k8s集群ETCD数据不一致处理
一:前言#
公司k8s集群规模为3master+7node,3master前面使用haproxy做负载均衡,使用自定义域名解析,公司内部路由器上做DNS解析。
前段时间无意中发现同时间多次get pod资源时,返回的结果不一致,通过查询发现ETCD节点数据不一致,现进行修复
| 主机名 | IP |
|---|---|
| master1 | 192.168.0.211 |
| master2 | 192.168.0.212 |
| master3 | 192.168.0.213 |
二:修复#
1:查询集群状态#
ETCD状态查询得知3台master的ETCD数据均不一致,这里保险起见,以数据最多的节点(master1)作为数据恢复节点。

2:确定需要恢复数据的节点,切换leader#
上图可见现在的leader为master3,我们需要将leader切换到master1

3:数据备份#
备份leader节点数据

保险起见,将数据物理目录也备份

将另外两个异常节点的ETCD数据按照以上方式备份。
4:停止etcd服务,删除旧数据#
停止master2节点上的etcd服务,由于我们的集群是通过kubeadm部署的,所以ectd是以static pod方式运行,只需要将/etc/kubernetes/manifests/etcd.yaml文件删除或者移至其他目录即可。

etcd集群删除master2节点



删除master2节点上etcd数据

5:恢复etcd服务,自动同步leader节点数据#
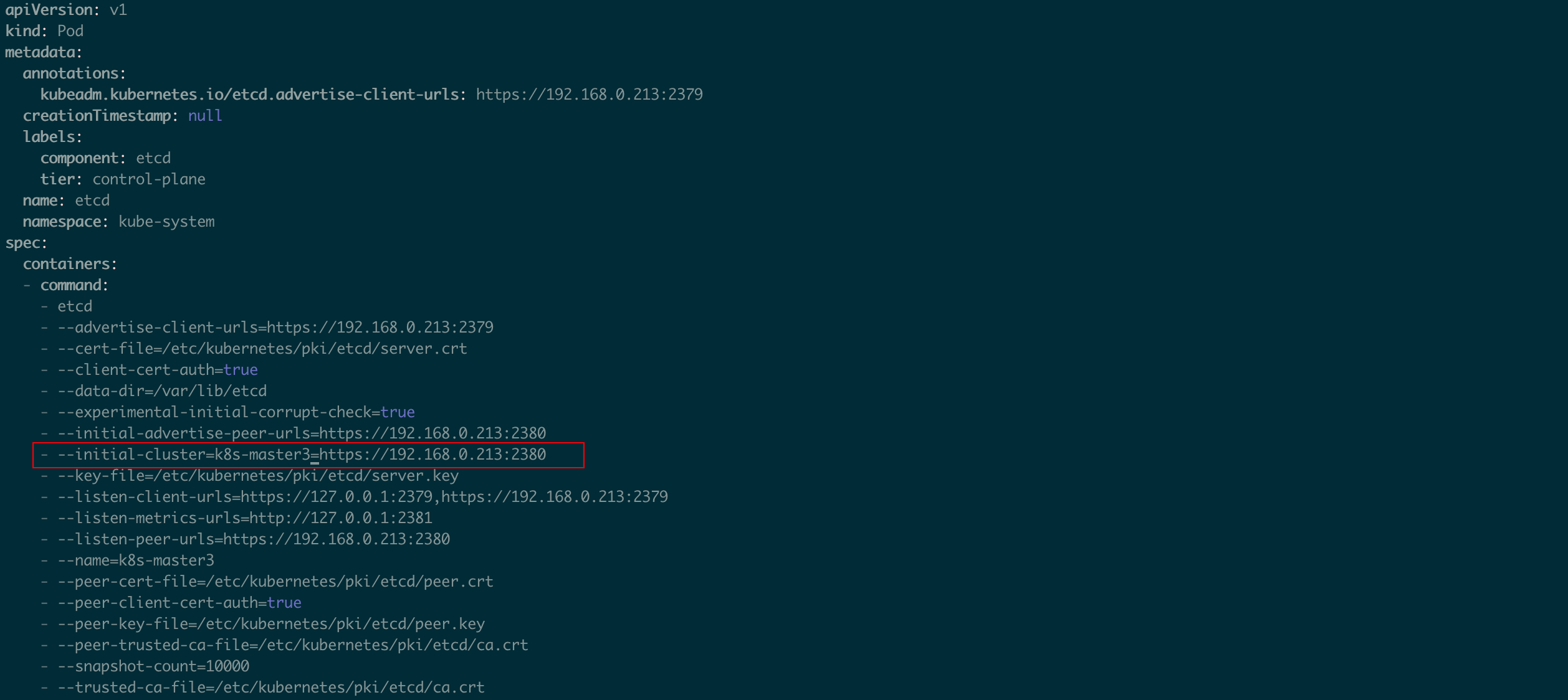
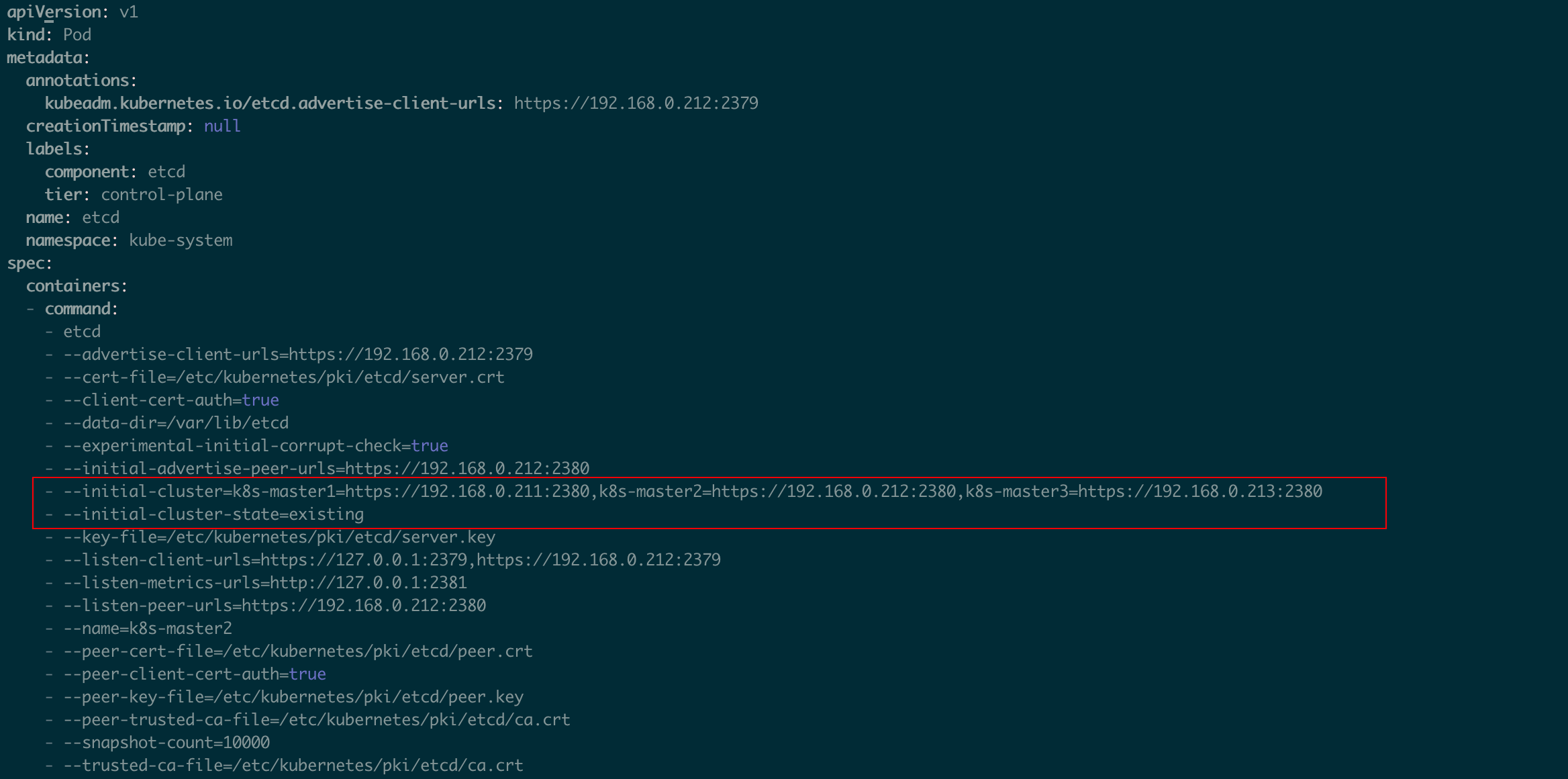
修改etcd.yaml文件, 修改参数,并添加参数: - --initial-cluster-state=existing
原参数:
修改后的参数:
把master2节点再次加入etcd集群,需要先添加至etcd集群再启动ectd服务,不然会报错。

再次查看leafer是否为master1,如果自动选举至其他节点,需再次手动切换为master1

master2启动ectd服务,将修改后的etcd.yaml移动至/etc/kubernetes/manifests/即可。
等待一段时间后,查看集群状态,发现master2数据已经和leader master1一致。

按照上述步骤将master3节点ECTD数据同步。
分类:
kubernetes
标签:
kuberbetes
, etcd




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!