
Spark入门,概述,部署,以及学习(Spark是一种快速、通用、可扩展的大数据分析引擎)
1:Spark的官方网址:http://spark.apache.org/
1:Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
2:Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
3:Spark是一种通用的大数据计算框架,一种通用的大数据快速处理引擎,正如传统大数据技术,hadoop的mapreduce,hive引擎,以及Storm流式实时计算引擎等等。
4:Spark包含了大数据领域常见的各种计算框架,比如Spark core用于离线计算,Spark SQL用于交互式查询,Spark Streaming用于实时流式计算,Spark MLlib用于机器学习,Spark GraphX用于图计算。
5:Spark主要用户大数据的计算,而Hadoop以后主要用于大数据的存储(比如,hdfs,hive,hbase),以及资源调度(yarn)。
6:Spark的核心,其实就是一种新型的大数据框架,而不是对Hadoop的替代,可以基于Hadoop上存储的大数据进行计算(比如:Hdfs,Hive)。Spark只是替代Hadoop的一部分,也就是Hadoop的计算框架Mapreduce,Hive查询引擎。但是Spark本身是不提供大数据的存储的。
7:对比:Spark Core(Spark SQL,Spark Streaming,Spark ML,Spark Graphx,Spark R);和Hadoop(Hive,Storm,Mahout,Griph);
2:Spark特点:
1 1:特点一:快 2 与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。 3 2:特点二:易用 4 Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。 5 3:特点三:通用 6 Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。 7 4:特点四:兼容性 8 Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
Spark的算子分为两类,一类叫做Transformation转换,一类叫做Action动作。Transformation延迟执行,当计算任务触发Action时候才会真正开始计算。
3:Spark的部署安装(上传jar,过程省略,记得安装好jdk。):
下载网址:http://www.apache.org/dyn/closer.lua/spark/ 或者 http://spark.apache.org/downloads.html
Spark的解压缩操作,如下所示:
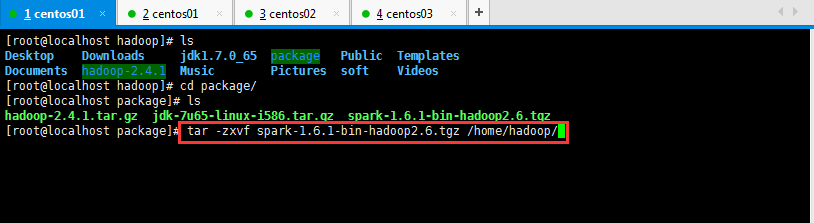
哈哈哈,犯了一个低级错误,千万记得加-C,解压安装包到指定位置。是大写的哦;
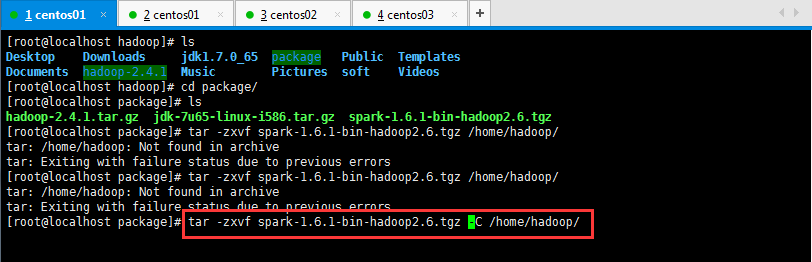
然后呢,进入到Spark安装目录,进入conf目录并重命名并修改spark-env.sh.template文件,操作如下所示:
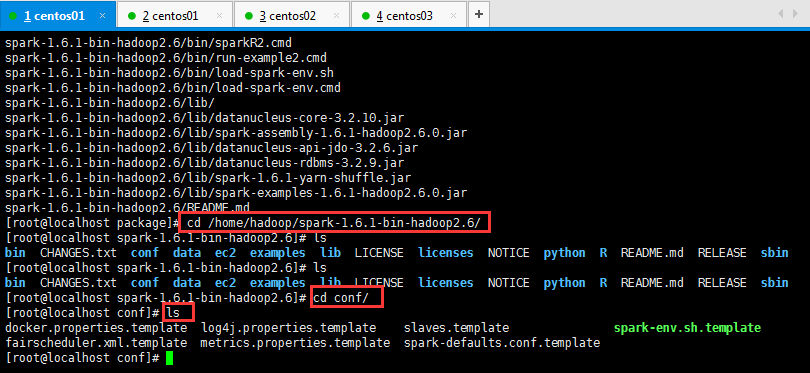
将spark-env.sh.template 名称修改为spark-env.sh,然后在该配置文件中添加如下配置,之后保存退出:
1 [root@localhost conf]# mv spark-env.sh.template spark-env.sh
具体操作如下所示:
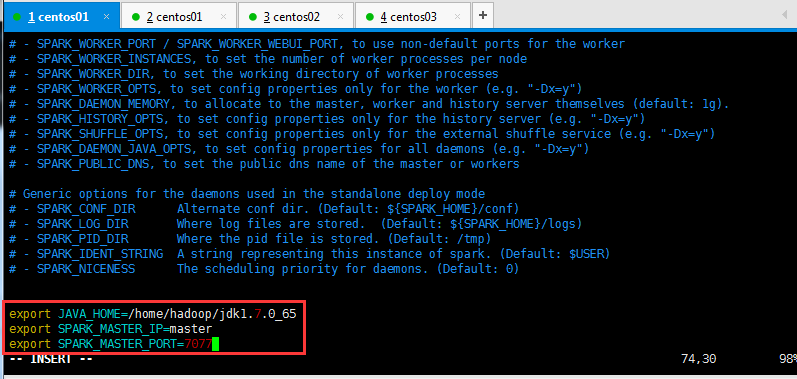
也可以将scala和hadoop的目录以及自定义内存大小进行定义,如下所示:
注意:可以去spark的sbin目录里面的start-master.sh使用more start-master.sh命令来查找spark-env.sh里面对应的端口号,或者找其他的.sh文件找对应的值;

或者添加更多的配置,这样初始化不会使用默认的配置,更多配置自己可以看注释进行添加:

export JAVA_HOME=/home/hadoop/soft/jdk1.7.0_65 export SCALA_HOME=/home/hadoop/soft/scala-2.10.6 export HADOOP_HOME=/home/hadoop/soft/hadoop-2.6.4
export HADOOP_CONF_DIR=/home/hadoop/soft/hadoop-2.6.4/etc/hadoop export SPARK_MASTER_IP=slaver1 export SPARK_MASTER_PORT=7077 export SPARK_MASTER_WEBUI_PORT=8080 export SPARK_WORKER_PORT=7078 export SPARK_WORKER_WEBUI_PORT=8081 export SPARK_WORKER_CORES=1 export SPARK_WORKER_MEMORY=800M export SPARK_WORKER_INSTANCES=1
具体操作如下所示:
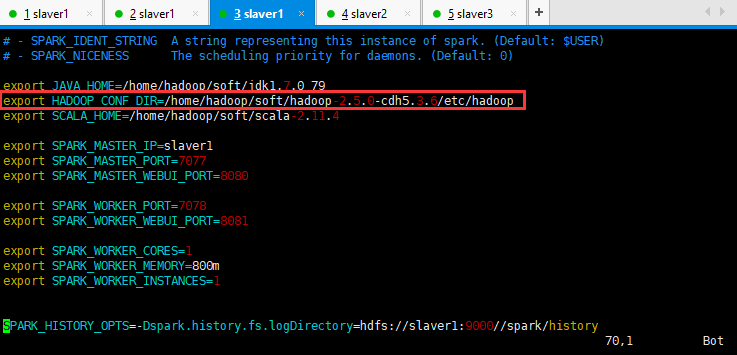
下面这个图片的hadoop_conf_dir目录出现错误,注意修改:

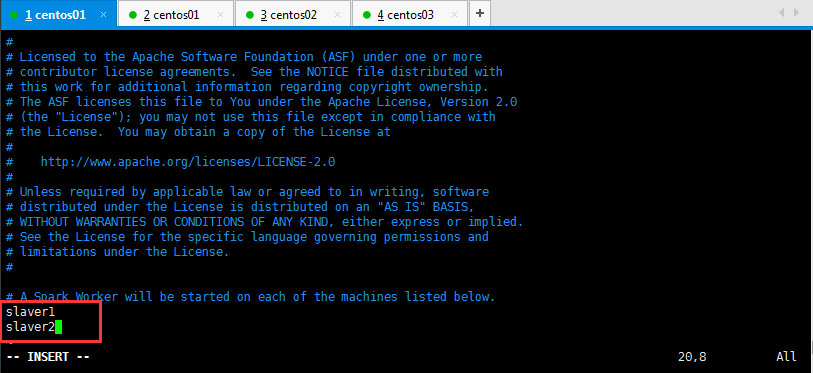
然后呢,重命名并修改slaves.template文件,如下所示:
1 [root@localhost conf]# mv slaves.template slaves
在该文件中添加子节点所在的位置(Worker节点),操作如下所示,然后保存退出:
如果想记录日志,可以将log4j.properties.template修改为log4j.properties,用于记录日志,查看自己的错误信息:
[root@master conf]# cp log4j.properties.template log4j.properties
将配置好的Spark拷贝到其他节点上:
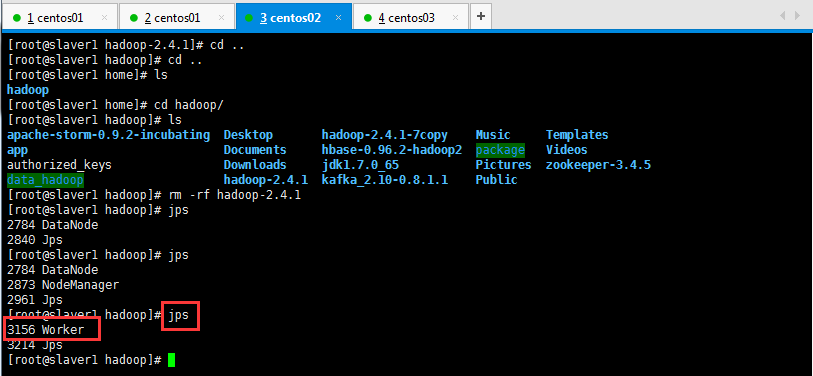
1 [root@localhost hadoop]# scp -r spark-1.6.1-bin-hadoop2.6/ slaver1:/home/hadoop/ 2 [root@localhost hadoop]# scp -r spark-1.6.1-bin-hadoop2.6/ slaver2:/home/hadoop/
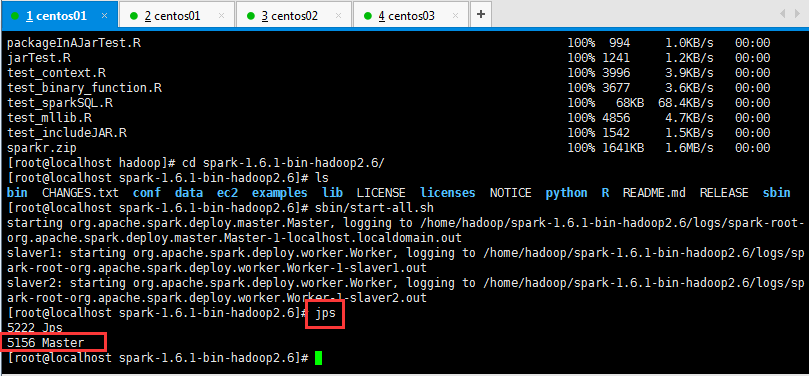
Spark集群配置完毕,目前是1个Master,2个Work(可以是多个Work),在master节点上启动Spark集群:

注意:启动的过程中,如果进入到spark的sbin目录直接输入start-all.sh是不行的,为什么呢,因为之前配置hadoop是配置的全局的,所以呢,这里不能直接输入start-all.sh命令来启动spark;可以输入sbin/start-all.sh启动spark;
启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://master:8080/:
可以查看一下是否启动起来,如下所示:

然后在页面可以查看信息,如下所示,如果浏览器一直加载不出来,可能是防火墙没关闭(service iptables stop暂时关闭,chkconfig iptables off永久关闭):
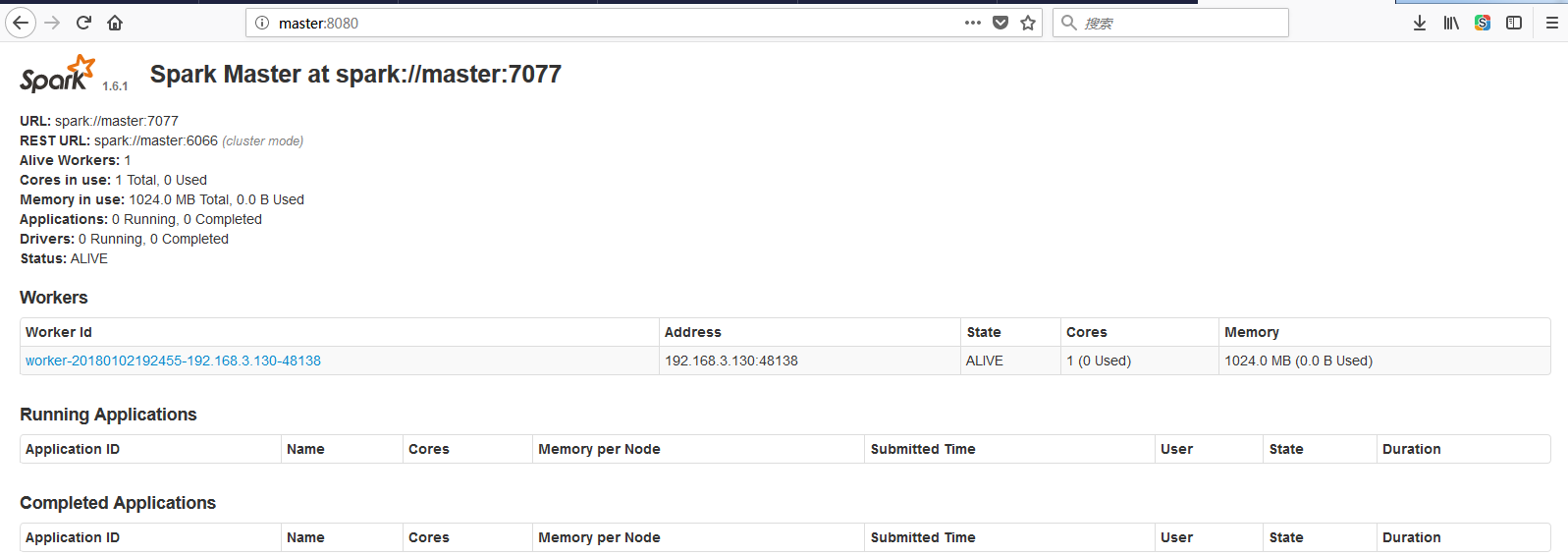
到此为止,Spark集群安装完毕。
1 但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借助zookeeper,并且启动至少两个Master节点来实现高可靠,配置方式比较简单,如下所示: 2 Spark集群规划:node1,node2是Master;node3,node4,node5是Worker 3 安装配置zk集群,并启动zk集群,然后呢,停止spark所有服务,修改配置文件spark-env.sh, 4 在该配置文件中删掉SPARK_MASTER_IP并添加如下配置: 5 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zk1,zk2,zk3 -Dspark.deploy.zookeeper.dir=/spark" 6 1.在node1节点上修改slaves配置文件内容指定worker节点 7 2.在node1上执行sbin/start-all.sh脚本,然后在node2上执行sbin/start-master.sh启动第二个Master
4:执行Spark程序(执行第一个spark程序,如下所示):
执行如下所示,然后就报了一大推错误,由于错误过多就隐藏了,方便以后脑补:
1 [root@master bin]# ./spark-submit \ 2 > --class org.apache.spark.examples.SparkPi \ 3 > --master spark://master:7077 \ 4 > --executor-memory 1G \ 5 > --total-executor-cores 2 \ 6 > /home/hadoop/spark-1.6.1-bin-hadoop2.6/l 7 lib/ licenses/ logs/ 8 > /home/hadoop/spark-1.6.1-bin-hadoop2.6/lib/spark-examples-1.6.1-hadoop2.6.0.jar \ 9 > 100
或者如下所示也可:
[root@master spark-1.6.1-bin-hadoop2.6]# bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512M --total-executor-cores 2 /home/hadoop/spark-1.6.1-bin-hadoop2.6/lib/spark-examples-1.6.1-hadoop2.6.0.jar 10
错误如下所示,由于太长了就折叠起来了:


1 [root@master hadoop]# cd spark-1.6.1-bin-hadoop2.6/ 2 [root@master spark-1.6.1-bin-hadoop2.6]# ls 3 bin conf ec2 lib licenses NOTICE R RELEASE 4 CHANGES.txt data examples LICENSE logs python README.md sbin 5 [root@master spark-1.6.1-bin-hadoop2.6]# bi 6 bind biosdecode biosdevname 7 [root@master spark-1.6.1-bin-hadoop2.6]# cd bin/ 8 [root@master bin]# ls 9 beeline pyspark run-example2.cmd spark-class.cmd spark-shell spark-submit 10 beeline.cmd pyspark2.cmd run-example.cmd sparkR spark-shell2.cmd spark-submit2.cmd 11 load-spark-env.cmd pyspark.cmd spark-class sparkR2.cmd spark-shell.cmd spark-submit.cmd 12 load-spark-env.sh run-example spark-class2.cmd sparkR.cmd spark-sql 13 [root@master bin]# ./spark-submit \ 14 > --class org.apache.spark.examples.SparkPi \ 15 > --master spark://master:7077 \ 16 > --executor-memory 1G \ 17 > --total-executor-cores 2 \ 18 > /home/hadoop/spark-1.6.1-bin-hadoop2.6/l 19 lib/ licenses/ logs/ 20 > /home/hadoop/spark-1.6.1-bin-hadoop2.6/lib/spark-examples-1.6.1-hadoop2.6.0.jar \ 21 > 100 22 Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 23 18/01/02 19:44:01 INFO SparkContext: Running Spark version 1.6.1 24 18/01/02 19:44:05 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 25 18/01/02 19:44:06 INFO SecurityManager: Changing view acls to: root 26 18/01/02 19:44:06 INFO SecurityManager: Changing modify acls to: root 27 18/01/02 19:44:06 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root) 28 18/01/02 19:44:09 INFO Utils: Successfully started service 'sparkDriver' on port 41731. 29 18/01/02 19:44:11 INFO Slf4jLogger: Slf4jLogger started 30 18/01/02 19:44:11 INFO Remoting: Starting remoting 31 18/01/02 19:44:12 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@192.168.3.129:49630] 32 18/01/02 19:44:12 INFO Utils: Successfully started service 'sparkDriverActorSystem' on port 49630. 33 18/01/02 19:44:13 INFO SparkEnv: Registering MapOutputTracker 34 18/01/02 19:44:13 INFO SparkEnv: Registering BlockManagerMaster 35 18/01/02 19:44:13 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-c154fc3f-8552-49d4-9a9a-1ce79dba74d7 36 18/01/02 19:44:13 INFO MemoryStore: MemoryStore started with capacity 517.4 MB 37 18/01/02 19:44:14 INFO SparkEnv: Registering OutputCommitCoordinator 38 18/01/02 19:44:15 INFO Utils: Successfully started service 'SparkUI' on port 4040. 39 18/01/02 19:44:15 INFO SparkUI: Started SparkUI at http://192.168.3.129:4040 40 18/01/02 19:44:15 INFO HttpFileServer: HTTP File server directory is /tmp/spark-2b7d6514-96ad-4999-a7d0-5797b4a53652/httpd-fda58f3c-9d2e-49df-bfe7-2a72fd6dab39 41 18/01/02 19:44:15 INFO HttpServer: Starting HTTP Server 42 18/01/02 19:44:15 INFO Utils: Successfully started service 'HTTP file server' on port 42161. 43 18/01/02 19:44:18 INFO SparkContext: Added JAR file:/home/hadoop/spark-1.6.1-bin-hadoop2.6/lib/spark-examples-1.6.1-hadoop2.6.0.jar at http://192.168.3.129:42161/jars/spark-examples-1.6.1-hadoop2.6.0.jar with timestamp 1514951058742 44 18/01/02 19:44:19 INFO AppClient$ClientEndpoint: Connecting to master spark://master:7077... 45 18/01/02 19:44:28 INFO SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20180102194427-0000 46 18/01/02 19:44:30 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 58259. 47 18/01/02 19:44:30 INFO NettyBlockTransferService: Server created on 58259 48 18/01/02 19:44:30 INFO BlockManagerMaster: Trying to register BlockManager 49 18/01/02 19:44:30 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.3.129:58259 with 517.4 MB RAM, BlockManagerId(driver, 192.168.3.129, 58259) 50 18/01/02 19:44:30 INFO BlockManagerMaster: Registered BlockManager 51 18/01/02 19:44:31 INFO AppClient$ClientEndpoint: Executor added: app-20180102194427-0000/0 on worker-20180103095039-192.168.3.131-39684 (192.168.3.131:39684) with 1 cores 52 18/01/02 19:44:31 INFO SparkDeploySchedulerBackend: Granted executor ID app-20180102194427-0000/0 on hostPort 192.168.3.131:39684 with 1 cores, 1024.0 MB RAM 53 18/01/02 19:44:31 INFO AppClient$ClientEndpoint: Executor added: app-20180102194427-0000/1 on worker-20180103095039-192.168.3.130-46477 (192.168.3.130:46477) with 1 cores 54 18/01/02 19:44:31 INFO SparkDeploySchedulerBackend: Granted executor ID app-20180102194427-0000/1 on hostPort 192.168.3.130:46477 with 1 cores, 1024.0 MB RAM 55 18/01/02 19:44:33 INFO SparkDeploySchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0 56 18/01/02 19:44:37 INFO SparkContext: Starting job: reduce at SparkPi.scala:36 57 18/01/02 19:44:38 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:36) with 100 output partitions 58 18/01/02 19:44:38 INFO DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:36) 59 18/01/02 19:44:38 INFO DAGScheduler: Parents of final stage: List() 60 18/01/02 19:44:38 INFO DAGScheduler: Missing parents: List() 61 18/01/02 19:44:38 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:32), which has no missing parents 62 18/01/02 19:44:41 INFO AppClient$ClientEndpoint: Executor updated: app-20180102194427-0000/0 is now RUNNING 63 18/01/02 19:44:41 INFO AppClient$ClientEndpoint: Executor updated: app-20180102194427-0000/1 is now RUNNING 64 18/01/02 19:44:44 WARN SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes 65 18/01/02 19:44:45 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1904.0 B, free 1904.0 B) 66 18/01/02 19:44:46 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1216.0 B, free 3.0 KB) 67 18/01/02 19:44:46 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.3.129:58259 (size: 1216.0 B, free: 517.4 MB) 68 18/01/02 19:44:46 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1006 69 18/01/02 19:44:46 INFO DAGScheduler: Submitting 100 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:32) 70 18/01/02 19:44:46 INFO TaskSchedulerImpl: Adding task set 0.0 with 100 tasks 71 18/01/02 19:45:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 72 18/01/02 19:45:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 73 18/01/02 19:45:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 74 18/01/02 19:45:46 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 75 18/01/02 19:46:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 76 18/01/02 19:46:07 INFO AppClient$ClientEndpoint: Executor updated: app-20180102194427-0000/0 is now EXITED (Command exited with code 1) 77 18/01/02 19:46:07 INFO SparkDeploySchedulerBackend: Executor app-20180102194427-0000/0 removed: Command exited with code 1 78 18/01/02 19:46:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 79 18/01/02 19:46:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 80 18/01/02 19:46:46 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 81 18/01/02 19:47:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 82 18/01/02 19:47:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 83 18/01/02 19:47:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 84 18/01/02 19:47:46 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 85 ^C18/01/02 19:47:58 INFO SparkContext: Invoking stop() from shutdown hook 86 18/01/02 19:47:58 INFO SparkUI: Stopped Spark web UI at http://192.168.3.129:4040 87 18/01/02 19:47:58 INFO DAGScheduler: Job 0 failed: reduce at SparkPi.scala:36, took 201.147338 s 88 18/01/02 19:47:58 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:36) failed in 191.823 s 89 Exception in thread "main" 18/01/02 19:47:58 ERROR LiveListenerBus: SparkListenerBus has already stopped! Dropping event SparkListenerStageCompleted(org.apache.spark.scheduler.StageInfo@10d7390) 90 18/01/02 19:47:58 ERROR LiveListenerBus: SparkListenerBus has already stopped! Dropping event SparkListenerJobEnd(0,1514951278747,JobFailed(org.apache.spark.SparkException: Job 0 cancelled because SparkContext was shut down)) 91 18/01/02 19:47:58 INFO SparkDeploySchedulerBackend: Shutting down all executors 92 org.apache.spark.SparkException: Job 0 cancelled because SparkContext was shut down 93 at org.apache.spark.scheduler.DAGScheduler$$anonfun$cleanUpAfterSchedulerStop$1.apply(DAGScheduler.scala:806) 94 at org.apache.spark.scheduler.DAGScheduler$$anonfun$cleanUpAfterSchedulerStop$1.apply(DAGScheduler.scala:804) 95 at scala.collection.mutable.HashSet.foreach(HashSet.scala:79) 96 at org.apache.spark.scheduler.DAGScheduler.cleanUpAfterSchedulerStop(DAGScheduler.scala:804) 97 at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onStop(DAGScheduler.scala:1658) 98 at org.apache.spark.util.EventLoop.stop(EventLoop.scala:84) 99 at org.apache.spark.scheduler.DAGScheduler.stop(DAGScheduler.scala:1581) 100 at org.apache.spark.SparkContext$$anonfun$stop$9.apply$mcV$sp(SparkContext.scala:1740) 101 at org.apache.spark.util.Utils$.tryLogNonFatalError(Utils.scala:1229) 102 at org.apache.spark.SparkContext.stop(SparkContext.scala:1739) 103 at org.apache.spark.SparkContext$$anonfun$3.apply$mcV$sp(SparkContext.scala:596) 104 at org.apache.spark.util.SparkShutdownHook.run(ShutdownHookManager.scala:267) 105 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply$mcV$sp(ShutdownHookManager.scala:239) 106 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply(ShutdownHookManager.scala:239) 107 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply(ShutdownHookManager.scala:239) 108 at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1765) 109 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply$mcV$sp(ShutdownHookManager.scala:239) 110 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply(ShutdownHookManager.scala:239) 111 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply(ShutdownHookManager.scala:239) 112 at scala.util.Try$.apply(Try.scala:161) 113 at org.apache.spark.util.SparkShutdownHookManager.runAll(ShutdownHookManager.scala:239) 114 at org.apache.spark.util.SparkShutdownHookManager$$anon$2.run(ShutdownHookManager.scala:218) 115 at org.apache.hadoop.util.ShutdownHookManager$1.run(ShutdownHookManager.java:54) 116 at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:620) 117 at org.apache.spark.SparkContext.runJob(SparkContext.scala:1832) 118 at org.apache.spark.SparkContext.runJob(SparkContext.scala:1952) 119 at org.apache.spark.rdd.RDD$$anonfun$reduce$1.apply(RDD.scala:1025) 120 at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150) 121 at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111) 122 at org.apache.spark.rdd.RDD.withScope(RDD.scala:316) 123 at org.apache.spark.rdd.RDD.reduce(RDD.scala:1007) 124 at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:36) 125 at org.apache.spark.examples.SparkPi.main(SparkPi.scala) 126 at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) 127 at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) 128 at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) 129 at java.lang.reflect.Method.invoke(Method.java:606) 130 at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731) 131 at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181) 132 at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206) 133 at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121) 134 at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) 135 ^C18/01/02 19:48:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 136 ^C^C^C^C^C 137 18/01/02 19:48:07 WARN NettyRpcEndpointRef: Error sending message [message = RemoveExecutor(0,Command exited with code 1)] in 1 attempts 138 org.apache.spark.rpc.RpcTimeoutException: Futures timed out after [120 seconds]. This timeout is controlled by spark.rpc.askTimeout 139 at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) 140 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) 141 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) 142 at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) 143 at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:76) 144 at org.apache.spark.rpc.RpcEndpointRef.askWithRetry(RpcEndpointRef.scala:101) 145 at org.apache.spark.rpc.RpcEndpointRef.askWithRetry(RpcEndpointRef.scala:77) 146 at org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.removeExecutor(CoarseGrainedSchedulerBackend.scala:359) 147 at org.apache.spark.scheduler.cluster.SparkDeploySchedulerBackend.executorRemoved(SparkDeploySchedulerBackend.scala:144) 148 at org.apache.spark.deploy.client.AppClient$ClientEndpoint$$anonfun$receive$1.applyOrElse(AppClient.scala:186) 149 at org.apache.spark.rpc.netty.Inbox$$anonfun$process$1.apply$mcV$sp(Inbox.scala:116) 150 at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:204) 151 at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100) 152 at org.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:215) 153 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 154 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 155 at java.lang.Thread.run(Thread.java:745) 156 Caused by: java.util.concurrent.TimeoutException: Futures timed out after [120 seconds] 157 at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:219) 158 at scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:223) 159 at scala.concurrent.Await$$anonfun$result$1.apply(package.scala:107) 160 at scala.concurrent.BlockContext$DefaultBlockContext$.blockOn(BlockContext.scala:53) 161 at scala.concurrent.Await$.result(package.scala:107) 162 at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:75) 163 ... 12 more 164 ^C^C^C^C^C^C^C^C^C 165 166 167 ^C^C^C^C^C^C^C^C^C^C^C18/01/02 19:48:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 168 ^C^C^C^C^C^C^C^C^C^C18/01/02 19:48:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 169 18/01/02 19:48:46 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 170 18/01/02 19:49:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 171 18/01/02 19:49:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 172 18/01/02 19:49:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 173 18/01/02 19:49:46 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 174 18/01/02 19:49:58 WARN NettyRpcEndpointRef: Error sending message [message = StopExecutors] in 1 attempts 175 org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout 176 at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) 177 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) 178 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) 179 at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) 180 at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:185) 181 at scala.util.Try$.apply(Try.scala:161) 182 at scala.util.Failure.recover(Try.scala:185) 183 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 184 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 185 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 186 at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293) 187 at scala.concurrent.impl.ExecutionContextImpl$$anon$1.execute(ExecutionContextImpl.scala:133) 188 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 189 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 190 at scala.concurrent.Promise$class.complete(Promise.scala:55) 191 at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:153) 192 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 193 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 194 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 195 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.processBatch$1(Future.scala:643) 196 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply$mcV$sp(Future.scala:658) 197 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 198 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 199 at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) 200 at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:634) 201 at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:694) 202 at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:685) 203 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 204 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 205 at scala.concurrent.Promise$class.tryFailure(Promise.scala:112) 206 at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:153) 207 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:241) 208 at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) 209 at java.util.concurrent.FutureTask.run(FutureTask.java:262) 210 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178) 211 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292) 212 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 213 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 214 at java.lang.Thread.run(Thread.java:745) 215 Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in 120 seconds 216 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:242) 217 ... 7 more 218 18/01/02 19:50:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 219 18/01/02 19:50:10 WARN NettyRpcEndpointRef: Error sending message [message = RemoveExecutor(0,Command exited with code 1)] in 2 attempts 220 org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout 221 at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) 222 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) 223 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) 224 at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) 225 at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:185) 226 at scala.util.Try$.apply(Try.scala:161) 227 at scala.util.Failure.recover(Try.scala:185) 228 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 229 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 230 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 231 at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293) 232 at scala.concurrent.impl.ExecutionContextImpl$$anon$1.execute(ExecutionContextImpl.scala:133) 233 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 234 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 235 at scala.concurrent.Promise$class.complete(Promise.scala:55) 236 at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:153) 237 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 238 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 239 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 240 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.processBatch$1(Future.scala:643) 241 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply$mcV$sp(Future.scala:658) 242 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 243 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 244 at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) 245 at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:634) 246 at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:694) 247 at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:685) 248 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 249 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 250 at scala.concurrent.Promise$class.tryFailure(Promise.scala:112) 251 at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:153) 252 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:241) 253 at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) 254 at java.util.concurrent.FutureTask.run(FutureTask.java:262) 255 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178) 256 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292) 257 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 258 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 259 at java.lang.Thread.run(Thread.java:745) 260 Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in 120 seconds 261 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:242) 262 ... 7 more 263 18/01/02 19:50:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 264 18/01/02 19:50:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 265 18/01/02 19:50:46 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 266 18/01/02 19:51:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 267 18/01/02 19:51:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 268 18/01/02 19:51:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 269 18/01/02 19:51:46 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 270 18/01/02 19:52:01 WARN NettyRpcEndpointRef: Error sending message [message = StopExecutors] in 2 attempts 271 org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout 272 at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) 273 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) 274 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) 275 at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) 276 at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:185) 277 at scala.util.Try$.apply(Try.scala:161) 278 at scala.util.Failure.recover(Try.scala:185) 279 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 280 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 281 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 282 at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293) 283 at scala.concurrent.impl.ExecutionContextImpl$$anon$1.execute(ExecutionContextImpl.scala:133) 284 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 285 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 286 at scala.concurrent.Promise$class.complete(Promise.scala:55) 287 at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:153) 288 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 289 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 290 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 291 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.processBatch$1(Future.scala:643) 292 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply$mcV$sp(Future.scala:658) 293 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 294 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 295 at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) 296 at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:634) 297 at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:694) 298 at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:685) 299 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 300 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 301 at scala.concurrent.Promise$class.tryFailure(Promise.scala:112) 302 at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:153) 303 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:241) 304 at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) 305 at java.util.concurrent.FutureTask.run(FutureTask.java:262) 306 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178) 307 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292) 308 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 309 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 310 at java.lang.Thread.run(Thread.java:745) 311 Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in 120 seconds 312 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:242) 313 ... 7 more 314 18/01/02 19:52:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 315 18/01/02 19:52:13 WARN NettyRpcEndpointRef: Error sending message [message = RemoveExecutor(0,Command exited with code 1)] in 3 attempts 316 org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout 317 at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) 318 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) 319 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) 320 at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) 321 at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:185) 322 at scala.util.Try$.apply(Try.scala:161) 323 at scala.util.Failure.recover(Try.scala:185) 324 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 325 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 326 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 327 at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293) 328 at scala.concurrent.impl.ExecutionContextImpl$$anon$1.execute(ExecutionContextImpl.scala:133) 329 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 330 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 331 at scala.concurrent.Promise$class.complete(Promise.scala:55) 332 at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:153) 333 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 334 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 335 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 336 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.processBatch$1(Future.scala:643) 337 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply$mcV$sp(Future.scala:658) 338 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 339 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 340 at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) 341 at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:634) 342 at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:694) 343 at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:685) 344 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 345 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 346 at scala.concurrent.Promise$class.tryFailure(Promise.scala:112) 347 at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:153) 348 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:241) 349 at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) 350 at java.util.concurrent.FutureTask.run(FutureTask.java:262) 351 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178) 352 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292) 353 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 354 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 355 at java.lang.Thread.run(Thread.java:745) 356 Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in 120 seconds 357 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:242) 358 ... 7 more 359 18/01/02 19:52:13 ERROR Inbox: Ignoring error 360 org.apache.spark.SparkException: Error notifying standalone scheduler's driver endpoint 361 at org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.removeExecutor(CoarseGrainedSchedulerBackend.scala:362) 362 at org.apache.spark.scheduler.cluster.SparkDeploySchedulerBackend.executorRemoved(SparkDeploySchedulerBackend.scala:144) 363 at org.apache.spark.deploy.client.AppClient$ClientEndpoint$$anonfun$receive$1.applyOrElse(AppClient.scala:186) 364 at org.apache.spark.rpc.netty.Inbox$$anonfun$process$1.apply$mcV$sp(Inbox.scala:116) 365 at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:204) 366 at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100) 367 at org.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:215) 368 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 369 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 370 at java.lang.Thread.run(Thread.java:745) 371 Caused by: org.apache.spark.SparkException: Error sending message [message = RemoveExecutor(0,Command exited with code 1)] 372 at org.apache.spark.rpc.RpcEndpointRef.askWithRetry(RpcEndpointRef.scala:118) 373 at org.apache.spark.rpc.RpcEndpointRef.askWithRetry(RpcEndpointRef.scala:77) 374 at org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.removeExecutor(CoarseGrainedSchedulerBackend.scala:359) 375 ... 9 more 376 Caused by: org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout 377 at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) 378 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) 379 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) 380 at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) 381 at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:185) 382 at scala.util.Try$.apply(Try.scala:161) 383 at scala.util.Failure.recover(Try.scala:185) 384 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 385 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 386 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 387 at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293) 388 at scala.concurrent.impl.ExecutionContextImpl$$anon$1.execute(ExecutionContextImpl.scala:133) 389 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 390 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 391 at scala.concurrent.Promise$class.complete(Promise.scala:55) 392 at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:153) 393 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 394 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 395 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 396 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.processBatch$1(Future.scala:643) 397 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply$mcV$sp(Future.scala:658) 398 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 399 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 400 at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) 401 at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:634) 402 at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:694) 403 at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:685) 404 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 405 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 406 at scala.concurrent.Promise$class.tryFailure(Promise.scala:112) 407 at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:153) 408 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:241) 409 at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) 410 at java.util.concurrent.FutureTask.run(FutureTask.java:262) 411 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178) 412 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292) 413 ... 3 more 414 Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in 120 seconds 415 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:242) 416 ... 7 more 417 18/01/02 19:52:13 INFO AppClient$ClientEndpoint: Executor added: app-20180102194427-0000/2 on worker-20180103095039-192.168.3.131-39684 (192.168.3.131:39684) with 1 cores 418 18/01/02 19:52:13 INFO SparkDeploySchedulerBackend: Granted executor ID app-20180102194427-0000/2 on hostPort 192.168.3.131:39684 with 1 cores, 1024.0 MB RAM 419 18/01/02 19:52:13 INFO AppClient$ClientEndpoint: Executor updated: app-20180102194427-0000/1 is now EXITED (Command exited with code 1) 420 18/01/02 19:52:13 INFO SparkDeploySchedulerBackend: Executor app-20180102194427-0000/1 removed: Command exited with code 1 421 18/01/02 19:52:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 422 18/01/02 19:52:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 423 18/01/02 19:52:46 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 424 18/01/02 19:53:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 425 18/01/02 19:53:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 426 18/01/02 19:53:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 427 18/01/02 19:53:46 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 428 18/01/02 19:54:01 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 429 18/01/02 19:54:04 WARN NettyRpcEndpointRef: Error sending message [message = StopExecutors] in 3 attempts 430 org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout 431 at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) 432 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) 433 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) 434 at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) 435 at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:185) 436 at scala.util.Try$.apply(Try.scala:161) 437 at scala.util.Failure.recover(Try.scala:185) 438 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 439 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 440 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 441 at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293) 442 at scala.concurrent.impl.ExecutionContextImpl$$anon$1.execute(ExecutionContextImpl.scala:133) 443 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 444 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 445 at scala.concurrent.Promise$class.complete(Promise.scala:55) 446 at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:153) 447 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 448 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 449 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 450 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.processBatch$1(Future.scala:643) 451 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply$mcV$sp(Future.scala:658) 452 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 453 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 454 at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) 455 at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:634) 456 at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:694) 457 at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:685) 458 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 459 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 460 at scala.concurrent.Promise$class.tryFailure(Promise.scala:112) 461 at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:153) 462 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:241) 463 at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) 464 at java.util.concurrent.FutureTask.run(FutureTask.java:262) 465 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178) 466 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292) 467 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 468 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 469 at java.lang.Thread.run(Thread.java:745) 470 Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in 120 seconds 471 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:242) 472 ... 7 more 473 18/01/02 19:54:04 ERROR Utils: Uncaught exception in thread Thread-3 474 org.apache.spark.SparkException: Error asking standalone scheduler to shut down executors 475 at org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.stopExecutors(CoarseGrainedSchedulerBackend.scala:328) 476 at org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.stop(CoarseGrainedSchedulerBackend.scala:333) 477 at org.apache.spark.scheduler.cluster.SparkDeploySchedulerBackend.org$apache$spark$scheduler$cluster$SparkDeploySchedulerBackend$$stop(SparkDeploySchedulerBackend.scala:197) 478 at org.apache.spark.scheduler.cluster.SparkDeploySchedulerBackend.stop(SparkDeploySchedulerBackend.scala:101) 479 at org.apache.spark.scheduler.TaskSchedulerImpl.stop(TaskSchedulerImpl.scala:446) 480 at org.apache.spark.scheduler.DAGScheduler.stop(DAGScheduler.scala:1582) 481 at org.apache.spark.SparkContext$$anonfun$stop$9.apply$mcV$sp(SparkContext.scala:1740) 482 at org.apache.spark.util.Utils$.tryLogNonFatalError(Utils.scala:1229) 483 at org.apache.spark.SparkContext.stop(SparkContext.scala:1739) 484 at org.apache.spark.SparkContext$$anonfun$3.apply$mcV$sp(SparkContext.scala:596) 485 at org.apache.spark.util.SparkShutdownHook.run(ShutdownHookManager.scala:267) 486 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply$mcV$sp(ShutdownHookManager.scala:239) 487 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply(ShutdownHookManager.scala:239) 488 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply(ShutdownHookManager.scala:239) 489 at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1765) 490 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply$mcV$sp(ShutdownHookManager.scala:239) 491 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply(ShutdownHookManager.scala:239) 492 at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply(ShutdownHookManager.scala:239) 493 at scala.util.Try$.apply(Try.scala:161) 494 at org.apache.spark.util.SparkShutdownHookManager.runAll(ShutdownHookManager.scala:239) 495 at org.apache.spark.util.SparkShutdownHookManager$$anon$2.run(ShutdownHookManager.scala:218) 496 at org.apache.hadoop.util.ShutdownHookManager$1.run(ShutdownHookManager.java:54) 497 Caused by: org.apache.spark.SparkException: Error sending message [message = StopExecutors] 498 at org.apache.spark.rpc.RpcEndpointRef.askWithRetry(RpcEndpointRef.scala:118) 499 at org.apache.spark.rpc.RpcEndpointRef.askWithRetry(RpcEndpointRef.scala:77) 500 at org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.stopExecutors(CoarseGrainedSchedulerBackend.scala:324) 501 ... 21 more 502 Caused by: org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout 503 at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) 504 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) 505 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) 506 at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) 507 at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:185) 508 at scala.util.Try$.apply(Try.scala:161) 509 at scala.util.Failure.recover(Try.scala:185) 510 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 511 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 512 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 513 at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293) 514 at scala.concurrent.impl.ExecutionContextImpl$$anon$1.execute(ExecutionContextImpl.scala:133) 515 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 516 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 517 at scala.concurrent.Promise$class.complete(Promise.scala:55) 518 at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:153) 519 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 520 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 521 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 522 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.processBatch$1(Future.scala:643) 523 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply$mcV$sp(Future.scala:658) 524 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 525 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 526 at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) 527 at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:634) 528 at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:694) 529 at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:685) 530 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 531 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 532 at scala.concurrent.Promise$class.tryFailure(Promise.scala:112) 533 at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:153) 534 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:241) 535 at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) 536 at java.util.concurrent.FutureTask.run(FutureTask.java:262) 537 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178) 538 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292) 539 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 540 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 541 at java.lang.Thread.run(Thread.java:745) 542 Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in 120 seconds 543 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:242) 544 ... 7 more 545 18/01/02 19:54:13 WARN NettyRpcEndpointRef: Error sending message [message = RemoveExecutor(1,Command exited with code 1)] in 1 attempts 546 org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout 547 at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) 548 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) 549 at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) 550 at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) 551 at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:185) 552 at scala.util.Try$.apply(Try.scala:161) 553 at scala.util.Failure.recover(Try.scala:185) 554 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 555 at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) 556 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 557 at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293) 558 at scala.concurrent.impl.ExecutionContextImpl$$anon$1.execute(ExecutionContextImpl.scala:133) 559 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 560 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 561 at scala.concurrent.Promise$class.complete(Promise.scala:55) 562 at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:153) 563 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 564 at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) 565 at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) 566 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.processBatch$1(Future.scala:643) 567 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply$mcV$sp(Future.scala:658) 568 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 569 at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) 570 at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) 571 at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:634) 572 at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:694) 573 at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:685) 574 at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) 575 at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) 576 at scala.concurrent.Promise$class.tryFailure(Promise.scala:112) 577 at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:153) 578 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:241) 579 at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) 580 at java.util.concurrent.FutureTask.run(FutureTask.java:262) 581 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178) 582 at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292) 583 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 584 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 585 at java.lang.Thread.run(Thread.java:745) 586 Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in 120 seconds 587 at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:242) 588 ... 7 more 589 ^C^C^C^C^C^C^C 590 18/01/02 19:54:16 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 591 ^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C^C 592 593 594 595 596 ^X^X^X^X^C^C^C^C^C^C^C^C^C^C^C18/01/02 19:54:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources 597 ^C^C^C
由于之前学习hadoop,虚拟机内存才设置512M了,Spark是在内存中进行运算的,所以学习Spark一定要设置好内存啊,关闭虚拟机,将内存设置为1G,给Spark设置800M的内存,所以spark-env.sh配置,多添加了:
export SPARK_WORKER_MEMORY=800M
如下所示:
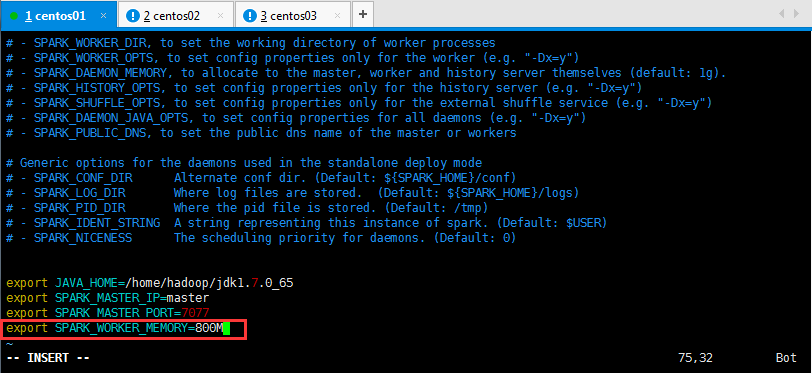
然后执行,如下所示命令:
1 [root@master spark-1.6.1-bin-hadoop2.6]# bin/spark-submit \ 2 > --class org.apache.spark.examples.SparkPi \ 3 > --master spark://master:7077 \ 4 > --executor-memory 512M \ 5 > --total-executor-cores 2 \ 6 > /home/hadoop/spark-1.6.1-bin-hadoop2.6/lib/spark-examples-1.6.1-hadoop2.6.0.jar \ 7 > 100
5:启动Spark Shell:
spark-shell是Spark自带的交互式Shell程序,方便用户进行交互式编程,用户可以在该命令行下用scala编写spark程序。
启动spark shell,如下所示:
注意:如果配置文件spark-env.sh配置内存,核数信息这里直接使用bin/spark-shell命令启动即可:
1 [root@master spark-1.6.1-bin-hadoop2.6]# bin/spark-shell \ 2 > --master spark://master:7077 \ 3 > --executor-memory 512M \ 4 > --total-executor-cores 2 5 6 参数说明: 7 --master spark://master:7077 指定Master的地址 8 --executor-memory 512M 指定每个worker可用内存为512M 9 --total-executor-cores 2 指定整个集群使用的cup核数为2个
如果启动spark-shell命令的时候,指定了--master的位置,那么运行的application就可以显示出来了,而不用去指定spark-default.sh文件;

注意:
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,没有与集群建立联系。
Spark Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可;
操作如下所示:
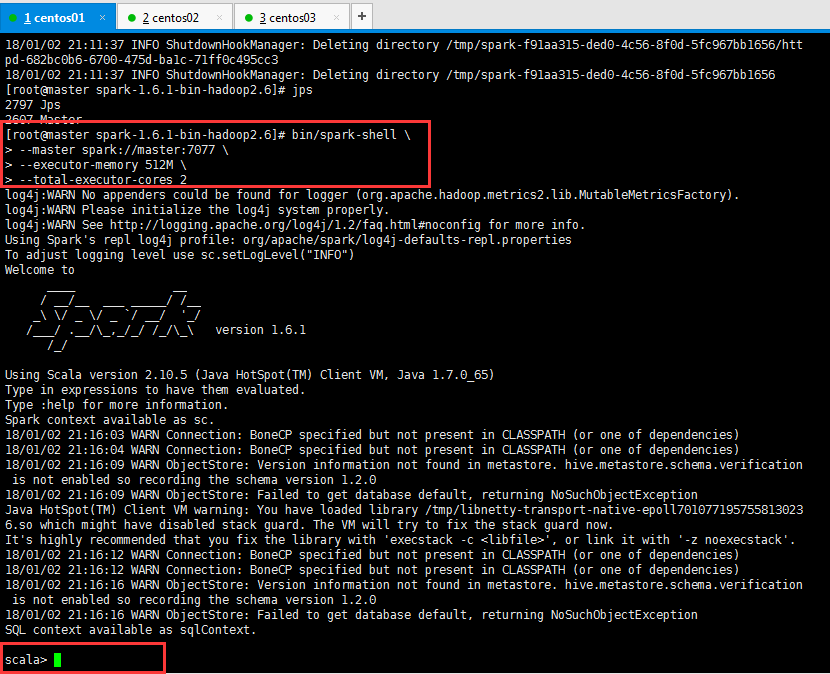
退出使用命令exit即可;
贴一下日了狗了的报错,没有接受指令超过一定时间就报错了,如下所示,按Enter又回到scala> 等待命令键入:
scala> 18/01/03 02:37:36 WARN NettyRpcEndpointRef: Error sending message [message = RemoveExecutor(0,Command exited with code 1)] in 1 attempts org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:185) at scala.util.Try$.apply(Try.scala:161) at scala.util.Failure.recover(Try.scala:185) at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293) at scala.concurrent.impl.ExecutionContextImpl$$anon$1.execute(ExecutionContextImpl.scala:133) at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) at scala.concurrent.Promise$class.complete(Promise.scala:55) at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:153) at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.processBatch$1(Future.scala:643) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply$mcV$sp(Future.scala:658) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:634) at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:694) at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:685) at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) at scala.concurrent.Promise$class.tryFailure(Promise.scala:112) at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:153) at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:241) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) at java.util.concurrent.FutureTask.run(FutureTask.java:262) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at java.lang.Thread.run(Thread.java:745) Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in 120 seconds at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:242) ... 7 more 18/01/03 02:39:39 WARN NettyRpcEndpointRef: Error sending message [message = RemoveExecutor(0,Command exited with code 1)] in 2 attempts org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:185) at scala.util.Try$.apply(Try.scala:161) at scala.util.Failure.recover(Try.scala:185) at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293) at scala.concurrent.impl.ExecutionContextImpl$$anon$1.execute(ExecutionContextImpl.scala:133) at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) at scala.concurrent.Promise$class.complete(Promise.scala:55) at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:153) at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.processBatch$1(Future.scala:643) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply$mcV$sp(Future.scala:658) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:634) at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:694) at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:685) at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) at scala.concurrent.Promise$class.tryFailure(Promise.scala:112) at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:153) at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:241) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) at java.util.concurrent.FutureTask.run(FutureTask.java:262) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at java.lang.Thread.run(Thread.java:745) Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in 120 seconds at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:242) ... 7 more
6:Spark 官网源码编译查看:

7:Linux安装Scala编译器:
下载地址:下载Scala地址http://downloads.typesafe.com/scala/2.10.6/scala-2.10.6.tgz然后解压Scala到指定目录
然后将下载的软件上传到虚拟机上面,过程省略。然后进行解压缩操作:
[root@master package]# tar -zxvf scala-2.10.6.tgz -C /home/hadoop/
然后,配置环境变量,将scala加入到PATH中:
[root@master package]# vim /etc/profile
配置内容如下所示:

然后刷新配置,最后进行验证即可:

退出按exit即可;
8:如果spark-defaults.conf文件(spark-defaults.conf是spark-defaults.conf.template文件cp过来的)不修改,默认的话是在本地运行的,如我的spark://master:7077,如果需要修改,就将这个默认值修改即可:
注意:如果master节点的主机hostname名称不是master,而是其他,比如我的slaver1是hostname,所以这里需要在spark-default.conf文件修改,不然默认是本地模式。那么浏览器的ui界面显示不出来运行的Running Applications;

如下所示,再启动你的bin/spark-shell就可以显示出来运行的applications了,那么就可以看详细信息了:

修改如下所示:
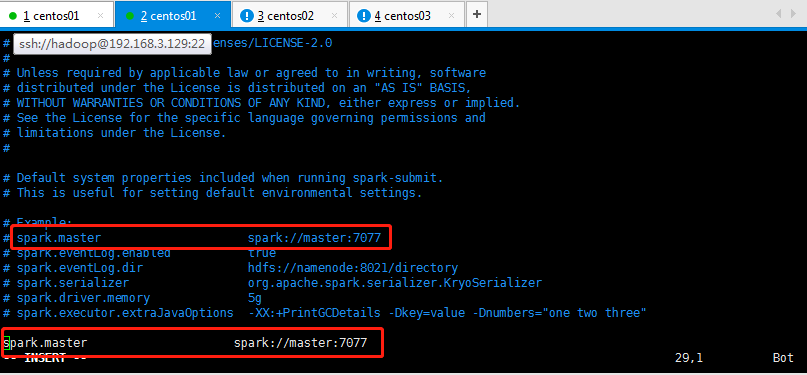
9:读取hdfs上面的文件内容,案例如下操作所示:
首先启动hadoop集群,然后将文件上传到hdfs上面,然后启动spark集群,打开spark shell。
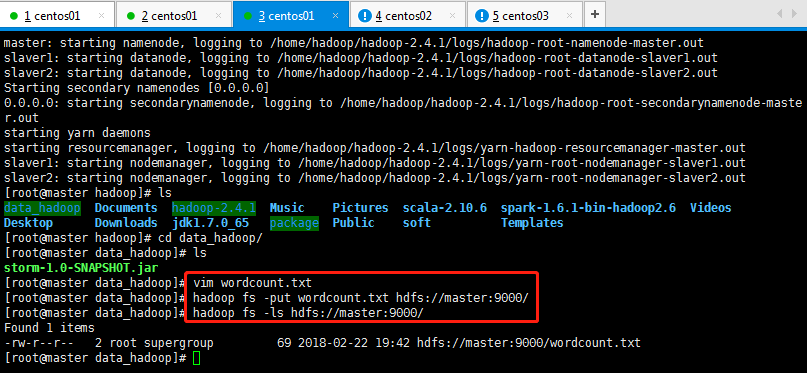
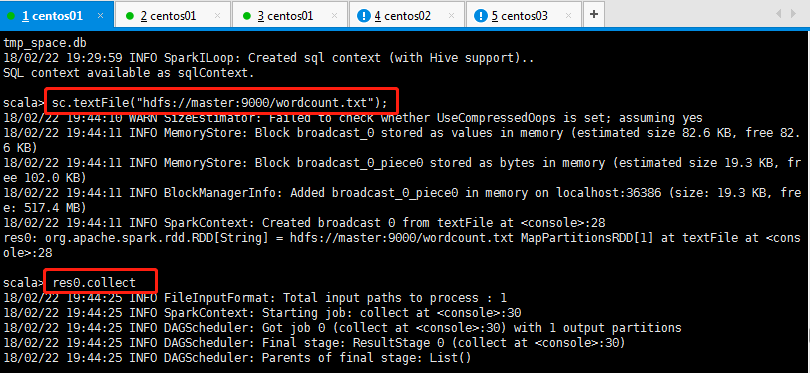
结果如下所示:

标准退出,sc.stop

10:可以使用帮助命令进行查看可以带的参数:
11:Spark的wordcount功能(类比hadoop的map,reduce操作,感觉spark瞬间简单了许多许多):
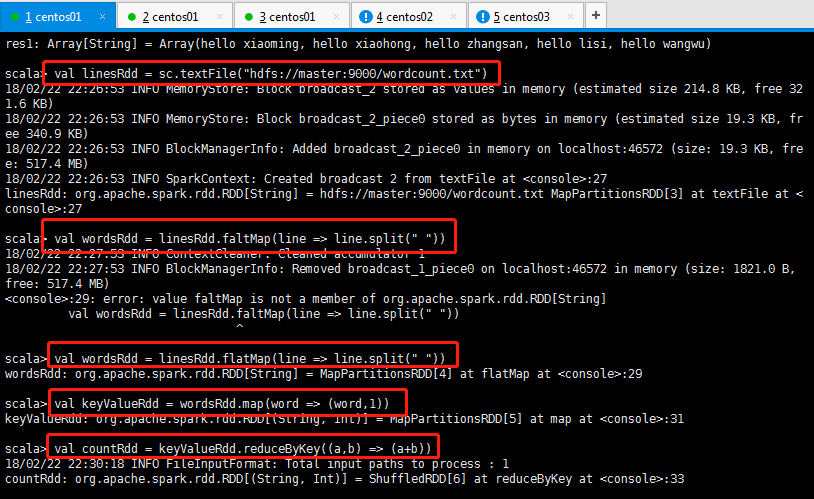
然后查看结果如下所示:

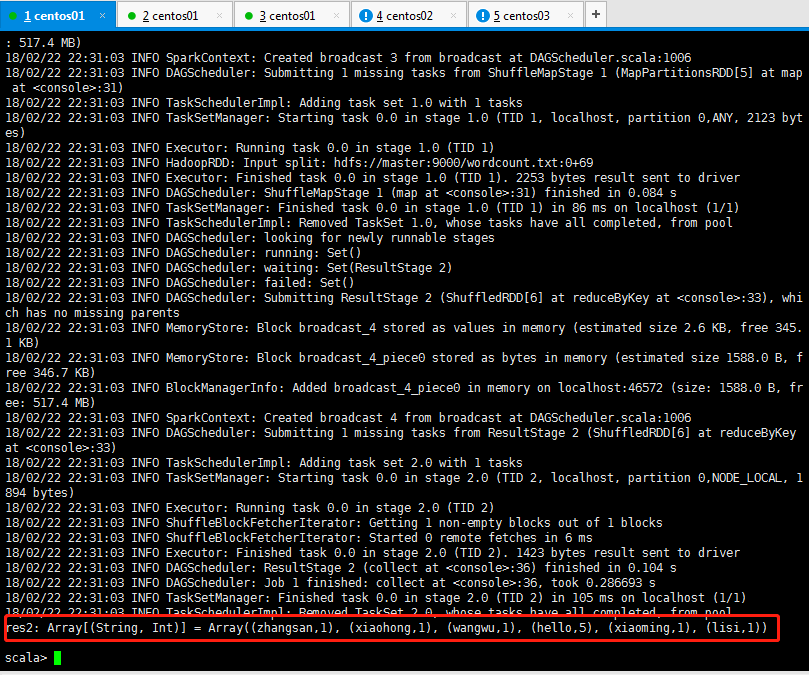
简写如下所示:
注意:spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包的依赖。
scala> sc.textFile("hdfs://master:9000/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).collect
解释说明:
sc是SparkContext对象,该对象时提交spark程序的入口。
textFile("hdfs://master:9000/wordcount.txt")是hdfs中读取数据。
flatMap(_.split(" "))先map再压平。
map((_,1))将单词和1构成元组。
reduceByKey(_+_)按照key进行reduce,并将value累加
12:Spark Running Architecture:
1:构建Spark Application运行环境: 在Driver Program中新建SparkContext(包含sparkcontext的程序称为Driver Program);Spark Application运行的表现方式为: 在集群上运行着一组独立的executor进程,这些进程由sparkcontext来协调; 2:SparkContext向资源管理器申请运行Executor资源,并启动StandaloneExecutorBackend,executor向SparkContext申请task;集群通过SparkContext连接到不同的cluster manager(standalone,yarn,mesos),cluster mangaer为运行应用的Executor分配资源;一旦连接建立以后,Spark每个Application就会获得各个节点上的Executor(进程);每个Application都有自己独立的executor进程;Executor才是真正运行在WorkNode上的工作进程,它们为应用来计算或者存储数据; 3:SparkContext获取到executor以后,Application的应用代码将会被发送到各个executor; 4:SparkContext构建RDD DAG图,将RDD DAG图分解成Stage DAG图,将Stage提交给TaskScheduler,最后由TaskScheduler将Task发送给Executor运行。 5:Task在Executor上运行,运行完毕后释放所有资源。
13、Spark JobHistoryServer:
1、应用运行完成以后,如何监控呢???
对于MapReduce应用来说,监控已经运行完成的应用,尤其当应用运行失败的时候,去查看错误异常,非常的关键。
2、Spark Application,运行的时候,使用4040端口进行监控,应用运行所在的机器。
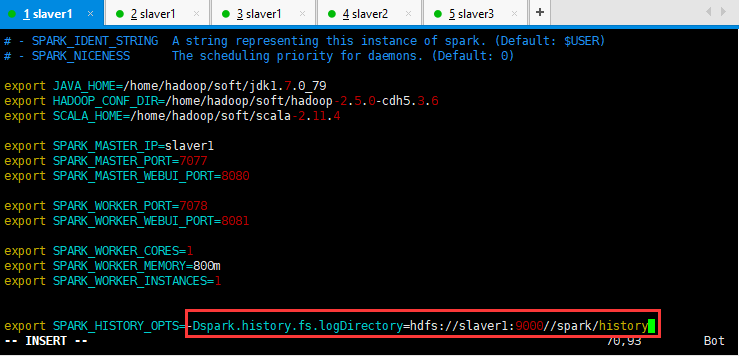
在Spark-env.sh文件里面添加:
export SPARK_HISTORY_OPTS=-Dspark.history.fs.logDirectory=hdfs://slaver1:9000//spark/history
然后配置一下Spark-default.sh文件(不然启动无法查看已经执行结束的应用的日志信息):

启动如下所示命令:
[hadoop@slaver1 spark-1.5.1-bin-hadoop2.4]$ ./sbin/start-history-server.sh
然后可以查看到停止的应用也可以查看日志信息,访问地址:http://192.168.19.131:18080/:

直接访问18080端口号是没有问题了,但是点击Application Detail UI的时候会报无法找到文件路径的错误,解决方法还未找到,先记录一下:
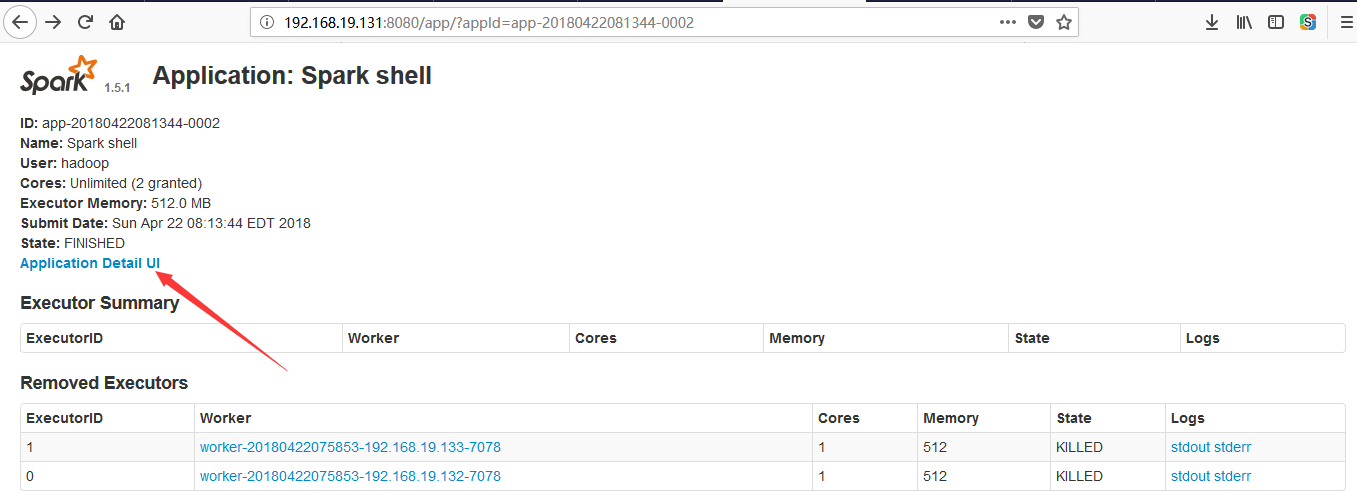
错误如下所示:

14、Spark Application运行的两种方式Client和Cluster区别:
[hadoop@slaver1 spark-1.5.1-bin-hadoop2.4]$ spark-shell --help
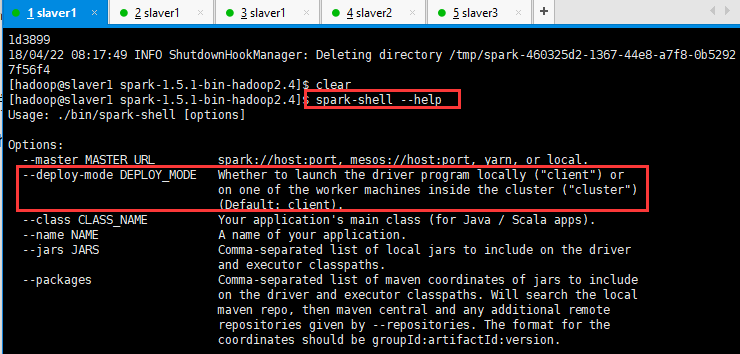
可以看到Spark Application运行的两种方式Client(本地模式)和Cluster(运行在集群上面),默认是client模式的。可以在http://192.168.19.131:8080/页面查看到它们之间的区别,执行的命令也有区别:
spark-submit \ --master spark://slaver1:7077 \ --executor-memory 512M \ --deploy-mode client \ /home/hadoop/soft/spark-1.5.1-bin-hadoop2.4/jars/helloScala.jar spark-submit \ --master spark://slaver1:7077 \ --executor-memory 512M \ --deploy-mode cluster \ /home/hadoop/soft/spark-1.5.1-bin-hadoop2.4/jars/helloScala.jar
15、 Spark 如何运行在YARN上(两种模式的区别):
首先停止你的Spark集群哦:[hadoop@slaver1 spark-1.5.1-bin-hadoop2.4]$ sbin/stop-all.sh
可以启动history节点:[hadoop@slaver1 spark-1.5.1-bin-hadoop2.4]$ ./sbin/start-history-server.sh
然后启动Spark 运行在Yarn上面的命令:[hadoop@slaver1 spark-1.5.1-bin-hadoop2.4]$ spark-shell --master yarn-client
出错以及解决链接:执行Spark运行在yarn上的命令报错 spark-shell --master yarn-client
待续......



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?