KafKa综述
一、消息系统分类
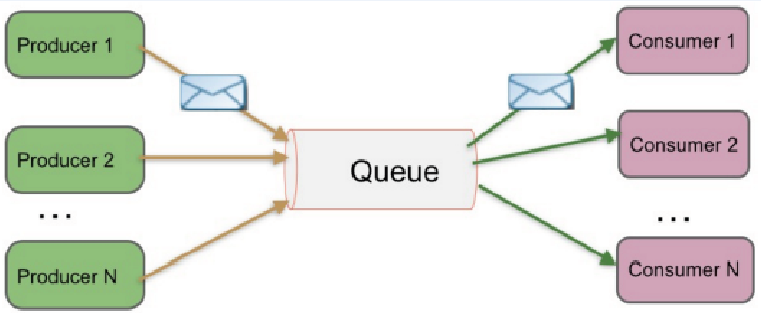
(1)P2P(Peer-to-Peer)
- 特点
- 一般基于Pull或者Polling接收消息
- 即便有多个接收者在同一个队列中监听同一消息,但是该消息只能仅且被一个接收者所接收
- 不仅支持异步“即发即弃”的消息传送方式,而且也支持同步请求/应答传送方式
- 示意
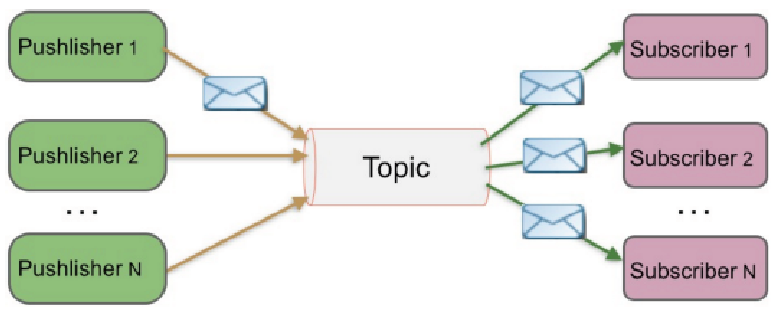
(2)Publish/Subscribe(发布/订阅)
- 特点
- 发布到一个主题的消息,可被多个订阅者所接收
- 发布/订阅即可以基于Push消费数据,也可以基于Pull或者Polling消费数据
- 解耦能力比P2P模型更强
- 示意图
二、消息系统应用场景
- 解耦能力:各个系统之间通过消息系统这个统一的接口交换数据,无须了解彼此的存在;
- 扩展能力:消息系统是统一的数据接口,各个系统可独立扩展;
- 峰值处理能力:消息系统可顶住峰值流量,业务系统可根据处理能力从消费系统中获取并处理对应量的请求;
- 冗余性:部分消息系统具有消息持久化能力,可规避消息处理前丢失的风险;
- 异步通信:在不需要立即处理请求的场景下,可以将请求放入消息系统,合适的时候再处理;
- 可恢复性:系统中部分组件失效并不会影响整个系统,它恢复后仍然可从消息系统中获取并处理数据;
三、消息系统对比
- RabbitMQ:Erlang编写,支持多协议AMQP、XMPP、SMTP、STOMP,支持负载均衡、数据持久化,同时支持P2P和发布/订阅模式
- Redis:基于Key-Value对的NoSQL数据库,同时支持MQ功能,可做轻量级队列服务使用。就入队操作而言,Redis对短消息(小于10KB)的性能比RabbitMQ好,长消息的性能比RabbitMQ差。
- ZeroMQ:轻量级,不需要单独的消息服务器或中间件,应用程序本身扮演该角色,P2P。它实质上是一个库,需要开发人员自己组合多种技术,使用复杂度高。
- ActiveMQ:JMS实现,P2P,支持持久化、XA事务。
- Kafka/Jafka:高性能跨语言的分布发布/订阅消息系统,数据持久化,全分布式,同时支持在线和离线处理。
- MetaQ/RocketMQ:纯Java实现,发布/订阅消息系统,支持本地事务和XA分布式事务。
四、Kafka系统
(1)设计目标
- 高吞吐率:在廉价的商用机器上单机可以支持每秒100万条消息的读写。
- 消息持久化:所有消息均被持久化到磁盘,无消息丢失,支持消息重放。
- 完全分布式:Producer、Broker、Consumer均支持水平扩展。
- 同时适应在线流处理和离线批处理。
(2)逻辑架构
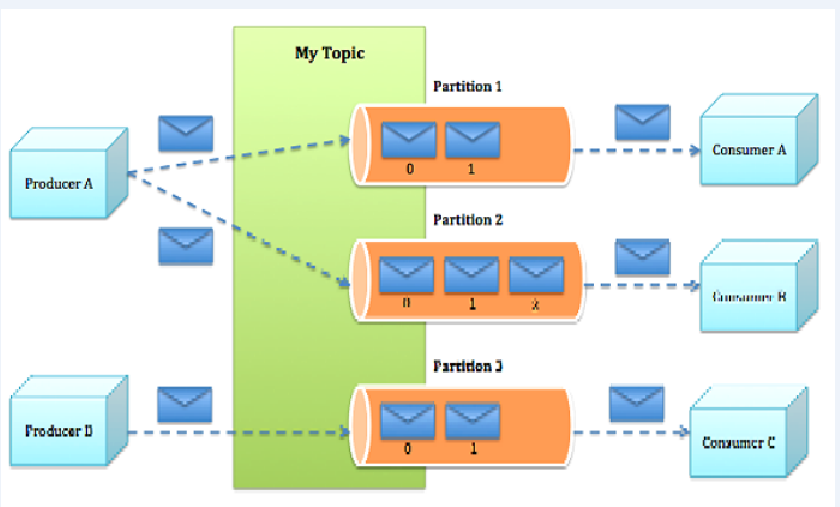
(3)相关概念
- Topic:特指Kafka处理的消息源(feeds of messages)的不同分类。
- 逻辑概念,同一个Topic的消息可以分布在一个或多个节点(Broker)上。
- 一个Topic包含一个或者多个Partition。
- 每条消息有且仅属于一个Topic。
- Producer发布数据时,必须指定将该消息发布到哪一个Topic。
- Consumer订阅消息时,必须指定订阅哪个Topic的消息。
- 示意图:
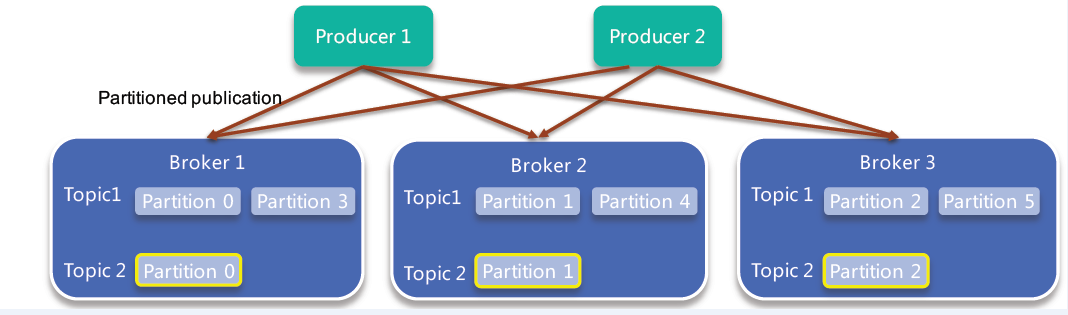
- Partition:Topic物理上的分组,一个Topic可以分为多个Partition,每个Partition是一个有序的队列。Partition中的每条消息都会被分配一个有序的id(offset)。
- Message:消息,是通信的基本单位,每个Producer可以向一个Topic发布一些消息。
- Producers:消息和数据生产者,向Kafka的一个Topic发布消息的过程叫做Producers。
- Consumers:消息和数据消费者,订阅Topics并处理其发布的消息过程叫做Consumers。
- Consumer Group:消息被消费后,并不会被删除,只是相应的offset加一;对于每条消息,在同一个Consumer Group里只会被一个Consumer消费;不同Consumer Group可消费同一条消息。
- 示意图:
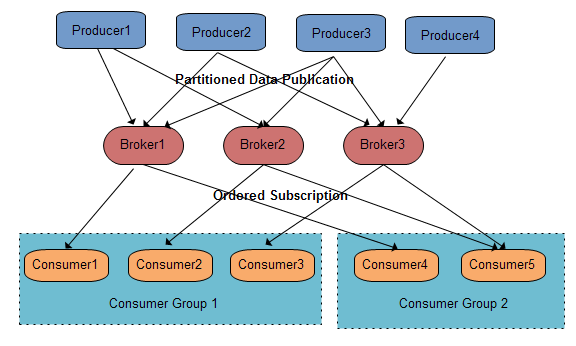
- Broker:缓存代理,Kafka集群中的一台或多台服务器统称为Broker。
(4)Offset
- 每条Kafka消息都有一个offset(位移标记),每条消息都默认在Kafka中保留7天。
- Kafka中保存了每个Consumer消费消息的offset。
- Consumer消费消息后需要提交offset到kafka(自动commit/手动commit)。
- Consumer接收消息时,只会从Kafka中这条消息最新的offset开始接收。
(5)消息模式
Kafka消息模式有两种:Pull模式和Push模式;各自的优劣如下所示:
- Push模式:
- 优势:延时低
- 劣势:可能造成Consumer来不及处理消息,网络拥塞
- Pull模式:
- 优势:Consumer按实际处理能力获取相应量的数据,Broker实现简单
- 劣势:如果处理不好,实时性相对不足(Kafka使用long polling)
Producer/Consumer各自采用的消息模式如下所示:
- Producer:通过主动Push的方式将消息发布到Broker。
- Consumer:通过Pull从Broker消费数据。
(6)实现方式
- 一个Topic可以有多个Partition。
- Producer发送消息给Topic的Partition。
- Consumer也是针对Topic的Partition。
- 一对一方式:一个Partition的消息只会分发给一个ConsumerGroup的其中一个consumer消费。
- 一对多方式: 一个Partition的消息可以分发给多个ConsumerGroup的其中一个consumer消费。
(7)消息传输事务
消息传输事务的定义:
- 最多一次: 消息不会被重复发送,最多被传输一次,但也有可能一次不传输。
- 最少一次: 消息不会被漏发送,最少被传输一次,但也有可能被重复传输。
- 精确的一次: 不会漏传输也不会重复传输,每个消息都传输被一次而且仅仅被传输一次。
KafKa没有事务,但内部机制采用的是”最少一次”传输定义
(8)消息有序性
设置Topic只有一个Partition,当然也就只有一个Consumer能顺序消费它了。
(9)消息可靠性
消息可靠性需要靠以下2点保证 :
1、Producer和Broker参数严谨性来保证。 Broker: unclean.leader.election.enable=false replication-factor=6 min.insync.replicas=2 Producer: acks=all retries=5 2、Producer容错重发机制,在应用端代码业务控制,故消息可能会发重复,要求Consumer保证幂等性。
阅读是一种修养,分享是一种美德。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号