
Elasticsearch 6.x版本全文检索学习之集群调优建议
1、系统设置要到位,遵照官方建议设置所有的系统参数。
https://www.elastic.co/guide/en/elasticsearch/reference/6.7/setup.html

部署Elasticsearch集群之前将操作系统的配置设置好。 之前部署单机版、集群报了很多错误,嗯,就是这里可以解决你的问题,提前看下英文文档,解决这些问题。
https://www.elastic.co/guide/en/elasticsearch/reference/6.7/system-config.html
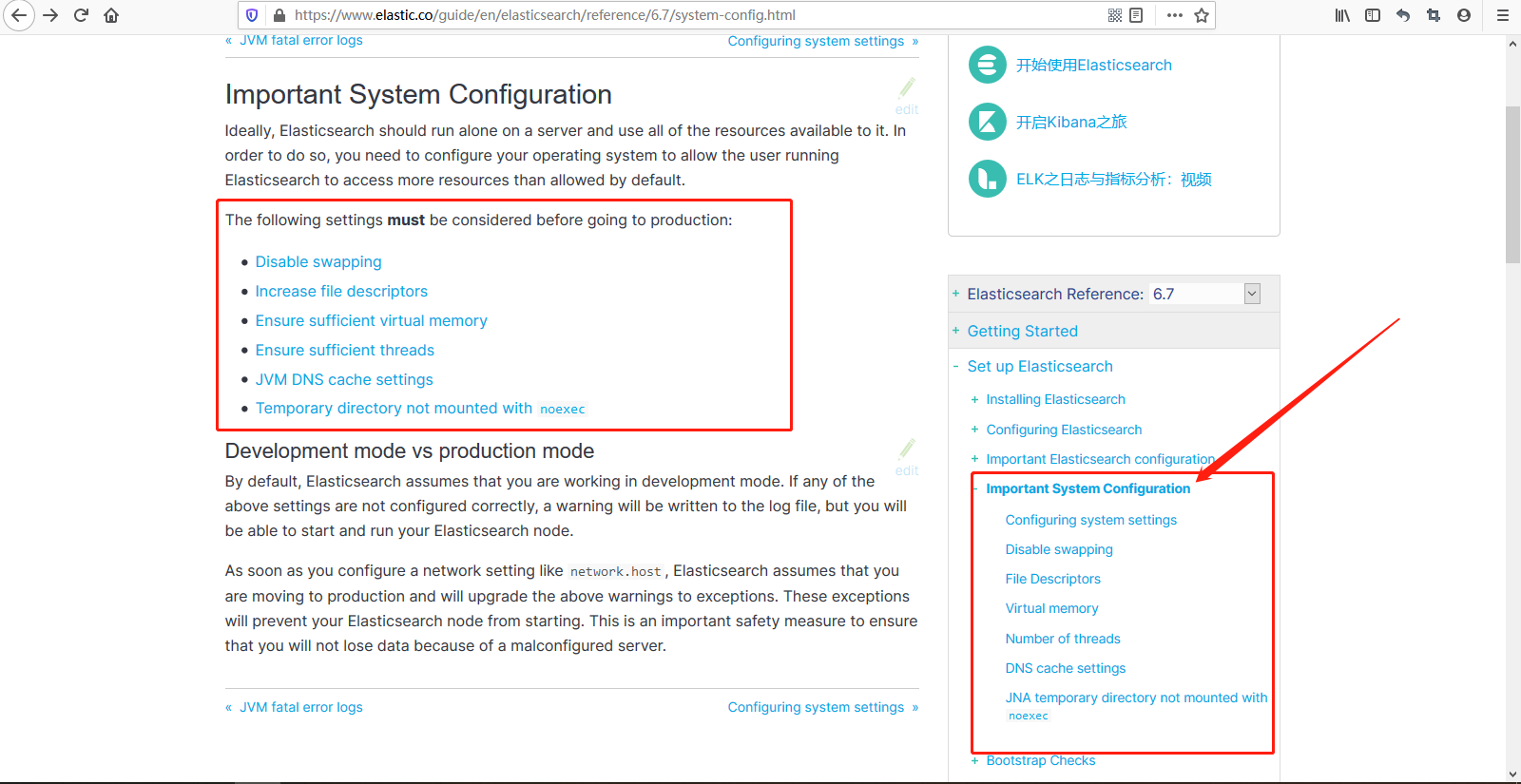
2、Elasticsearch设置尽量简洁,elasticsearch.yml中尽量只写必备的参数,其他可以通过api动态设置的参数都通过api来设置。随着es的版本升级,很多网络流传的配置参数已经不再支持,因此不要随意复制别人的集群配置参数。
https://www.elastic.co/guide/en/elasticsearch/reference/6.7/important-settings.html

3、elasticsearch.yml中建议设定的基本参数。
1)、静态设置参数elasticsearch.yml,cluster.name、node.name、node.master/node.data/node.ingest。
2)、network.host建议显示指定为内网ip,不要偷懒直接设定为0.0.0.0。
3)、discovery.zen.ping.unicast.hosts设定集群其他节点地址。
4)、discovery.zen.minimum_master_nodes一般设定为2。
5)、path.data/path.log。除上述参数外再根据需要增加其他的静态配置参数。

1 # ======================== Elasticsearch Configuration ========================= 2 # 3 # NOTE: Elasticsearch comes with reasonable defaults for most settings. 4 # Before you set out to tweak and tune the configuration, make sure you 5 # understand what are you trying to accomplish and the consequences. 6 # 7 # The primary way of configuring a node is via this file. This template lists 8 # the most important settings you may want to configure for a production cluster. 9 # 10 # Please consult the documentation for further information on configuration options: 11 # https://www.elastic.co/guide/en/elasticsearch/reference/index.html 12 # 13 # ---------------------------------- Cluster ----------------------------------- 14 # 15 # Use a descriptive name for your cluster: 16 # 17 #cluster.name: my-application 18 # 19 # ------------------------------------ Node ------------------------------------ 20 # 21 # Use a descriptive name for the node: 22 # 23 #node.name: node-1 24 # 25 # Add custom attributes to the node: 26 # 27 #node.attr.rack: r1 28 # 29 # ----------------------------------- Paths ------------------------------------ 30 # 31 # Path to directory where to store the data (separate multiple locations by comma): 32 # 33 #path.data: /path/to/data 34 # 35 # Path to log files: 36 # 37 #path.logs: /path/to/logs 38 # 39 # ----------------------------------- Memory ----------------------------------- 40 # 41 # Lock the memory on startup: 42 # 43 #bootstrap.memory_lock: true 44 # 45 # Make sure that the heap size is set to about half the memory available 46 # on the system and that the owner of the process is allowed to use this 47 # limit. 48 # 49 # Elasticsearch performs poorly when the system is swapping the memory. 50 # 51 # ---------------------------------- Network ----------------------------------- 52 # 53 # Set the bind address to a specific IP (IPv4 or IPv6): 54 # 55 #network.host: 192.168.0.1 56 57 # network.host: 192.168.110.133 58 network.host: 0.0.0.0 59 60 # 61 # Set a custom port for HTTP: 62 # 63 #http.port: 9200 64 # 65 # For more information, consult the network module documentation. 66 # 67 # --------------------------------- Discovery ---------------------------------- 68 # 69 # Pass an initial list of hosts to perform discovery when new node is started: 70 # The default list of hosts is ["127.0.0.1", "[::1]"] 71 # 72 #discovery.zen.ping.unicast.hosts: ["host1", "host2"] 73 # 74 75 # discovery.zen.ping.unicast.hosts: ["192.168.110.133:5200", "192.168.110.133:5300"] 76 77 78 # Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1): 79 # 80 # discovery.zen.minimum_master_nodes: 81 # 82 83 # discovery.zen.minimum_master_nodes: 1 84 85 # For more information, consult the zen discovery module documentation. 86 # 87 # ---------------------------------- Gateway ----------------------------------- 88 # 89 # Block initial recovery after a full cluster restart until N nodes are started: 90 # 91 #gateway.recover_after_nodes: 3 92 # 93 # For more information, consult the gateway module documentation. 94 # 95 # ---------------------------------- Various ----------------------------------- 96 # 97 # Require explicit names when deleting indices: 98 # 99 #action.destructive_requires_name: true
动态设置的参数elasticsearch.yml,有transient和persistent两种设置,前者在集群重启后会丢失,后者不会,但两种设定都会覆盖elasticsearch.yml。
1 # 动态设置的参数有transient和persistent两种设置 2 PUT /_cluster/settings 3 { 4 "persistent": { 5 "discovery.zen.minimum_master_nodes": 2 6 }, 7 "transient": { 8 "indices.store.throttle.max_bytes_per_sec": "50mb" 9 } 10 }
4、关于JVM内存设定,不要超过31GB,预留一半内存给操作系统,用来做文件缓存。
1)、具体大小根据该node要存储的数据量来估算,为了保证性能,在内存和数据量间有一个建议的比例。
搜索类项目的比例建议在1:16以内。即1GB内存可以存储16GB数据。
日志类项目的比例建议在1:48~1:96。即1GB内存可以存储48GB~96GB的数据。
2)、假设总数据量大小为1TB,3个node,1个副本,那么每个node要存储的数据量为2TB/3=666GB,即700GB左右,做20%的预留空间,每个node要存储大约850GB的数据。
如果是搜索类项目,每个node内存大小为850GB/16=53GB,大于31GB。31*16=496,即每个node最多存储496GB数据,所以需要至少5个node。
如果是日志类型项目,每个node内存大小为850GB/48=18GB,因此3个节点足够。
5、Elasticsearch写数据过程,写性能优化。refresh、translog、flush概念理解。红色截图来源于慕课网,尊重版权从你我做起。
Elasticsearch写数据,refresh过程理解如下所示:


Elasticsearch写数据,translog过程理解如下所示:


Elasticsearch写数据,flush过程理解如下所示:

Elasticsearch写数据过程,写性能优化。目标是增大写吞吐量-EPS(events Per Second)越高越好。
优化方案:a、客户端,多线程写,批量写。b、Elasticsearch,在高质量数据建模的前提下,主要是在refresh、translog和flush之间做文章。
Elasticsearch写数据过程,写性能优化。refresh优化。
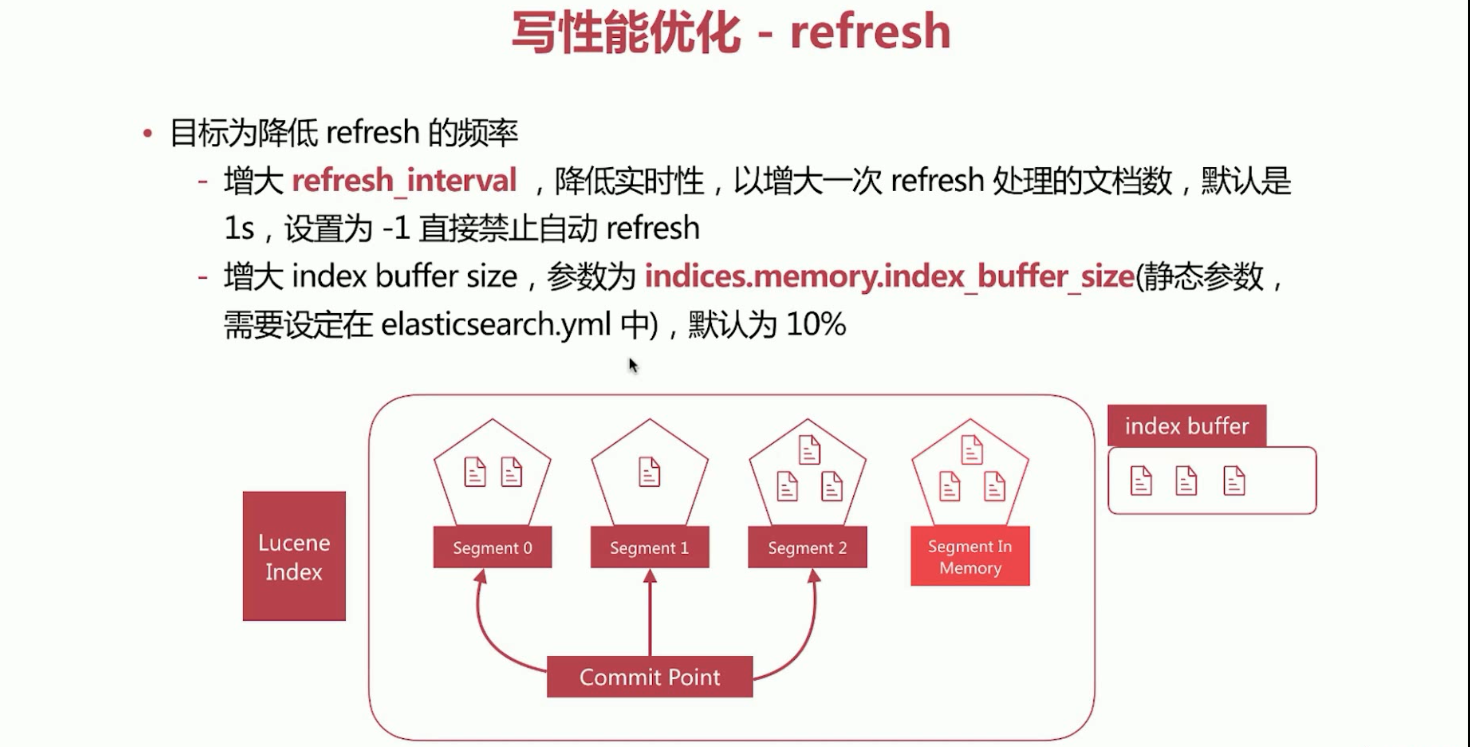
Elasticsearch写数据过程,写性能优化。translog优化。

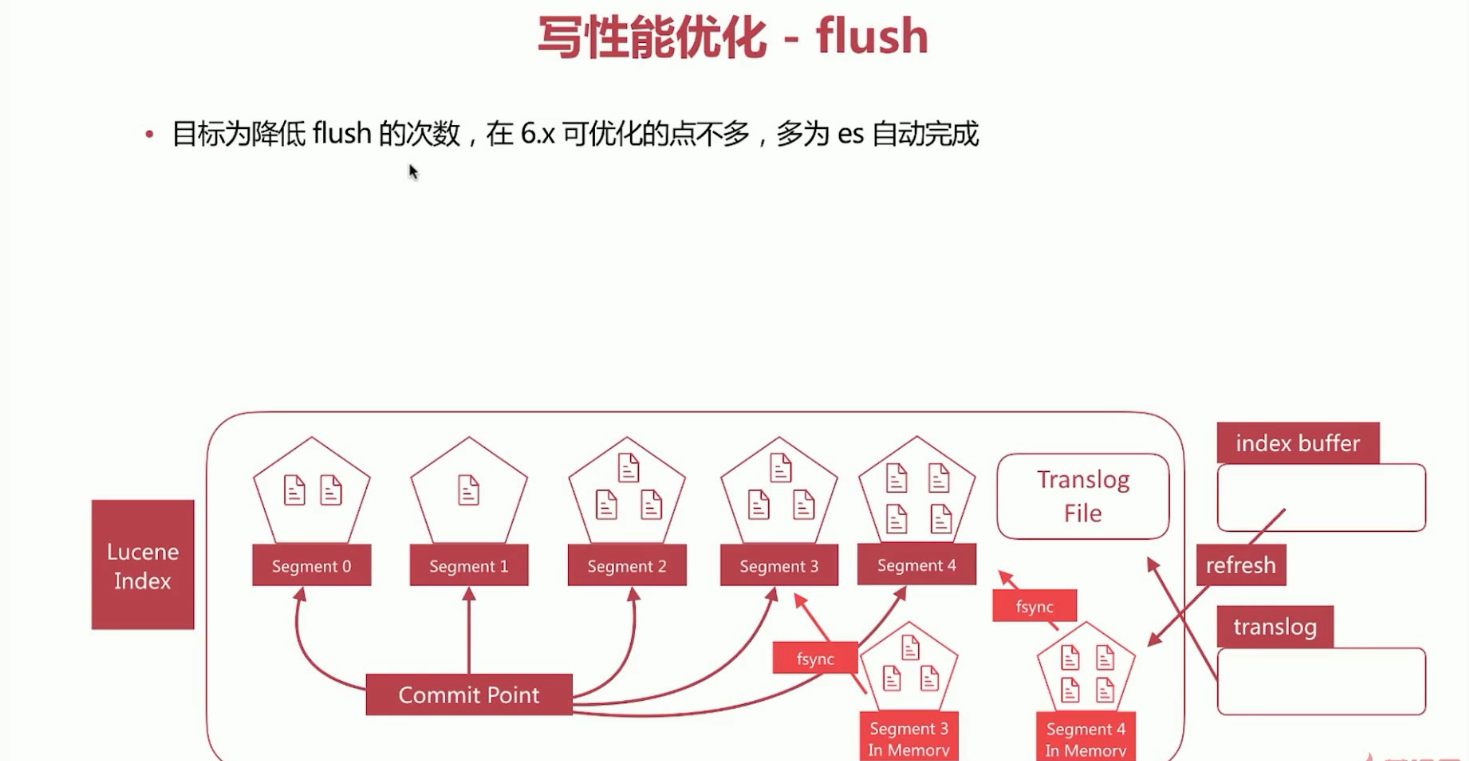
Elasticsearch写数据过程,写性能优化。flush优化。
6、读性能主要受以下几个方面的影响。
a、数据模型是否符合业务模型。数据建模。高质量的数据建模是优化的基础,将需要通过script脚本动态计算的值提前算好作为字段存到文档中。尽量使得数据模型铁近业务模型。
b、数据规模是否过大。数据规模。根据不同的数据规模设定不同的SLA,上万条数据与上千万条数据性能肯定存在差异。
c、索引配置是否优化。索引配置调优。索引配置优化主要包括,根据数据规模设置合理的主分片数,可以通过测试得到最适合的分片数。设置合理的副本数目,不是越多越好。
d、查询语句是否优化。查询语句调优。查询语句调优主要有以下几种常用手段。
1)、尽量使用Filter上下文,减少算分的场景,由于Filter有缓存机制,可以极大提升查询性能。
2)、尽量不适用Script进行字段计算或者算分排序等等。
3)、结合profile、expalin API分析慢查询语句的症结所在,然后再去优化数据模型。
7、X-Pack Monitoring,官方推出的免费集群监控功能。X-Pack Monitoring的安装,部署。
除了在Elasticsearch安装X-Pack以外,Elasticsearch6.7版本默认安装X-Pack,还要在Kibana安装X-Pack的(嗯,Kibana6.7版本默认安装X-Pack了)。如果没有默认安装的话,安装成功以后,分别重启Elasticsearch、Kibana。
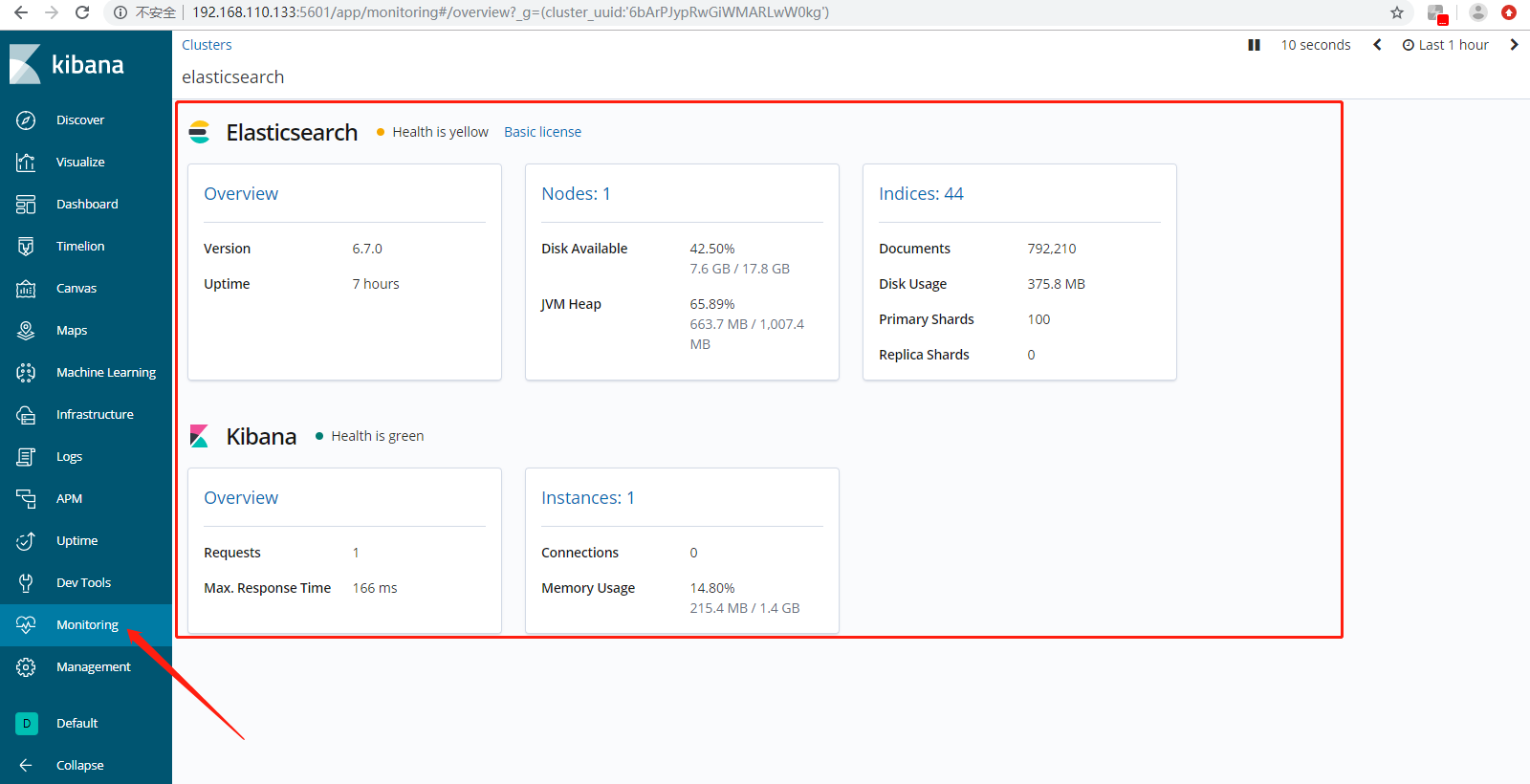
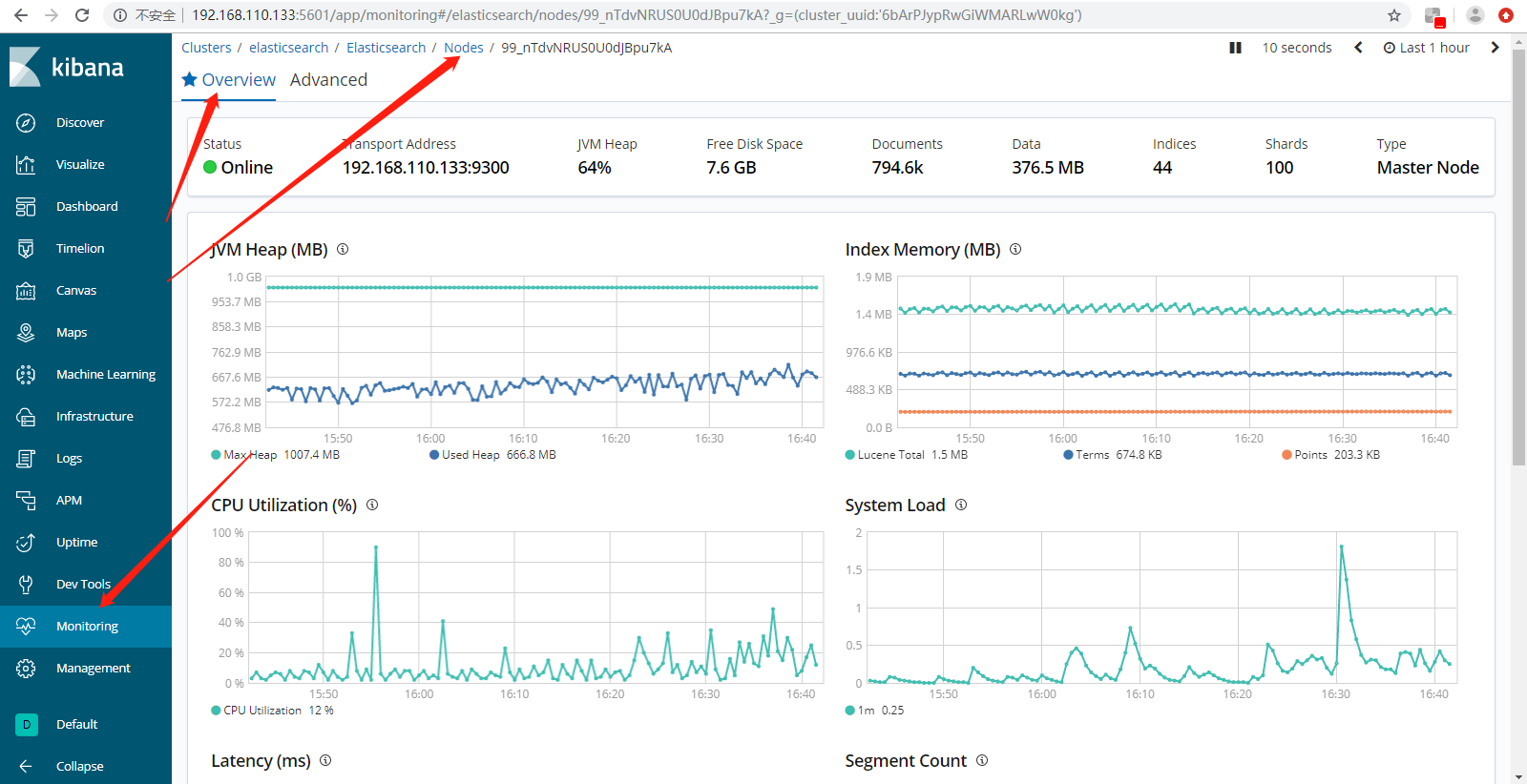
Overview,Search Rate是查询性能,Indexing Rate是写入性能,Search Latency查询延迟,Indexing Latency写入延迟。

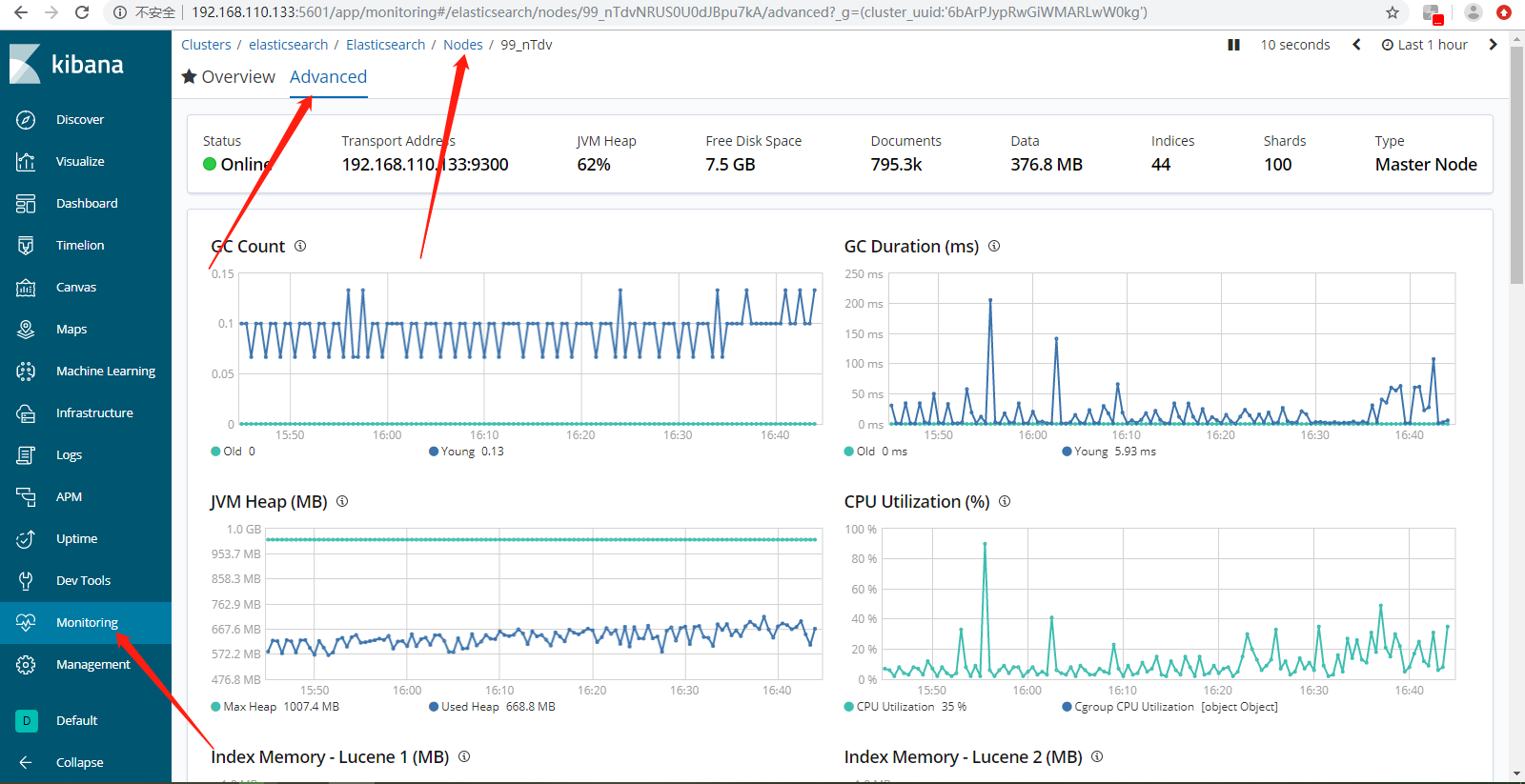
Node展示内存,磁盘,Cpu的指标信息。

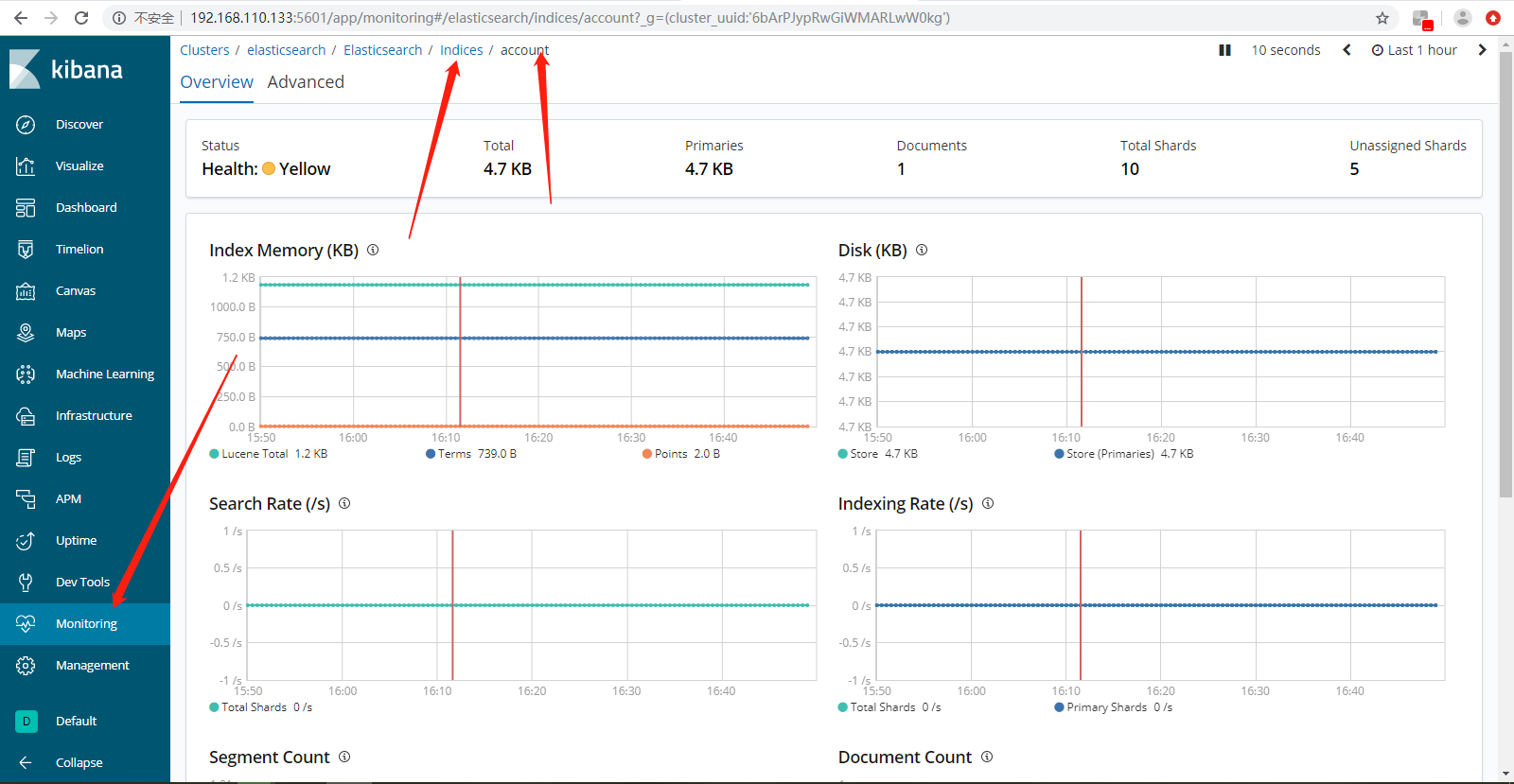
Indices索引级别查看数据。

X-Pack更多指标自己慢慢学习和查看吧。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
2018-11-13 主要是解决,作为一个数据共享的数据库,存在的数据库统计,然后将计算的数据量输出到自己使用的数据库,进行主页面展示。
2018-11-13 使用kettle来根据时间戳或者批次号来批量导入数据,达到增量的效果。
2018-11-13 使用java的Calendar工具类获取到本月的第一天起始时间和最后一天结束时间。
2017-11-13 关于yum网络版仓库(本地yum仓库的安装配置,如果没网了,做一个局域网内的yum仓库)
2016-11-13 Java Web应用的开发环境配置