
Elasticsearch 6.x版本全文检索学习之分布式特性介绍
1、Elasticsearch 6.x版本全文检索学习之分布式特性介绍。
1)、Elasticsearch支持集群默认,是一个分布式系统,其好处主要有两个。
a、增大系统容量,如内存、磁盘、使得es集群可以支持PB级别的数据。
b、提供系统可用性,即使部分节点停止服务,整个集群依然可以正常服务。
2)、Elasticsearch集群由多个es实例组成。
a、不同集群通过集群名字来区分,可以通过cluster.name进行修改,默认为elasticsearch。
b、每个es实例本质上是一个JVM进程,且有自己的名字,通过node.name进行修改。
2、cerebro的安装与运行。Github地址:https://github.com/lmenezes/cerebro。下载,安装,部署。
运行如下命令可以启动一个es节点实例,模版:./bin/elasticsearch -E cluster.name=my_cluster -E path.data=my_cluster_node1 -E node.name=node1 -E http.port=5200 -d

1 [root@slaver4 package]# wget https://github.com/lmenezes/cerebro/releases/download/v0.7.2/cerebro-0.7.2.tgz 2 --2019-11-01 09:20:22-- https://github.com/lmenezes/cerebro/releases/download/v0.7.2/cerebro-0.7.2.tgz 3 正在解析主机 github.com (github.com)... 13.250.177.223 4 正在连接 github.com (github.com)|13.250.177.223|:443... 已连接。 5 已发出 HTTP 请求,正在等待回应... 302 Found 6 位置:https://github-production-release-asset-2e65be.s3.amazonaws.com/54560347/a5bf160e-d454-11e7-849b-758511101a2f?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20191101%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20191101T012023Z&X-Amz-Expires=300&X-Amz-Signature=8b121e4e2a72d997441ebf78e2d8bea9deeeb322d1a3fbc676bc8398099b73a3&X-Amz-SignedHeaders=host&actor_id=0&response-content-disposition=attachment%3B%20filename%3Dcerebro-0.7.2.tgz&response-content-type=application%2Foctet-stream [跟随至新的 URL] 7 --2019-11-01 09:20:23-- https://github-production-release-asset-2e65be.s3.amazonaws.com/54560347/a5bf160e-d454-11e7-849b-758511101a2f?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20191101%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20191101T012023Z&X-Amz-Expires=300&X-Amz-Signature=8b121e4e2a72d997441ebf78e2d8bea9deeeb322d1a3fbc676bc8398099b73a3&X-Amz-SignedHeaders=host&actor_id=0&response-content-disposition=attachment%3B%20filename%3Dcerebro-0.7.2.tgz&response-content-type=application%2Foctet-stream 8 正在解析主机 github-production-release-asset-2e65be.s3.amazonaws.com (github-production-release-asset-2e65be.s3.amazonaws.com)... 52.216.130.123 9 正在连接 github-production-release-asset-2e65be.s3.amazonaws.com (github-production-release-asset-2e65be.s3.amazonaws.com)|52.216.130.123|:443... 已连接。 10 已发出 HTTP 请求,正在等待回应... 200 OK 11 长度:52121825 (50M) [application/octet-stream] 12 正在保存至: “cerebro-0.7.2.tgz” 13 14 100%[======================================================================================================================================================================================>] 52,121,825 1.34MB/s 用时 30s 15 16 2019-11-01 09:20:55 (1.65 MB/s) - 已保存 “cerebro-0.7.2.tgz” [52121825/52121825]) 17 18 [root@slaver4 package]# ls 19 cerebro-0.7.2.tgz elasticsearch-6.7.0.tar.gz erlang-solutions-1.0-1.noarch.rpm filebeat-6.7.0-linux-x86_64.tar.gz kibana-6.7.0-linux-x86_64.tar.gz logstash-6.7.0.tar.gz materials rabbitmq-server-3.5.1-1.noarch.rpm 20 [root@slaver4 package]# tar -zxvf cerebro-0.7.2.tgz -C /home/hadoop/soft/
将cerebro赋予新创建的elsearch用户,用户组。
1 [root@slaver4 package]# cd ../soft/ 2 [root@slaver4 soft]# ls 3 cerebro-0.7.2 elasticsearch-6.7.0 filebeat-6.7.0-linux-x86_64 kibana-6.7.0-linux-x86_64 logstash-6.7.0 4 [root@slaver4 soft]# chown elsearch:elsearch cerebro-0.7.2/ 5 [root@slaver4 soft]# su elsearch 6 [elsearch@slaver4 soft]$ ls 7 cerebro-0.7.2 elasticsearch-6.7.0 filebeat-6.7.0-linux-x86_64 kibana-6.7.0-linux-x86_64 logstash-6.7.0 8 [elsearch@slaver4 soft]$ ll 9 总用量 0 10 drwxr-xr-x. 5 elsearch elsearch 57 11月 28 2017 cerebro-0.7.2 11 drwxr-xr-x. 9 elsearch elsearch 155 10月 25 15:09 elasticsearch-6.7.0 12 drwxr-xr-x. 6 elsearch elsearch 252 10月 26 11:22 filebeat-6.7.0-linux-x86_64 13 drwxr-xr-x. 13 elsearch elsearch 246 10月 25 16:13 kibana-6.7.0-linux-x86_64 14 drwxr-xr-x. 12 elsearch elsearch 255 10月 26 14:37 logstash-6.7.0 15 [elsearch@slaver4 soft]$
安装了jvm即java就可以运行了。我启动报了如下错误,修改一下日志记录的路径。
1 [elsearch@slaver4 bin]$ ./cerebro 2 09:27:05,150 |-INFO in ch.qos.logback.classic.LoggerContext[default] - Could NOT find resource [logback.groovy] 3 09:27:05,151 |-INFO in ch.qos.logback.classic.LoggerContext[default] - Could NOT find resource [logback-test.xml] 4 09:27:05,151 |-INFO in ch.qos.logback.classic.LoggerContext[default] - Found resource [logback.xml] at [file:/home/hadoop/soft/cerebro-0.7.2/conf/logback.xml] 5 09:27:05,363 |-INFO in ch.qos.logback.classic.joran.action.ConfigurationAction - debug attribute not set 6 09:27:05,371 |-INFO in ch.qos.logback.core.joran.action.ConversionRuleAction - registering conversion word coloredLevel with class [play.api.libs.logback.ColoredLevel] 7 09:27:05,371 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - About to instantiate appender of type [ch.qos.logback.core.FileAppender] 8 09:27:05,381 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - Naming appender as [FILE] 9 09:27:05,393 |-INFO in ch.qos.logback.core.joran.action.NestedComplexPropertyIA - Assuming default type [ch.qos.logback.classic.encoder.PatternLayoutEncoder] for [encoder] property 10 09:27:05,427 |-INFO in ch.qos.logback.core.FileAppender[FILE] - File property is set to [./logs/application.log] 11 09:27:05,428 |-ERROR in ch.qos.logback.core.FileAppender[FILE] - Failed to create parent directories for [/home/hadoop/soft/cerebro-0.7.2/./logs/application.log] 12 09:27:05,429 |-ERROR in ch.qos.logback.core.FileAppender[FILE] - openFile(./logs/application.log,true) call failed. java.io.FileNotFoundException: ./logs/application.log (没有那个文件或目录) 13 at java.io.FileNotFoundException: ./logs/application.log (没有那个文件或目录) 14 at at java.io.FileOutputStream.open0(Native Method) 15 at at java.io.FileOutputStream.open(FileOutputStream.java:270) 16 at at java.io.FileOutputStream.<init>(FileOutputStream.java:213) 17 at at ch.qos.logback.core.recovery.ResilientFileOutputStream.<init>(ResilientFileOutputStream.java:26) 18 at at ch.qos.logback.core.FileAppender.openFile(FileAppender.java:186) 19 at at ch.qos.logback.core.FileAppender.start(FileAppender.java:121) 20 at at ch.qos.logback.core.joran.action.AppenderAction.end(AppenderAction.java:90) 21 at at ch.qos.logback.core.joran.spi.Interpreter.callEndAction(Interpreter.java:309) 22 at at ch.qos.logback.core.joran.spi.Interpreter.endElement(Interpreter.java:193) 23 at at ch.qos.logback.core.joran.spi.Interpreter.endElement(Interpreter.java:179) 24 at at ch.qos.logback.core.joran.spi.EventPlayer.play(EventPlayer.java:62) 25 at at ch.qos.logback.core.joran.GenericConfigurator.doConfigure(GenericConfigurator.java:155) 26 at at ch.qos.logback.core.joran.GenericConfigurator.doConfigure(GenericConfigurator.java:142) 27 at at ch.qos.logback.core.joran.GenericConfigurator.doConfigure(GenericConfigurator.java:103) 28 at at ch.qos.logback.core.joran.GenericConfigurator.doConfigure(GenericConfigurator.java:53) 29 at at ch.qos.logback.classic.util.ContextInitializer.configureByResource(ContextInitializer.java:75) 30 at at ch.qos.logback.classic.util.ContextInitializer.autoConfig(ContextInitializer.java:150) 31 at at org.slf4j.impl.StaticLoggerBinder.init(StaticLoggerBinder.java:84) 32 at at org.slf4j.impl.StaticLoggerBinder.<clinit>(StaticLoggerBinder.java:55) 33 at at play.api.libs.logback.LogbackLoggerConfigurator.configure(LogbackLoggerConfigurator.scala:80) 34 at at play.api.libs.logback.LogbackLoggerConfigurator.configure(LogbackLoggerConfigurator.scala:62) 35 at at play.api.inject.guice.GuiceApplicationBuilder$$anonfun$applicationModule$1.apply(GuiceApplicationBuilder.scala:102) 36 at at play.api.inject.guice.GuiceApplicationBuilder$$anonfun$applicationModule$1.apply(GuiceApplicationBuilder.scala:102) 37 at at scala.Option.foreach(Option.scala:257) 38 at at play.api.inject.guice.GuiceApplicationBuilder.applicationModule(GuiceApplicationBuilder.scala:101) 39 at at play.api.inject.guice.GuiceBuilder.injector(GuiceInjectorBuilder.scala:181) 40 at at play.api.inject.guice.GuiceApplicationBuilder.build(GuiceApplicationBuilder.scala:123) 41 at at play.api.inject.guice.GuiceApplicationLoader.load(GuiceApplicationLoader.scala:21) 42 at at play.core.server.ProdServerStart$.start(ProdServerStart.scala:47) 43 at at play.core.server.ProdServerStart$.main(ProdServerStart.scala:22) 44 at at play.core.server.ProdServerStart.main(ProdServerStart.scala) 45 09:27:05,429 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - About to instantiate appender of type [ch.qos.logback.core.ConsoleAppender] 46 09:27:05,431 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - Naming appender as [STDOUT] 47 09:27:05,431 |-INFO in ch.qos.logback.core.joran.action.NestedComplexPropertyIA - Assuming default type [ch.qos.logback.classic.encoder.PatternLayoutEncoder] for [encoder] property 48 09:27:05,439 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [play] to INFO 49 09:27:05,440 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [application] to INFO 50 09:27:05,440 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [com.avaje.ebean.config.PropertyMapLoader] to OFF 51 09:27:05,440 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [com.avaje.ebeaninternal.server.core.XmlConfigLoader] to OFF 52 09:27:05,440 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [com.avaje.ebeaninternal.server.lib.BackgroundThread] to OFF 53 09:27:05,440 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [com.gargoylesoftware.htmlunit.javascript] to OFF 54 09:27:05,440 |-INFO in ch.qos.logback.classic.joran.action.RootLoggerAction - Setting level of ROOT logger to ERROR 55 09:27:05,440 |-INFO in ch.qos.logback.core.joran.action.AppenderRefAction - Attaching appender named [STDOUT] to Logger[ROOT] 56 09:27:05,441 |-INFO in ch.qos.logback.core.joran.action.AppenderRefAction - Attaching appender named [FILE] to Logger[ROOT] 57 09:27:05,441 |-INFO in ch.qos.logback.classic.joran.action.ConfigurationAction - End of configuration. 58 09:27:05,442 |-INFO in ch.qos.logback.classic.joran.JoranConfigurator@53aac487 - Registering current configuration as safe fallback point 59 60 09:27:05,150 |-INFO in ch.qos.logback.classic.LoggerContext[default] - Could NOT find resource [logback.groovy] 61 09:27:05,151 |-INFO in ch.qos.logback.classic.LoggerContext[default] - Could NOT find resource [logback-test.xml] 62 09:27:05,151 |-INFO in ch.qos.logback.classic.LoggerContext[default] - Found resource [logback.xml] at [file:/home/hadoop/soft/cerebro-0.7.2/conf/logback.xml] 63 09:27:05,363 |-INFO in ch.qos.logback.classic.joran.action.ConfigurationAction - debug attribute not set 64 09:27:05,371 |-INFO in ch.qos.logback.core.joran.action.ConversionRuleAction - registering conversion word coloredLevel with class [play.api.libs.logback.ColoredLevel] 65 09:27:05,371 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - About to instantiate appender of type [ch.qos.logback.core.FileAppender] 66 09:27:05,381 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - Naming appender as [FILE] 67 09:27:05,393 |-INFO in ch.qos.logback.core.joran.action.NestedComplexPropertyIA - Assuming default type [ch.qos.logback.classic.encoder.PatternLayoutEncoder] for [encoder] property 68 09:27:05,427 |-INFO in ch.qos.logback.core.FileAppender[FILE] - File property is set to [./logs/application.log] 69 09:27:05,428 |-ERROR in ch.qos.logback.core.FileAppender[FILE] - Failed to create parent directories for [/home/hadoop/soft/cerebro-0.7.2/./logs/application.log] 70 09:27:05,429 |-ERROR in ch.qos.logback.core.FileAppender[FILE] - openFile(./logs/application.log,true) call failed. java.io.FileNotFoundException: ./logs/application.log (没有那个文件或目录) 71 at java.io.FileNotFoundException: ./logs/application.log (没有那个文件或目录) 72 at at java.io.FileOutputStream.open0(Native Method) 73 at at java.io.FileOutputStream.open(FileOutputStream.java:270) 74 at at java.io.FileOutputStream.<init>(FileOutputStream.java:213) 75 at at ch.qos.logback.core.recovery.ResilientFileOutputStream.<init>(ResilientFileOutputStream.java:26) 76 at at ch.qos.logback.core.FileAppender.openFile(FileAppender.java:186) 77 at at ch.qos.logback.core.FileAppender.start(FileAppender.java:121) 78 at at ch.qos.logback.core.joran.action.AppenderAction.end(AppenderAction.java:90) 79 at at ch.qos.logback.core.joran.spi.Interpreter.callEndAction(Interpreter.java:309) 80 at at ch.qos.logback.core.joran.spi.Interpreter.endElement(Interpreter.java:193) 81 at at ch.qos.logback.core.joran.spi.Interpreter.endElement(Interpreter.java:179) 82 at at ch.qos.logback.core.joran.spi.EventPlayer.play(EventPlayer.java:62) 83 at at ch.qos.logback.core.joran.GenericConfigurator.doConfigure(GenericConfigurator.java:155) 84 at at ch.qos.logback.core.joran.GenericConfigurator.doConfigure(GenericConfigurator.java:142) 85 at at ch.qos.logback.core.joran.GenericConfigurator.doConfigure(GenericConfigurator.java:103) 86 at at ch.qos.logback.core.joran.GenericConfigurator.doConfigure(GenericConfigurator.java:53) 87 at at ch.qos.logback.classic.util.ContextInitializer.configureByResource(ContextInitializer.java:75) 88 at at ch.qos.logback.classic.util.ContextInitializer.autoConfig(ContextInitializer.java:150) 89 at at org.slf4j.impl.StaticLoggerBinder.init(StaticLoggerBinder.java:84) 90 at at org.slf4j.impl.StaticLoggerBinder.<clinit>(StaticLoggerBinder.java:55) 91 at at play.api.libs.logback.LogbackLoggerConfigurator.configure(LogbackLoggerConfigurator.scala:80) 92 at at play.api.libs.logback.LogbackLoggerConfigurator.configure(LogbackLoggerConfigurator.scala:62) 93 at at play.api.inject.guice.GuiceApplicationBuilder$$anonfun$applicationModule$1.apply(GuiceApplicationBuilder.scala:102) 94 at at play.api.inject.guice.GuiceApplicationBuilder$$anonfun$applicationModule$1.apply(GuiceApplicationBuilder.scala:102) 95 at at scala.Option.foreach(Option.scala:257) 96 at at play.api.inject.guice.GuiceApplicationBuilder.applicationModule(GuiceApplicationBuilder.scala:101) 97 at at play.api.inject.guice.GuiceBuilder.injector(GuiceInjectorBuilder.scala:181) 98 at at play.api.inject.guice.GuiceApplicationBuilder.build(GuiceApplicationBuilder.scala:123) 99 at at play.api.inject.guice.GuiceApplicationLoader.load(GuiceApplicationLoader.scala:21) 100 at at play.core.server.ProdServerStart$.start(ProdServerStart.scala:47) 101 at at play.core.server.ProdServerStart$.main(ProdServerStart.scala:22) 102 at at play.core.server.ProdServerStart.main(ProdServerStart.scala) 103 09:27:05,429 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - About to instantiate appender of type [ch.qos.logback.core.ConsoleAppender] 104 09:27:05,431 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - Naming appender as [STDOUT] 105 09:27:05,431 |-INFO in ch.qos.logback.core.joran.action.NestedComplexPropertyIA - Assuming default type [ch.qos.logback.classic.encoder.PatternLayoutEncoder] for [encoder] property 106 09:27:05,439 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [play] to INFO 107 09:27:05,440 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [application] to INFO 108 09:27:05,440 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [com.avaje.ebean.config.PropertyMapLoader] to OFF 109 09:27:05,440 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [com.avaje.ebeaninternal.server.core.XmlConfigLoader] to OFF 110 09:27:05,440 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [com.avaje.ebeaninternal.server.lib.BackgroundThread] to OFF 111 09:27:05,440 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [com.gargoylesoftware.htmlunit.javascript] to OFF 112 09:27:05,440 |-INFO in ch.qos.logback.classic.joran.action.RootLoggerAction - Setting level of ROOT logger to ERROR 113 09:27:05,440 |-INFO in ch.qos.logback.core.joran.action.AppenderRefAction - Attaching appender named [STDOUT] to Logger[ROOT] 114 09:27:05,441 |-INFO in ch.qos.logback.core.joran.action.AppenderRefAction - Attaching appender named [FILE] to Logger[ROOT] 115 09:27:05,441 |-INFO in ch.qos.logback.classic.joran.action.ConfigurationAction - End of configuration. 116 09:27:05,442 |-INFO in ch.qos.logback.classic.joran.JoranConfigurator@53aac487 - Registering current configuration as safe fallback point 117 09:27:05,457 |-INFO in ch.qos.logback.classic.joran.action.ConfigurationAction - debug attribute not set 118 09:27:05,457 |-INFO in ch.qos.logback.core.joran.action.ConversionRuleAction - registering conversion word coloredLevel with class [play.api.libs.logback.ColoredLevel] 119 09:27:05,457 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - About to instantiate appender of type [ch.qos.logback.core.FileAppender] 120 09:27:05,457 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - Naming appender as [FILE] 121 09:27:05,458 |-INFO in ch.qos.logback.core.joran.action.NestedComplexPropertyIA - Assuming default type [ch.qos.logback.classic.encoder.PatternLayoutEncoder] for [encoder] property 122 09:27:05,459 |-INFO in ch.qos.logback.core.FileAppender[FILE] - File property is set to [/home/hadoop/soft/cerebro-0.7.2/logs/application.log] 123 09:27:05,459 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - About to instantiate appender of type [ch.qos.logback.core.ConsoleAppender] 124 09:27:05,459 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - Naming appender as [STDOUT] 125 09:27:05,461 |-INFO in ch.qos.logback.core.joran.action.NestedComplexPropertyIA - Assuming default type [ch.qos.logback.classic.encoder.PatternLayoutEncoder] for [encoder] property 126 09:27:05,473 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [play] to INFO 127 09:27:05,474 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [application] to INFO 128 09:27:05,474 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [com.avaje.ebean.config.PropertyMapLoader] to OFF 129 09:27:05,474 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [com.avaje.ebeaninternal.server.core.XmlConfigLoader] to OFF 130 09:27:05,474 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [com.avaje.ebeaninternal.server.lib.BackgroundThread] to OFF 131 09:27:05,474 |-INFO in ch.qos.logback.classic.joran.action.LoggerAction - Setting level of logger [com.gargoylesoftware.htmlunit.javascript] to OFF 132 09:27:05,474 |-INFO in ch.qos.logback.classic.joran.action.RootLoggerAction - Setting level of ROOT logger to ERROR 133 09:27:05,474 |-INFO in ch.qos.logback.core.joran.action.AppenderRefAction - Attaching appender named [STDOUT] to Logger[ROOT] 134 09:27:05,474 |-INFO in ch.qos.logback.core.joran.action.AppenderRefAction - Attaching appender named [FILE] to Logger[ROOT] 135 09:27:05,474 |-INFO in ch.qos.logback.classic.joran.action.ConfigurationAction - End of configuration. 136 09:27:05,474 |-INFO in ch.qos.logback.classic.joran.JoranConfigurator@534a5a98 - Registering current configuration as safe fallback point 137 138 [info] play.api.Play - Application started (Prod) 139 [info] p.c.s.NettyServer - Listening for HTTP on /0:0:0:0:0:0:0:0:9000
修改vim logback.xml,这个配置文件,<file>/home/hadoop/soft/cerebro-0.7.2/logs/application.log</file>,配置成自己的日志文件路径即可。
1 <configuration> 2 3 <conversionRule conversionWord="coloredLevel" converterClass="play.api.libs.logback.ColoredLevel"/> 4 5 <appender name="FILE" class="ch.qos.logback.core.FileAppender"> 6 <file>/home/hadoop/soft/cerebro-0.7.2/logs/application.log</file> 7 <encoder> 8 <pattern>%date - [%level] - from %logger in %thread %n%message%n%xException%n</pattern> 9 </encoder> 10 </appender> 11 12 <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> 13 <encoder> 14 <pattern>%coloredLevel %logger{15} - %message%n%xException{5}</pattern> 15 </encoder> 16 </appender> 17 18 <logger name="play" level="INFO"/> 19 <logger name="application" level="INFO"/> 20 21 <!-- Off these ones as they are annoying, and anyway we manage configuration ourself --> 22 <logger name="com.avaje.ebean.config.PropertyMapLoader" level="OFF"/> 23 <logger name="com.avaje.ebeaninternal.server.core.XmlConfigLoader" level="OFF"/> 24 <logger name="com.avaje.ebeaninternal.server.lib.BackgroundThread" level="OFF"/> 25 <logger name="com.gargoylesoftware.htmlunit.javascript" level="OFF"/> 26 27 <root level="ERROR"> 28 <appender-ref ref="STDOUT"/> 29 <appender-ref ref="FILE"/> 30 </root> 31 32 </configuration>
重新启动,如下所示:
1 [root@slaver4 bin]$ ./cerebro 2 [info] play.api.Play - Application started (Prod) 3 [info] p.c.s.NettyServer - Listening for HTTP on /0:0:0:0:0:0:0:0:9000
现在启动你的Elasticseach。访问地址http://192.168.110.133:9000,界面如下所示:
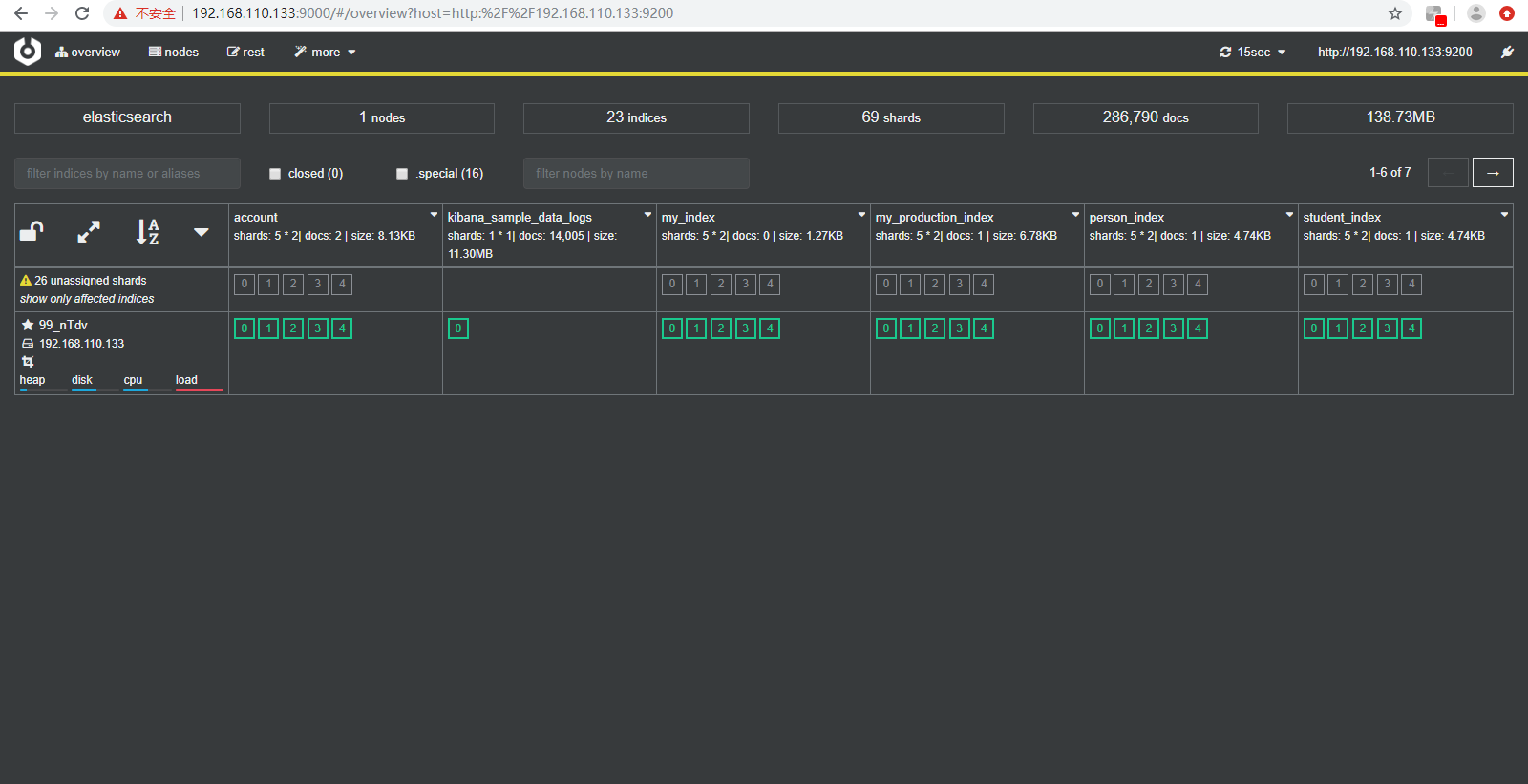
连上如下所示:
3、Elasticsearch快速构建集群。指定集群名称cluster.name、path.data的名称、node.name的名称、http.port端口号。最后的-d参数在后台运行。
1 [elsearch@slaver4 bin]$ ./elasticsearch -Ecluster.name=my_cluster -Epath.data=my_cluster_node1 -Enode.name=node1 -Ehttp.port=5200 -d 2 OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N 3 [elsearch@slaver4 bin]$
4、Cluster state,集群状态。
答:1)、Elasticsearch集群相关的数据称为cluster state,主要记录如下信息。cluster state有版本控制的,创建索引以后,版本更新。
2)、节点信息,比如节点名称、连接地址等等。
3)、索引信息,比如索引名称、配置等等。
4)、实心五角星代表的是主节点、圆代表的是Coordinating节点、方框代表的是data节点。
5、Master Node,集群主节点。
答:1)、可以修改cluster state的节点称为master节点,一个集群只能有一个。
2)、cluster state存储在每个节点上,master维护最新版本并同步给其他节点。
3)、master节点是通过集群中所有节点选举产生的,可以被选举的节点称为master-eligible节点,相关配置如下所示:node.master:true。
6、Coordinating Node,处理请求节点。
答:1)、处理请求的节点即为coordinating节点,该节点为所有节点的默认角色,不能取消。
2)、路由请求到正确的节点处理,比如创建索引的请求到master节点。
7、Data Node,存储数据的节点。
答:存储数据的节点即为data节点,默认节点都是data类型,相关配置如下。node.data:true。
8、解决单点问题,如果单节点,一个节点挂了,集群停止服务,可以通过新增节点保障集群健壮性,运行如下命令,可以启动一个es节点实例。启动多个节点依次类推。
./elasticsearch -Ecluster.name=my_cluster -Epath.data=my_cluster_node2 -Enode.name=node2 -Ehttp.port=5300 -d。
1 [root@slaver4 ~]# su elsearch 2 [elsearch@slaver4 root]$ cd /home/hadoop/soft/ 3 [elsearch@slaver4 soft]$ ls 4 cerebro-0.7.2 elasticsearch-6.7.0 filebeat-6.7.0-linux-x86_64 kibana-6.7.0-linux-x86_64 logstash-6.7.0 5 [elsearch@slaver4 soft]$ cd elasticsearch-6.7.0/ 6 [elsearch@slaver4 elasticsearch-6.7.0]$ ls 7 bin config data lib LICENSE.txt logs modules my_cluster_node1 NOTICE.txt plugins README.textile 8 [elsearch@slaver4 elasticsearch-6.7.0]$ cd bin/ 9 [elsearch@slaver4 bin]$ ./elasticsearch -Ecluster.name=my_cluster -Epath.data=my_cluster_node2 -Enode.name=node2 -Ehttp.port=5300 -d 10 OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N 11 [elsearch@slaver4 bin]$ ./elasticsearch -Ecluster.name=my_cluster -Epath.data=my_cluster_node1 -Enode.name=node1 -Ehttp.port=5200 -d 12 OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N 13 [elsearch@slaver4 bin]$
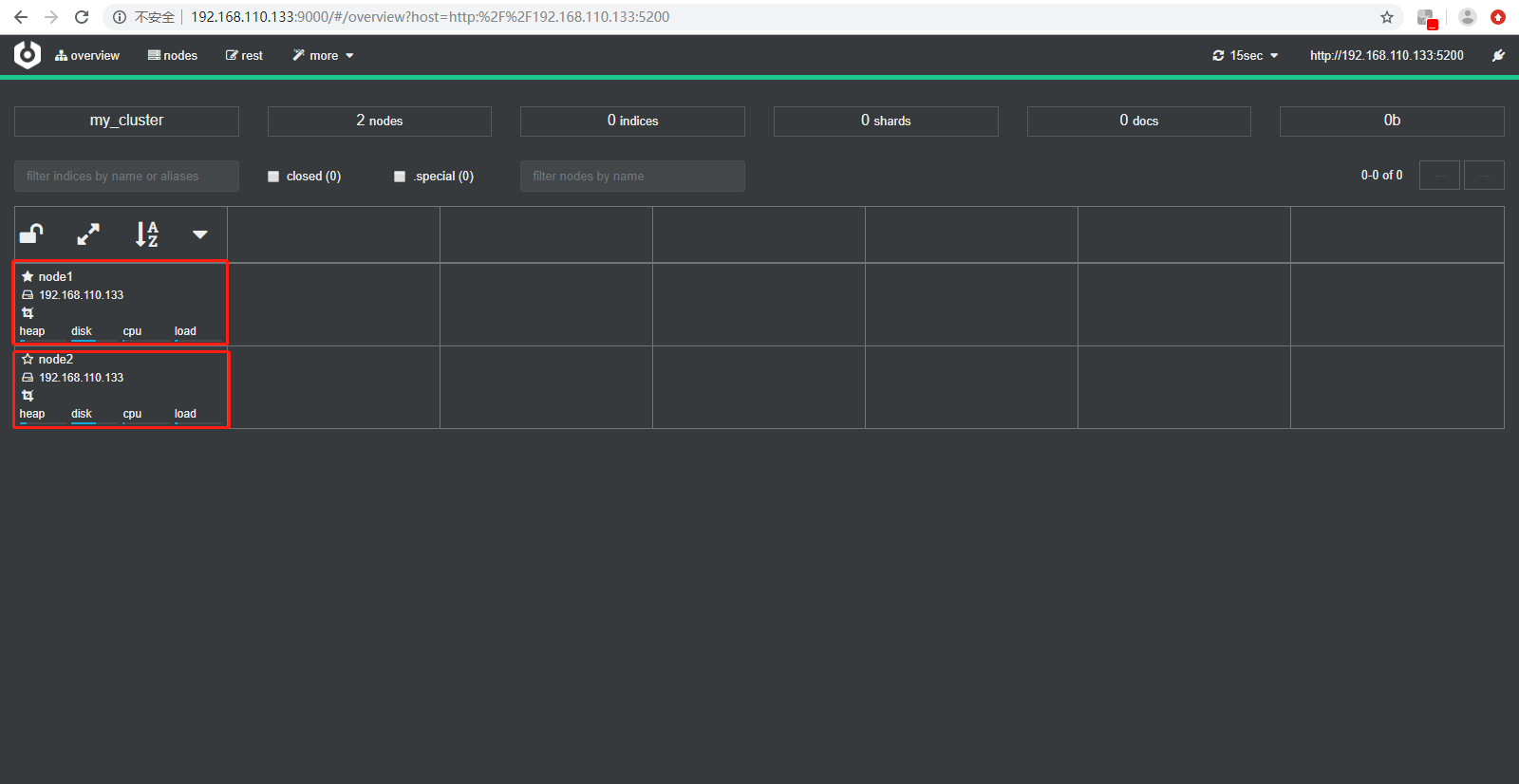
如果使用的是虚拟机,一定要将此配置修改为这样,不然你是将节点加不到一个集群里面的。
[elsearch@slaver4 config]$ vim elasticsearch.yml
1 network.host: 0.0.0.0
将network.host确实解决了加入不到集群的问题,效果如下所示:
如果报下面的错误,就是端口号占用了,换一个端口号即可,如下所示:
1 [elsearch@slaver1 elasticsearch-6.7.0]$ ./bin/elasticsearch -E cluster.name=el_cluster -E path.data=el_cluster_node2 -E node.name=node2 -E http.port=9300 2 [2021-01-18T15:16:23,069][INFO ][o.e.e.NodeEnvironment ] [node2] using [1] data paths, mounts [[/ (rootfs)]], net usable_space [2.1gb], net total_space [17.7gb], types [rootfs] 3 [2021-01-18T15:16:23,076][INFO ][o.e.e.NodeEnvironment ] [node2] heap size [1007.3mb], compressed ordinary object pointers [true] 4 [2021-01-18T15:16:23,106][INFO ][o.e.n.Node ] [node2] node name [node2], node ID [8yrGpCKuSkSStJi6YxeeiA] 5 [2021-01-18T15:16:23,106][INFO ][o.e.n.Node ] [node2] version[6.7.0], pid[11992], build[default/tar/8453f77/2019-03-21T15:32:29.844721Z], OS[Linux/3.10.0-957.el7.x86_64/amd64], JVM[Oracle Corporation/OpenJDK 64-Bit Server VM/1.8.0_252/25.252-b09] 6 [2021-01-18T15:16:23,107][INFO ][o.e.n.Node ] [node2] JVM arguments [-Xms1g, -Xmx1g, -XX:+UseConcMarkSweepGC, -XX:CMSInitiatingOccupancyFraction=75, -XX:+UseCMSInitiatingOccupancyOnly, -Des.networkaddress.cache.ttl=60, -Des.networkaddress.cache.negative.ttl=10, -XX:+AlwaysPreTouch, -Xss1m, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -XX:-OmitStackTraceInFastThrow, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.netty.recycler.maxCapacityPerThread=0, -Dlog4j.shutdownHookEnabled=false, -Dlog4j2.disable.jmx=true, -Djava.io.tmpdir=/tmp/elasticsearch-1646055356750119515, -XX:+HeapDumpOnOutOfMemoryError, -XX:HeapDumpPath=data, -XX:ErrorFile=logs/hs_err_pid%p.log, -XX:+PrintGCDetails, -XX:+PrintGCDateStamps, -XX:+PrintTenuringDistribution, -XX:+PrintGCApplicationStoppedTime, -Xloggc:logs/gc.log, -XX:+UseGCLogFileRotation, -XX:NumberOfGCLogFiles=32, -XX:GCLogFileSize=64m, -Des.path.home=/home/hadoop/soft/elasticsearch-6.7.0, -Des.path.conf=/home/hadoop/soft/elasticsearch-6.7.0/config, -Des.distribution.flavor=default, -Des.distribution.type=tar] 7 [2021-01-18T15:16:27,041][INFO ][o.e.p.PluginsService ] [node2] loaded module [aggs-matrix-stats] 8 [2021-01-18T15:16:27,041][INFO ][o.e.p.PluginsService ] [node2] loaded module [analysis-common] 9 [2021-01-18T15:16:27,042][INFO ][o.e.p.PluginsService ] [node2] loaded module [ingest-common] 10 [2021-01-18T15:16:27,042][INFO ][o.e.p.PluginsService ] [node2] loaded module [ingest-geoip] 11 [2021-01-18T15:16:27,042][INFO ][o.e.p.PluginsService ] [node2] loaded module [ingest-user-agent] 12 [2021-01-18T15:16:27,042][INFO ][o.e.p.PluginsService ] [node2] loaded module [lang-expression] 13 [2021-01-18T15:16:27,042][INFO ][o.e.p.PluginsService ] [node2] loaded module [lang-mustache] 14 [2021-01-18T15:16:27,042][INFO ][o.e.p.PluginsService ] [node2] loaded module [lang-painless] 15 [2021-01-18T15:16:27,043][INFO ][o.e.p.PluginsService ] [node2] loaded module [mapper-extras] 16 [2021-01-18T15:16:27,043][INFO ][o.e.p.PluginsService ] [node2] loaded module [parent-join] 17 [2021-01-18T15:16:27,043][INFO ][o.e.p.PluginsService ] [node2] loaded module [percolator] 18 [2021-01-18T15:16:27,043][INFO ][o.e.p.PluginsService ] [node2] loaded module [rank-eval] 19 [2021-01-18T15:16:27,043][INFO ][o.e.p.PluginsService ] [node2] loaded module [reindex] 20 [2021-01-18T15:16:27,044][INFO ][o.e.p.PluginsService ] [node2] loaded module [repository-url] 21 [2021-01-18T15:16:27,044][INFO ][o.e.p.PluginsService ] [node2] loaded module [transport-netty4] 22 [2021-01-18T15:16:27,044][INFO ][o.e.p.PluginsService ] [node2] loaded module [tribe] 23 [2021-01-18T15:16:27,044][INFO ][o.e.p.PluginsService ] [node2] loaded module [x-pack-ccr] 24 [2021-01-18T15:16:27,045][INFO ][o.e.p.PluginsService ] [node2] loaded module [x-pack-core] 25 [2021-01-18T15:16:27,045][INFO ][o.e.p.PluginsService ] [node2] loaded module [x-pack-deprecation] 26 [2021-01-18T15:16:27,045][INFO ][o.e.p.PluginsService ] [node2] loaded module [x-pack-graph] 27 [2021-01-18T15:16:27,045][INFO ][o.e.p.PluginsService ] [node2] loaded module [x-pack-ilm] 28 [2021-01-18T15:16:27,045][INFO ][o.e.p.PluginsService ] [node2] loaded module [x-pack-logstash] 29 [2021-01-18T15:16:27,045][INFO ][o.e.p.PluginsService ] [node2] loaded module [x-pack-ml] 30 [2021-01-18T15:16:27,045][INFO ][o.e.p.PluginsService ] [node2] loaded module [x-pack-monitoring] 31 [2021-01-18T15:16:27,046][INFO ][o.e.p.PluginsService ] [node2] loaded module [x-pack-rollup] 32 [2021-01-18T15:16:27,046][INFO ][o.e.p.PluginsService ] [node2] loaded module [x-pack-security] 33 [2021-01-18T15:16:27,046][INFO ][o.e.p.PluginsService ] [node2] loaded module [x-pack-sql] 34 [2021-01-18T15:16:27,046][INFO ][o.e.p.PluginsService ] [node2] loaded module [x-pack-upgrade] 35 [2021-01-18T15:16:27,046][INFO ][o.e.p.PluginsService ] [node2] loaded module [x-pack-watcher] 36 [2021-01-18T15:16:27,047][INFO ][o.e.p.PluginsService ] [node2] no plugins loaded 37 [2021-01-18T15:16:35,766][INFO ][o.e.x.s.a.s.FileRolesStore] [node2] parsed [0] roles from file [/home/hadoop/soft/elasticsearch-6.7.0/config/roles.yml] 38 [2021-01-18T15:16:37,703][INFO ][o.e.x.m.p.l.CppLogMessageHandler] [node2] [controller/12054] [Main.cc@109] controller (64 bit): Version 6.7.0 (Build d74ae2ac01b10d) Copyright (c) 2019 Elasticsearch BV 39 [2021-01-18T15:16:38,687][DEBUG][o.e.a.ActionModule ] [node2] Using REST wrapper from plugin org.elasticsearch.xpack.security.Security 40 [2021-01-18T15:16:39,237][INFO ][o.e.d.DiscoveryModule ] [node2] using discovery type [zen] and host providers [settings] 41 [2021-01-18T15:16:40,963][INFO ][o.e.n.Node ] [node2] initialized 42 [2021-01-18T15:16:40,964][INFO ][o.e.n.Node ] [node2] starting ... 43 [2021-01-18T15:16:41,323][INFO ][o.e.t.TransportService ] [node2] publish_address {192.168.110.133:9301}, bound_addresses {[::]:9301} 44 [2021-01-18T15:16:41,389][INFO ][o.e.b.BootstrapChecks ] [node2] bound or publishing to a non-loopback address, enforcing bootstrap checks 45 [2021-01-18T15:16:44,951][INFO ][o.e.c.s.ClusterApplierService] [node2] detected_master {node1}{D4bdInIuSaCrabcHbvOrUg}{05AelwewTxGAH2GyqfWvBg}{192.168.110.133}{192.168.110.133:9300}{ml.machine_memory=5703213056, ml.max_open_jobs=20, xpack.installed=true, ml.enabled=true}, added {{node1}{D4bdInIuSaCrabcHbvOrUg}{05AelwewTxGAH2GyqfWvBg}{192.168.110.133}{192.168.110.133:9300}{ml.machine_memory=5703213056, ml.max_open_jobs=20, xpack.installed=true, ml.enabled=true},}, reason: apply cluster state (from master [master {node1}{D4bdInIuSaCrabcHbvOrUg}{05AelwewTxGAH2GyqfWvBg}{192.168.110.133}{192.168.110.133:9300}{ml.machine_memory=5703213056, ml.max_open_jobs=20, xpack.installed=true, ml.enabled=true} committed version [10]]) 46 [2021-01-18T15:16:45,333][WARN ][o.e.x.s.a.s.m.NativeRoleMappingStore] [node2] Failed to clear cache for realms [[]] 47 [2021-01-18T15:16:45,351][INFO ][o.e.x.s.a.TokenService ] [node2] refresh keys 48 [2021-01-18T15:16:45,746][INFO ][o.e.x.s.a.TokenService ] [node2] refreshed keys 49 [2021-01-18T15:16:45,857][INFO ][o.e.l.LicenseService ] [node2] license [8e1ea613-54a5-4ee9-8d5d-30b02f882630] mode [basic] - valid 50 [2021-01-18T15:16:45,987][WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] [node2] uncaught exception in thread [main] 51 org.elasticsearch.bootstrap.StartupException: BindHttpException[Failed to bind to [9300]]; nested: BindException[地址已在使用]; 52 at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:163) ~[elasticsearch-6.7.0.jar:6.7.0] 53 at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:150) ~[elasticsearch-6.7.0.jar:6.7.0] 54 at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86) ~[elasticsearch-6.7.0.jar:6.7.0] 55 at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:124) ~[elasticsearch-cli-6.7.0.jar:6.7.0] 56 at org.elasticsearch.cli.Command.main(Command.java:90) ~[elasticsearch-cli-6.7.0.jar:6.7.0] 57 at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:116) ~[elasticsearch-6.7.0.jar:6.7.0] 58 at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:93) ~[elasticsearch-6.7.0.jar:6.7.0] 59 Caused by: org.elasticsearch.http.BindHttpException: Failed to bind to [9300] 60 at org.elasticsearch.http.netty4.Netty4HttpServerTransport.bindAddress(Netty4HttpServerTransport.java:487) ~[?:?] 61 at org.elasticsearch.http.netty4.Netty4HttpServerTransport.createBoundHttpAddress(Netty4HttpServerTransport.java:384) ~[?:?] 62 at org.elasticsearch.http.netty4.Netty4HttpServerTransport.doStart(Netty4HttpServerTransport.java:361) ~[?:?] 63 at org.elasticsearch.xpack.security.transport.netty4.SecurityNetty4HttpServerTransport.doStart(SecurityNetty4HttpServerTransport.java:97) ~[?:?] 64 at org.elasticsearch.common.component.AbstractLifecycleComponent.start(AbstractLifecycleComponent.java:72) ~[elasticsearch-6.7.0.jar:6.7.0] 65 at org.elasticsearch.node.Node.start(Node.java:809) ~[elasticsearch-6.7.0.jar:6.7.0] 66 at org.elasticsearch.bootstrap.Bootstrap.start(Bootstrap.java:269) ~[elasticsearch-6.7.0.jar:6.7.0] 67 at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:342) ~[elasticsearch-6.7.0.jar:6.7.0] 68 at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:159) ~[elasticsearch-6.7.0.jar:6.7.0] 69 ... 6 more 70 Caused by: java.net.BindException: 地址已在使用 71 at sun.nio.ch.Net.bind0(Native Method) ~[?:?] 72 at sun.nio.ch.Net.bind(Net.java:433) ~[?:?] 73 at sun.nio.ch.Net.bind(Net.java:425) ~[?:?] 74 at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:220) ~[?:?] 75 at io.netty.channel.socket.nio.NioServerSocketChannel.doBind(NioServerSocketChannel.java:130) ~[?:?] 76 at io.netty.channel.AbstractChannel$AbstractUnsafe.bind(AbstractChannel.java:562) ~[?:?] 77 at io.netty.channel.DefaultChannelPipeline$HeadContext.bind(DefaultChannelPipeline.java:1358) ~[?:?] 78 at io.netty.channel.AbstractChannelHandlerContext.invokeBind(AbstractChannelHandlerContext.java:501) ~[?:?] 79 at io.netty.channel.AbstractChannelHandlerContext.bind(AbstractChannelHandlerContext.java:486) ~[?:?] 80 at io.netty.channel.DefaultChannelPipeline.bind(DefaultChannelPipeline.java:1019) ~[?:?] 81 at io.netty.channel.AbstractChannel.bind(AbstractChannel.java:258) ~[?:?] 82 at io.netty.bootstrap.AbstractBootstrap$2.run(AbstractBootstrap.java:366) ~[?:?] 83 at io.netty.util.concurrent.AbstractEventExecutor.safeExecute(AbstractEventExecutor.java:163) ~[?:?] 84 at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:404) ~[?:?] 85 at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:474) ~[?:?] 86 at io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:909) ~[?:?] 87 at java.lang.Thread.run(Thread.java:748) [?:1.8.0_252] 88 [2021-01-18T15:16:45,996][INFO ][o.e.n.Node ] [node2] stopping ... 89 [2021-01-18T15:16:46,056][INFO ][o.e.x.w.WatcherService ] [node2] stopping watch service, reason [shutdown initiated] 90 [2021-01-18T15:16:46,183][INFO ][o.e.x.m.p.l.CppLogMessageHandler] [node2] [controller/12054] [Main.cc@148] Ml controller exiting 91 [2021-01-18T15:16:46,184][INFO ][o.e.x.m.p.NativeController] [node2] Native controller process has stopped - no new native processes can be started 92 [2021-01-18T15:16:46,221][INFO ][o.e.n.Node ] [node2] stopped 93 [2021-01-18T15:16:46,221][INFO ][o.e.n.Node ] [node2] closing ... 94 [2021-01-18T15:16:46,245][INFO ][o.e.n.Node ] [node2] closed
9、提供elasticsearch系统可用性。
答:1)、服务可用性,比如,在2个节点的情况下,允许其中1个节点停止服务,此集群还可以对外提供服务。
2)、数据可用性,即便一个节点挂掉之后,数据还是完整的。
a、es引入副本(Replication)的概念解决此问题,即每个节点都具有完备的数据,此时,即便一个节点挂掉,在其他节点依然可以获取这个数据的完整内容。
b、每个节点上都有完备的数据,一个节点具备另外一个节点的副本数据。
10、elasticsearch的副本和分片,创建索引的时候,可以指定分片数量、副本的数量(副本的数量是相对分片来说的,指定分片之后,就可以指定该分片的副本数量了!)。
答:1)、如何将数据分布到所有节点上,elasticsearch引入分片(Shard)解决问题,可以将数据分配到es的不同节点上。
2)、分片是ES支持PB级数据的基石,特点:
a、分片存储了部分数据,可以分布于任意节点上。
b、分片数在索引创建时指定且后续不允许再更改,默认为5个。
c、分片有主分片和副本分片之分,副本分片,可以实现数据的高可用。
d、副本分片的数据由主分片同步,可以有多个副本分片,从而提高读取的吞吐量。
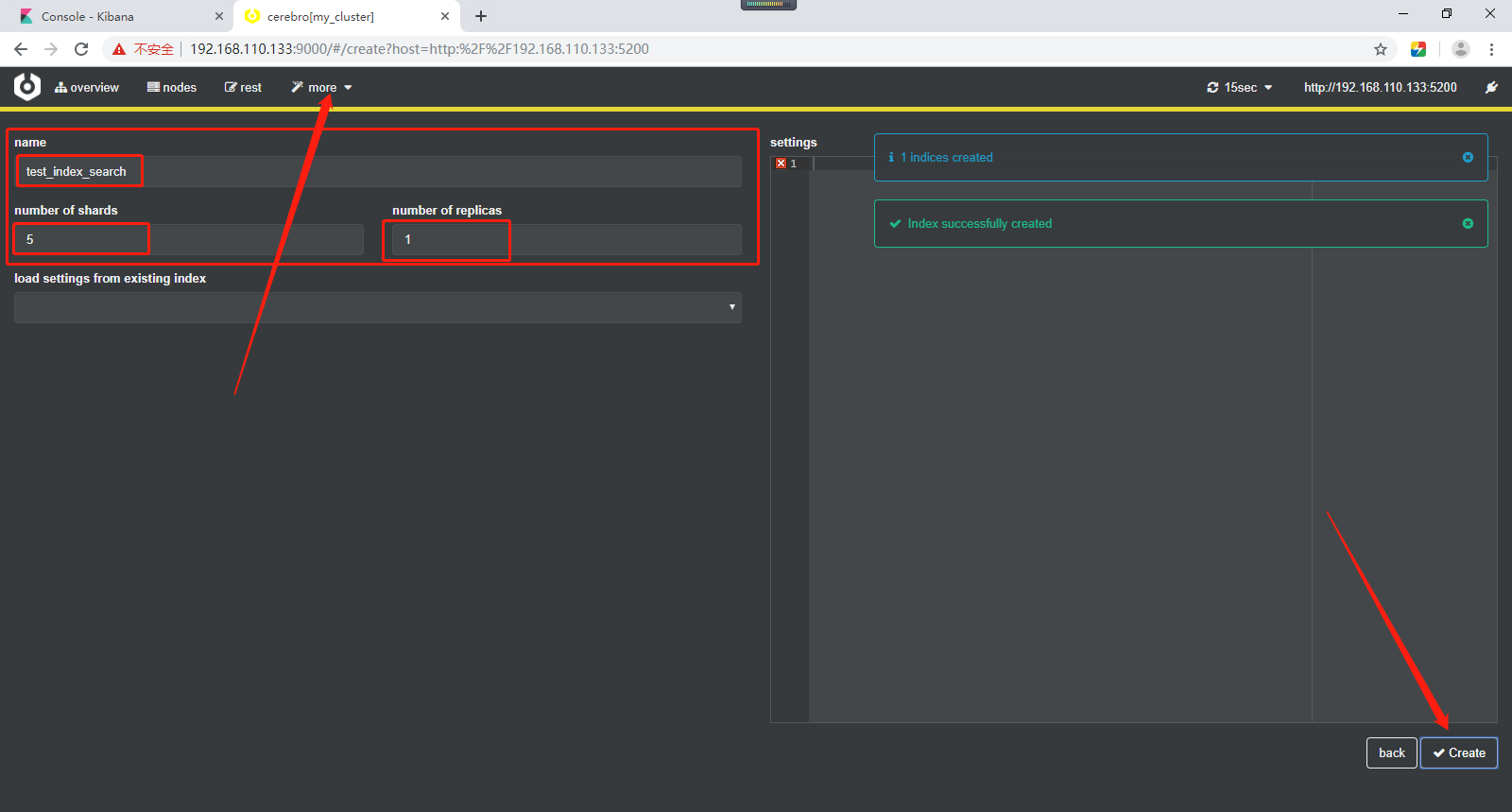
创建索引的两种方式,第一种,直接使用api进行创建即可,如下所示:
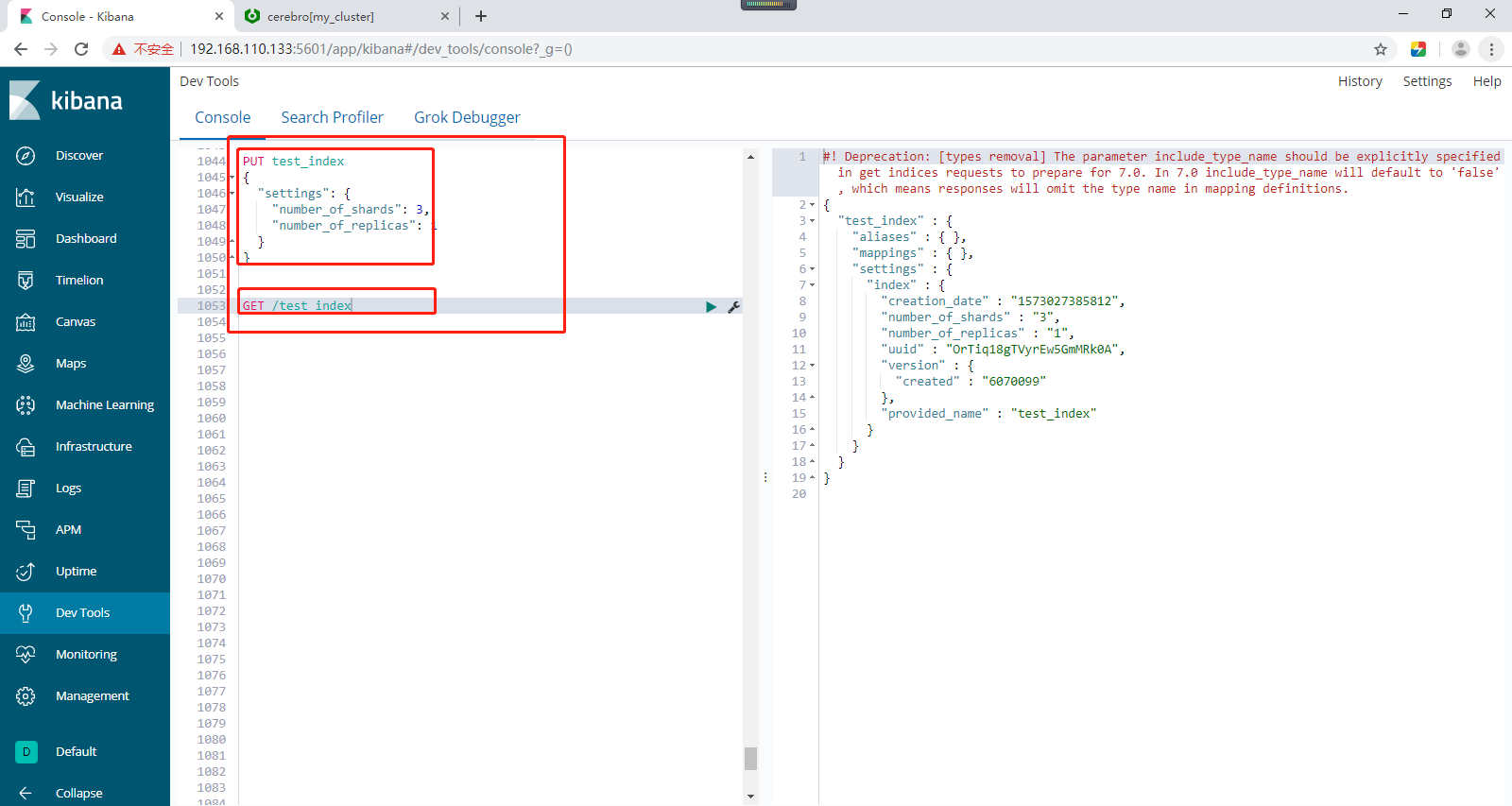
在集群中test_index索引,创建3个分片和1个副本。Primary Shard主分片、Replication Shard副本分片。
# 在集群中test_index索引,创建3个分片和1个副本。Primary Shard主分片、Replication Shard副本分片。 PUT test_index { "settings": { "number_of_shards": 3, "number_of_replicas": 1 } }
方式二,直接使用页面创建即可,如下所示:
实线表示主分片,虚线表示副分片,主分片和副本分片一一对应。效果如下所示:
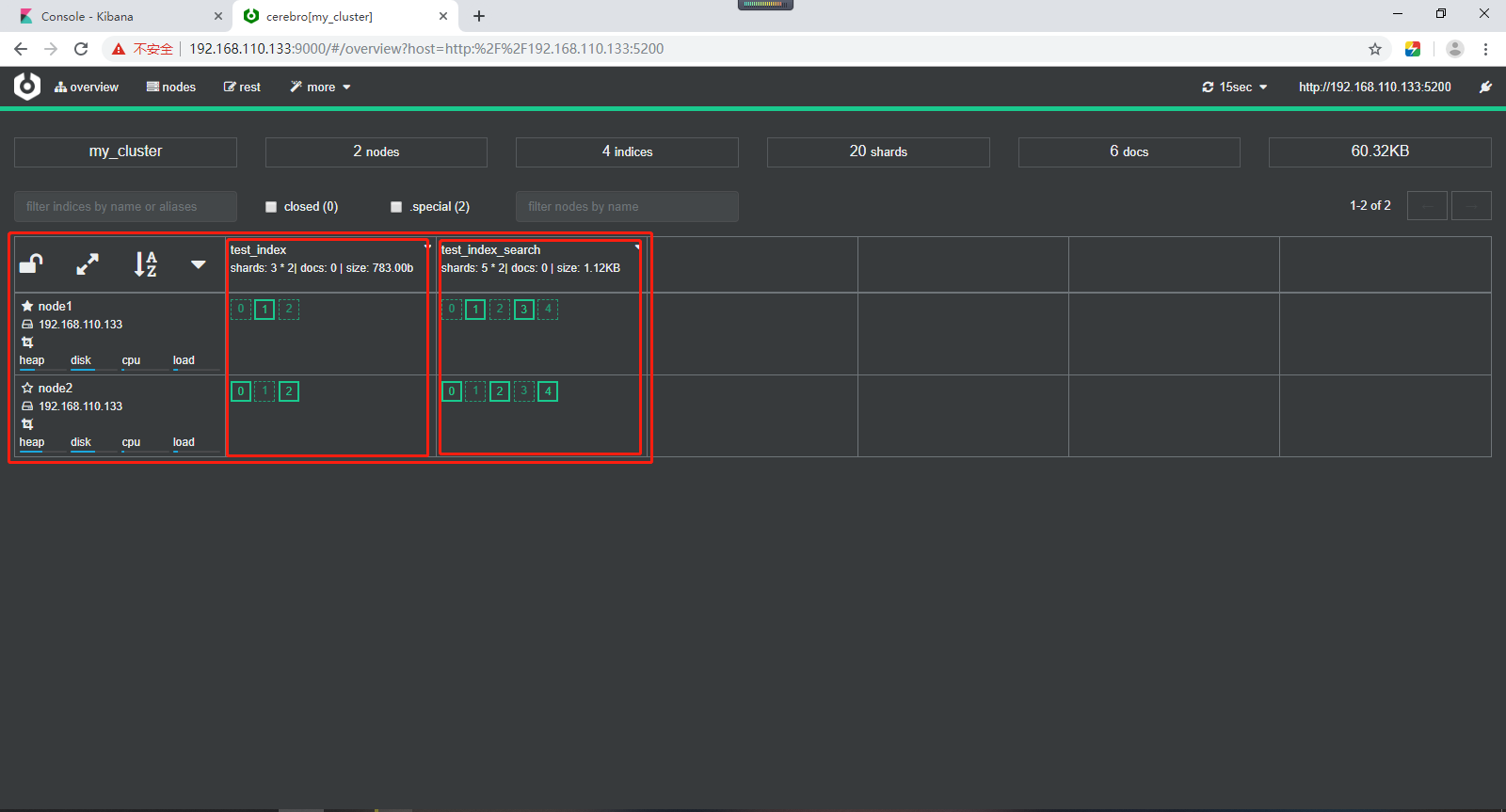
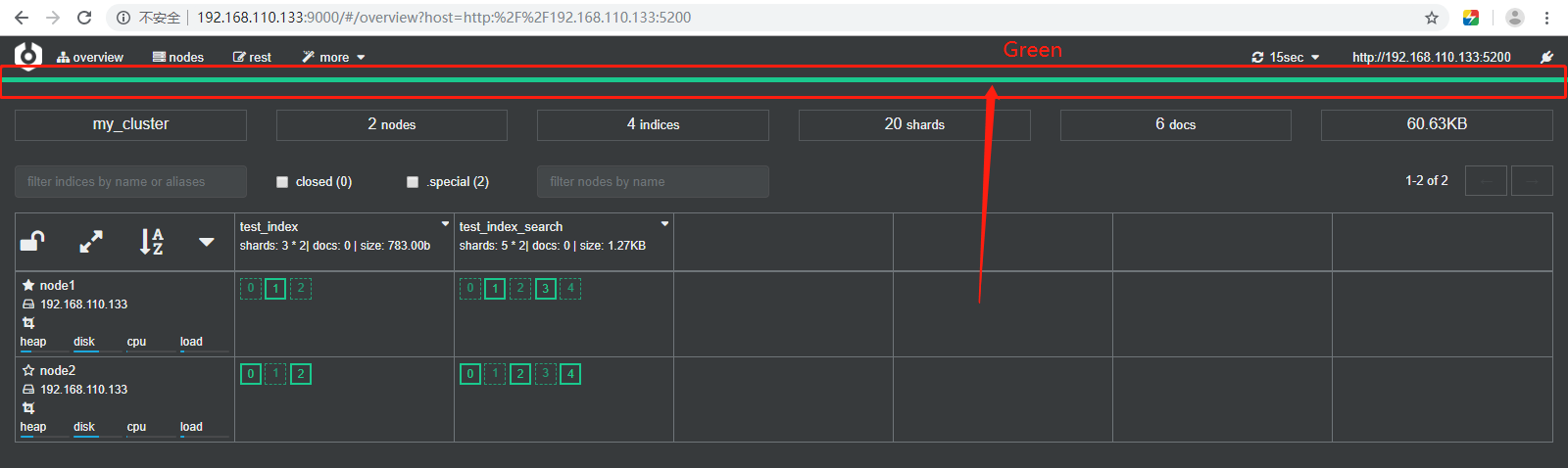
如果是三台节点,创建5个分片,每个分片一个副本的情况,如下所示:

如果创建5个分片,3个副本,就会导致副本无法完整分布,就会出现下面的集群黄色预警,如下所示:

11、如果集群是三个节点,此时增加节点是否能提高test_index的数据容量?
答:不能,因为只有3个分片,已经分布在3台节点上,新增的节点无法利用。
12、如果集群是三个节点,此时增加副本数是否能提高test_index的读取吞吐量?。
答:不能,因为新增的副本是分布在3个节点上,还是利用了同样的资源,如果要增加吞吐量,还需要增加节点,增加新节点,读请求落到新的节点上,就增加了es的吞吐量。
13、分片数的设定非常重要,需要提前规划好。
答:1)、分片数太少,导致后续无法通过增加节点实现水平扩容。
2)、分片数过大,导致一个节点上分布多个分片,造成资源浪费,同时会影响查询性能。
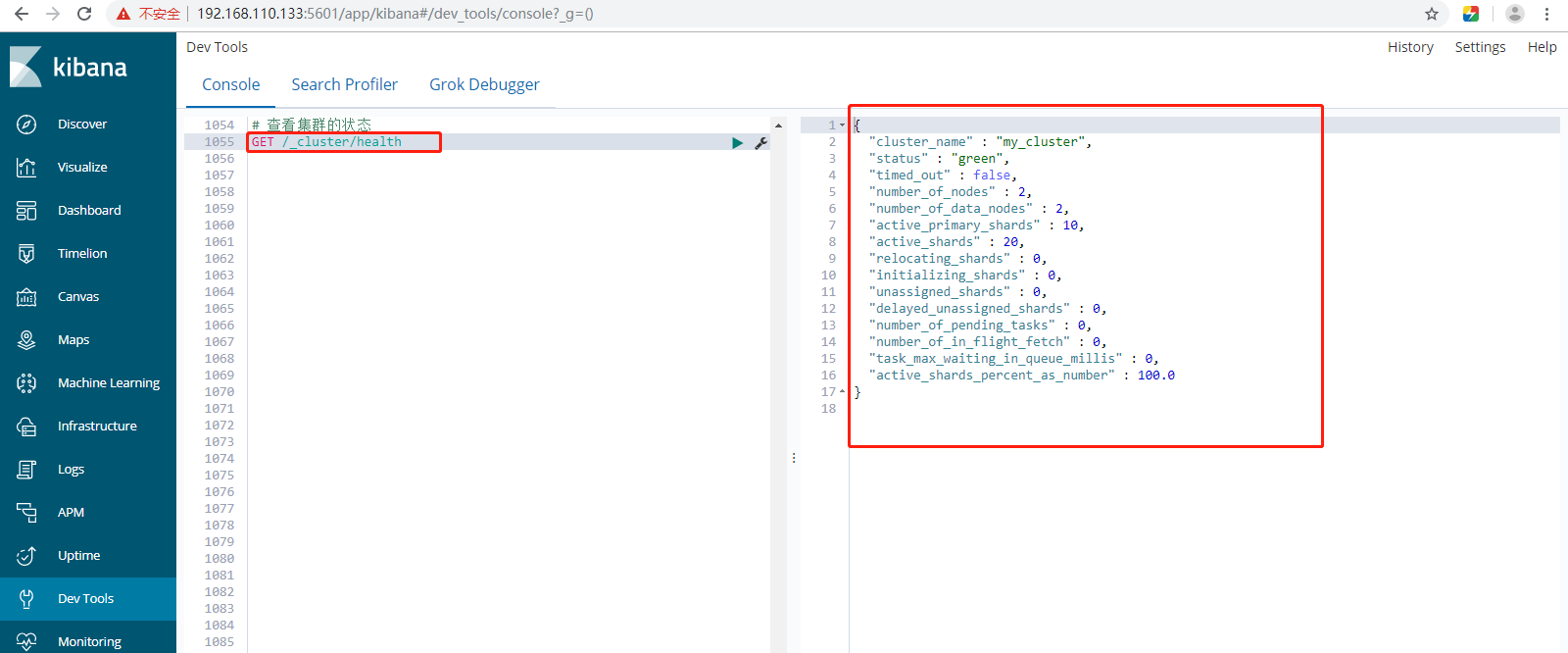
14、集群状态Cluster Health。三种状态只是代表分片的工作状态,并不是代表整个es集群是否能够对外提供服务。Rest api获取状态:GET _cluster/health。
答:通过如下api可以查看集群健康状况,包括以下三种:
a、green 健康状态,指所有主副分片都正常分配。
b、yellow 指所有主分片都正常分配,但是有副本分片未正常分配。
c、red 有主分片未分配。但是可以访问该集群的。
Rest api获取状态:GET _cluster/health。
15、elasticsearch故障转移。图文参考:https://blog.csdn.net/weixin_40792878/article/details/86096009#2_84
备注:红色截图来源于慕课网,尊重版权,从你我做起,谢谢。
假设集群由3个节点组成,此时集群状态是green。初始状态,node1节点(P0、R1分片)、node2节点(P1、R2分片)、node3节点(P2、R0分片)。
如果node1(node1节点是主节点)所在机器宕机导致服务终止,此时集群会如何处理?
第一步、node2和node3发现node1无法响应一段时间后会发起master选举,比如这里选举node2为master节点,此时由于主分片P0下线,集群状态变为red。
第二步、node2发现主分片P0未分配,将R0提升为主分片。此时由于所有主分片都正常分配,集群状态变为yellow。node2节点(P1、R2分片)、node3节点(P2、P0分片)。
第三步、node2发现主分片P0和P1生成新的副本,集群状态变为green。node2节点(P1、R2、R0分片)、node3节点(P2、P0、R1分片)。

将节点2关掉,elasticsearch开始进行故障转移,如下所示:

16、elasticsearch文档分布式存储。
文档最终会存储在分片上,elasticsearch使用文档存储算法。假设doc1存储到分片P1,doc1是如何存储到分片P1的呢,需要文档到分片的映射算法,目的使得文档均匀分布在所有分片上, 以充分利用资源。elasticsearch的分布式文档存储方案使用的是hash算法。
elasticsearch通过如下公式计算文档对应的分片。 shard=hash(routing)%number_of_primary_shards。 解释如下所示: hash算法保证可以将数据均匀的分散在分片中。 routing是一个关键参数,默认是文档id,也可以自行指定。 number_of_primary_shards是主分片数。该算法与主分片数相关,这也是分片数一旦确定后便不能更改的根本原因。
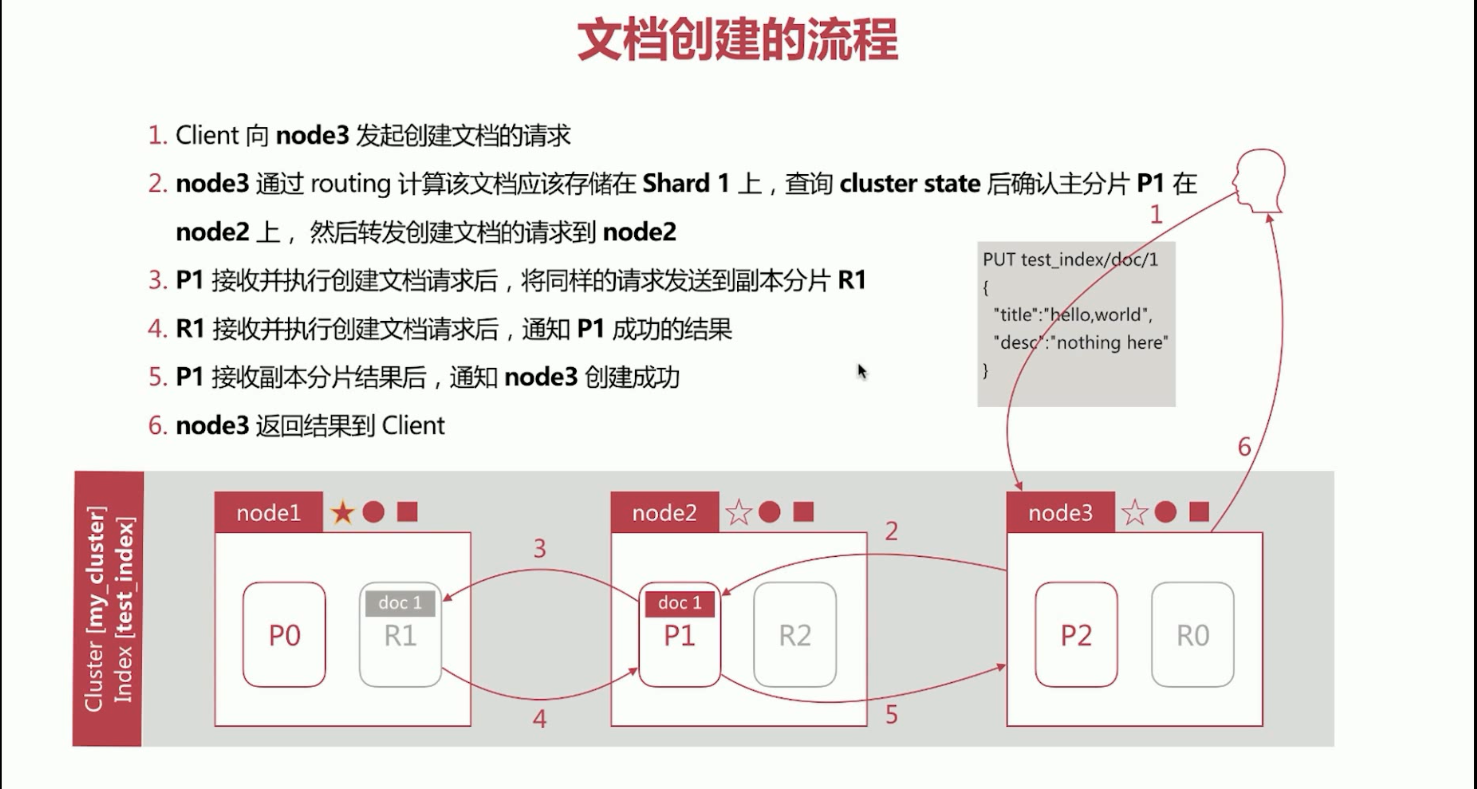
17、elasticsearch文档创建流程。
第一步、Client客户端向node3发起创建文档的请求,node3作为接受请求的节点,此时是node3的Coordinating Node角色起的作用。
第二步、node3通过routing计算该文档应该存储在Shard1上,查询cluste state后确认主分片P1在node2上,然后转发创建文档的请求到node2。
第三步、P1接受并执行创建文档的请求后,将同样的请求发送到副本分片R1。
第四步、R1接收并执行创建文档请求后,通知P1成功的结果。
第五步、P1接收副本分片结果后,通过node3创建成功。
第六步、node3返回结果到client。
18、elasticsearch文档读取流程。
第一步、Client向node3发起创建文档的请求。
第二步、node3通过routing计算该文档应该存储在Shard1上,查询cluste state后获取Shard1的主副分片列表,然后以轮询的机制获取一个shard,比如这里是R1,然后转发读取文档的请求到node1。
第三步、R1接收并执行创建文档的请求后,将结果返回给node3。
第四步、node3返回结果给Client。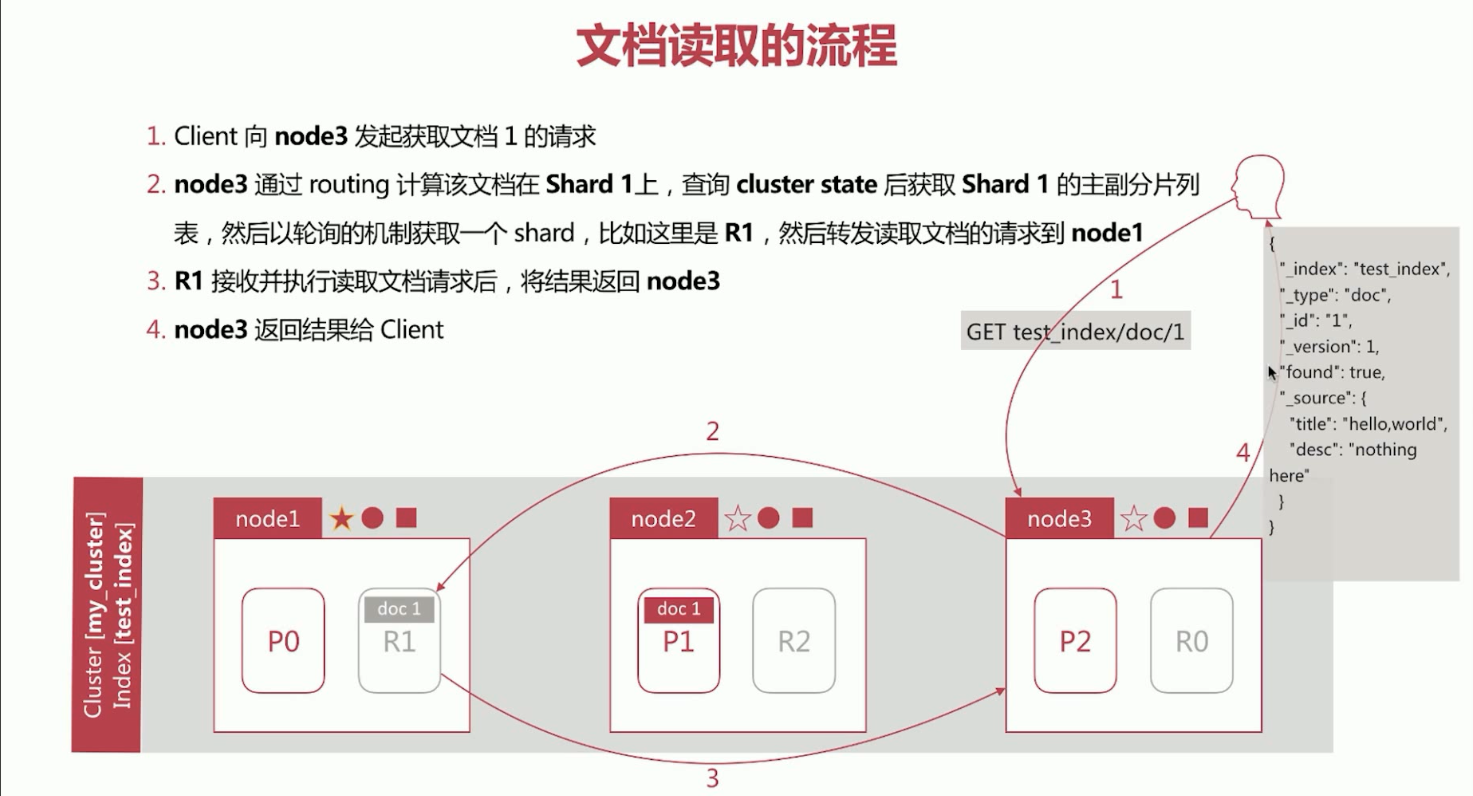
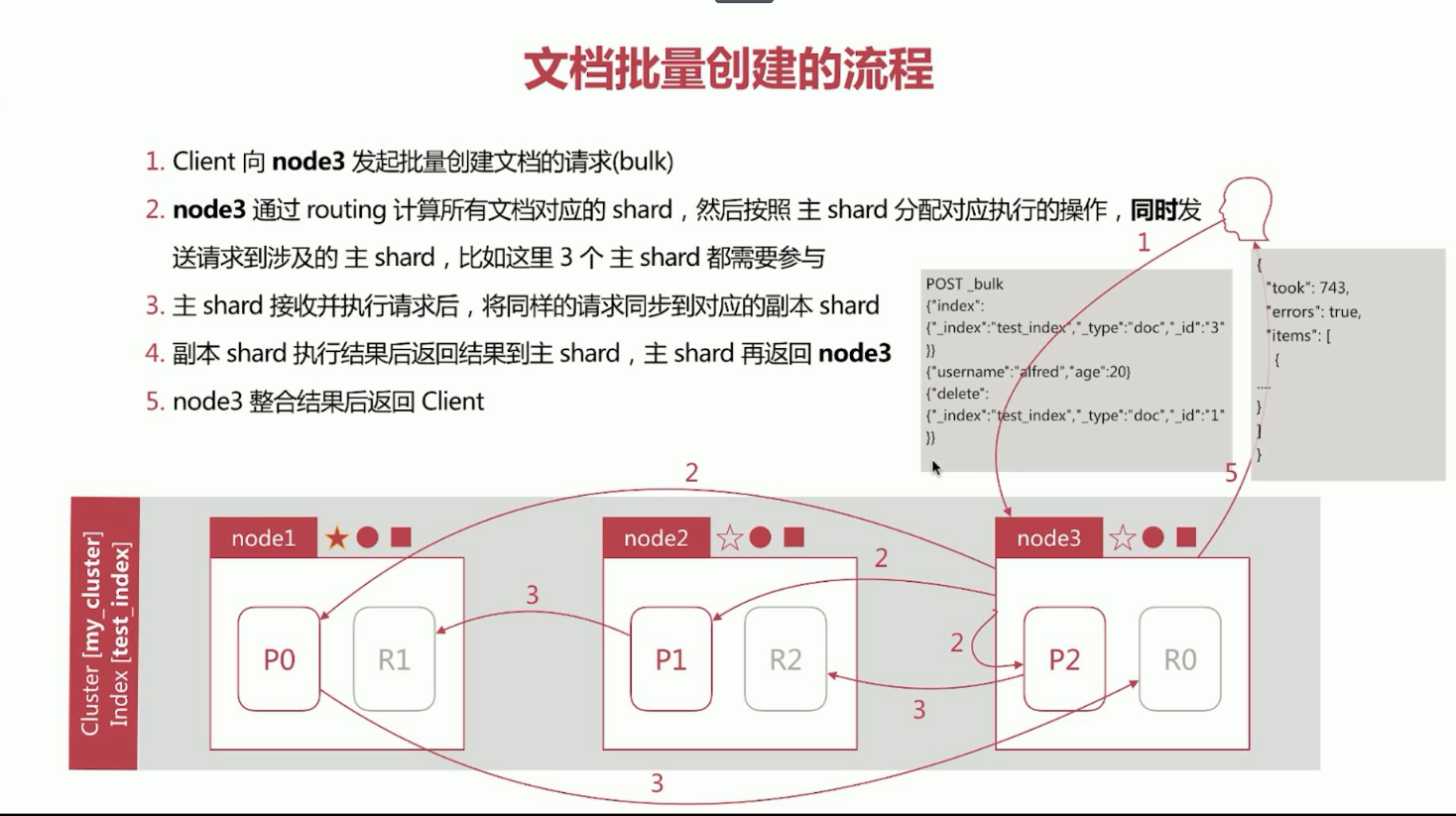
19、elasticsearch文档批量创建的流程。
第一步、Client向node3发起批量创建文档的请求(bulk)。
第二步、node3通过routing计算所有文档对应的shard,然后按照主shard分配对应执行的操作,同时发送请求到涉及的主shard,比如这里3个主shard都需要参与。
第三步、主shard接受并执行请求后,将通过的请求同步到对应的副本shard。
第四步、副本shard执行结果后返回结果到主shard,主shard再返回node3。
第五步、node3整合结果后返回Client。
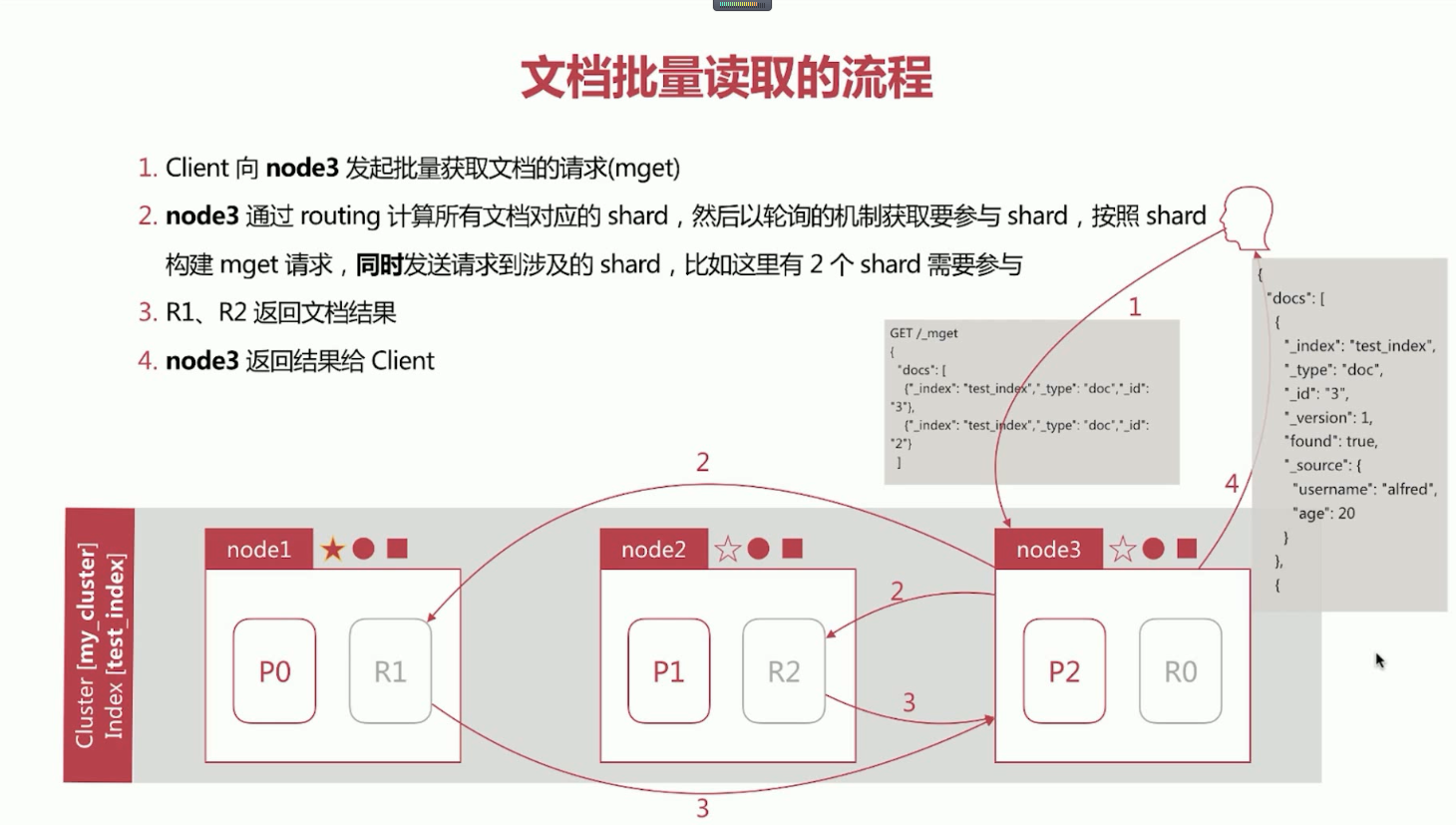
20、elasticsearch文档批量读取的流程。
第一步、Client向node3发起批量获取文档的请求(mget)。
第二步、node3通过routing计算所有文档对应的shard,然后以轮询的机制获取要参与的shard,按照shard构建mget请求,同时发送请求到涉及的shard,比如这里有2个shard需要参与。
第三步、R1、R2返回文档结果。
第四步、node3返回结果给Client。
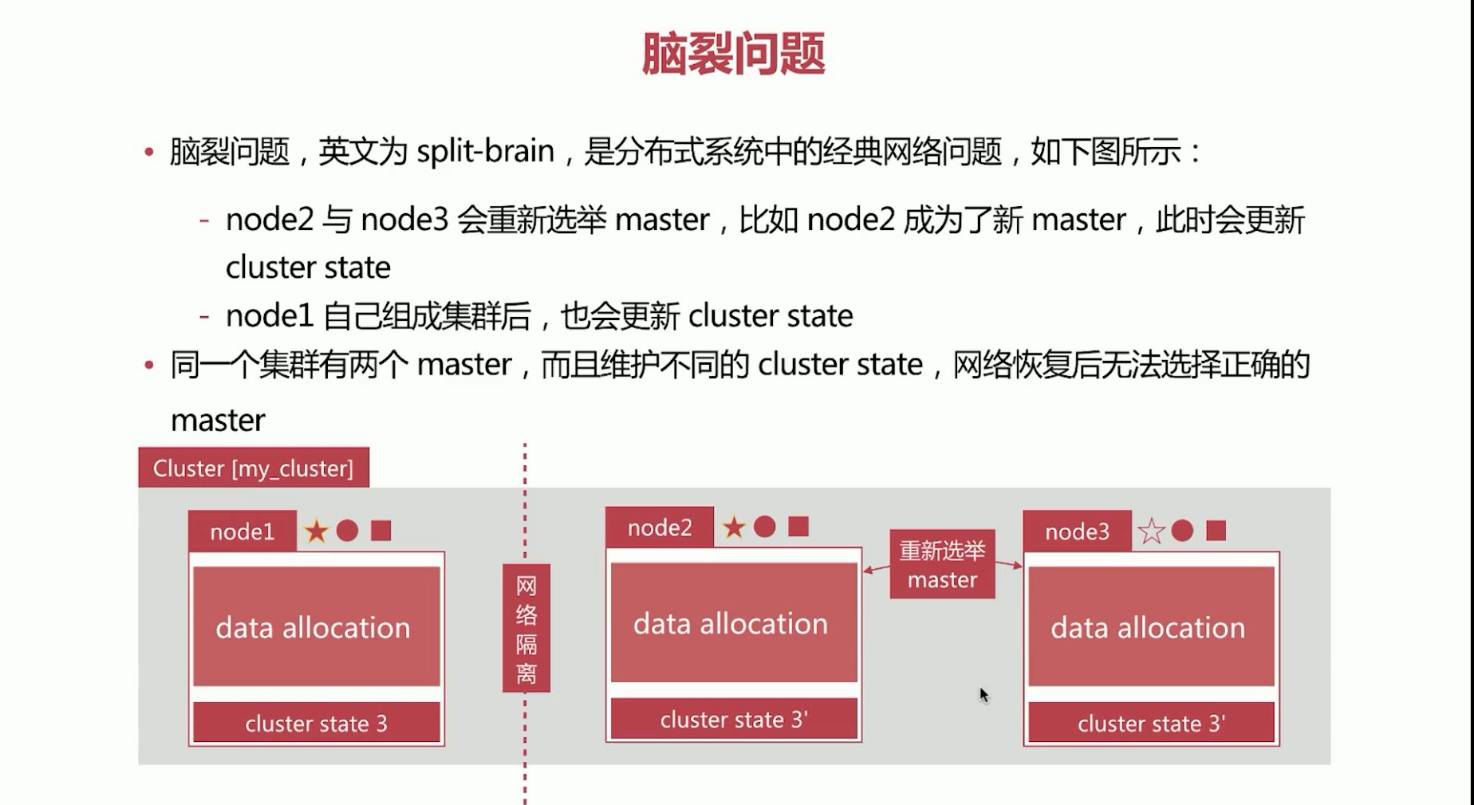
21、elasticsearch的脑裂问题。脑裂问题,英文为split-brain,是分布式系统中的经典网络问题。
如果node1和node2、node3网络隔离了。这个时候会发生如下所示的情况。
node2与node3会重新选举master,比如node2成为了新master,此时会更新cluster state,然后node1自己组成集群后,也会更新cluster state。同一个集群有两个master,而维护不同的cluster state,网络恢复后无法选择正确的master。
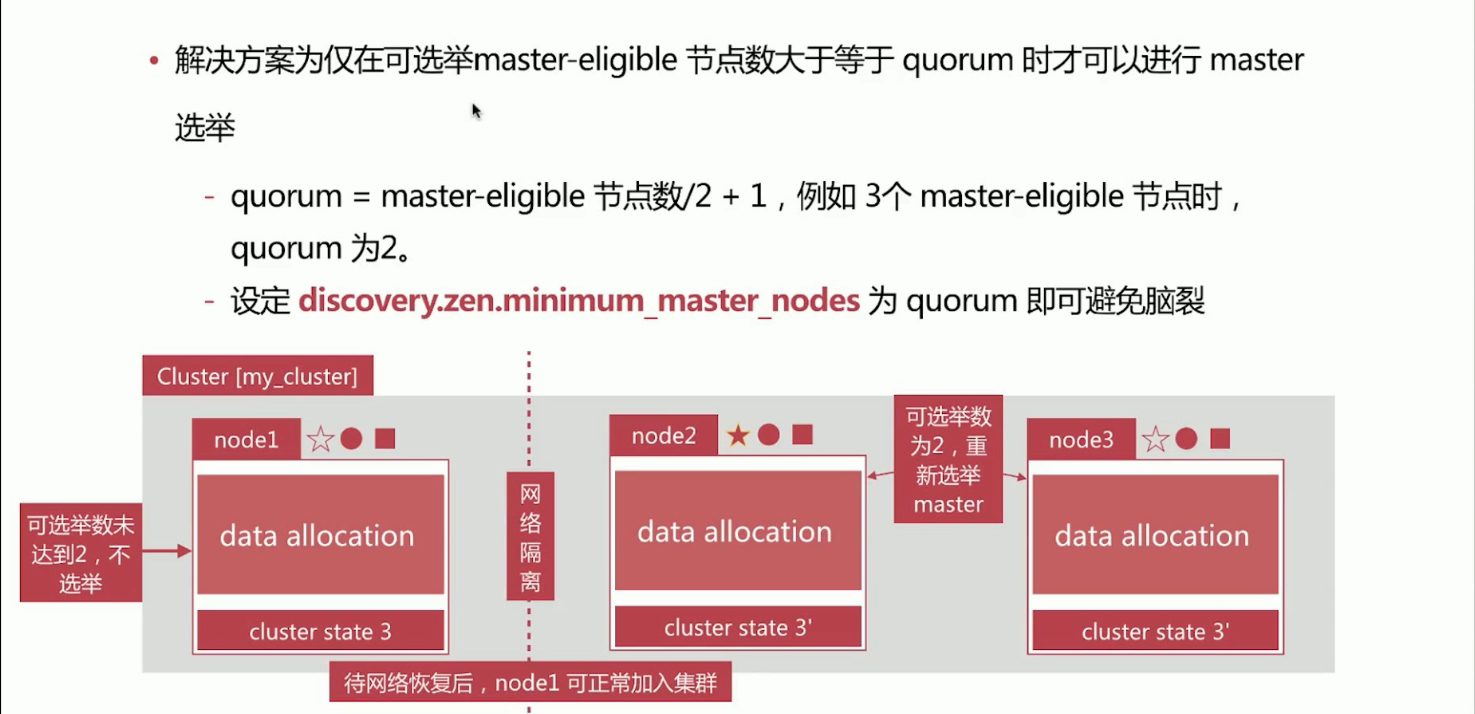
如何解决脑裂问题,解决方案为仅在可选举master-eligible节点数大于等于quorum时候才可以进行master选举。
quorum = master-eligible 节点数/2 + 1,例如 3个master-eligible节点时,quorum为2。
解决:设置config/elasticsearch.yml参数配置 discovery.zen.mininum_master_nodes为quorum的值即可避免脑裂。
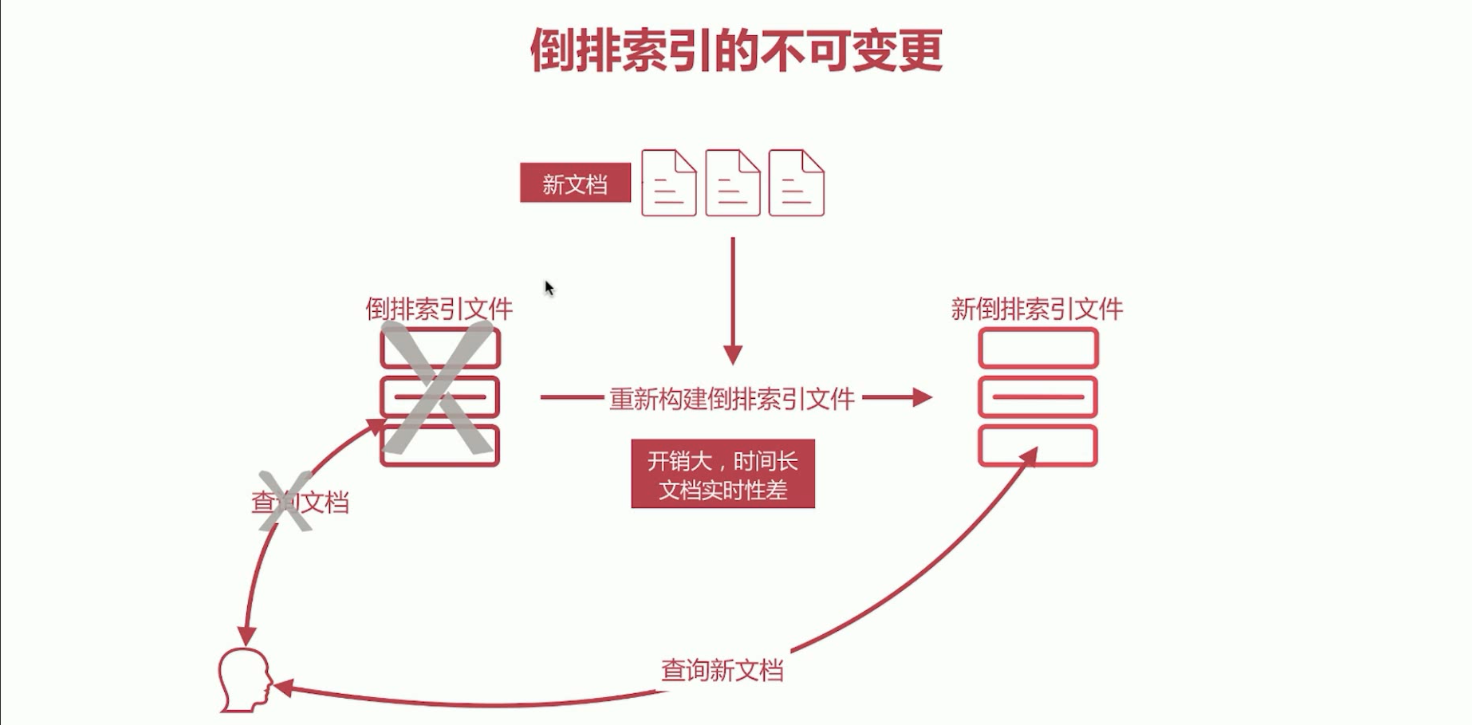
22、倒排索引生成不能更改。倒排索引一旦生成,不能更改。
1)、好处,如下所示:
a、不用考虑并发写文件的问题,杜绝了锁机制带来的性能问题。
b、由于文件不再更改,可以充分利用文件系统缓存,只允许载入一次,只要内存足够。
c、对该文件的读取都会从内存读取,性能高。
d、利于生成缓存数据。
e、利于对文件进行压缩存储,节省磁盘和内存存储空间。
2)、坏处,如下所示:
a、写入新文档时,必须重新构建倒排索引文件,然后替换老文件后,新文档才能被检索,导致文档实时性受到影响。
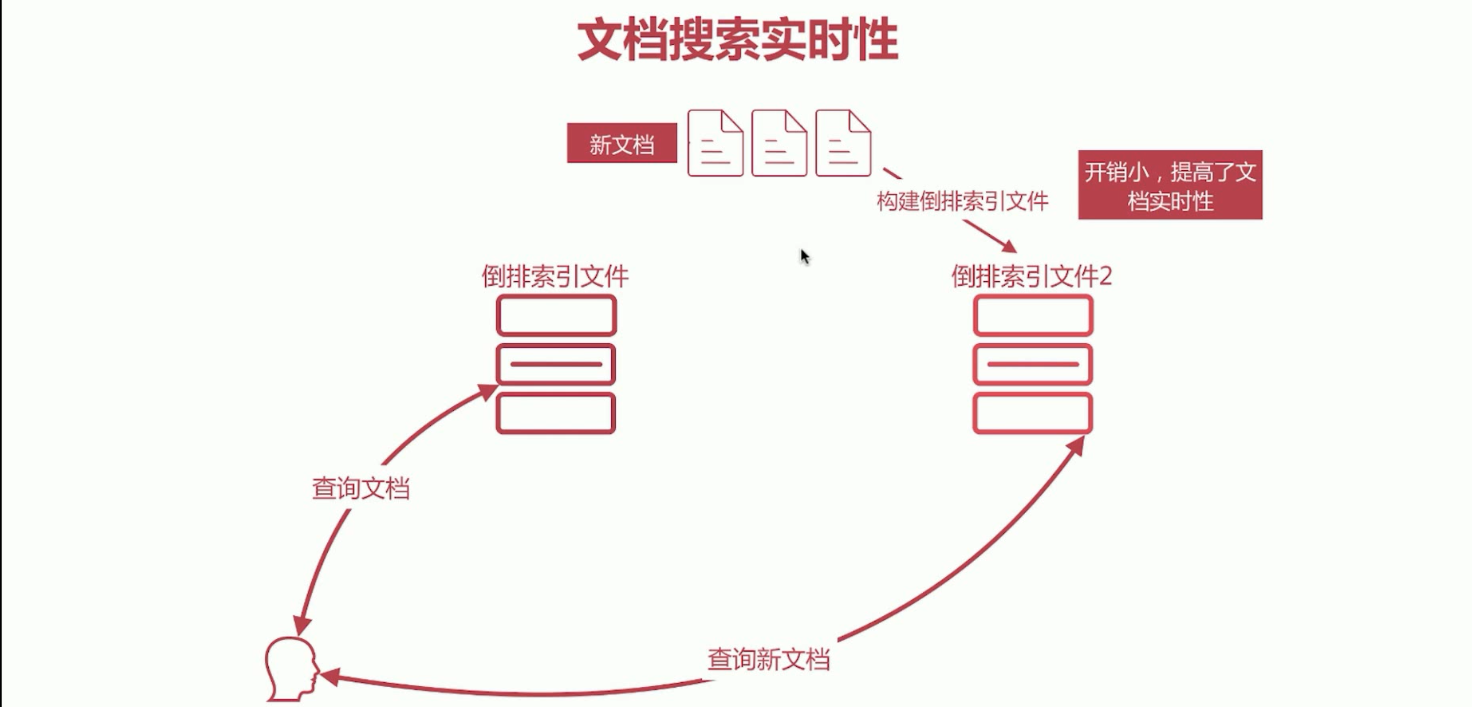
文档搜索实时性,解决新文档查询慢的问题,解决方案是新文档直接生成新的倒排索引文件,查询的时候同时查询所有的倒排文件,然后做结果的汇总计算即可。
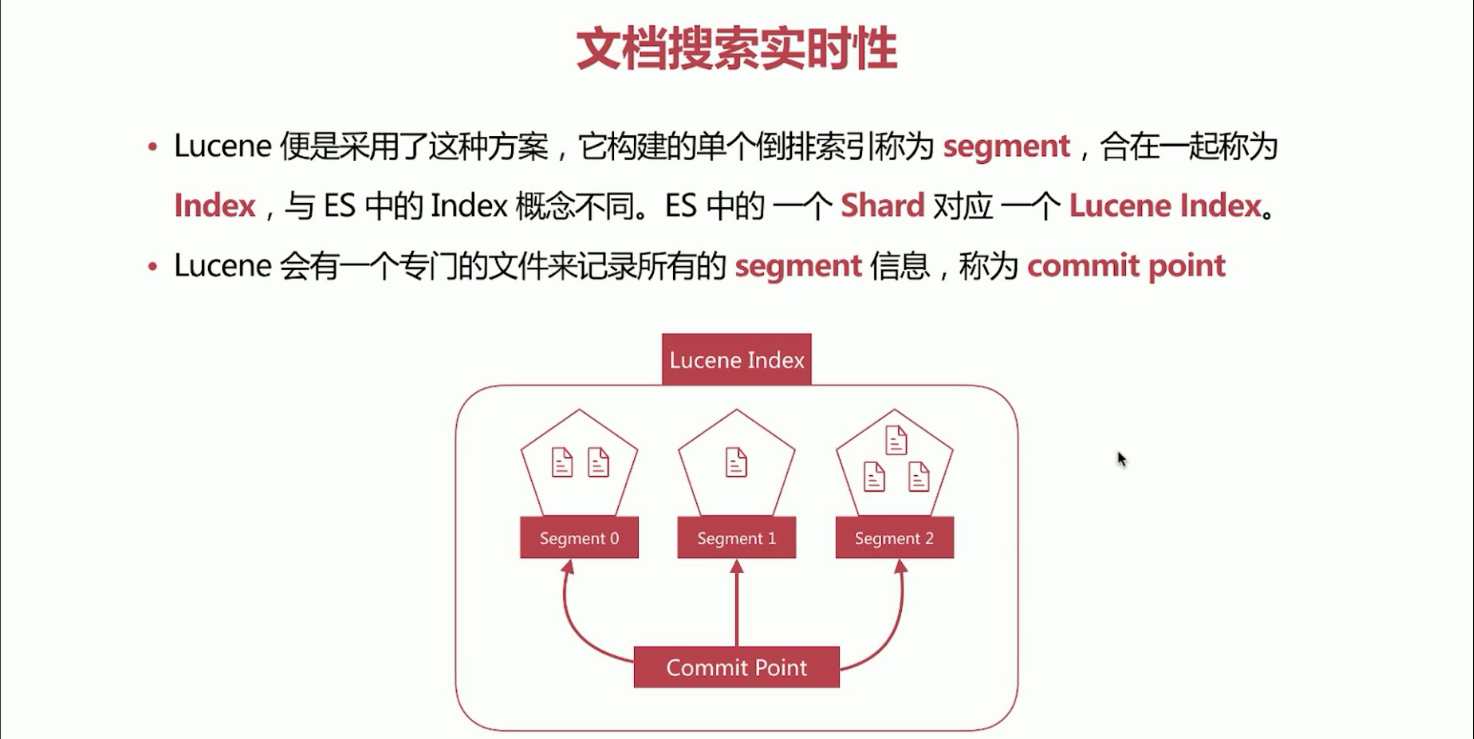
23、Lucene 中的segment、Elasticsearch中的Index的概念理解。
a、Lucene采用了这种方案,它构建的单个倒排索引称为segment,合在一起称为Index(Lucene中的名称,是segment的集合),与Elasticsearch中的Index(逻辑上document文档集合)概念不同,Elasticsearch中的一个Shard对应一个Lucene Index。
b、Lucene会有一个专门的文件来记录所有的segment信息,称为 Commit Point。
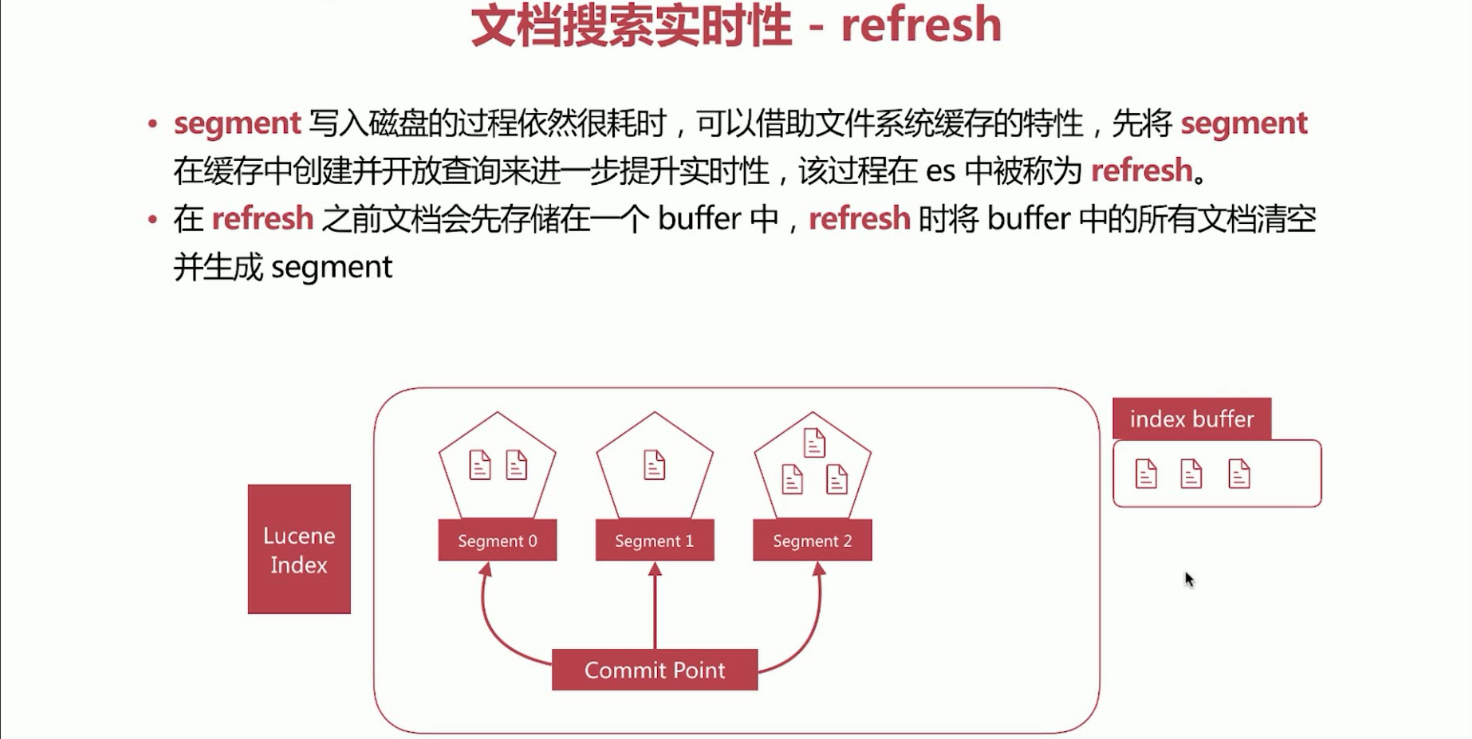
24、文档搜索实时性概念refresh。利用缓存来提升查询实时性。
a、segment写入磁盘的过程依然很耗时,可以借助文件系统缓存的特性,先将segment在缓存(即内存)中创建并开放查询来进一步提升实时性,该过程在es中被称为refresh。
b、在refresh之前文档会先存储在一个buffer中,refresh时将buffer中的所有文档清空并生成segment。
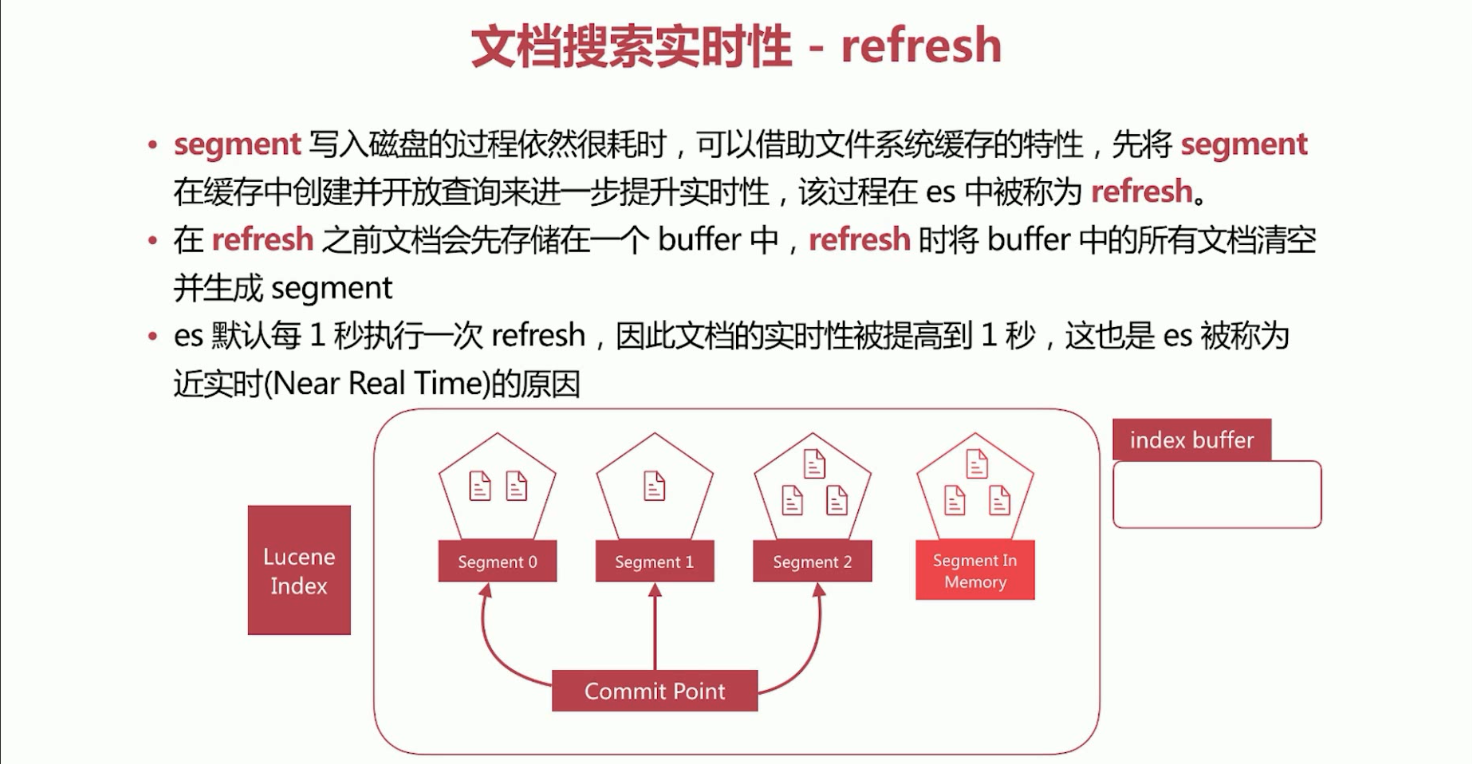
c、Elasticsearch默认每1秒执行一次refresh,因此文档的实时性被提高到1秒,这也是es被称为近实时(Near Real Time)的原因。
refresh将缓存中的文件清空并在磁盘上面生成segment。
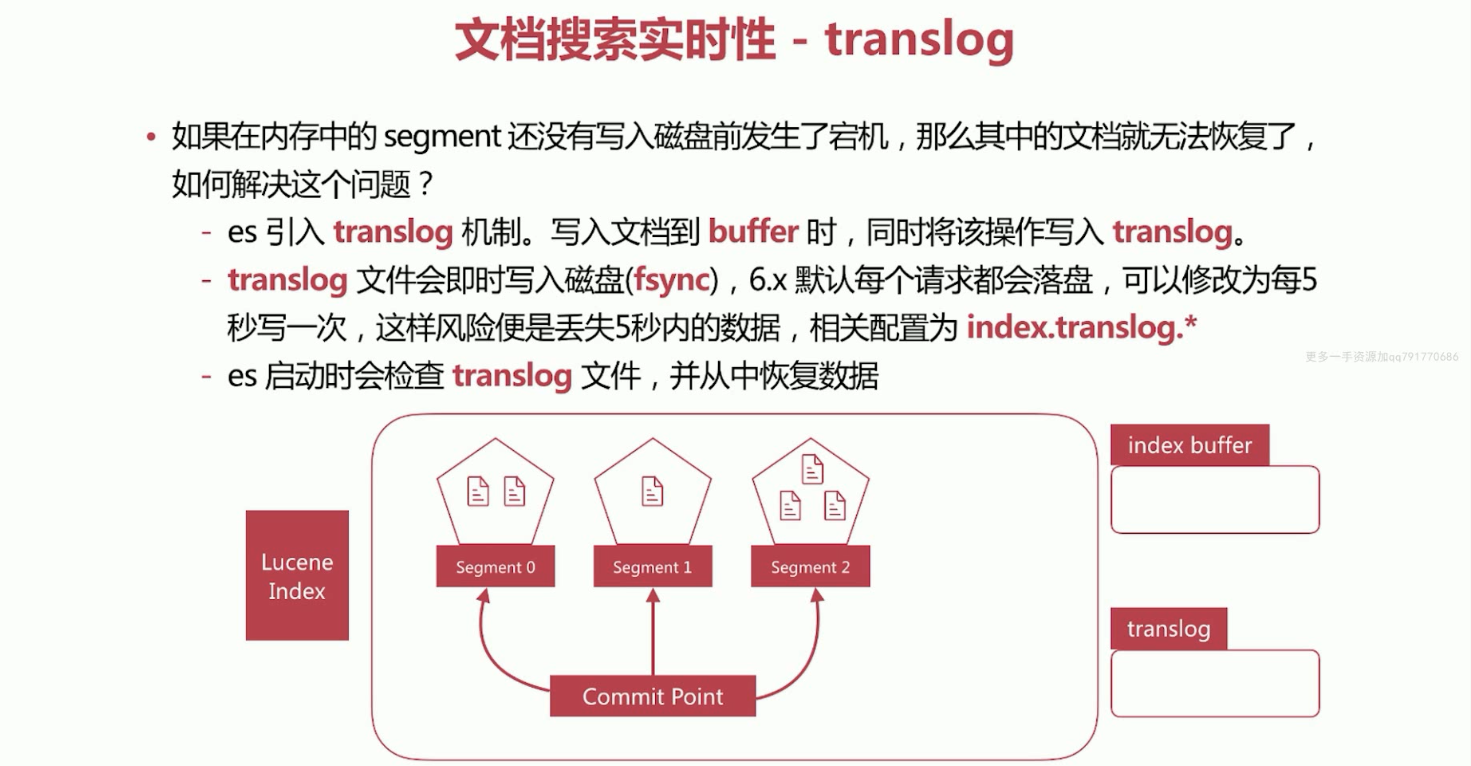
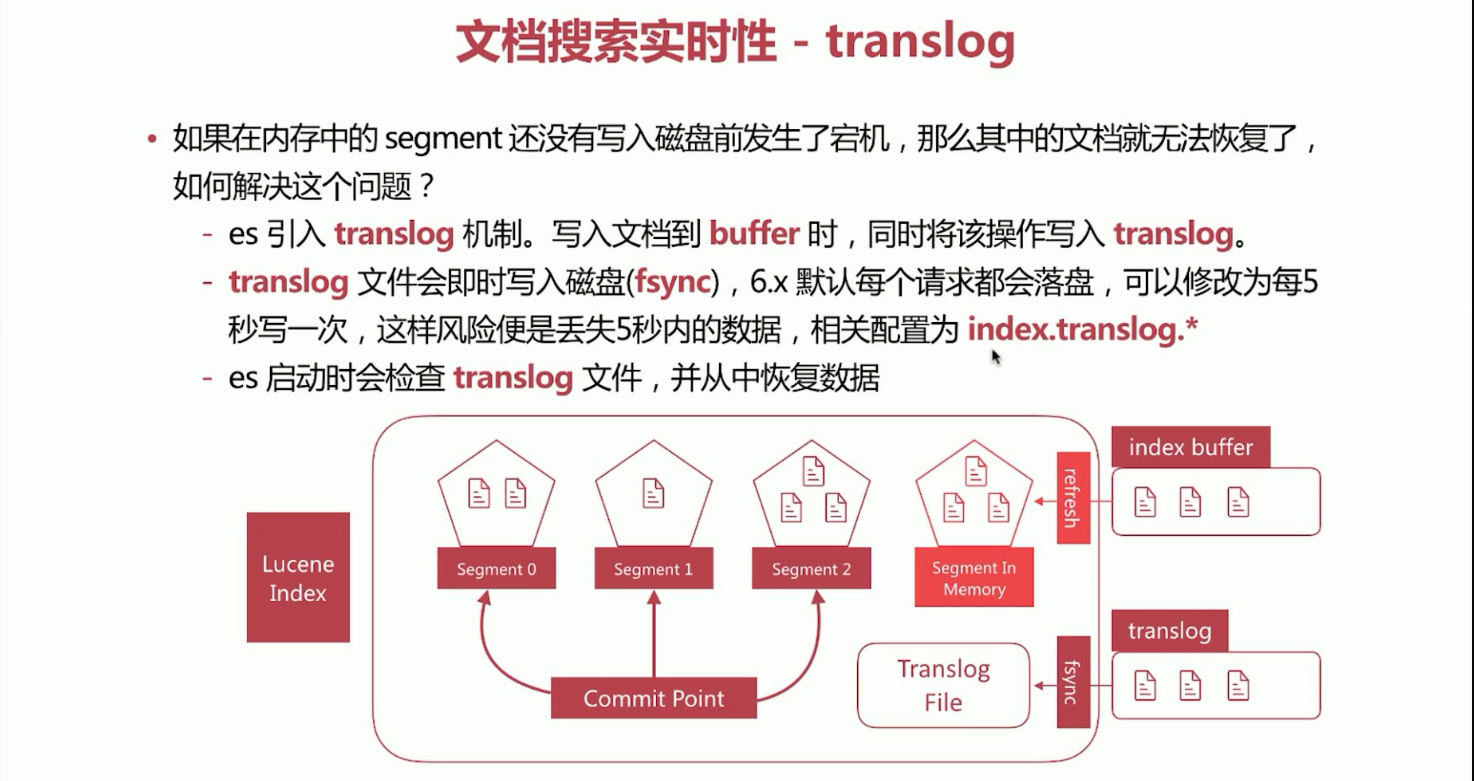
25、文档搜索实时性概念translog。处理缓存易丢失的情况。
如果在内存中的segment还没有写入磁盘前发生了宕机,那么其中的文档就无法恢复了,如何解决这个问题呢?
a、Elasticsearch引入了translog机制,写入文档到buffer的时候,同时将该操作写入translog。
b、translog文件会即时写入磁盘(fsync),6.x默认每个请求都会落盘,可以修改为每5秒写一次,这样风险便是丢失5秒内的数据,相关配置为index.translog.*。
c、Elasticsearch启动的时候会检查translog文件,并从中恢复数据。
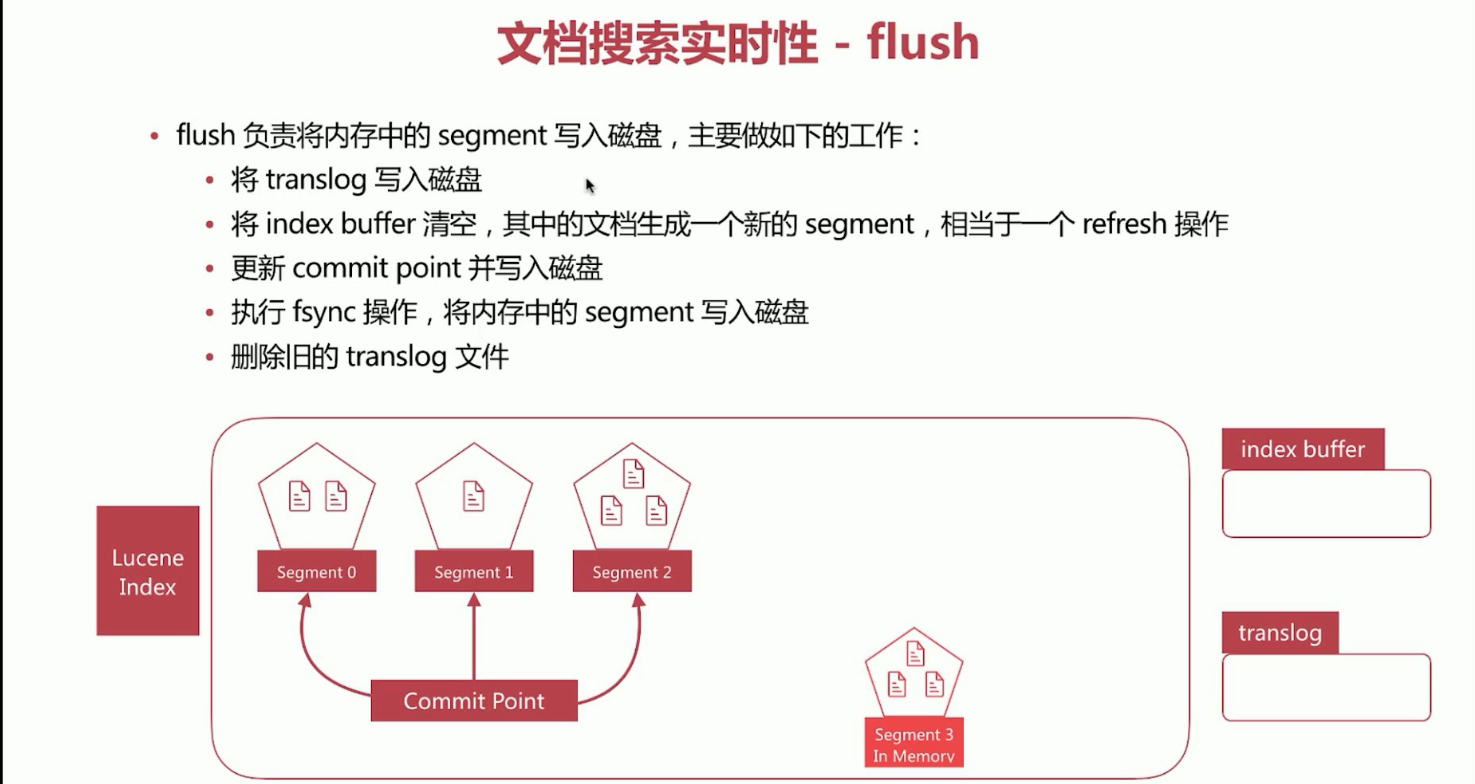
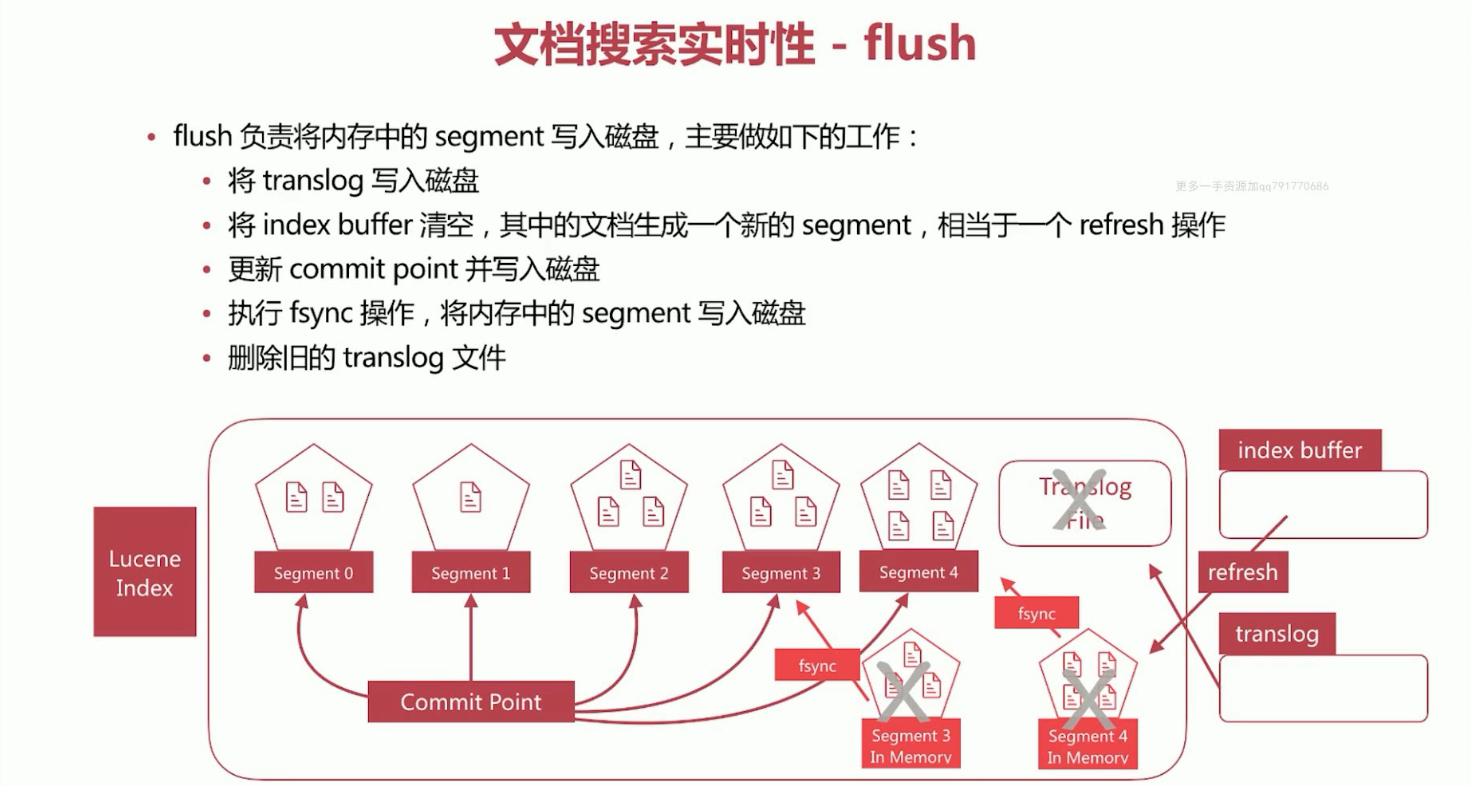
26、文档搜索实时性概念flush。持久化缓存中的segment。
flush负责将内存中的segment写入磁盘,主要做如下的工作。
a、将translog写入磁盘。
b、将index buffer清空,其中的文档生成一个新的segment,相当于一个refresh操作。
c、更新commit point并写入磁盘。
d、执行fsync操作,将内存中的segment写入磁盘。
e、删除旧的translog文件。
27、文档搜索实时性概念refresh。
refresh发生的时机主要有如下几种情况。
a、间隔时间达到的时候,通过index.settings.refresh_interval来设定,默认是1秒。
b、index.buffer占满时,其大小通过indices.memory.index_buffer_size设置,默认为jvm heap的10%,所有shard共享。
c、flush发生的时候也会发生refresh。
28、文档搜索实时性概念flush。
flush发生的时机主要有以下几种情况:
a、间隔时间达到时,默认是30分钟,5.x之前可以通index.translog.flush_threshold_period修改;之后发布的版本无法设置。
b、translog占满时,其大小可以通过index.translog.flush_threshold_size控制,默认是512MB;每个index有自己的translog。
29、文档搜索实时性,删除与更新文档。
1)、segment一旦生成就不能更改,那么如果你要删除文档该如何操作呢?
a、Lucene专门维护一个.del的文件,记录所有已经删除的文档,注意,.del上记录的是文档在Lucene内部的id。
b、在查询结果返回前会过滤掉.del中的所有文档。
2)、更新文档如何进行呢?
a、首先删除文档,然后再创建新文档。
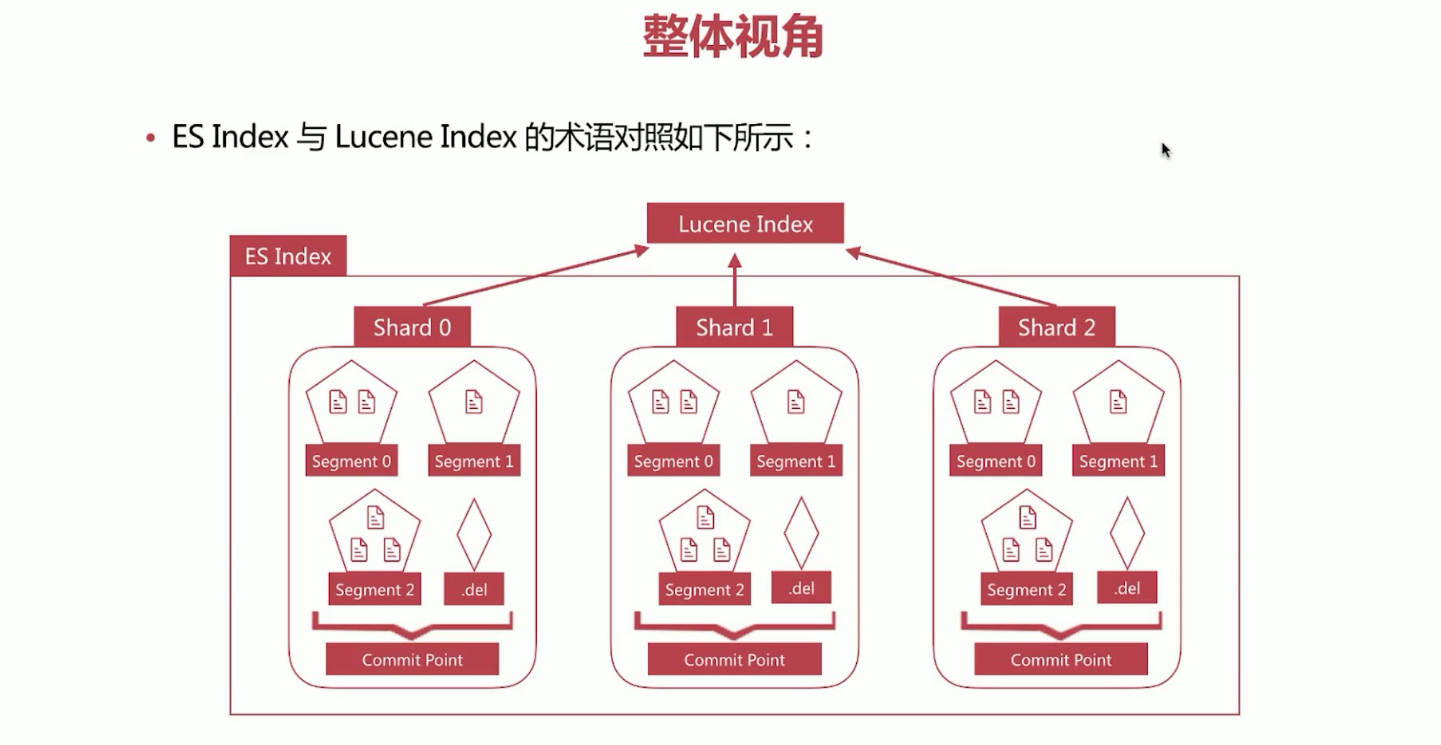
3)、ES的index,一个index可以包含多个Shard,比如这里的Shard0、Shard1、Shard2,而每一个Shard就是一个Lucene Index。一个Lucene Index是由一堆Segment组成的,而会有Commit Point维护这些Segment文件,同时.del文件记录已删除的文档。
30、Elasticsearch中的Segment Merge。
a、随着segment的增多,由于一次查询的segment数增多,查询速度会变慢。
b、es会定时在后台进行segment merge的操作,减少segment的 数量。
c、通过force_merge api可以手动强制做segment merge的操作。
作者:别先生
博客园:https://www.cnblogs.com/biehongli/
如果您想及时得到个人撰写文章以及著作的消息推送,可以扫描上方二维码,关注个人公众号哦。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?