collapse into X&. Since t is always an lvalue (remember that a named rvalue reference is an lvalue), but we want to bind t to an rvalue reference, we have to explicitly cast t to the correct return type. The call of a function that returns an rvalue reference is itself an xvalue. Now you know where xvalues come from ;)
The call of a function that returns an rvalue reference, such as
std::move, is an xvalue.
Note that returning by rvalue reference is fine in this example, because t does not denote an automatic object, but instead an object that was passed in by the caller.
转自:Understanding when not to std::move in C++
 CC0
CC0One of the most important concepts introduced in C++11 was move semantics. Move semantics is a way to avoid expensive deep copy operations and replace them with cheaper move operations. Essentially, you can think of it as turning a deep copy into a shallow copy.
Move semantics came along with several more or less related features, such as rvalue references, xvalues, forwarding references, perfect forwarding, and so on. The standard C++ library gained a function template called std::move, which, despite its name, does not move anything. std::move merely casts its argument to an rvalue reference to allow moving it, but doesn't guarantee a move operation. For example, we can write a more effective version of swap using std::move:
template<typename T>
void swap(T& a, T& b)
{
T t(std::move (a));
a = std::move (b);
b = std::move (t);
}
This version of swap consists of one move construction and two move assignments and does not involve any deep copies. All is well. However, std::move must be used judiciously; using it blithely may lead to performance degradation, or simply be redundant, affecting readability of the code. Fortunately, the compiler can sometimes help with finding such wrong uses of std::move. In this article, I will introduce two new warnings I've implemented for GCC 9 that deal with incorrect usage of std::move.
-Wpessimizing-move
When returning a local variable of the same class type as the function return type, the compiler is free to omit any copying or moving (i.e., perform copy/move elision), if the variable we are returning is a non-volatile automatic object and is not a function parameter. In such a case, the compiler can construct the object directly in its final destination (i.e., in the caller's stack frame). The compiler is free to perform this optimization even when the move/copy construction has side effects. Additionally, C++17 says that copy elision is mandatory in certain situations. This is what we call Named Return Value Optimization (NRVO). (Note that this optimization does not depend on any of the -O levels.) For instance:
struct T {
// ...
};
T fn()
{
T t;
return t;
}
T t = fn ();
The object a function returns doesn't need to have a name. For example, the return statement in the function fn above might be return T(); and copy elision would still apply. In this case, this optimization is simply Return Value Optimization (RVO).
Some programmers might be tempted to "optimize" the code by putting std::move into the return statement like this:
T fn()
{
T t;
return std::move (t);
}
However, here the call to std::move precludes the NRVO, because it breaks the conditions specified in the C++ standard, namely [class.copy.elision]: the returned expression must be a name. The reason for this is that std::move returns a reference, and in general, the compiler can't know to what object the function returns a reference to. So GCC 9 will issue a warning (when -Wall is in effect):
t.C:8:20: warning: moving a local object in a return statement prevents copy elision [-Wpessimizing-move] 8 | return std::move (t); | ~~~~~~~~~~^~~ t.C:8:20: note: remove ‘std::move’ call
-Wredundant-move
When the class object that a function returns is a function parameter, copy elision is not possible. However, when all the other conditions for the RVO are satisfied, C++ (as per the resolution of Core Issue 1148) says that a move operation should be used: overload resolution is performed as if the object were an rvalue (this is known as two-stage overload resolution). The parameter is an lvalue (because it has a name), but it's about to be destroyed. Thus, the compiler ought to treat is as an rvalue.
For instance:
struct T {
T(const T&) = delete;
T(T&&);
};
T fn(T t)
{
return t; // move used implicitly
}
Explicitly using return std::move (t); here would not be pessimizing—a move would be used in any case—it is merely redundant. The compiler can now point that out using the new warning -Wredundant-move, enabled by -Wextra:
r.C:8:21: warning: redundant move in return statement [-Wredundant-move] 8 | return std::move(t); // move used implicitly | ~~~~~~~~~^~~ r.C:8:21: note: remove ‘std::move’ call
Because the GNU C++ compiler implements Core Issue 1579, the following call to std::move is also redundant:
struct U { };
struct T { operator U(); };
U f()
{
T t;
return std::move (t);
}
Copy elision isn't possible here because the types T and U don't match. But, the rules for the implicit rvalue treatment are less strict than the rules for the RVO, and the call to std::move is not necessary.
There are situations where returning std::move (expr) makes sense, however. The rules for the implicit move require that the selected constructor take an rvalue reference to the returned object's type. Sometimes that isn't the case. For example, when a function returns an object whose type is a class derived from the class type the function returns. In that case, overload resolution is performed a second time, this time treating the object as an lvalue:
struct U { };
struct T : U { };
U f()
{
T t;
return std::move (t);
}
While in general std::move is a great addition to the language, it's not always appropriate to use it, and, sadly, the rules are fairly complicated. Fortunately, the compiler is able to recognize the contexts where a call to std::move would either prevent elision of a move or a copy—or would actually not make a difference—and warns appropriately. Therefore, we recommend enabling these warnings and perhaps adjusting the code base. The reward may be a minor performance gain and cleaner code. GCC 9 will be part of Fedora 30, but you can try it right now on Godbolt.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?