

logstash的output配置中指定elasticsearch的template
转自:https://blog.csdn.net/felix_yujing/article/details/78930389
之前采用的是通过filebeat收集nginx的日志,直接到elasticsearch。filebeat带有nginx的module模块,通过这个nginx模块实现filebeat对nginx日志中字段的处理。最近由于一些实际的使用场景和需求,对nginx日志的收集和处理方式做了一下调整:
filebeat收集nginx原始日志信息到kafka,然后logstash再从kafka读取日志,并进行字段处理后送到elasticsearch集群。即相比原来的方式,添加了kafka层。
logstash从kafka读取过来的日志为json格式,字段的解析可以借助Grok Debugger工具来调,具体的解析方式这里就不细说了。这里主要说一下在logstash使用elasticsearch的template进行字段类型mapping的时候,需要注意的一点问题。
logstash将日志里的字段解析出来并发送到elasticsearch后,发现es上字段的默认的类型都是text的。如果对一些关键字需要做统计报表的时候,就会出现提示报错。如,我用grafana将elasticsearch做为数据源进行数据展示时遇到如下报错: 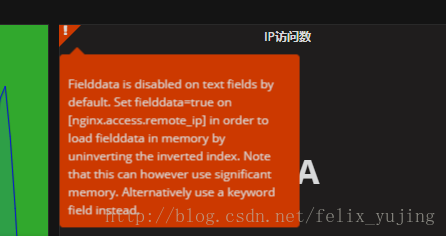
有报错提示可以看出,将nginx.access.remote_ip的字段换成keyword类型可以解决。
于是,参考原先filebeat中使用的template,写了一个供logstash用的template,起名为nginx_req_log_wireless.json,部分片段如下:
"template": "nginx_req_log_wireless", "settings": { "index.refresh_interval": "5s" }, "mappings": { ...略 "nginx": { "properties": { "access": { "properties": { "referrer": { "ignore_above": 1024, "type": "keyword" }, "agent": { "norms": false, "type": "text" }, "response_code": { "type": "long" }, "geoip": { "properties": { "continent_name": { "ignore_above": 1024, "type": "keyword" }, "city_name": { "ignore_above": 1024, "type": "keyword" }, "country_name": { "ignore_above": 1024, "type": "keyword" }, "region_name": { "ignore_above": 1024, "type": "keyword" }, "location": { "type": "geo_point" } } }, "remote_ip": { "ignore_above": 1024, "type": "keyword" }, "method": { "ignore_above": 1024, "type": "keyword" }, "user_name": { "ignore_above": 1024, "type": "keyword" }, "http_version": { "ignore_above": 1024, "type": "keyword" }, "body_sent": { "properties": { "bytes": { "type": "long" } } }, "url": { "ignore_above": 1024, "type": "keyword" } ...略
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
之后,在logstash的output里的elasticsearch配置部分对template模板进行指定:
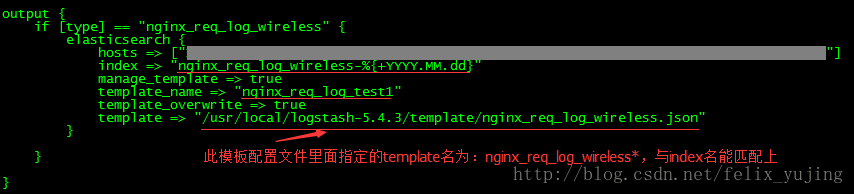
index => "nginx_req_log_wireless-%{+YYYY.MM.dd}" manage_template => true template_name => "nginx_req_log_wireless" template_overwrite => true template => "/usr/local/logstash-5.4.3/template/nginx_req_log_wireless.json"
- 1
- 2
- 3
- 4
- 5
调试后发现,elasticsearch上创建的索引中字段的类型,并没有按照指定的template去mapping。后来才注意到,是应为创建的索引后面带了日期部分:
index => "nginx_req_log_wireless-%{+YYYY.MM.dd}"
- 1
这导致跟nginx_req_log_wireless.json模板文件中指定的template名并不匹配造成的:
"template": "nginx_req_log_wireless"
- 1
解决办法,就是将template名末尾加一个*号通配符即可:
"template": "nginx_req_log_wireless*"
- 1
总结一下:
index的名字必须要和指定的json文件中的templete名相匹配,定义的mapping才会生效。logstash的output配置的template_name名可以随便。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
2014-03-28 C++类间相互引用