ELK-filebeat收集日志到Kafka,并转存ES
https://blog.51cto.com/tryingstuff/2052271
在有些不需要安装java环境的服务器如Nginx,php等为主的web 应用可以使用filebeat来对这些服务日志进行收集。
Filebeat用于收集本地文件的日志数据。 它作为服务器上的代理安装,Filebeat监视日志目录或特定的日志文件,尾部文件,并将它们转发到Elasticsearch或Logstash进行索引。
logstash 和filebeat都具有日志收集功能,filebeat更轻量,使用go语言编写,占用资源更少,可以有很高的并发,但logstash 具有filter功能,能过滤分析日志。一般结构都是filebeat采集日志,然后发送到消息队列,如redis,kafka。然后logstash去获取,利用filter功能过滤分析,然后存储到elasticsearch中。
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache定级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。
环境说明
node1: Elasticsearch, zookeeper, Kafka,Nginx,Kibana,filebeat
node2: Elasticsearch, zookeeper,Kafka, logstash
node3: zookeeper,Kafka
配置步骤
这里介绍一下 zookeeper和 kafka配置步骤,node1和node2上关于ES,logstash,Kibana,Nginx的配置可以参考之前的文章。node1上使用nginx代理本地Kibana。
在配置之前,需要在每台机器是做好主机名解析:
echo "192.168.20.60 node1" >> /etc/hosts
echo "192.168.20.61 node2" >> /etc/hosts
echo "192.168.20.62 node3" >> /etc/hostszookeeper依赖java环境,需要安装openjdk:
yum install java-1.8.0-openjdk -y安装配置zookeeper
在官网下载zookeeper的安装包: https://www.apache.org/dyn/closer.cgi/zookeeper/
在三台节点上解压安装,执行如下操作:
wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.5.2-alpha/zookeeper-3.5.2-alpha.tar.gz
tar xvf zookeeper-3.5.2-alpha.tar.gz
mv zookeeper-3.5.2-alpha /usr/local/
ln -sv /usr/local/zookeeper-3.5.2-alpha /usr/local/zookeeper
mkdir /usr/local/zookeeper/data/
vim /usr/local/zookeeper/conf/zoo.cfg修改zookeeper的配置文件为如下内容:
# grep "^[a-Z]" /usr/local/zookeeper/conf/zoo.cfg
tickTime=2000 #服务器之间或客户端与服务器之间的单次心跳检测时间间隔,单位为毫秒
initLimit=10 #集群中leader服务器与follower服务器第一次连接最多次数
syncLimit=5 # leader 与 follower 之间发送和应答时间,如果该follower 在设置的时间内不能与leader 进行通信,那么此 follower 将被视为不可用。
dataDir=/usr/local/zookeeper/data #自定义的zookeeper保存数据的目录
clientPort=2181 #客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
server.1=192.168.20.60:2888:3888 #服务器编号=服务器IP:LF数据同步端口:LF选举端口
server.2=192.168.20.61:2888:3888
server.3=192.168.20.62:2888:3888配置zookeeper集群节点ID
在node1上执行:
[root@node1 ~]# echo "1" > /usr/local/zookeeper/data/myid在node2上执行:
[root@node2 ~]# echo "2" > /usr/local/zookeeper/data/myid在node3上执行:
[root@node3 ~]# echo "3" > /usr/local/zookeeper/data/myid在三个节点上启动zookeeper:
# /usr/local/zookeeper/bin/zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED查看三个节点的启动状态:
[root@node1 data]# /usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
[root@node2 ~]# /usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
[root@node3 ~]# /usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader对zookeeper集群进行操作验证:
在任意节点上执行:
[root@node1 data]# /usr/local/zookeeper/bin/zkCli.sh -server 192.168.20.62:2181
[zk: 192.168.20.62:2181(CONNECTED) 0] create /test "welcome"
Created /test在其他节点上获取:
[root@node3 ~]# /usr/local/zookeeper/bin/zkCli.sh -server 192.168.20.60:2181
[zk: 192.168.20.60:2181(CONNECTED) 0] get /test
welcome安装配置Kafka
kafka官方下载地址: http://kafka.apache.org/downloads.html
在三台节点上安装Kafka集群,进行如下操作:
wget http://mirrors.hust.edu.cn/apache/kafka/1.0.0/kafka_2.11-1.0.0.tgz
tar xvf kafka_2.11-1.0.0.tgz
mv kafka_2.11-1.0.0 /usr/local/
ln -sv /usr/local/kafka_2.11-1.0.0/ /usr/local/kafkanode1上修改配置文件的如下选项,系统默认选项这里没有列出:
[root@node1 local]# grep "^[a-Z]" /usr/local/kafka/config/server.properties
broker.id=1 # 指定节点的ID号,不同节点ID必须不同
listeners=PLAINTEXT://192.168.20.60:9092 # 监听的ip和端口
log.dirs=/tmp/kafka-logs
log.retention.hours=24 # 日志保留的时间单位为小时
zookeeper.connect=192.168.20.60:2181,192.168.20.61:2181,192.168.20.62:2181 # zookeeper集群IP端口node2上修改kafka配置文件的如下选项:
# /usr/local/kafka/config/server.properties
broker.id=2
listeners=PLAINTEXT://192.168.20.61:9092
log.dirs=/tmp/kafka-logs
log.retention.hours=24
zookeeper.connect=192.168.20.60:2181,192.168.20.61:2181,192.168.20.62:2181node3上修改如下参数:
# /usr/local/kafka/config/server.properties
broker.id=3
listeners=PLAINTEXT://192.168.20.62:9092
num.network.threads=3
log.dirs=/tmp/kafka-logs
log.retention.hours=24
zookeeper.connect=192.168.20.60:2181,192.168.20.61:2181,192.168.20.62:2181使用 -daemon 的方式启动kafka:
[root@node1 ~]# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
[root@node2 ~]# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
[root@node3 ~]# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties查看kafka启动状态:
# tail -f /usr/local/kafka/logs/server.log # 日志最后一条,显示已经启动
...
[2017-12-19 16:10:05,542] INFO [KafkaServer id=3] started (kafka.server.KafkaServer)查看后台进程:
[root@node1 ~]# jps
6594 QuorumPeerMain
7570 Kafka
7653 Jps
1884 Elasticsearch
[root@node3 ~]# jps
5184 QuorumPeerMain
6003 Jps
5885 Kafka提示: jps 是查看java进程的小工具,如果没有jps命令,说明只安装了java-1.8.0-openjdk,还需要安装java-1.8.0-openjdk-devel
Kafka 操作命令
测试Kafka添加topic:
[root@node3 logs]# /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.20.60:2181,192.168.20.61:2181,192.168.20.62:2181 --partitions 3 --replication-factor 3 --topic kafkatest
Created topic "kafkatest".查看添加的topic(集群中任意服务器上都可以看到):
[root@node1 ~]# /usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.20.60:2181,192.168.20.61:2181,192.168.20.62:2181
kafkatest测试获取topic:
[root@node2 ~]# /usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper 192.168.20.60:2181,192.168.20.61:2181,192.168.20.62:2181 --topic kafkatest
Topic:kafkatest PartitionCount:3 ReplicationFactor:3 Configs:
Topic: kafkatest Partition: 0 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
Topic: kafkatest Partition: 1 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1
Topic: kafkatest Partition: 2 Leader: 1 Replicas: 1,3,2 Isr: 1,3,2
状态说明:logstashtest有三个分区分别为0、1、2,分区0的leader是2(broker.id),分区0有三个副本,并且状态都为lsr(ln-sync,表示可以参加选举成为leader).
删除topic:
[root@node2 ~]# /usr/local/kafka/bin/kafka-topics.sh --delete --zookeeper 192.168.20.60:2181,192.168.20.61:2181,192.168.20.62:2181 --topic kafkatest
Topic kafkatest is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.测试使用命令发送消息:
创建一个topic:
/usr/local/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.20.60:2181,192.168.20.61:2181,192.168.20.62:2181 --partitions 3 --replication-factor 3 --topic kafkatest
Created topic "kafkatest".发送消息:
[root@node3 ~]# /usr/local/kafka/bin/kafka-console-producer.sh --broker-list 192.168.20.60:9092,192.168.20.61:9092,192.168.20.62:9092 --topic kafkatest
>hello
>good
>welcome其他节点获取数据(在任意节点上都能获取):
[root@node1 ~]# /usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper 192.168.20.60:2181,192.168.20.61:2181,192.168.20.62:2181 --topic kafkatest --from-beginning
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
good
welcome
hello使用Logstash和Kafka交互
编辑logstash配置文件:
[root@node1 ~]# cat /etc/logstash/conf.d/kafka.conf
input{
stdin{}
}
output{
kafka{
topic_id =>"kafkatest"
bootstrap_servers => "192.168.20.60:9092"
batch_size => 5
}
stdout{
codec => "rubydebug"
}
}前台启动logstash,输入数据:
[root@node1 ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/kafka.conf
The stdin plugin is now waiting for input:
123456
{
"@timestamp" => 2017-12-19T15:19:34.885Z,
"message" => "123456",
"host" => "node1",
"@version" => "1"
}
trying
{
"@timestamp" => 2017-12-19T15:20:15.234Z,
"message" => "trying",
"host" => "node1",
"@version" => "1"
}在kafka中查看写入的数据:
[root@node3 ~]# /usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper 192.168.20.60:2181,192.168.20.61:2181,192.168.20.62:2181 --topic kafkatest --from-beginning
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
2017-12-19T15:19:34.885Z node1 123456
2017-12-19T15:20:15.234Z node1 trying数据写入成功,kafka配置完成。
安装filebeat
从官网下载filebeat的安装包进行安装: https://www.elastic.co/downloads
[root@node1 tmp]# yum install filebeat-6.1.1-x86_64.rpm -y
在filebeat :6.1的版本中,默认的filebeat.reference.yml有各种模块的配置示例,配置filebeat写入本地文件:
[root@node1 filebeat]# cat /etc/filebeat/filebeat.yml
filebeat.modules:
- module: nginx
access:
enabled: true
var.paths:
- /var/log/nginx/access.log
filebeat.prospectors:
- type: log
enabled: false
paths:
- /var/log/*.log
output.file:
enabled: true
path: "/tmp/filebeat"
rotate_every_kb: 10000
number_of_files: 7
logging.to_files: true
提示:(引用官方原文) 在filebeat 6.0以前的版本中,可以同时启用多个输出,但只能使用不同的类型。例如,您可以启用Elasticsearch和Logstash输出,但不能启用两个Logstash输出。启用多个输出的缺点是在继续之前等待确认(Filebeat和Winlogbeat)的Beats减慢到最慢的输出。这种含义并不明显,阻碍了多个产出有用的用例。
作为我们为6.0所做的管道重新架构的一部分,我们删除了同时启用多个输出的选项。这有助于简化管道并明确Beats中的输出范围。
如果您需要多个输出,您有以下选择:
使用Logstash输出,然后使用Logstash将事件传送到多个输出.
运行相同Beat的多个实例.
如果您使用文件或控制台输出进行调试,除了主输出之外,我们建议使用-d “public”选项,将发布的事件记录在Filebeat日志中。
访问nginx,使用tail -f /tmp/filebeat/filebeat命令追踪日志的变化,发现有输出则配置成功。
输出日志到kakfa:
[root@node1 filebeat]# cat /etc/filebeat/filebeat.yml
filebeat.modules:
- module: nginx
access:
enabled: true
var.paths:
- /var/log/nginx/access.log
filebeat.prospectors:
- type: log
enabled: false
paths:
- /var/log/*.log
output.kafka:
enabled: true
hosts: ["192.168.20.60:9092","192.168.20.61:9092","192.168.20.62:9092"]
topic: "nginx-filebeat"
partition.hash:
reachable_only: true
compression: gzip
max_message_bytes: 1000000
required_acks: 1
logging.to_files: true
访问nginx查看kafka中是否写入:
[root@node3 ~]# /usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.20.60:2181,192.168.20.61:2181,192.168.20.62:2181
kafkatest
nginx-filebeat[root@node3 ~]# /usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper 192.168.20.60:2181,192.168.20.61:2181,192.168.20.62:2181 --topic nginx-filebeat
...当日志成功写入Kafka后配置logstash.
使用logstash从Kafka读取日志到ES
如果使用filebeat 6.0以上的版本,可以将filebeat收集到的各种类型日志统一输入到Kafka,然后通过配置logstash将日志分类输出到不同的容器中。
配置logstash读取kafka日志:
[root@node2 log]# cat /etc/logstash/conf.d/kafka2es.conf
input{
kafka{
bootstrap_servers => "192.168.20.62:9092"
topics => "nginx-filebeat"
consumer_threads => 1
decorate_events => true
codec => "json"
auto_offset_reset => "latest"
}
}
output{
elasticsearch {
hosts => ["192.168.20.61:9200"]
index => "nginx-filebeat-%{+YYYY.MM.dd}"
}
stdout{
codec => "rubydebug"
}
}测试文件:
[root@node2 ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/kafka2es.conf -t在前台运行,确保日志能正确输出:
[root@node2 ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/kafka2es.conf
...
重启logstash,查看Elasticsearch中是否收到数据:
[root@node2 ~]# systemctl restart logstashElasticsearch已经有了对应的数据: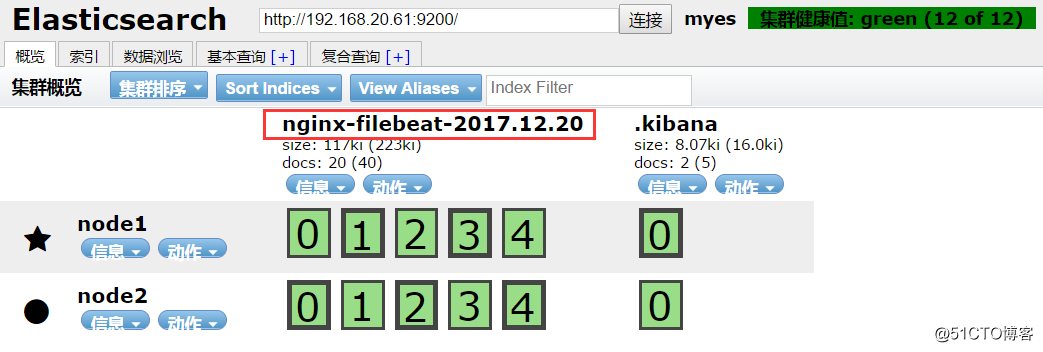
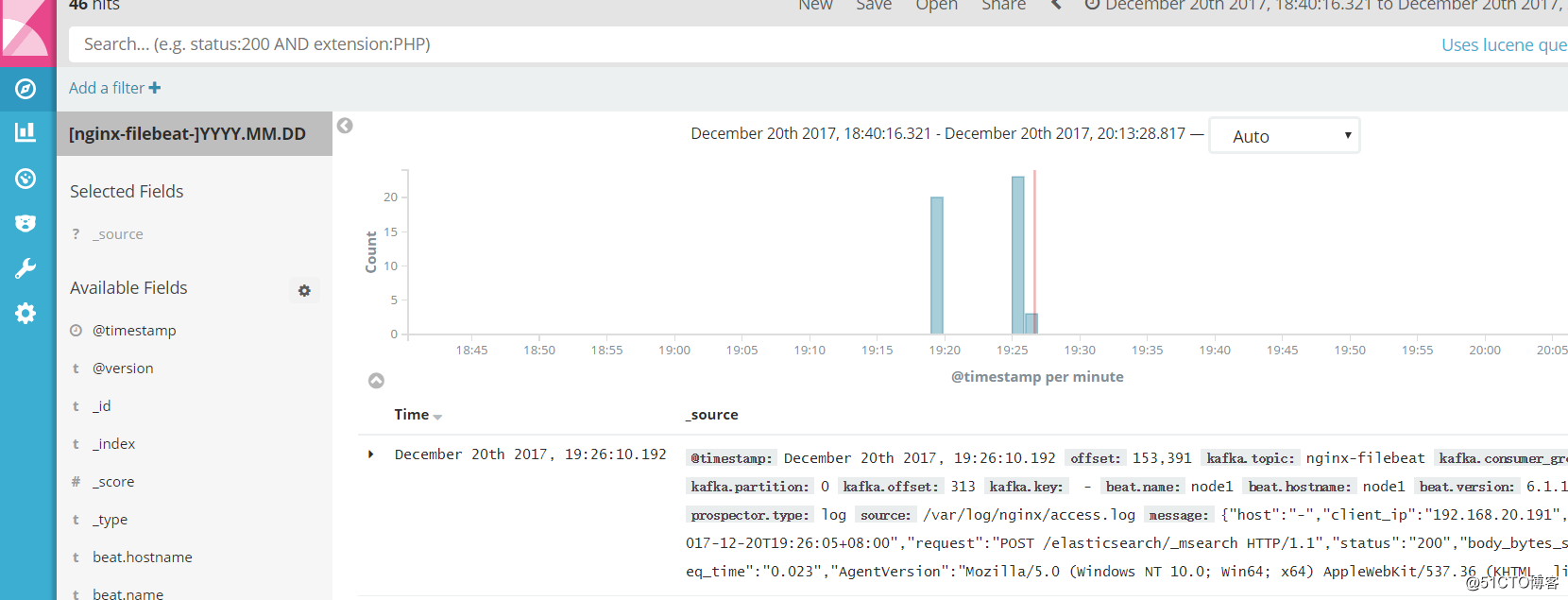
添加索引到Kibana,展示数据:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号