
硬件篇之MMU
<虚拟地址/物理地址>
a:如果处理器没有MMU,CPU内部执行单元产生的内存地址信号将直接通过地址总线发送到芯片引脚,被内存芯片接收,这就是物理地址(physical address),简称PA。英文physical代表物理的接触,所以PA就是与内存芯片physically connected的总线上的信号。
b:如果MMU存在且启用,CPU执行单元产生的地址信号在发送到内存芯片之前将被MMU截获,这个地址信号称为虚拟地址(virtual address),简称VA,MMU会负责把VA翻译成另一个地址,然后发到内存芯片地址引脚上,即VA映射成PA,如下图:
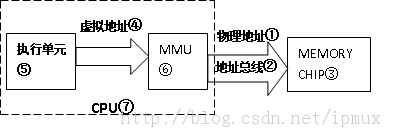
b-1:所以物理地址①是通过CPU对外地址总线②传给Memory Chip③使用的地址。
b-2:而虚拟地址④是CPU内部执行单元⑤产生的,发送给MMU⑥的地址。硬件上MMU⑥一般封装于CPU芯片⑦内部,所以虚拟地址④一般只存在于CPU⑦内部,到了CPU外部地址总线引脚上②的信号就是MMU转换过的物理地址①。
注意:软件上MMU对用户程序不可见,在启用MMU的平台上(没有MMU不必说,只有物理地址,不存在虚拟地址),用户C程序中变量和函数背后的数据/指令地址等都是虚拟地址,这些虚拟内存地址从CPU执行单元⑤发出后,都会首先被MMU拦截并转换成物理地址,然后再发送给内存。也就是说用户程序运行*pA =100;"这条赋值语句时,假设debugger显示指针pA的值为0x30004000(虚拟地址),但此时通过硬件工具(如逻辑分析仪)侦测到的CPU与外存芯片间总线信号很可能是另外一个值,如0x8000(物理地址)。当然对一般程序员来说,只要上述语句运行后debugger显示0x30004000位置处的内存值为100就行了,根本无需关心pA的物理地址是多少。但进行OS移植或驱动开发的系统程序员不同,他们必须清楚软件如何在幕后辅助硬件MMU完成地址转换。
"所有计算机科学中的问题都能通过增加一个中间转换层来解决"("All problems in computer science can be solved by another level of indirection")。某种程度上,这种被动解决问题的方式使计算机软硬件的一系列发展只不过是惯性向前,看起来顺理成章,然而几乎所有从业者的智慧都浪费在不断学习和构建新的中间层,身不由己的推动这个庞然大物继续膨胀。
<页/页帧/页表/页表项(PTE)>
MMU是负责把虚拟地址映射为物理地址,但凡"映射"都要解决两个问题:映射的最小单位(粒度)和映射的规则。
a:页
MMU中VA到PA映射的最小单位称为页(Page),映射的最低粒度是单个虚拟页到物理页,页大小通常是4K,即一次最少要把4K大小的VA页块整体映射到4K的PA页块(从0开始4K对齐划分页块),页内偏移不变,如VA的一页0x30004000~0x30004fff被映射到PA的一页 0x00008000~0x00008fff,当CPU执行单元访问虚拟地址0x30004008,实际访问的物理地址是0x00008008(0x30004008和0x00008008分别位于虚实两套地址空间,互不相干,不存在重叠和冲突)。以页为最小单位,就是不能把VA中某一页划分成几小块分别映射到不同PA,也不能把VA中属于不同页的碎块映射到PA某一页的不同部分,必须页对页整体映射。
b:页帧(Page Frame)
是指物理内存中的一页内存,MMU虚实地址映射就是寻找物理页帧的过程,对这个概念了解就可以了。
c:页表
MMU软件配置的核心是页表(Page Table),它描述MMU的映射规则,即虚拟内存哪(几)个页映射到物理内存哪(几)个页帧。页表由一条条代表映射规则的记录组成,每一条称为一个页表条目(Page Table Entry,即PTE),整个页表保存在片外内存,MMU通过查找页表确定一个VA应该映射到什么PA,以及是否有权限映射。但如果MMU每次地址转换都到位于外部内存的页表上查找PTE,转换速度就会大大降低,于是出现了TLB
c-1:TLB
TLB (Translation Lookaside Buffers)即转换快表,又简称快表,可以理解为MMU内部专用的存放页表的cache,保存着最近使用的PTE乃至全部页表。MMU接收到虚拟地址后,首先在TLB中查找,如果找到该VA对应的PTE就直接转换,找不到再去外存页表查找,并置换进TLB。TLB属于片上SRAM,访问速度快,通过TLB缓存PTE可以节省MMU访问外存页表的时间,从而加速虚实地址转换。TLB和CPU cache的工作原理一样,只是TLB专用于为MMU缓存页表。
<MMU的内存保护功能>
既然所有发往内存的地址信号都要经过MMU处理,那让它只单单做地址转换,岂不是浪费了这个特意安插的转换层?显然它有能力对虚地址访问做更多的限定(就像路由器转发网络包的同时还能过滤各种非法访问),比如内存保护。可以在PTE条目中预留出几个比特,用于设置访问权限的属性,如禁止访问、可读、可写和可执行等。设好后,CPU访问一个VA时,MMU找到页表中对应PTE,把指令的权限需求与该PTE中的限定条件做比对,若符合要求就把VA转换成PA,否则不允许访问,并产生异常。
<多级页表>
页号就更有故事了,一个32bits虚拟地址,可以划分为220个内存页,如果都以页为单位和物理页帧随意映射,页表的空间占用就是220*sizeof(PTE)*进程数(每个进程都要有自己的页表),PTE一般占4字节,即每进程4M,这对空间占用和MMU查询速度都很不利。
问题是实际应用中不需要每次都按最小粒度的页来映射,很多时候可以映射更大的内存块。因此最好采用变化的映射粒度,既灵活又可以减小页表空间。具体说可以把20bits的页号再划分为几部分(如下图linux的3级划分),
|
PGD(16bits) |
PMD(4bits) |
PTE(4bits) |
Offset(12bits) |
简单说每次MMU根据虚拟地址查询页表都是一级级进行,先根据PGD的值查询,如果查到PGD的匹配,但后续PMD和PTE没有,就以2(offset+pte+pmd)=1M为粒度进行映射,后20bits全部是块内偏移,与物理地址相同。
<操作系统和MMU>
实际上MMU是为满足操作系统越来越复杂的内存管理而产生的。OS和MMU的关系简单说:
a.系统初始化代码会在内存中生成页表,然后把页表地址设置给MMU对应寄存器,使MMU知道页表在物理内存中的什么位置,以便在需要时进行查找。之后通过专用指令启动MMU,以此为分界,之后程序中所有内存地址都变成虚地址,MMU硬件开始自动完成查表和虚实地址转换。
b.OS初始化后期,创建第一个用户进程,这个过程中也需要创建页表,把其地址赋给进程结构体中某指针成员变量。即每个进程都要有独立的页表。
c.用户创建新进程时,子进程拷贝一份父进程的页表,之后随着程序运行,页表内容逐渐更新变化。比较复杂了,几句讲不清楚,不多说了哈,有时间讲linux的话再说吧
6)总结
相关概念讲完,VA到PA的映射过程就一目了然:MMU得到VA后先在TLB内查找,若没找到匹配的PTE条目就到外部页表查询,并置换进TLB;根据PTE条目中对访问权限的限定检查该条VA指令是否符合,若不符合则不继续,并抛出exception异常;符合后根据VA的地址分段查询页表,保持offset(广义)不变,组合出物理地址,发送出去。
在这个过程中,软件的工作核心就是生成和配置页表。
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">
