
Elasticsearch伪集群搭建
Elasticsearch单机版安装:https://www.cnblogs.com/biehongli/p/11643482.html
1、Elasticsearch集群版安装,这里进行模拟,是伪集群版的安装,我使用一台机器,通过修改端口号的方式进行伪集群的搭建。
注意:由于单机版的安装过程中出现了各种错误,所以集群版我是直接复制修改好的单机版的(注意:home/hadoop/soft/el_slave/elasticsearch-5.4.3-slaver1/data里面有一个nodes文件夹,将该文件夹删除即可,下面也会提及)。我没有再次通过解压缩安装包的方式,因为单机版报了不少错误,所以用解决完错误的更快些。
Elasticsearch集群版的搭建,是一主二从的方式,即一个master主节点,两个slaver从节点。(备注,我第一次搭建的作为了主节点了,请自行脑补)。
我这里先创建一个el_slave文件夹,然后将第一次单机版的Elasticsearch复制两份,备用。

1 [elsearch@slaver4 soft]$ mkdir el_slave 2 [elsearch@slaver4 soft]$ ls 3 elasticsearch-5.4.3 elasticsearch-head-master el_slave node-v8.16.2-linux-x64 4 [elsearch@slaver4 soft]$ cp -r elasticsearch-5.4.3/ el_slave/ 5 [elsearch@slaver4 soft]$ ls 6 elasticsearch-5.4.3 elasticsearch-head-master el_slave node-v8.16.2-linux-x64 7 [elsearch@slaver4 soft]$ cd el_slave/ 8 [elsearch@slaver4 el_slave]$ ls 9 elasticsearch-5.4.3 10 [elsearch@slaver4 el_slave]$ mv elasticsearch-5.4.3/ elasticsearch-5.4.3-slaver1 11 [elsearch@slaver4 el_slave]$ cp -r elasticsearch-5.4.3-slaver1/ elasticsearch-5.4.3-slaver2 12 [elsearch@slaver4 el_slave]$ ls 13 elasticsearch-5.4.3-slaver1 elasticsearch-5.4.3-slaver2 14 [elsearch@slaver4 el_slave]$
2、开始zao起来,修改主节点的配置文件/home/hadoop/soft/elasticsearch-5.4.3/config/elasticsearch.yml。添加如下所示的内容。
1 # 指定集群的名称 2 cluster.name: biehl01 3 # 给master起一个名称,叫master 4 node.name: master 5 # 告诉此节点,它就是master 6 node.master: true 7 # 绑定的ip地址和默认端口号9200 8 network.host: 192.168.110.133
操作如下所示:
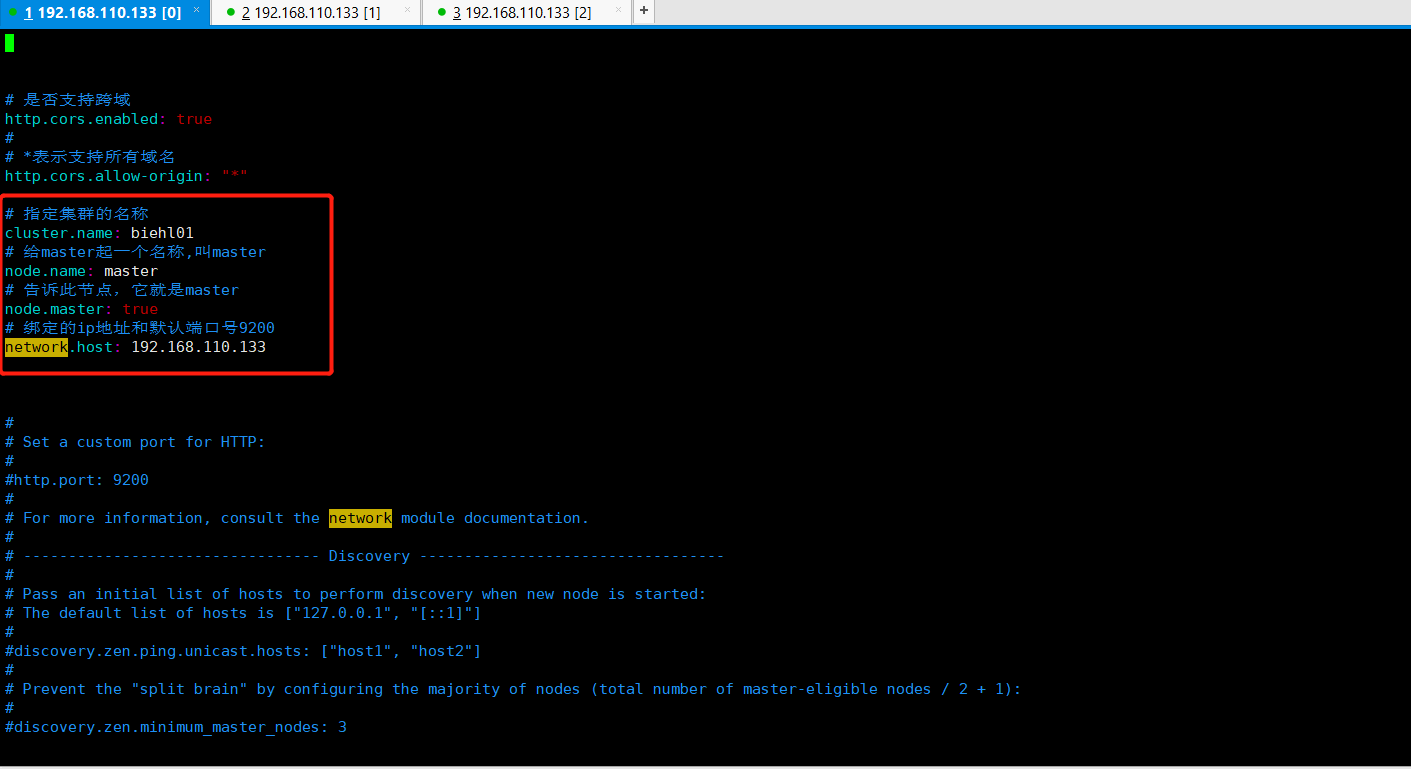
修改主节点配置文件,以后重启一下elasticsearch,查看效果,如下所示:

3、主节点修改,完毕开始修改从节点的配置文件,修改内容如下所示:
1 # 从节点cluster.name要和master主节点的名称要保持一致 2 cluster.name: biehl01 3 # 从节点起一个名称 4 node.name: slave1 5 # 绑定的ip地址 6 network.host: 192.168.110.133 7 # 修改默认的端口号,默认9200 8 http.port: 8200 9 10 # 找到master主节点 11 discovery.zen.ping.unicast.hosts: ["192.168.110.133"]
从节点一配置如下所示:
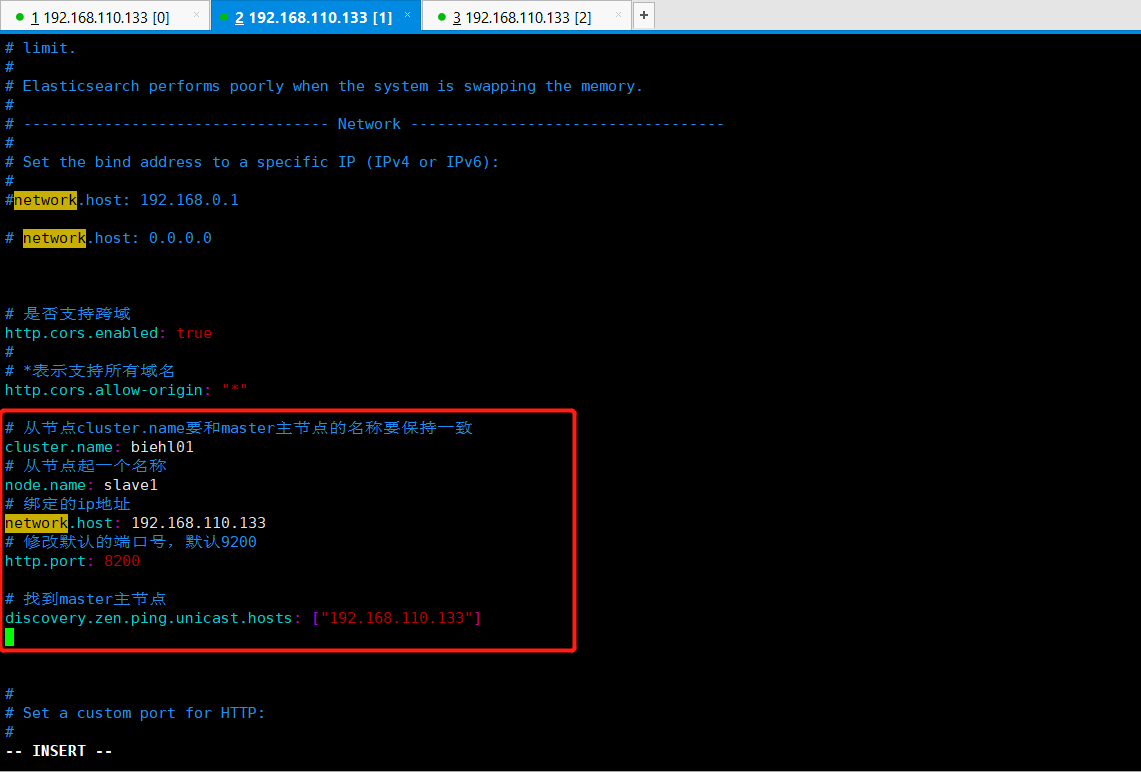
从节点二配置文件里面添加如下所示内容:
1 # 从节点cluster.name要和master主节点的名称要保持一致 2 cluster.name: biehl01 3 # # 从节点起一个名称 4 node.name: slave2 5 # # 绑定的ip地址 6 network.host: 192.168.110.133 7 # # 修改默认的端口号,默认9200 8 http.port: 7200 9 # 10 # # 找到master主节点,discovery.zen.minimum_master_nodes的值计算是节点总数/2 + 1(三个节点就是写2即可) 11 # discovery.zen.minimum_master_nodes: 2 12 discovery.zen.ping.unicast.hosts: ["192.168.110.133"]
从节点二配置如下所示:

修改完毕,主节点,从节点一二,开始启动,三个节点,发现自己有点单蠢了呢。开始三个节点后台启动,使用jps显示三个进程,但是界面就是显示不了从节点一二,主要造成这个的原因是我复制了主节点,然后分析一下原因,我前台启动,发现报错了,错误如下所示:
1 # 主节点的报错 2 [master] failed to send join request to master [{slave1}{rYUCm8sMRzaXu84zRj3duQ}{qL5ICfOKQKyDTaRytL5vGg}{192.168.110.133}{192.168.110.133:9301}], reason [RemoteTransportException[[slave1][192.168.110.133:9301][internal:discovery/zen/join]]; nested: NotMasterException[Node [{slave1}{rYUCm8sMRzaXu84zRj3duQ}{qL5ICfOKQKyDTaRytL5vGg}{192.168.110.133}{192.168.110.133:9301}] not master for join request]; ], tried [3] times 3 4 # 从节点的报错 5 [slave1] failed to send join request to master [{slave2}{rYUCm8sMRzaXu84zRj3duQ}{jY1TxxwdSkaZkQqdsNTGaQ}{192.168.110.133}{192.168.110.133:9302}], reason [RemoteTransportException[[slave2][192.168.110.133:9302][internal:discovery/zen/join]]; nested: NotMasterException[Node [{slave2}{rYUCm8sMRzaXu84zRj3duQ}{jY1TxxwdSkaZkQqdsNTGaQ}{192.168.110.133}{192.168.110.133:9302}] not master for join request]; ], tried [3] times
错误原因:每个节点索引分片的分配在每新增一个节点都要重新进行一次分配。
在home/hadoop/soft/el_slave/elasticsearch-5.4.3-slaver1/data里面有一个nodes文件夹,将该文件夹删除即可。然后重启从节点一,从节点二,问题解决。
1 [elsearch@slaver4 elasticsearch-5.4.3-slaver1]$ ls 2 bin config data hs_err_pid11491.log lib LICENSE.txt logs modules NOTICE.txt plugins README.textile 3 [elsearch@slaver4 elasticsearch-5.4.3-slaver1]$ cd data/ 4 [elsearch@slaver4 data]$ ls 5 nodes 6 [elsearch@slaver4 data]$ rm -rf nodes/ 7 [elsearch@slaver4 data]$ ls
1 [elsearch@slaver4 elasticsearch-5.4.3-slaver2]$ ls 2 bin config data hs_err_pid11491.log lib LICENSE.txt logs modules NOTICE.txt plugins README.textile 3 [elsearch@slaver4 elasticsearch-5.4.3-slaver2]$ cd data/ 4 [elsearch@slaver4 data]$ ls 5 nodes 6 [elsearch@slaver4 data]$ rm -rf nodes/ 7 [elsearch@slaver4 data]$ ls
重新启动三个节点,启动以后如下所示:
注意:elasticsearch 集群搭建起来,为什么head只显示master?(为什么我启动三个es后 head中只显示了一个master节点)。这种问题,我估计就是自己是复制的主节点的,需要将home/hadoop/soft/el_slave/elasticsearch-5.4.3-slaver1/data/nodes,这个nodes文件夹删除,重新生成,我是这样操作的。

Elasticsearch-head插件的web界面效果如下所示:

至此,ElasticSearch的集群版就已经搭建完毕了。ElasticSearch集群的搭建可以使用更多的参数。你可以通过新增更多的参数配置,来实验ElasticSearch集群版的搭建。
1 # ======================== Elasticsearch Configuration ========================= 2 # 3 # NOTE: Elasticsearch comes with reasonable defaults for most settings. 4 # Before you set out to tweak and tune the configuration, make sure you 5 # understand what are you trying to accomplish and the consequences. 6 # 7 # The primary way of configuring a node is via this file. This template lists 8 # the most important settings you may want to configure for a production cluster. 9 # 10 # Please consult the documentation for further information on configuration options: 11 # https://www.elastic.co/guide/en/elasticsearch/reference/index.html 12 # 13 # ---------------------------------- Cluster ----------------------------------- 14 # 15 # Use a descriptive name for your cluster: 16 # 17 18 # 1、修改这里,是修改集群的名称,如果想将节点加入到集群中,所有节点都必须是这个名称的。 19 # cluster.name: my-application 20 21 22 # 23 # ------------------------------------ Node ------------------------------------ 24 # 25 # Use a descriptive name for the node: 26 # 27 28 # 2、给节点起一个名称。默认node-1 29 #node.name: node-1 30 31 32 # 33 # Add custom attributes to the node: 34 # 35 #node.attr.rack: r1 36 # 37 # ----------------------------------- Paths ------------------------------------ 38 # 39 # Path to directory where to store the data (separate multiple locations by comma): 40 # 41 42 # 3、path.data是存储的数据的路径 43 #path.data: /path/to/data 44 45 46 # 47 # Path to log files: 48 # 49 50 # 4、path.logs是es运行产生的日志文件, 51 #path.logs: /path/to/logs 52 53 54 # 55 # ----------------------------------- Memory ----------------------------------- 56 # 57 # Lock the memory on startup: 58 # 59 #bootstrap.memory_lock: true 60 # 61 # Make sure that the heap size is set to about half the memory available 62 # on the system and that the owner of the process is allowed to use this 63 # limit. 64 # 65 # Elasticsearch performs poorly when the system is swapping the memory. 66 # 67 # ---------------------------------- Network ----------------------------------- 68 # 69 # Set the bind address to a specific IP (IPv4 or IPv6): 70 # 71 #network.host: 192.168.0.1 72 73 # 5、绑定的ip地址和默认端口号9200 74 # network.host: 0.0.0.0 75 76 77 78 # 下面这些配置是我自己加的,上面或者下面标数字的都是默认的。 79 80 # 是否支持跨域 81 http.cors.enabled: true 82 # 83 # *表示支持所有域名 84 http.cors.allow-origin: "*" 85 86 # 指定集群的名称 87 cluster.name: biehl01 88 # 给master起一个名称,叫master 89 node.name: master 90 # 告诉此节点,它就是master 91 node.master: true 92 # 绑定的ip地址和默认端口号9200 93 network.host: 192.168.110.133 94 95 discovery.zen.minimum_master_nodes: 2 96 discovery.zen.ping.unicast.hosts: ["192.168.110.133"] 97 98 99 # 100 # Set a custom port for HTTP: 101 # 102 103 # 6、默认端口号是9200的。 104 # http.port: 9200 105 106 107 108 # 7、Discovery服务发现,配置集群的话,是需要进行修改的。 109 110 111 # 112 # For more information, consult the network module documentation. 113 # 114 # --------------------------------- Discovery ---------------------------------- 115 # 116 # Pass an initial list of hosts to perform discovery when new node is started: 117 # The default list of hosts is ["127.0.0.1", "[::1]"] 118 # 119 120 # 8、集群里面的节点都需要加到里面,如果是伪集群的话,可以使用ip:端口号或者主机名称的形式加进去的,如果是非伪集群,可以直接使用ip:port或者主机名称加进去。 121 # 注意,这里面加的主机节点,是有机会进行选举主节点的,其他未加进去,没有机会进行选择主节点的机会的。 122 #discovery.zen.ping.unicast.hosts: ["host1", "host2"] 123 # 124 # Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1): 125 # 126 127 # 9、主节点数/ 2 + 1,此值是这样计算的,上面的注释也说明了。此值是为了阻止没有节点做主节点或者都做子节点的情况发生。避免出现脑裂。 128 # 默认值是3,这样才可以选出主节点的。那么这就需要注意了,你的主节点数至少是4的,不然无法正常选举。通过配置这个参数来防止集群脑裂现象 (集群总节点数量/2)+1 129 #discovery.zen.minimum_master_nodes: 3 130 131 132 # 133 # For more information, consult the zen discovery module documentation. 134 # 135 136 137 138 # ---------------------------------- Gateway ----------------------------------- 139 # 140 # Block initial recovery after a full cluster restart until N nodes are started: 141 # 142 #gateway.recover_after_nodes: 3 143 # 144 # For more information, consult the gateway module documentation. 145 # 146 # ---------------------------------- Various ----------------------------------- 147 # 148 # Require explicit names when deleting indices: 149 # 150 #action.destructive_requires_name: true
4、elasticsearch的基础概念总结:
1)、elasticsearch集群:elasticsearch集群是由一个或者多个节点组成的集合。每一个集群都有一个唯一的名称。默认是elasticsearch,我们可以自己设置的cluster_name的值,cluster_name的值非常重要,一个节点就是通过集群的名称加入集群的。然后,每一个节点都有自己的名称。节点是可以存储数据,参与集群索引数据,以及搜索数据的独立服务。
2)、索引,是含有相同属性的文档集合。
3)、类型,索引可以定义一个或者多个类型,文档必须属于一个类型。
4)、文档,文档是可以被索引的基本数据单位。索引在elasticsearch中是通过一个名称来识别的,必须是英文字母小写的,且不含中划线的,我们通过这个索引来对文档进行增删查改的操作。
5)、索引、类型、文档之间的关系,索引相当于数据库里面的database即数据库,类型相当于数据库里面的table即数据表,文档相当于数据库SQL里面的一行记录。
6)、分片,每个索引都有多个分片,每个分片是一个Lucene索引。
7)、备份,拷贝一份分片就完成了分片的备份。
注意:elasticsearch在创建索引的时候,默认创建5个分片,一份备份,这个数据可以进行修改。分片的数量只能在创建索引的时候进行指定,不能在后期进行修改,备份可以进行动态修改的。
5、Elasticsearch的基本用法,基本操作,基本使用。
elasticsearch是以RESTFul api风格来命名自己的api的。api的基本格式,http://<ip地址>:<port端口号>/<索引>/<类型>/<文档id>
注意:api的url里面的元素基本都是elasticsearch的基本概念都是名词,elasticsearch的动作都是常用http动词get/put/post/delete来决定的。
6、索引的创建分为非结构化创建("mappings": { }的json格式值是空的)、结构化创建("mappings": { }的json格式值非空的)。
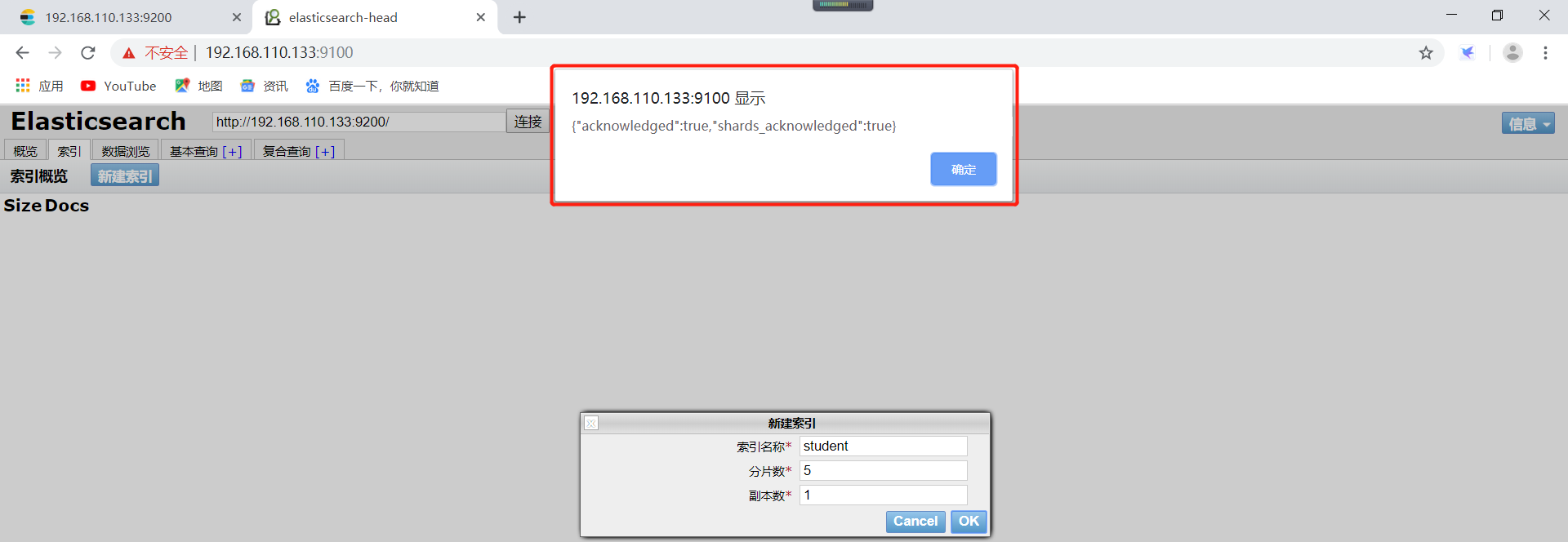
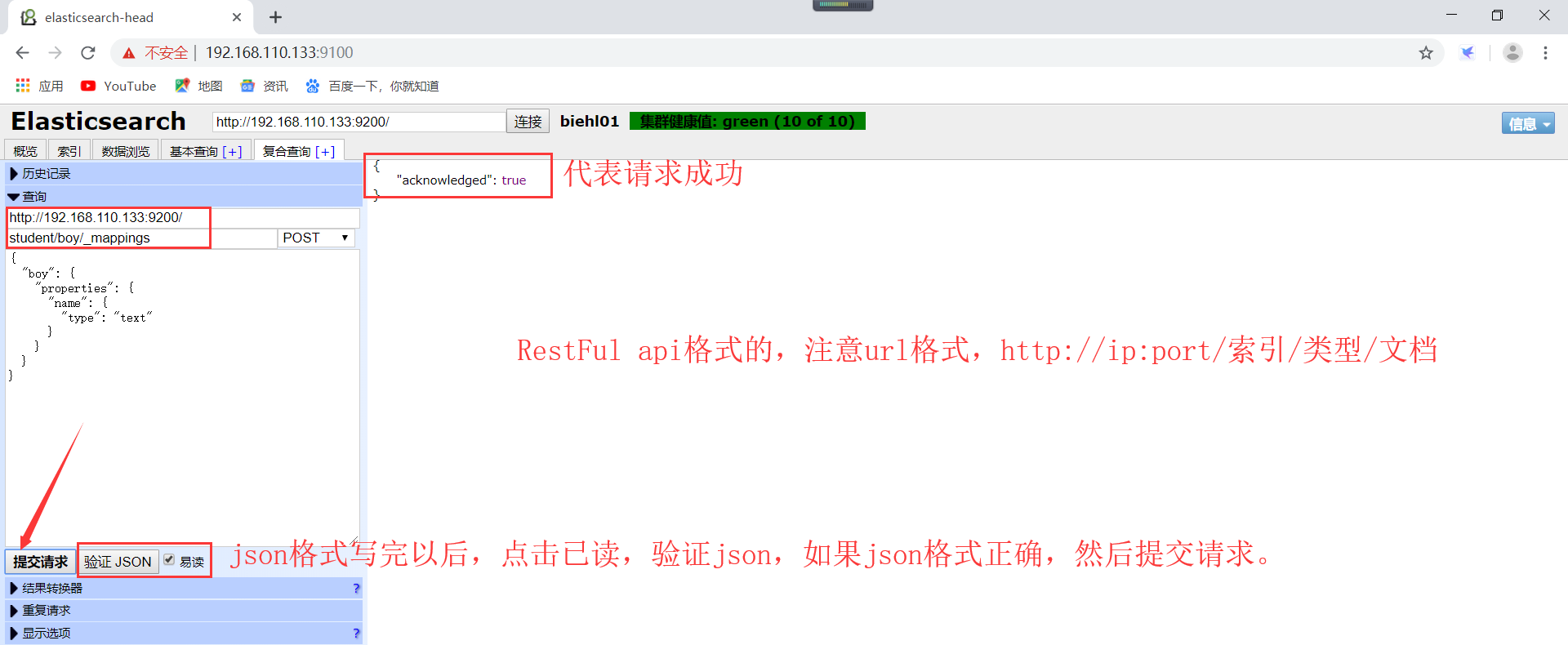
1)、创建非结构化索引,操作如下所示(注意:这里使用head插件进行创建非结构化索引的哦):

创建完毕以后可以看到一个弹出框,表示创建成功了。
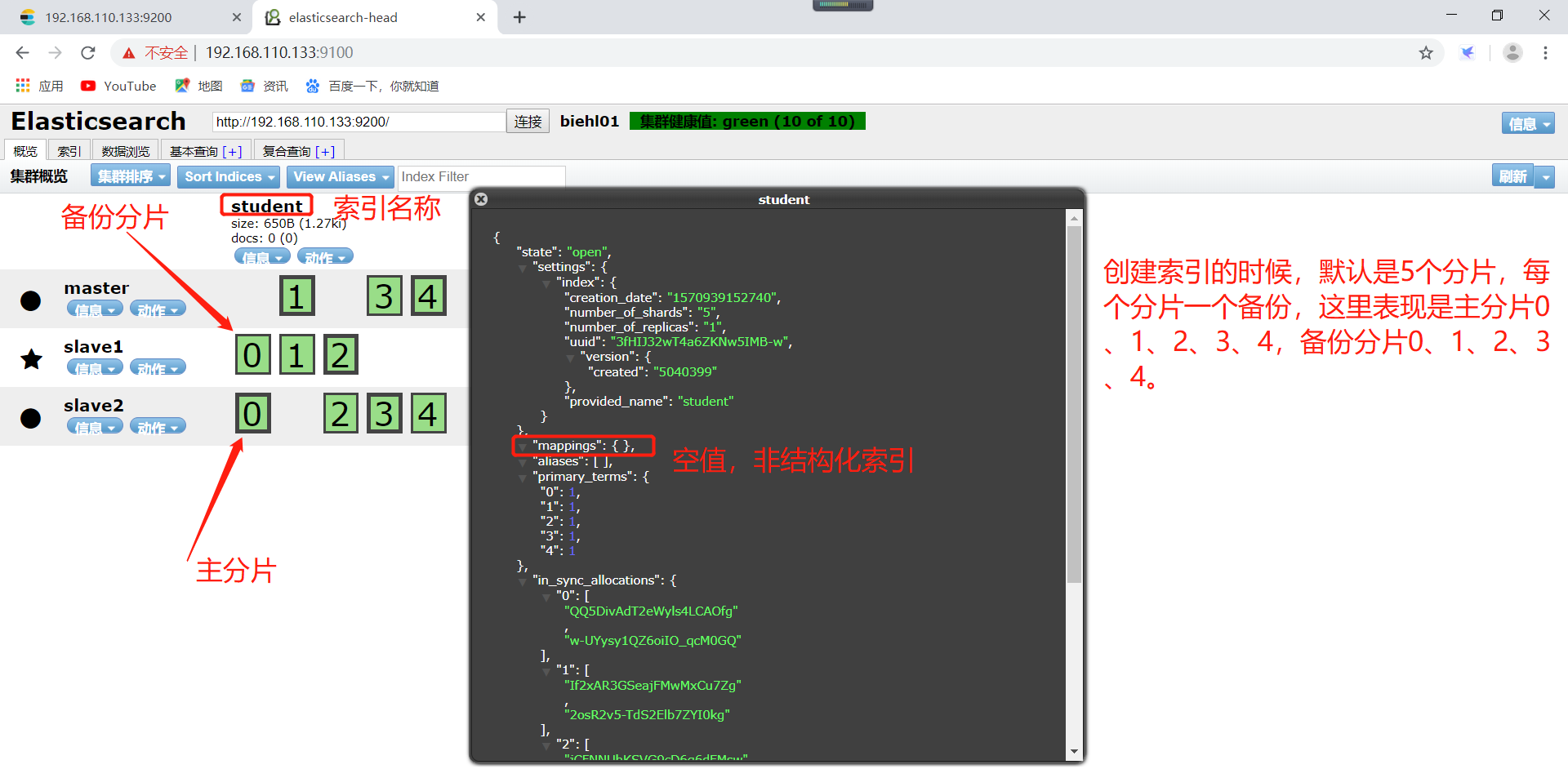
创建的索引,在概览可以看到自己创建的索引了,student是创建的索引的名称(切记,索引名称小写,不可以出现中划线)。每一个方框就是elasticsearch的分片,粗线方框是es的主分片,主分片旁边细线方框是es的备份分片,对应关系,粗线方框0的备份分片是细线方框0。依次类推。
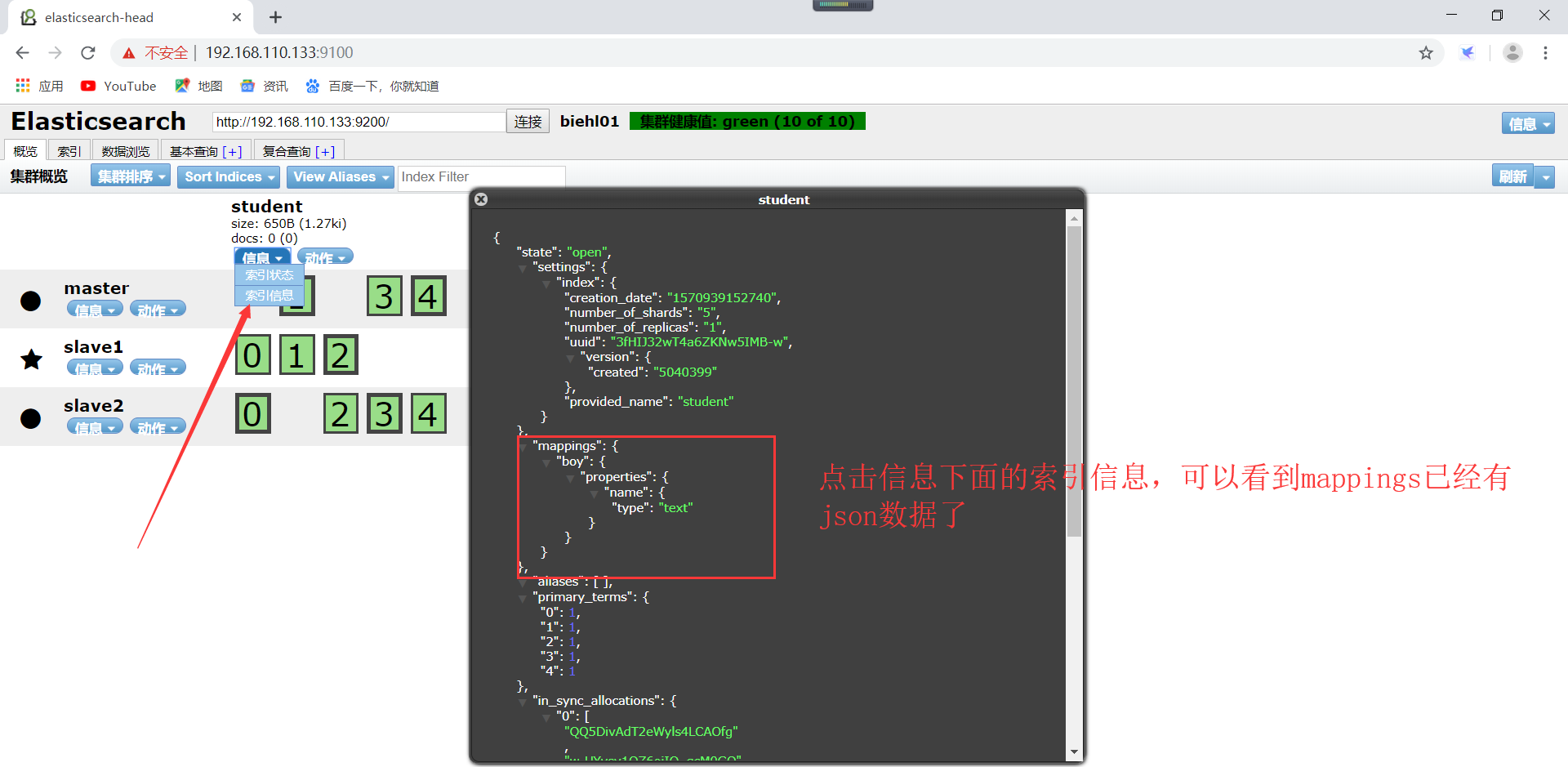
2)、创建非结构化索引,操作如下所示(注意:这里使用head插件进行创建结构化索引的哦):
查看创建的结构化索引,如下所示(修改了记得点击刷新哦):
postman是一个拥有可视化界面的http模拟器,可以验证json结构。之前介绍过,这里简单使用一下。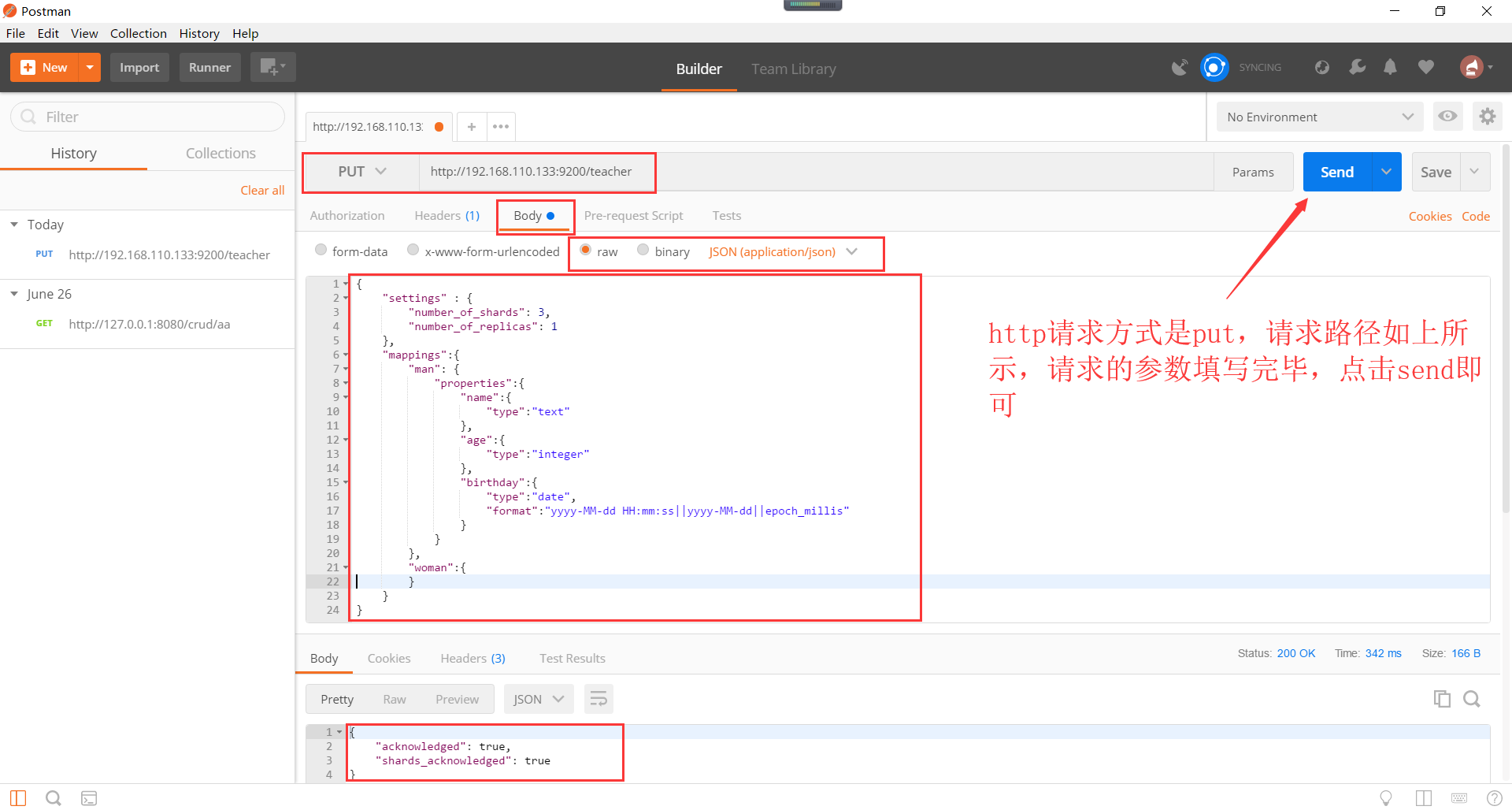
现在查看一下新创建的索引,如下所示:
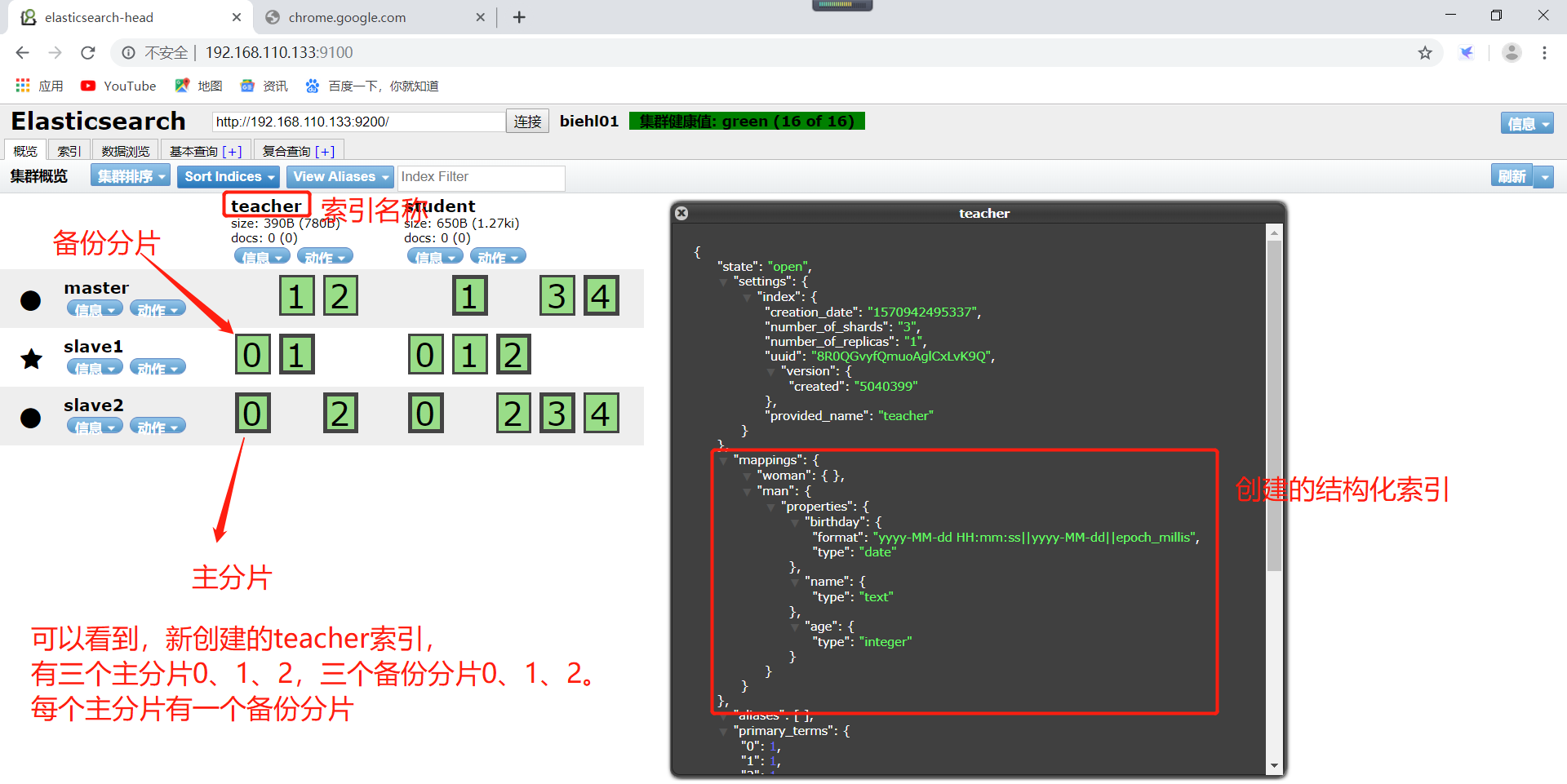
7、es的索引创建完毕以后就可以进行es的数据插入。插入分为指定文档id插入和自动产生文档id插入。文档id是什么呢,文档id是一个唯一索引值,指向我们的文档数据。
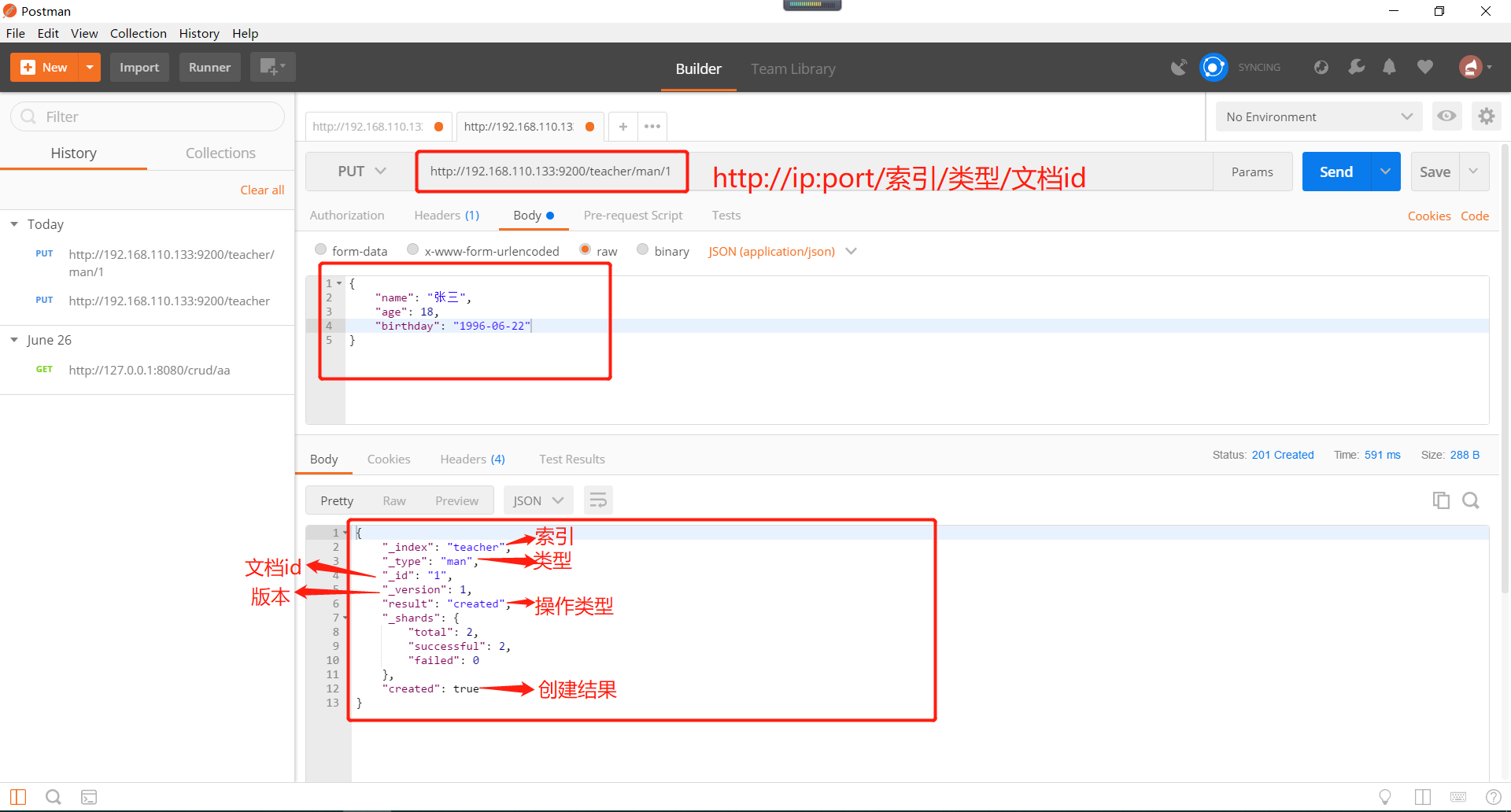
在head插件概览里面查看docs的变化,docs代表了该索引下所有文档的数量值。
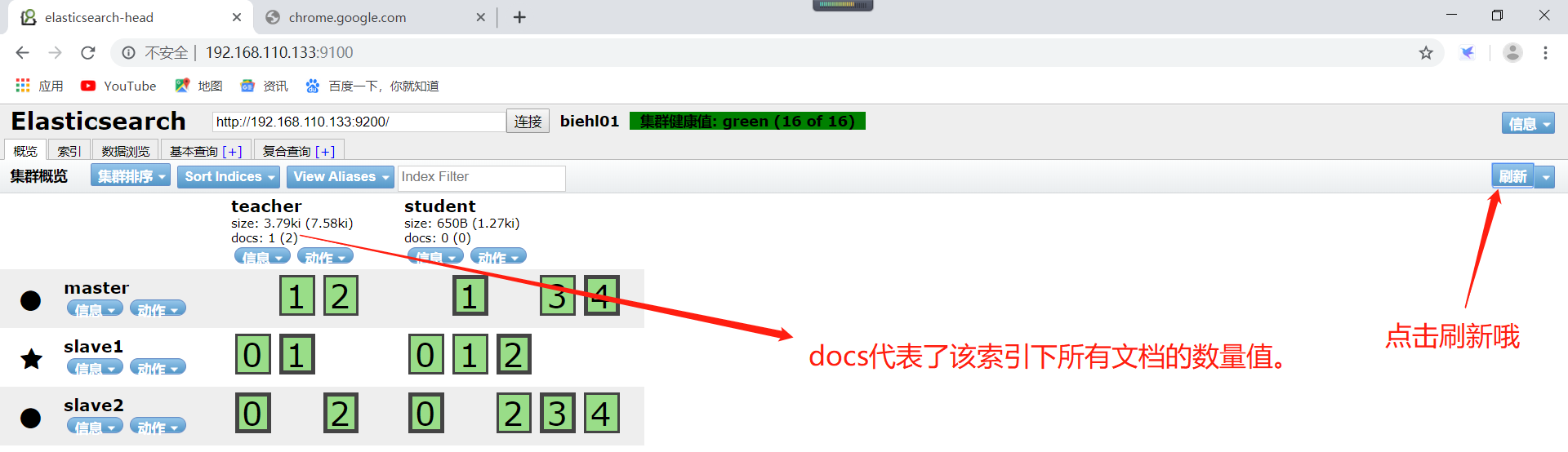
在head插件的数据浏览可以看到刚才插入的一条数据的。
如何让es自动指定文档id呢。如下所示:
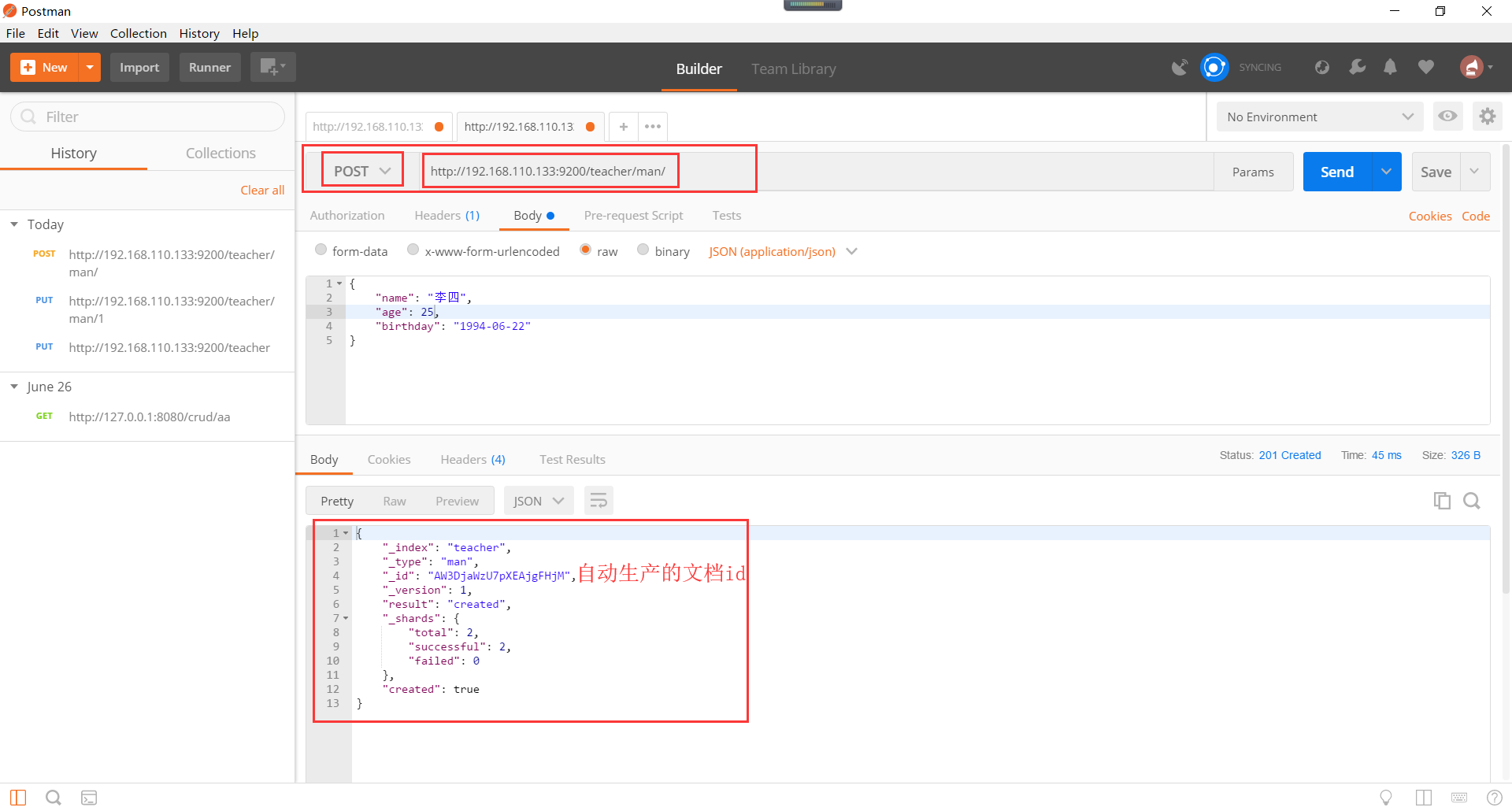
自己可以去head插件的概述和数据浏览进行查看,这里仅展示了数据浏览的数据。如下所示:
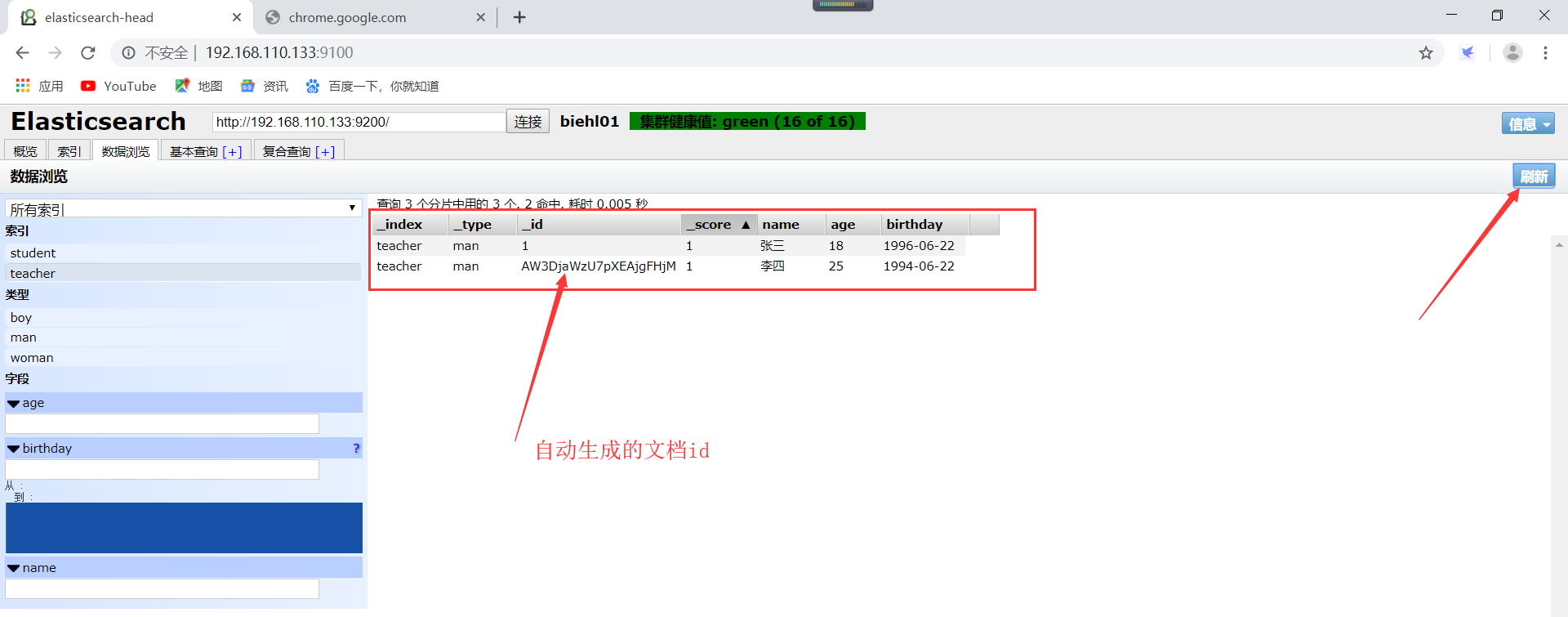
8、修改Elasticsearch的文档数据。分为直接修改文档、通过脚本修改文档。
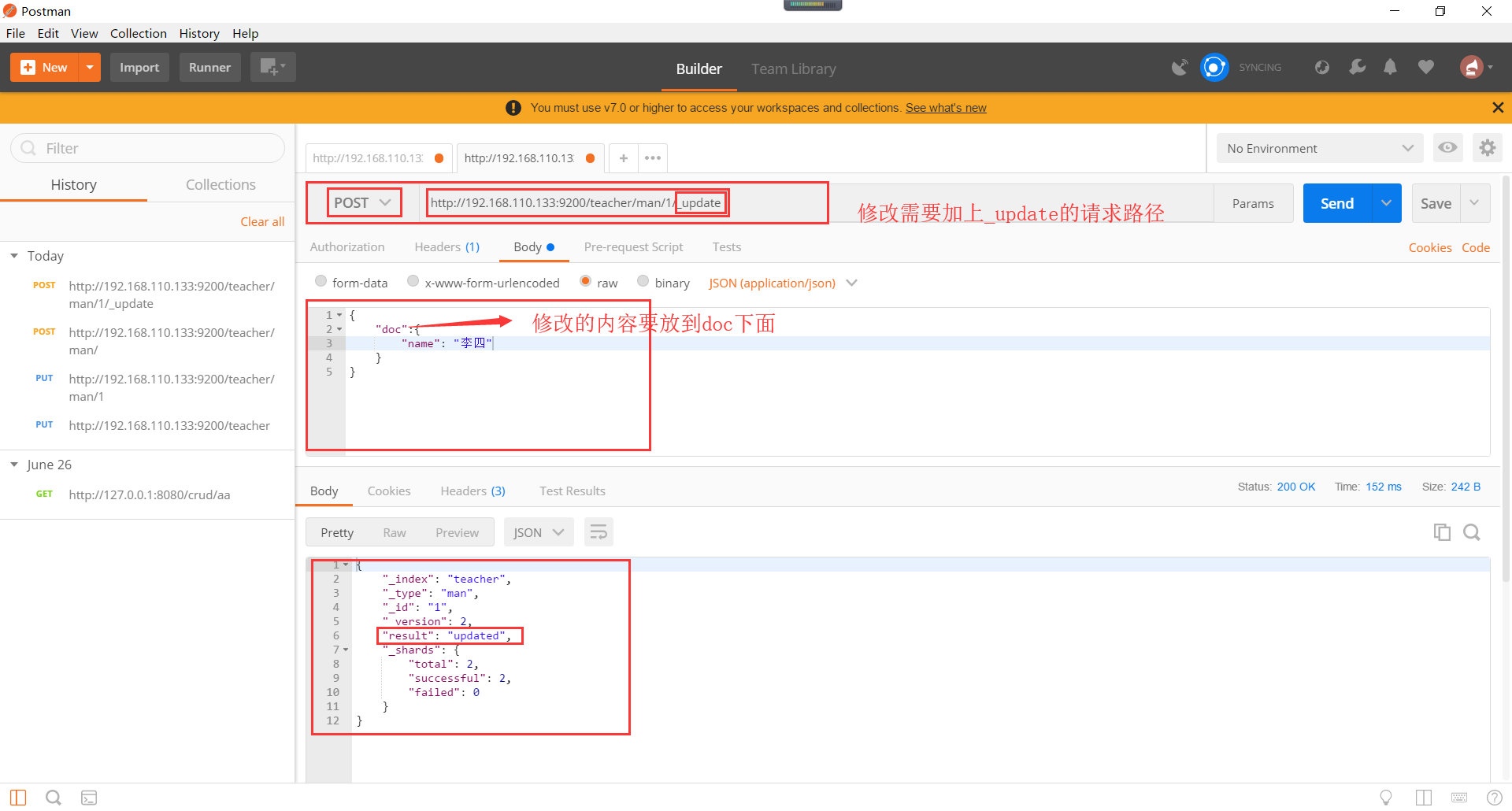
这种通过指定文档id进行直接修改的效果如下所示:
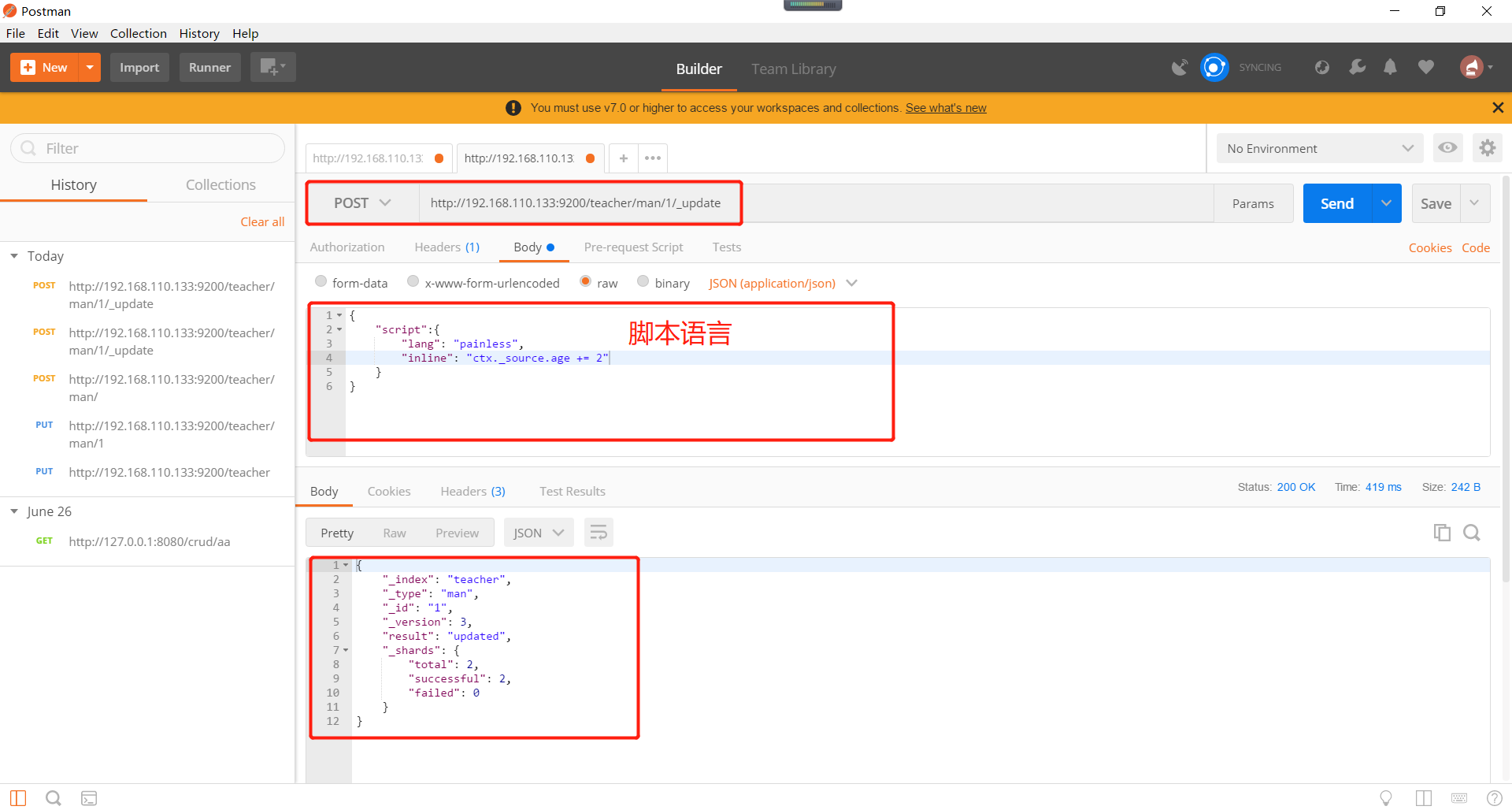
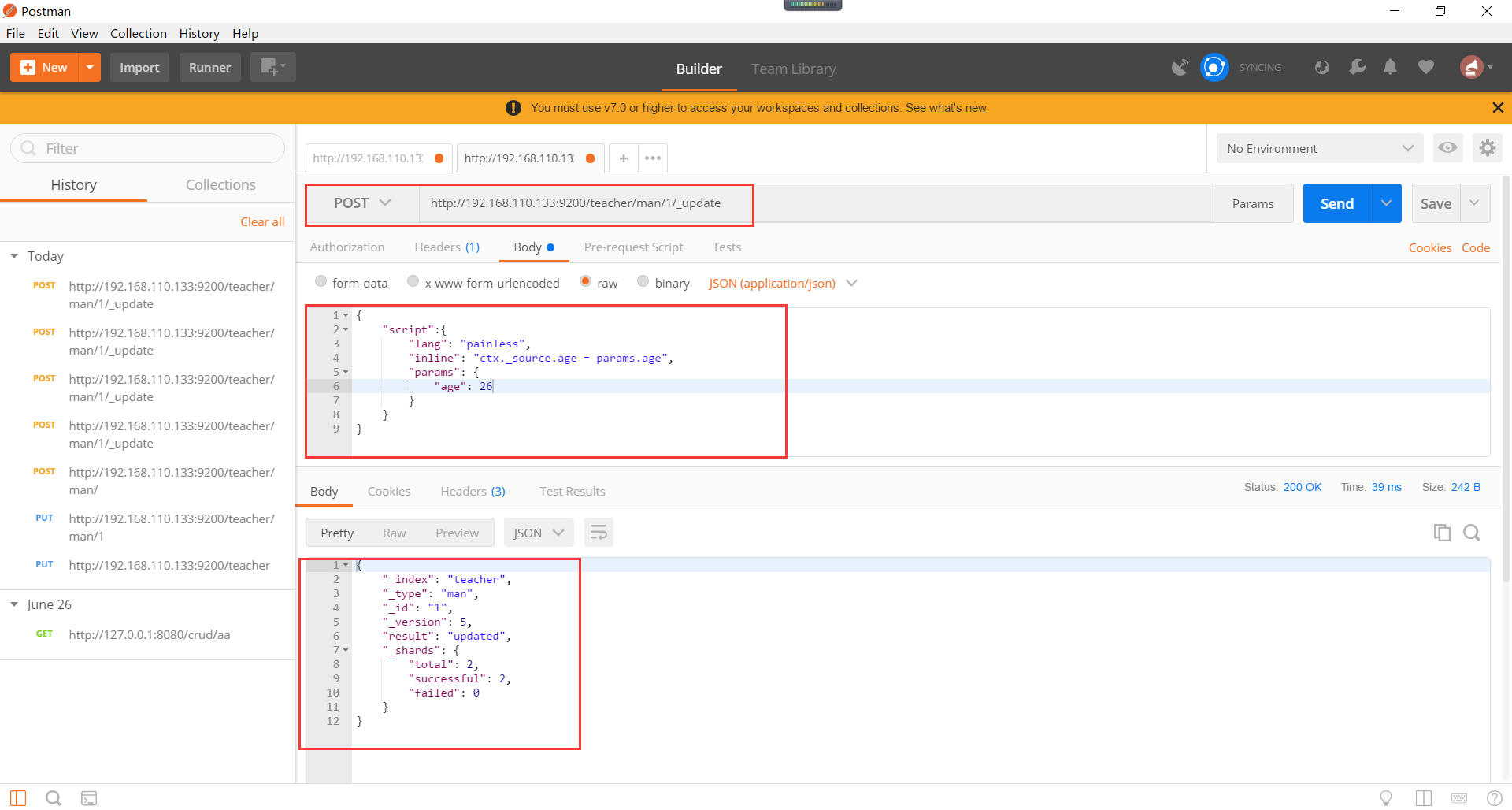
通过脚本修改文档。操作如下所示:
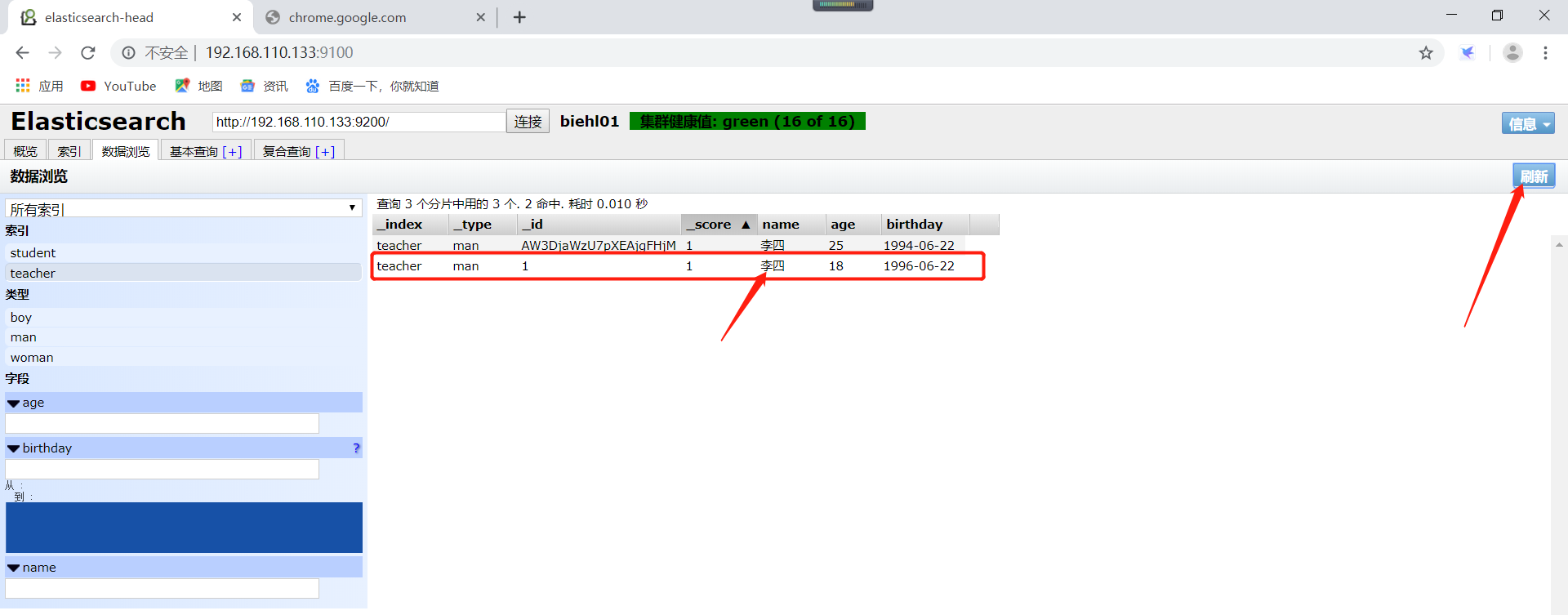
不同的方式,请求成功以后自己使用head查看效果即可。
9、删除Elasticsearch的文档、删除Elasticsearch的索引。
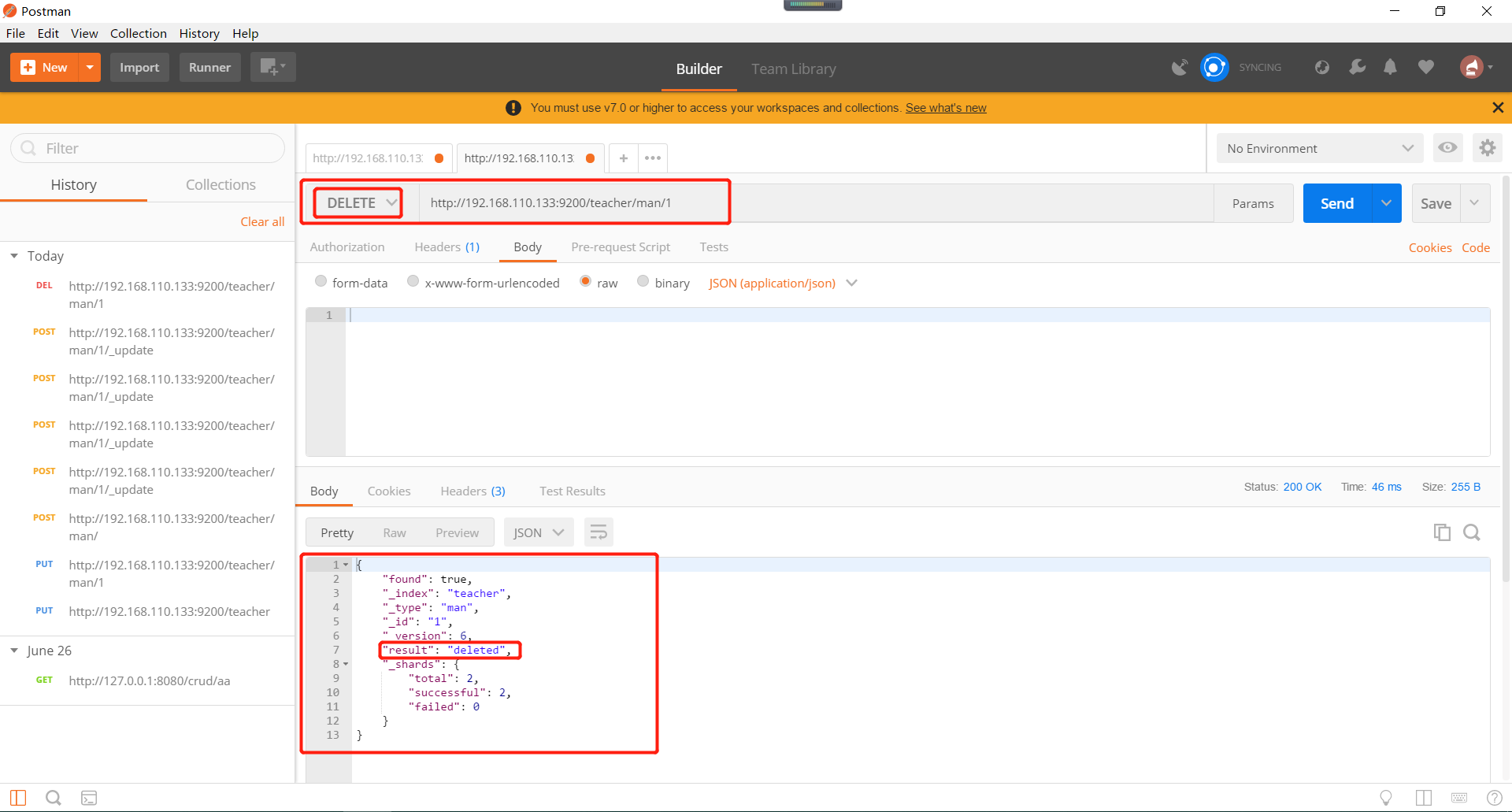
删除以后发现数据已经被删除了。
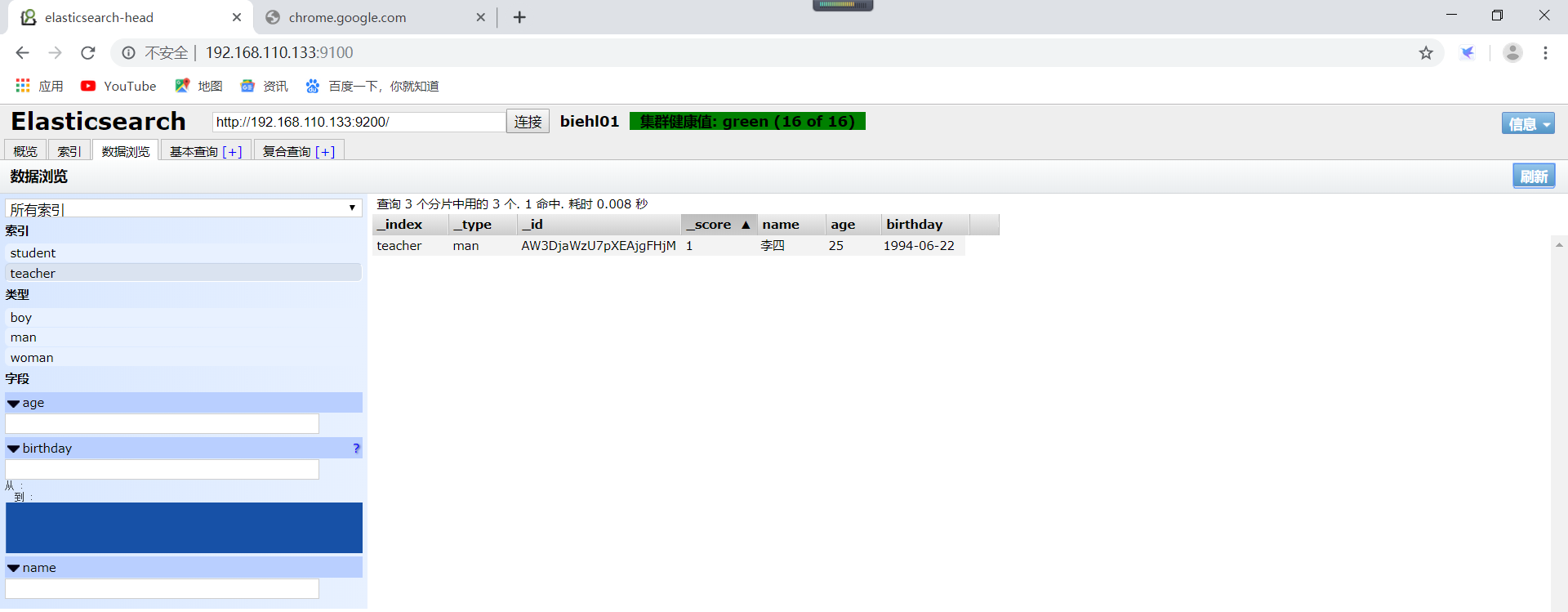
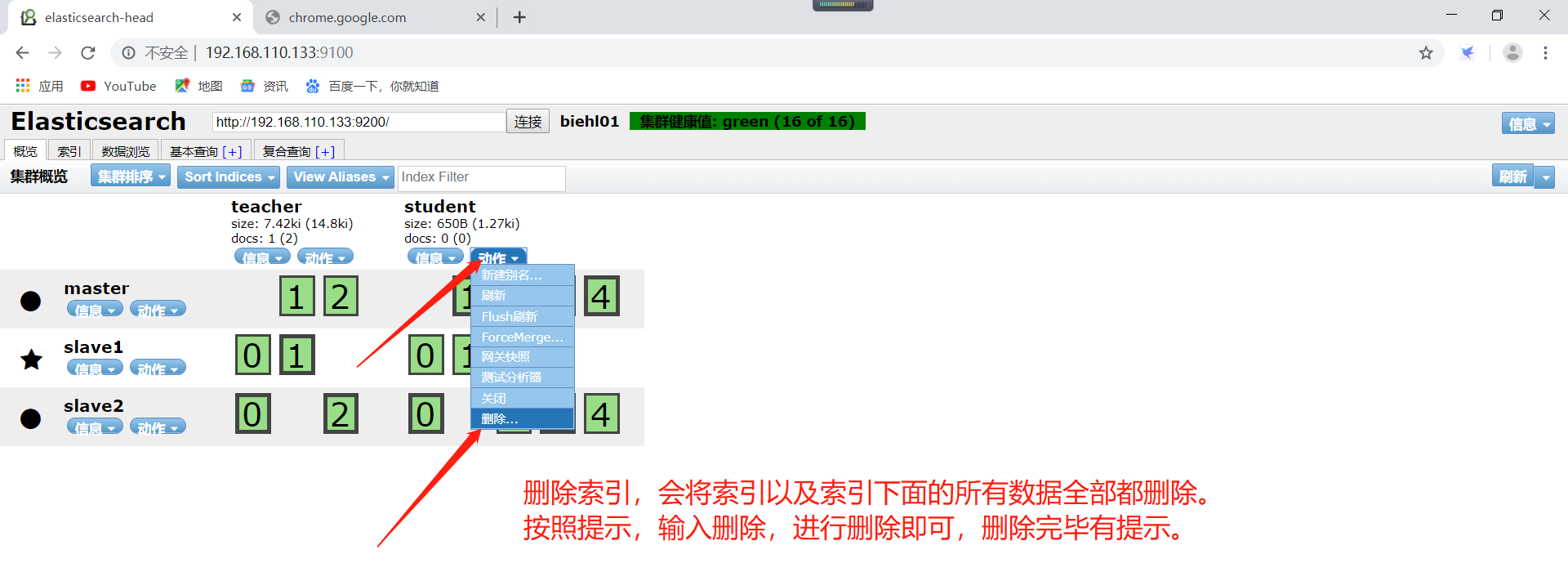
如何删除一个索引呢,可以直接使用head插件进行删除即可。也可以使用请求删除索引。
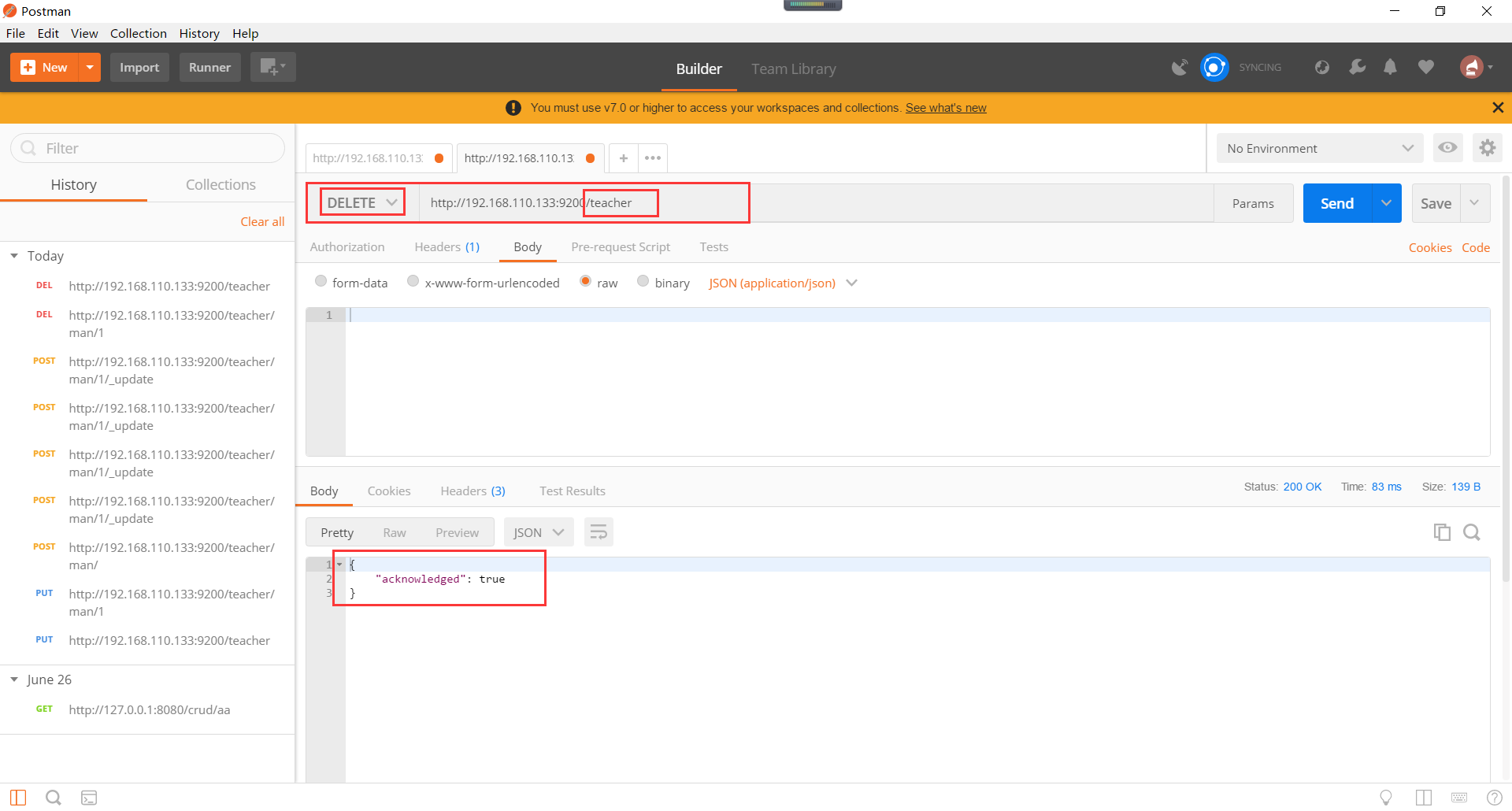
使用postman的http请求删除索引,如下所示(注意:删除索引,是高危操作,索引删除,其下的数据也将全部删除):
10、Elasticsearch的查询,分为简单查询,条件查询,聚合查询。(注意:Elasticsearch的查询才是重中之重哦!)。
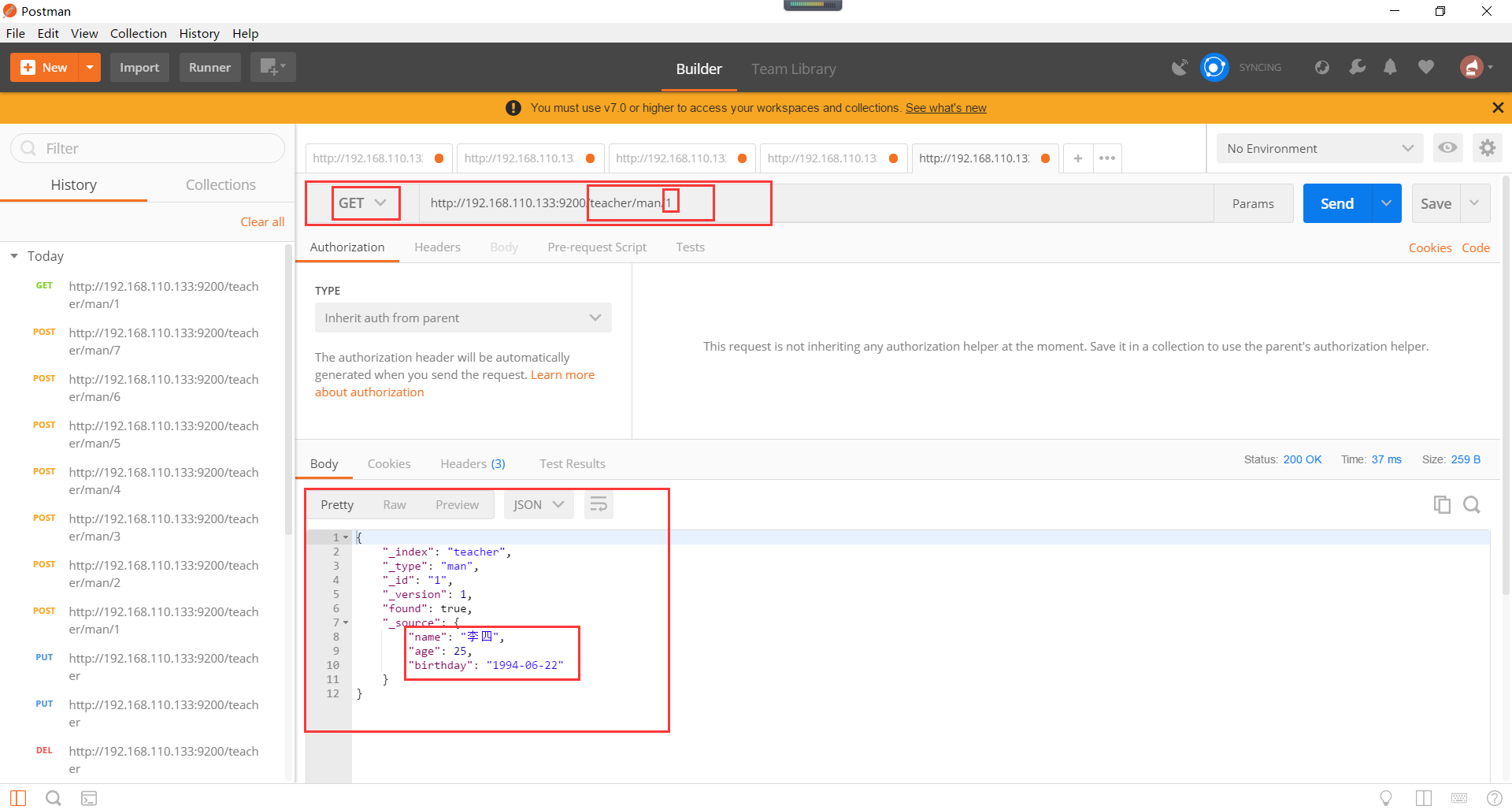
Elasticsearch的条件查询如下所示:

如何对Elasticsearch查询进行关键词的查询。查询出的数据顺序,以_score字段进行默认倒排的。

查询出的数据顺序,以_score字段进行默认倒排的。如何指定数据显示的顺序呢,如下所示:
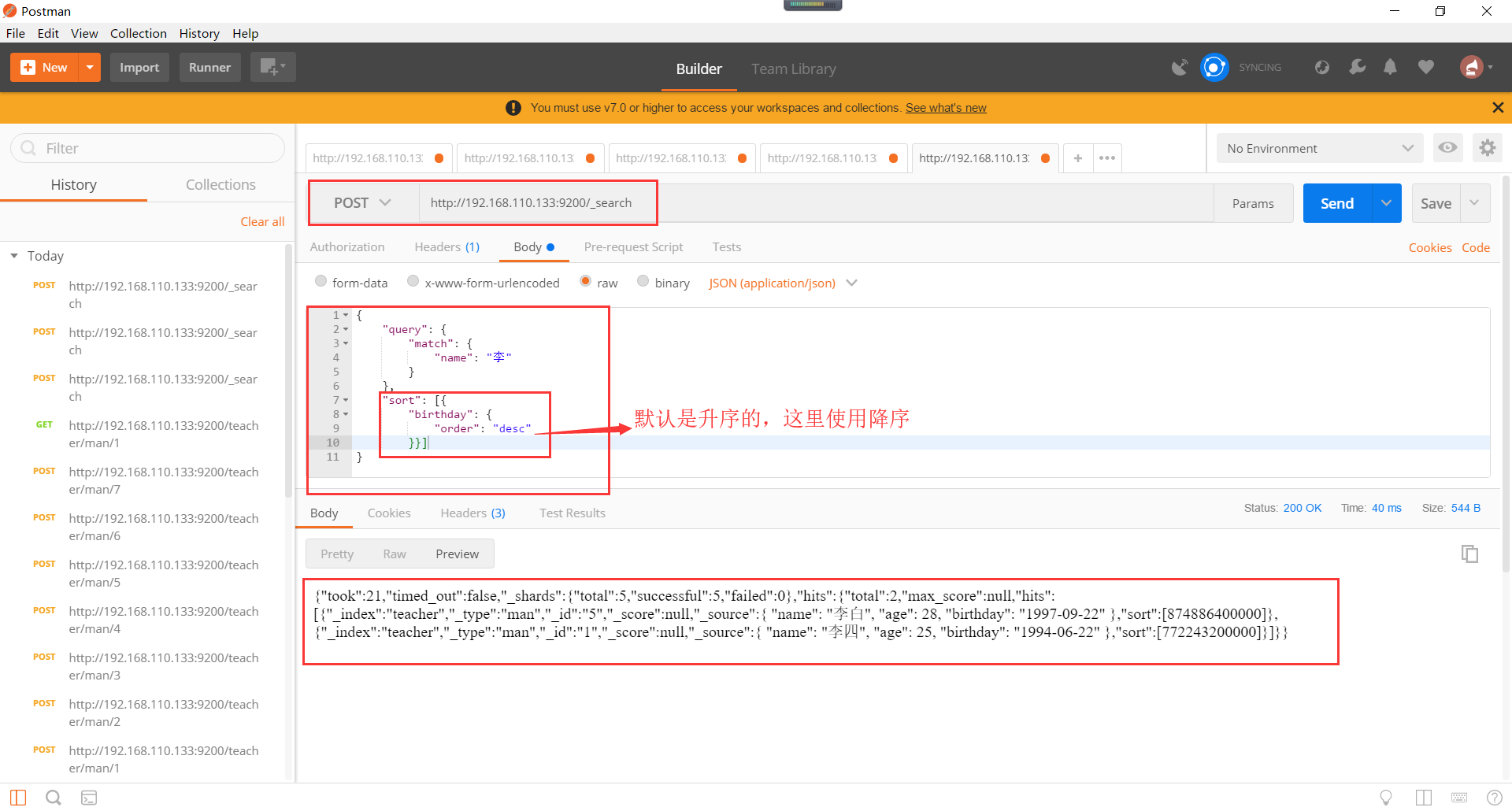
Elasticsearch聚合查询如下所示:
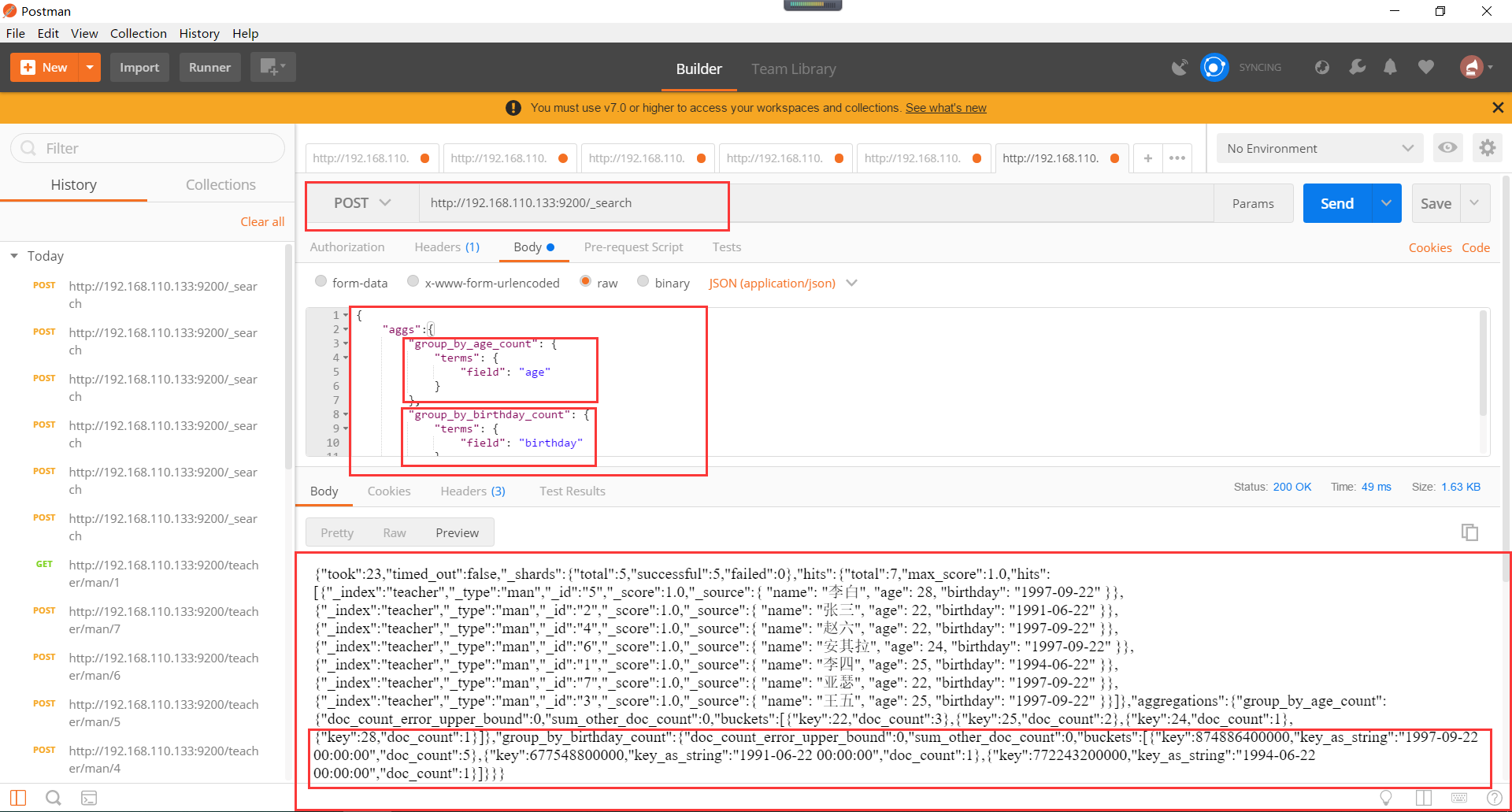
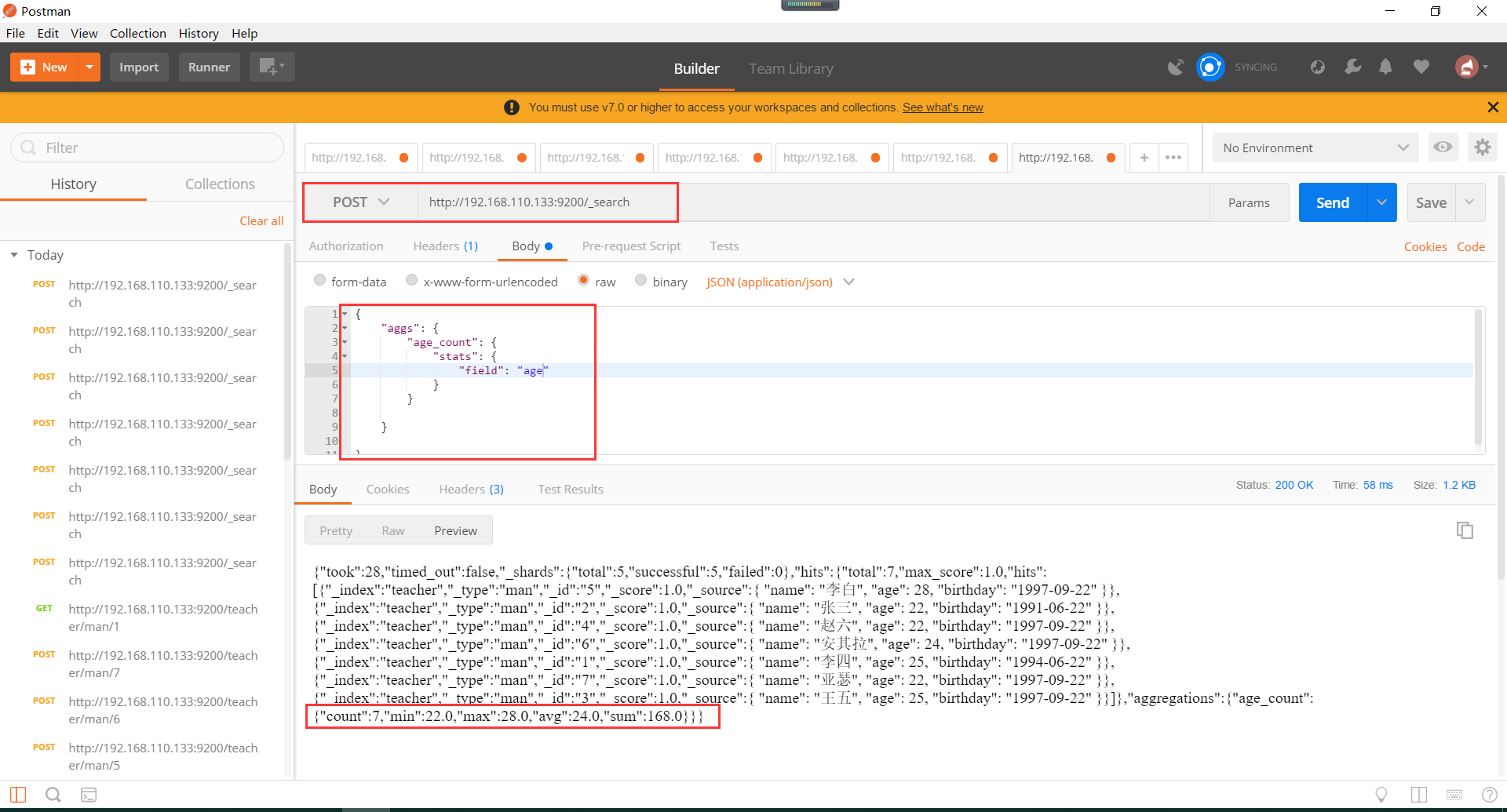
复杂的聚合函数使用如下所示,可以计算最小值,平均值,最大值等等:
11、Elasticsearch的高级查询。高级查询包含子条件查询(也叫做叶子条件查询),指特定字段查询所指特定值。复合条件查询,指以一定的逻辑组合子条件查询。子条件查询包含Query context、Filter context。
1)、Query context是指在查询过程中,除了判断文档是否满足查询条件外,es还会计算一个_score来标识匹配的程度,旨在判断目标文档和查询条件匹配的有多好。Query context常用查询,包含全文本查询,即针对文本类型数据。字段级别查询,针对结构化数据,如数字、日期等等。全文本查询有模糊匹配,短语匹配,多个字段的匹配查询,以及语法的查询等等。
模糊匹配查询,如下所示,但是模糊匹配有一个缺点,就是比如模糊查询"java入门",会查询出"java高级编程","elasticsearch入门"等等这些词语。
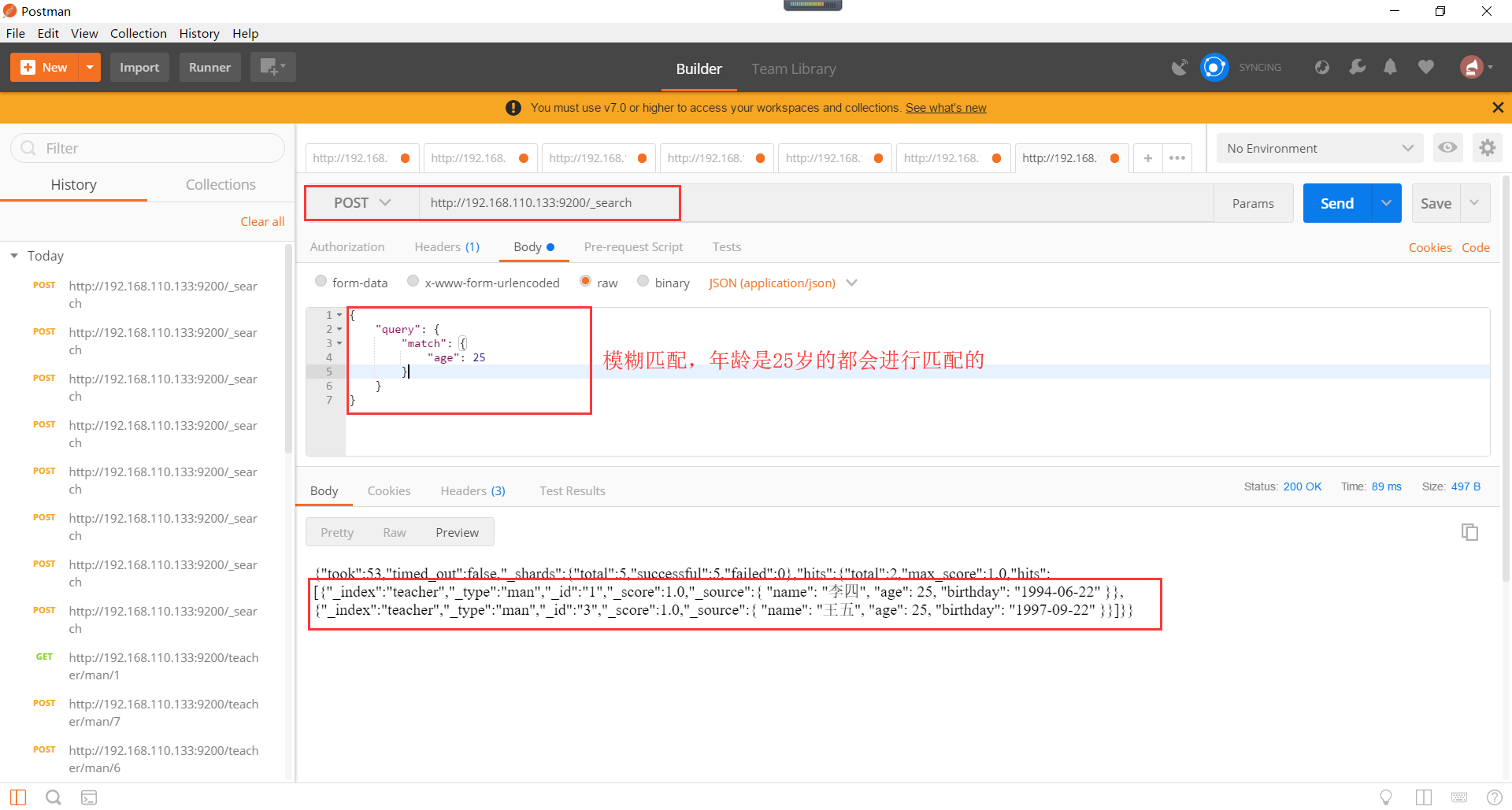
Elasticsearch短语匹配如下所示:
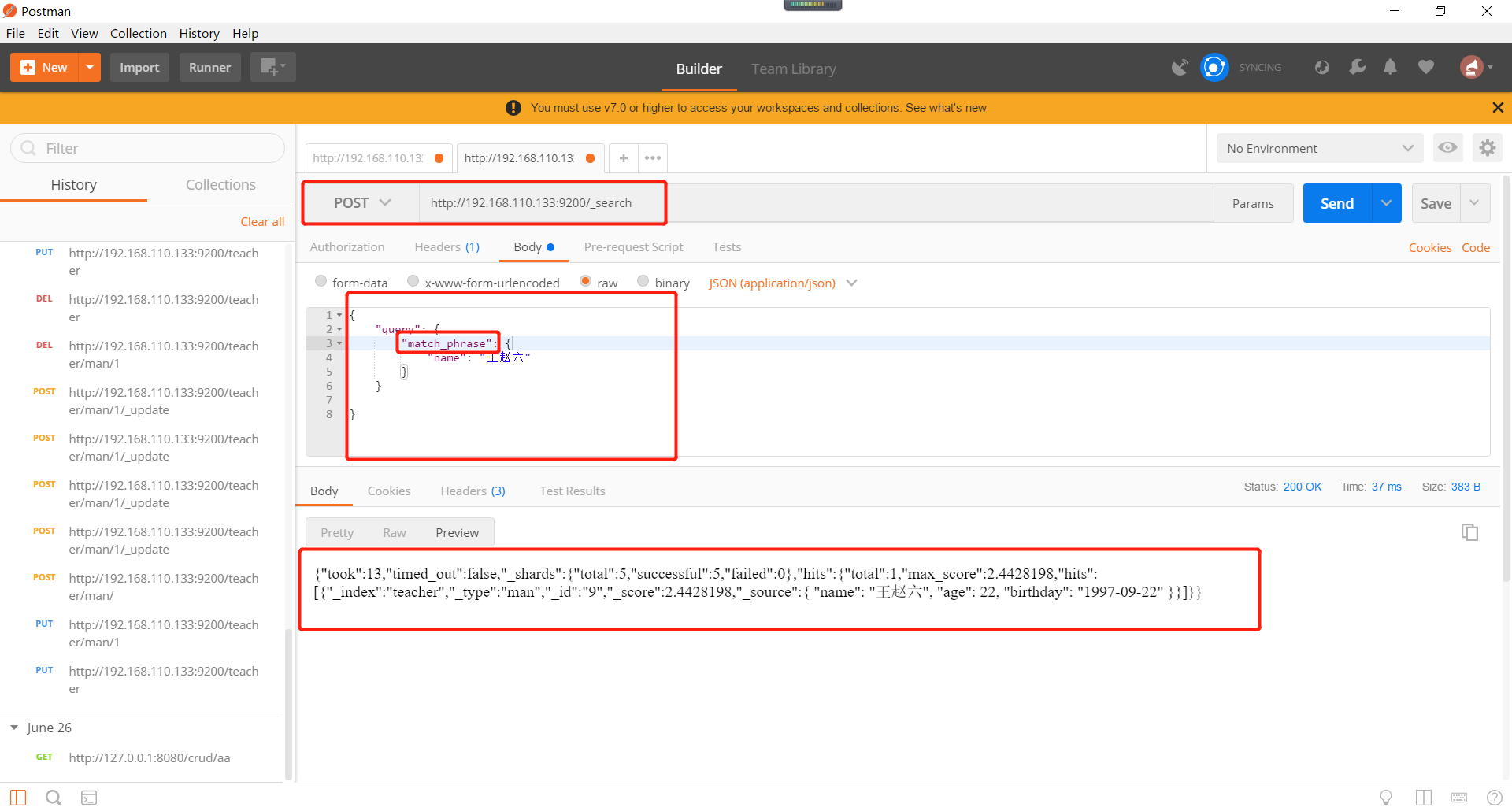
Elasticsearch多字段模糊匹配查询。
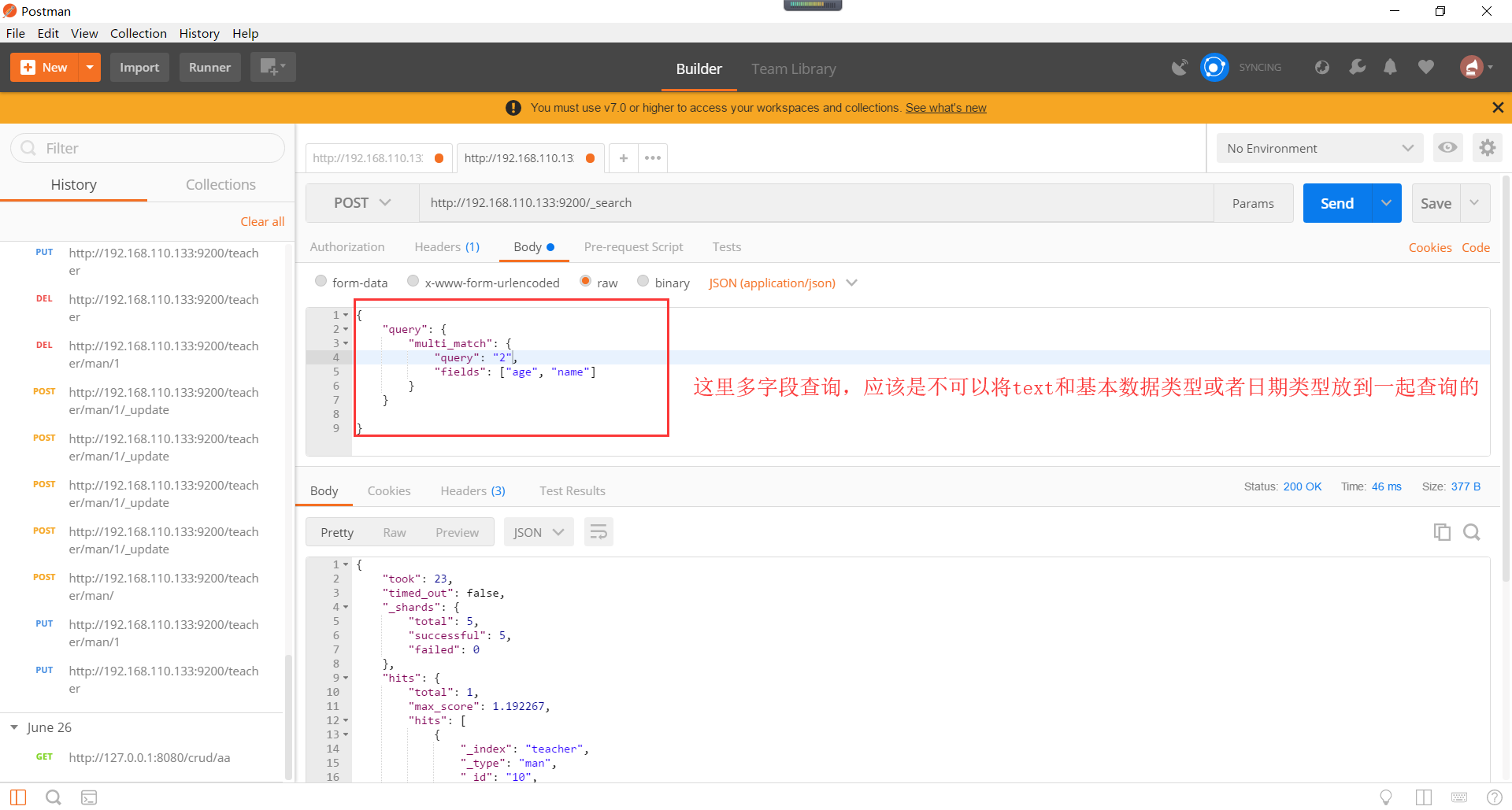
Elasticsearch语法查询。语法查询,是根据一定的语法规则进行的查询,一般用作数据搜索,支持通配符,boolean查询,范围查询,正则表达式查询。
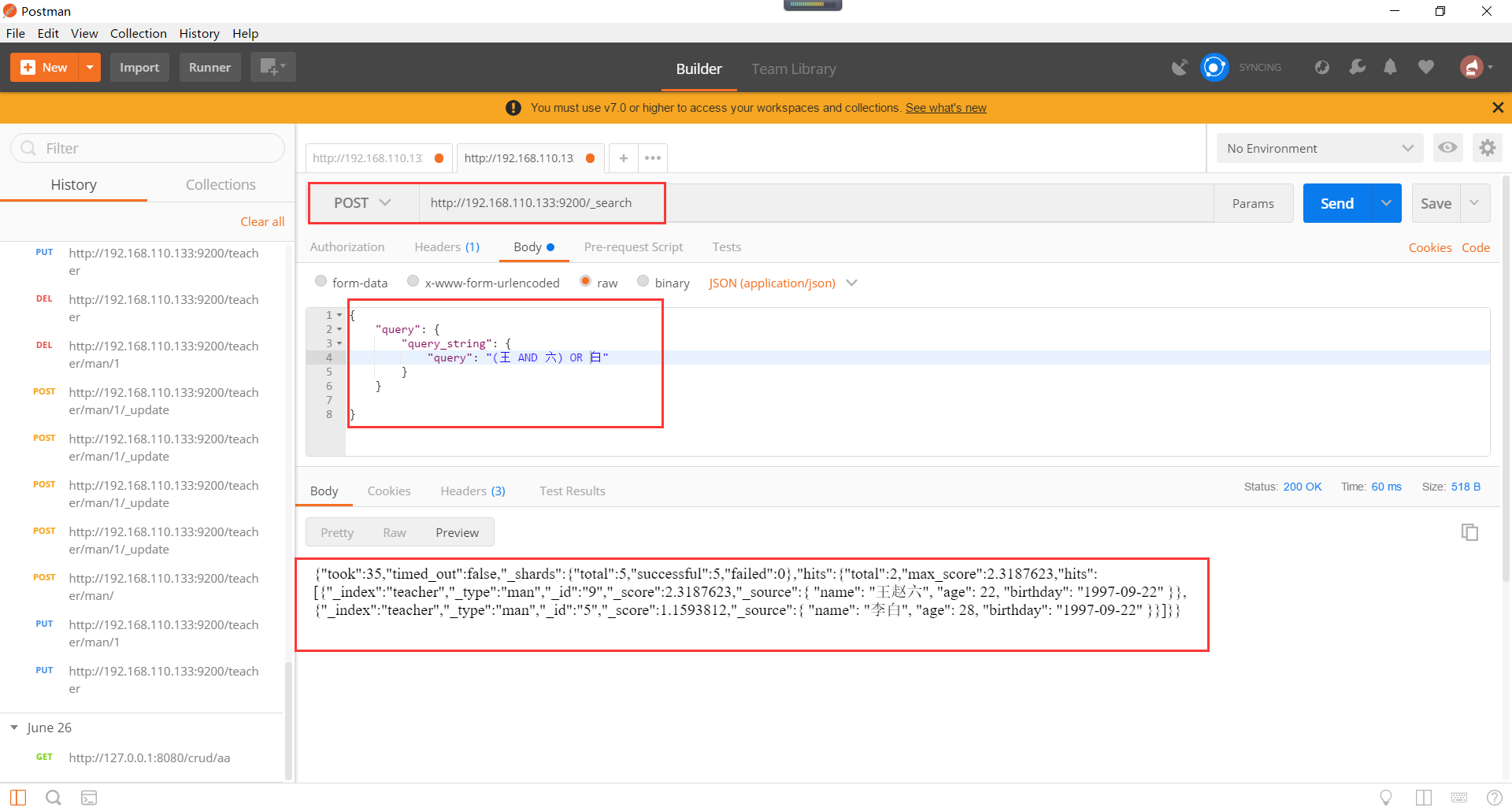
语法查询的多字段查询如下所示:
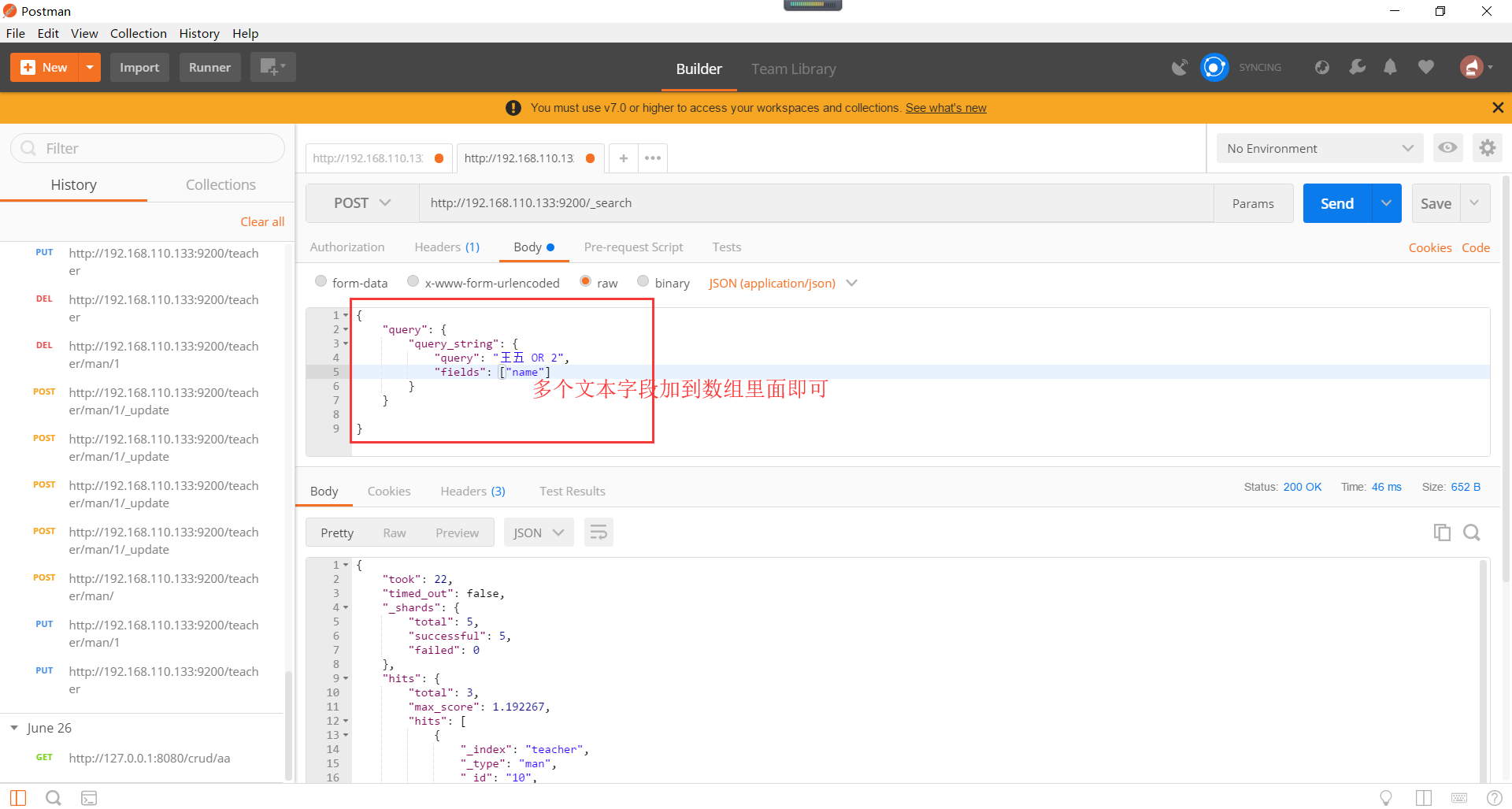
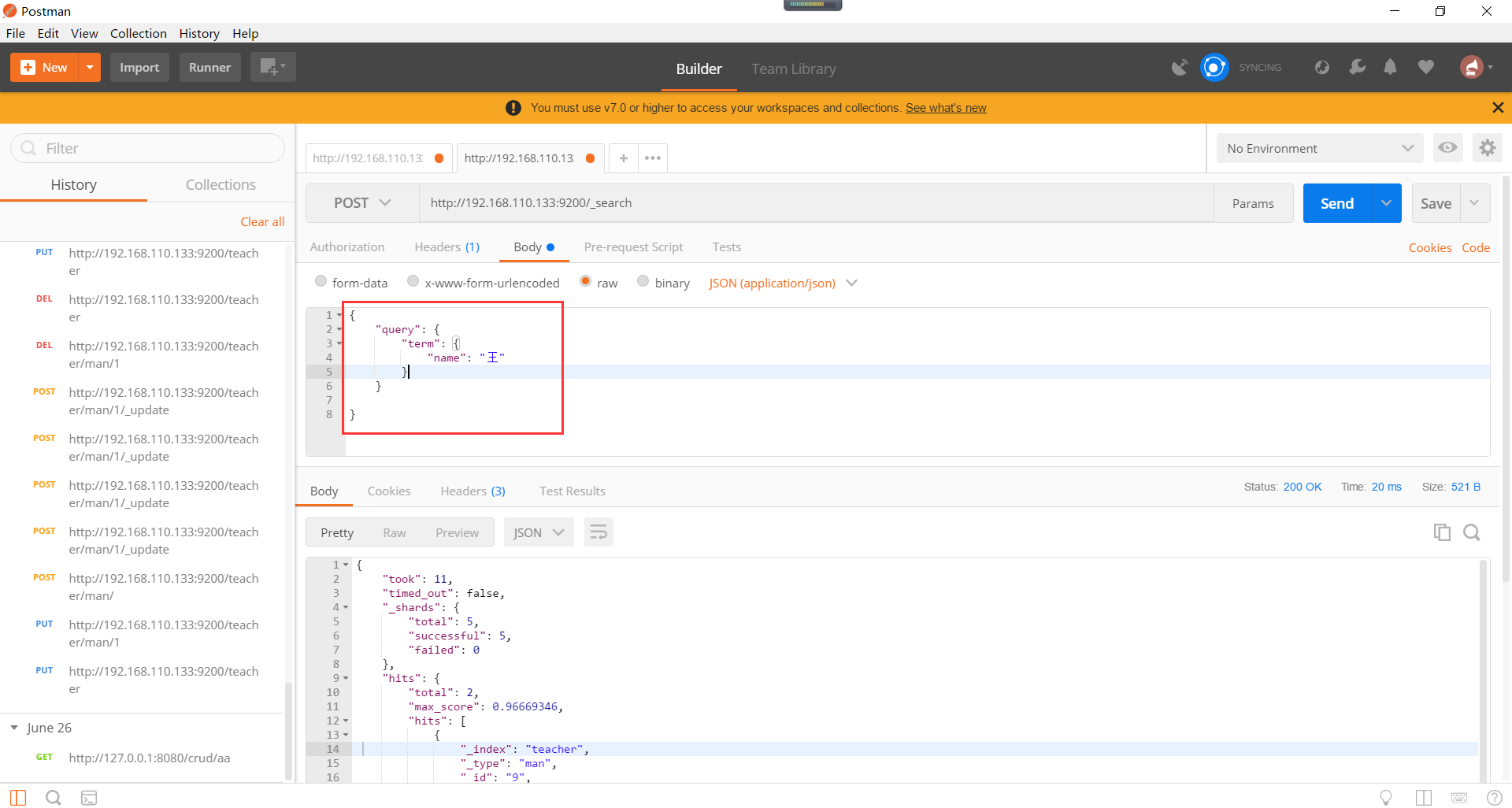
Elasticsearch字段的查询,即结构化数据的查询。term是具体项的含义,range是范围的含义。如下所示:
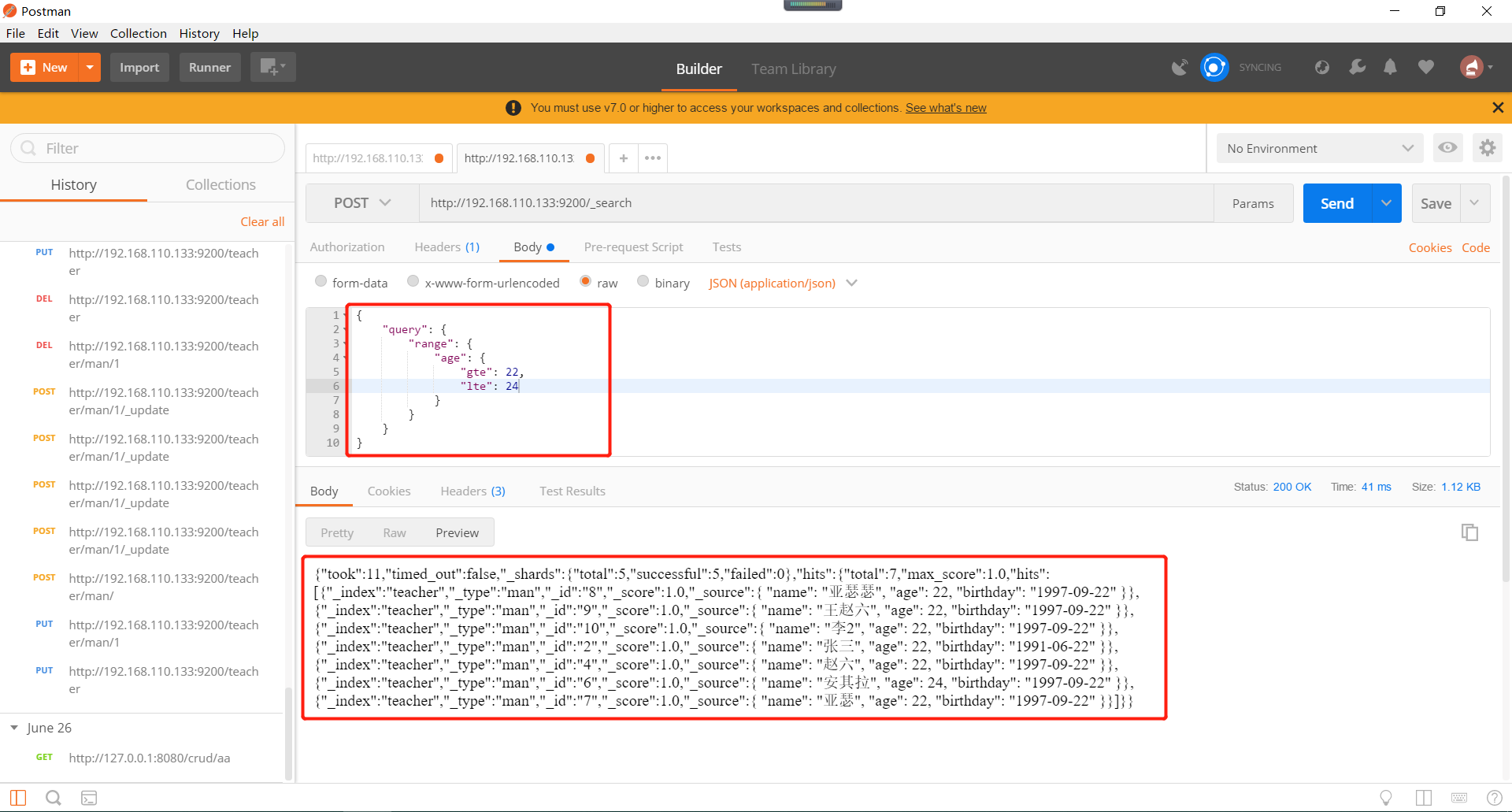
Elasticsearch范围的查询,gte是大于等于的含义,lte是小于等于的含义。gt是大于的含义,lt是小于的含义。
2)、Filter context的含义,Filter context在查询过程中,只判断该文档是否满足条件,只有yes或者no。Filter context主要用来做数据过滤的,查询的结果会被缓存起来。
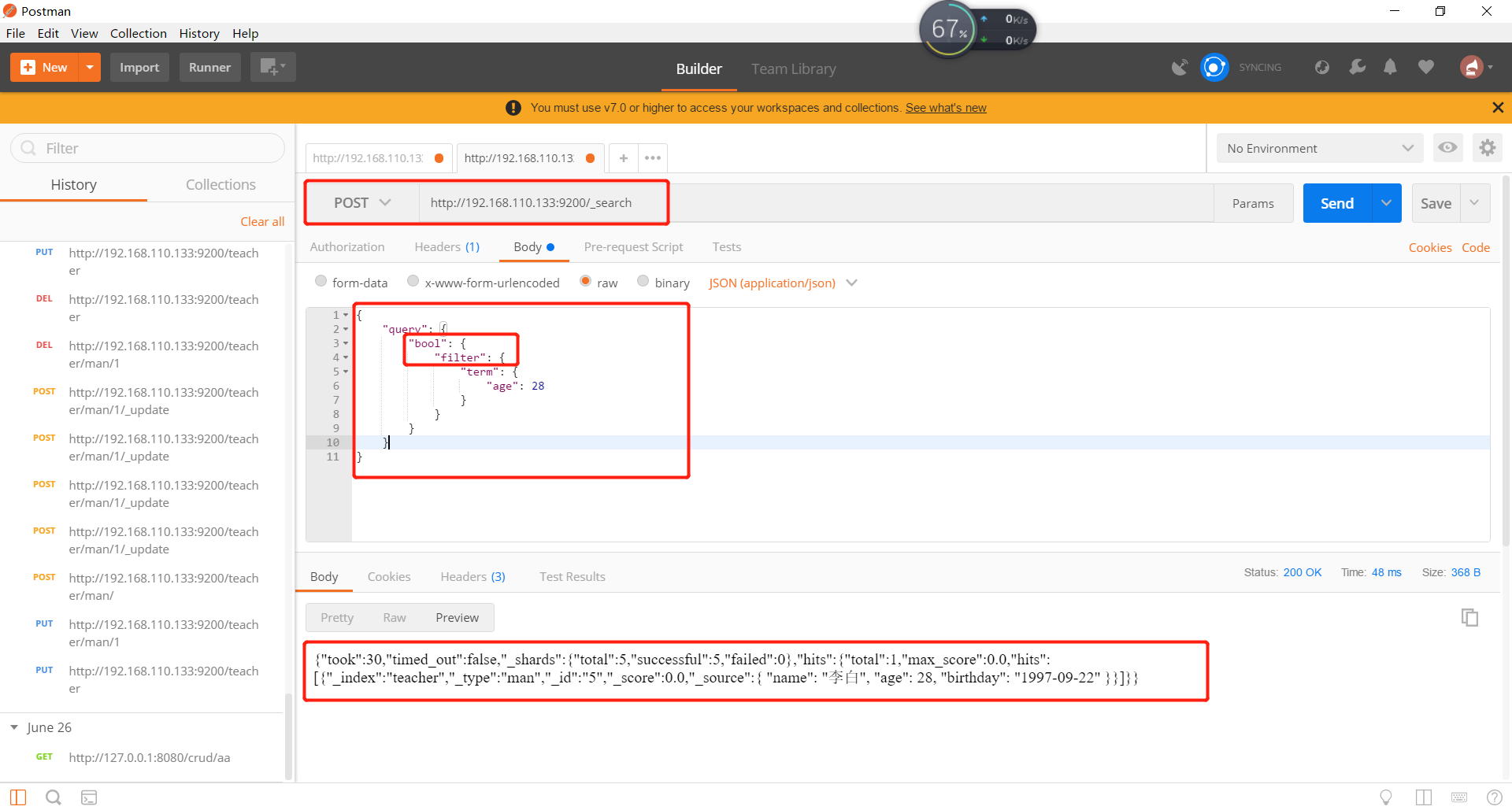
Query Context和Filter Context的复合查询,常用查询如固定分数查询、布尔查询。,如下所示:
Elasticsearch在查询返回后会给一个评分_score这个值,固定分数查询就是将分数固定下来,boost可以设置分数的值,如下所示:

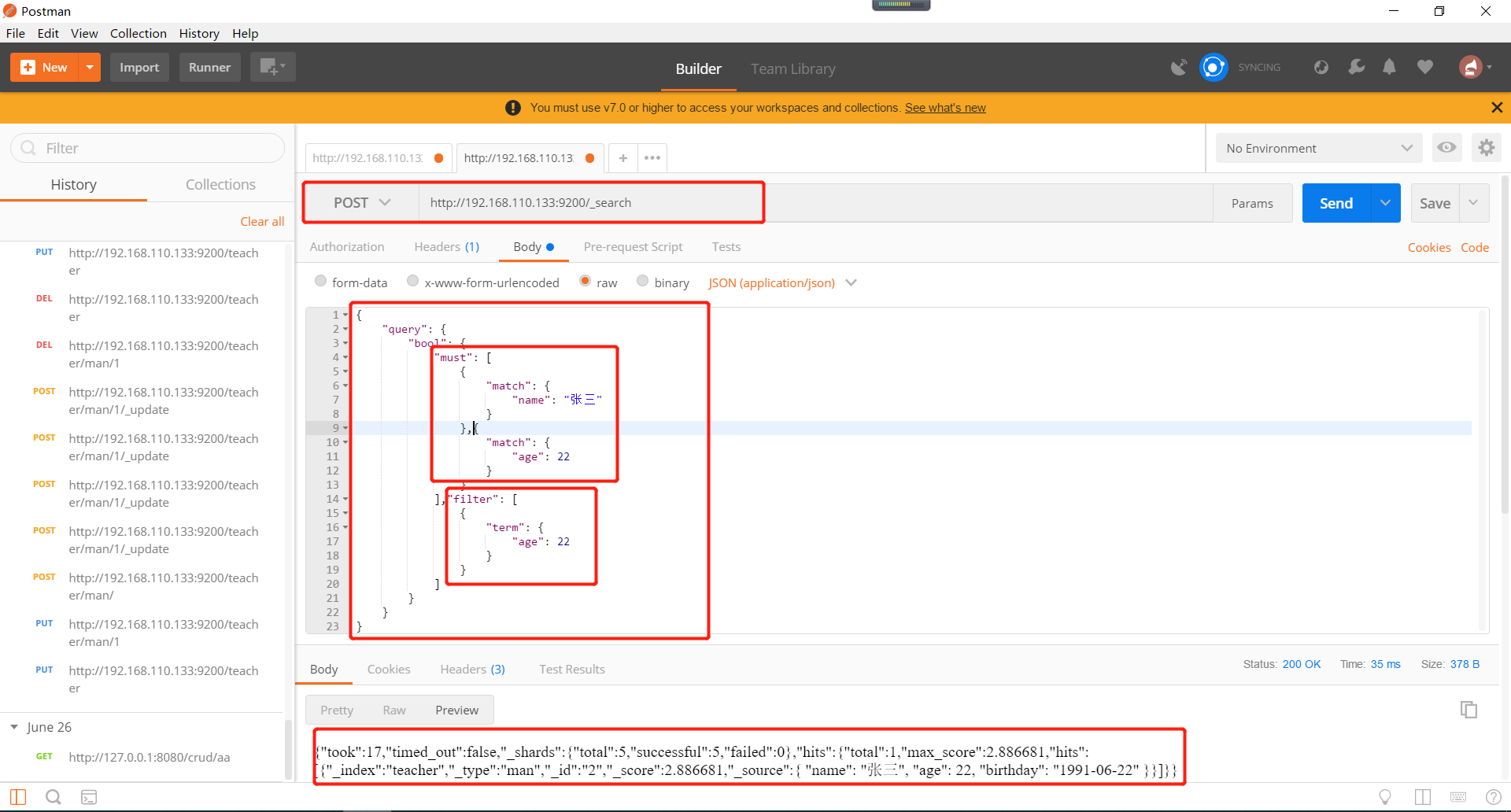
布尔查询如下所示,should是或者的关系,满足条件之一即查询出来,must是必须满足两者才查询出来,must就不截图了,替换成should即可测试:

布尔查询和过滤组成的组合查询,must的反义是must_not,自己可以进行测试即可,must和should的替换自行测试,如下所示:
作者:别先生
博客园:https://www.cnblogs.com/biehongli/
如果您想及时得到个人撰写文章以及著作的消息推送,可以扫描上方二维码,关注个人公众号哦。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
2017-10-16 一脸懵逼学习Hdfs---动态增加节点和副本数量管理(Hdfs动态扩容)
2017-10-16 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)