


笔记
康托展开和逆康托展开
康托展开和逆康托展开(转) - Sky丨Star - 博客园 (cnblogs.com)
康托展开表示的就是是当前排列组合在n个不同元素的全排列中的名次
逆康托展开则是由名次得出该名次的排列组合
公式:康托展开值X=a[n]*(n-1)!+a[n-1]*(n-2)!+...+a[i]*(i-1)!+...+a[1]*0!
X表示该排列组合前面有X个排列组合,所以该排列组合是第X+1个
a[i]表示当前未用到的元素中该元素排第几个
//阶乘 static const int Fac[]={1, 1, 2, 6, 24, 120, 720, 5040, 40320, 362880}; //康托展开 int cantor(int *a,int n){ int x=0; for(int i=0;i<n;++i){ int cnt=0; for(int j=i+1;j<n;++j) if(a[j]<a[i])cnt++; x+=Fac[n-i-1]*cnt; } return x; } //逆康托展开 void decantor(int x,int n){//x为康托展开值,n为元素个数 vector<int>v;//存放当前可选数 vector<int>a;//所求排列组合 for(int i=1;i<=n;++i)v.push_back(i); for(int i=n;i>=1;--i){ int l=x%Fac[i-1]; int r=x/Fac[i-1]; x=l; a.push_back(v[r]); v.erase(v.begin()+r); } }
__int128的使用方法
__int128 就是占用128字节的整数存储类型,范围是 -2^127~2^127-1
_int128只能实现四则运算,不能用cin,cout,scanf,printf输入输出,用快读和快写的函数
__int128 read() { //直接在函数里面实现读字符串操作更简洁 __int128 res=0;//初始结果赋值0 char scan[1005]; scanf("%s",scan); for(int i=0;i<strlen(scan);i++) res*=10,res+=scan[i]-'0';//实现进位 return res;//返回__int128类型 } void print(__int128 num) {//递归调用,实现从高位向低位输出 if(num>9) print(num/10); putchar(num%10+'0'); }
Lucas
int ksm(int x,int y){ int res=1; while(y){ if(y&1)res=res*x%mod; x=x*x%mod; y>>=1; } return res; } int c(int a,int b){ if(b>a)return 0; int res=1; for(int i=1,j=a;i<=b;++i,--j){ res=res*j%mod; res=res*ksm(i,mod-2)%mod; } return res; } int Lucas(int a,int b){ if(a<mod&&b<mod)return c(a,b); return c(a%mod,b%mod)*Lucas(a/mod,b/mod)%mod; }
阶乘逆元求组合数
int fact[N],infact[N]; int ksm(int a,int k,int p){ int res=1; while(k){ if(k&1)res=res*a%p; k>>=1; a=a*a%p; } return res; } void init(){ fact[0] = infact[0] = 1; for (int i = 1 ; i < N; ++i) { fact[i] = fact[i - 1] * i % mod; infact[i] = infact[i - 1] * ksm(i, mod - 2, mod) % mod; } //C(a,b)=fact[a]*infact[a-b]%mod*infact[b]%mod; }
struct E{ int x,y; E(){} E(int _x,int _y){x=_x,y=_y;} E operator-(E b){return E(x-b.x,y-b.y);} double len(){return ::hypot(x,y);}//sqrt(x*x+y*y); };
博弈论
Nim游戏
- 有n堆石子,两人轮流取石子,取不到的败
结论:每堆石子数异或和为非0则先手胜,否则先手败
- 有n个台阶,每个台阶有若干石子,两人轮流扔石子,石子被扔到下一台阶(到地面为止),无法扔的败
结论:所有第奇数个台阶的异或和为非0则先手胜,否则先手败
- 有n堆石子和一个集合S,两人轮流取石子,只能取si个石子,取不到的败
结论:所有堆数的SG异或和为非0则先手胜,否则先手败
//f初始为-1,sg(0)=0 vector<int>s,f(N); int sg(int x){ if(f[x]!=-1)return f[x]; unordered_set<int>se; for(int i=0;i<k;++i){ if(s[i]<=x)se.insert(sg(x-s[i])); } for(int i=0;;++i)if(!se.count(i))return f[x]=i; }
有n堆石子,两人轮流取一堆石子,换取两堆石子数都不超过被取堆的石子数的石子,不能取的败
结论:所有堆数的SG异或和为非0则先手胜利,否则先手败
//f初始为-1 vector<int>f(105); int sg(int x){ if(f[x]!=-1)return f[x]; unordered_set<int>se; for(int i=0;i<x;++i){ for(int j=0;j<=i;++j) se.insert(sg(i)^sg(j)); } for(int i=0;;++i)if(!se.count(i))return f[x]=i; }
欧拉函数
int cnt,primes[N],phi[N]; bool st[N]; int n; void get_phi(int n){ phi[1]=1; for(int i=2;i<=n;++i){ if(!st[i])phi[i]=i-1,primes[cnt++]=i; for(int j=0;primes[j]*i<=n;++j){ int t=i*primes[j]; st[t]=true; if(i%primes[j]==0){ phi[t]=phi[i]*primes[j]; break; } else phi[t]=phi[i]*(primes[j]-1); } } }
欧拉反演

线性基
详细→线性基详解-CSDN博客

构造线性基
//插入x void add(ll x) { for(int i=60;i>=0;i--) { if(x&(1ll<<i))//注意,如果i大于31,前面的1的后面一定要加ll { if(d[i])x^=d[i]; else { d[i]=x; break;//插入成功就退出 } } } }
如何求在一个序列中,取若干个数,使得它们的异或和最大
ll ans() { ll anss=0; for(int i=60;i>=0;i--)//记得从线性基的最高位开始 if((anss^d[i])>anss)anss^=d[i]; return anss; }
用线性基内的元素能异或出的最小值

从一个序列中取任意个元素进行异或,求能异或出的所有数字中第k小的那个
void work()//处理线性基 { for(int i=1;i<=60;i++) for(int j=1;j<=i;j++) if(d[i]&(1ll<<(j-1)))d[i]^=d[j-1]; } ll k_th(ll k) { if(k==1&&tot<n)return 0;//特判一下,假如k=1,并且原来的序列可以异或出0,就要返回0,tot表示线性基中的元素个数,n表示序列长度 if(tot<n)k--;//类似上面,去掉0的情况,因为线性基中只能异或出不为0的解 work(); ll ans=0; for(int i=0;i<=60;i++) if(d[i]!=0) { if(k%2==1)ans^=d[i]; k/=2; } }
8种球盒问题
https://zhuanlan.zhihu.com/p/429815465?utm_id=0
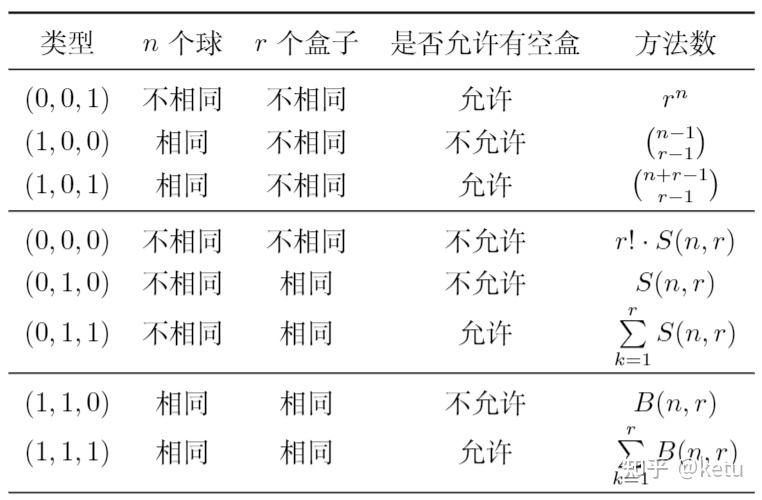
(0,1,0)
板子
int fact[N],infact[N];
int ksm(int a,int k,int p){
int res=1;
while(k){
if(k&1)res=res*a%p;
k>>=1;
a=a*a%p;
}
return res;
}
void init(){
fact[0] = infact[0] = 1;
for (int i = 1 ; i < N; ++i) {
fact[i] = fact[i - 1] * i % mod;
infact[i] = infact[i - 1] * ksm(i, mod - 2, mod) % mod;
}
//C(a,b)=fact[a]*infact[a-b]%mod*infact[b]%mod;
}
int C(int a,int b){
return fact[a]*infact[a-b]%mod*infact[b]%mod;
}
void solve() {
int n,m;
cin>>n>>m;
if(m>n){
cout<<0;
return ;
}
init();
int ans=0;
for(int i=0;i<=m;++i){
if(i%2){
ans=(ans-C(m,i)*ksm(m-i,n,mod)%mod+mod)%mod;
}else{
ans=(ans+C(m,i)*ksm(m-i,n,mod)%mod)%mod;
}
}
cout<<ans*infact[m]%mod;
}
扩展欧几里得
ax+by=c的求解
板子
int exgcd(int a, int b, int &x, int &y) {
if(!b) {
x = 1, y = 0;
return a;
}
int ans = exgcd(b, a%b, y, x);
y -= a / b * x;
return ans;
}
int P(int a, int b, int c) {///最小正整数解
int x, y, z;
z = exgcd(a, b, x, y);
if(c%z)
return -1;//不成立
// return x;//不需要最小正整数的话直接返回x
x *= c / z;
b = abs(b / z);
return (x%b + b) % b;
}

匈牙利二分图最大匹配
vector<int> st(n + 1), to(n + 1);
auto dfs = [&](int u, auto dfs)->bool {
for (auto v:ve[u]) {
if (st[v]) continue;
st[v] = 1;
if (!to[v] || dfs(to[v], dfs)) {
to[v] = u;
return true;
}
}
return false;
};
for (int i = 1; i <= n; ++i) {
std::fill(st.begin(), st.end(), 0);
if (dfs(i, dfs)) ans ++;
}tarjan求割边割点
无向图求割边
int dfn[N], low[N], ct;
vector<vector<int> > ve;
void tarjan(int u)
{
low[u] = dfn[u] = ++ct;
for (auto v : ve[u])
{
if (!dfn[v])
{
fa[v] = u;
tarjan(v);
low[u] = min(low[u], low[v]);
if (low[v] > dfn[u]) {
add_ge_bian(u, v);
//求割边
}
}
else if (v != fa[u])
low[u] = min(low[u], dfn[v]);
}
}
void work() {
//为连通图
tarjan(1);
}无向图求割点
int dfn[N], low[N], ct;
vector<vector<int> > ve;
void tarjan(int u, bool isroot)
{
int tot = 0;
low[u] = dfn[u] = ++ct;
for (auto v : ve[u])
{
if (!dfn[v])
{
tarjan(v, 0);
low[u] = min(low[u], low[v]);
tot += low[v] >= dfn[u];
}
else
low[u] = min(low[u], dfn[v]);
}
if ((isroot && tot >= 2) || (!isroot && tot >= 1)) {
//割点
add_ge_dian(u);
}
}
void work() {
//为连通图
tarjan(1, 1);
}边双连通分量
定义:不存在割边的极大双连通子图
性质:边双连通分量中任意一条边都包含在至少一个简单环中
vector<int> dfn(n + 5), low(n + 5), vis(n + 5), bel(n + 5);
// bel表示每个点属于的边双连通分量,bel[u] = vel[v]表示u和v在一个边双中
int bccnt = 0, idx = 0;
stack<int> st;
auto dfs = [&](int u, int fa, auto dfs) -> void {
dfn[u] = low[u] = ++idx;
st.push(u);
vis[u] = 1;
for (auto v: ve[u]) {
if (v == fa) continue;
if (!vis[v]) {
dfs(v, u, dfs);
low[u] = min(low[u], low[v]);
} else low[u] = min(low[u], dfn[v]);
}
if (dfn[u] == low[u]) {
int p;
++ bccnt;
do {
p = st.top();
st.pop();
bel[p] = bccnt;
} while (p != u);
}
};
for (int i = 1; i <= n; ++i) {
if (!vis[i]) {
dfs(i, -1, dfs);
}
}点双连通分量
定义:不存在割点的极大双连通子图
性质:点双连通分量中任意两点都同时包含在至少一个简单环中
vector<vector<int> > ve(N), ans(N); //ans中存放每个点双,有bcc个
int dfn[N], low[N], bcc, top, idx, n;
int s[N]; //栈
inline void tarjan(int u, int fa) {
int son = 0;
low[u] = dfn[u] = ++idx;
s[++top] = u;
for (auto v: ve[u]) {
if(!dfn[v]) {
son++;
tarjan(v, u);
low[u] = min(low[u], low[v]);
if(low[v] >= dfn[u]) {
bcc++;
while(s[top + 1] != v) ans[bcc].push_back(s[top--]);//将子树出栈
ans[bcc].push_back(u);//把割点/树根也丢到点双里
}
} else if(v != fa) low[u] = min(low[u], dfn[v]);
}
if(fa == 0 && son == 0) ans[++bcc].push_back(u);//特判独立点
}
void work() {
for (int i = 1; i <= n; ++i) {
if (dfn[i]) continue;
top = 0;
tarjan(i, 0);
}
}KMP
//找出第一个匹配下标
int kmp(string text, string pattern) {
int n = text.size(), m = pattern.size();
if (m == 0) {
return 0;
}
vector<int> next(m);
for (int i = 1, j = 0; i < m; i++) {
while (j > 0 && pattern[i] != pattern[j]) {
j = next[j - 1];
}
if (pattern[i] == pattern[j]) {
j++;
}
next[i] = j;
}
for (int i = 0, j = 0; i < n; i++) {
while (j > 0 && text[i] != pattern[j]) {
j = next[j - 1];
}
if (text[i] == pattern[j]) {
j++;
}
if (j == m) {
return i - m + 1;
}
}
return -1;
}
int ne[N];
void get_Next(string s) //这个函数对字符串s进行预处理得到next数组
{
int j = 0;
ne[0] = 0; //初始化
for (int i = 1; i < s.size(); i++) { //i指针指向的是后缀末尾,j指针指向的是前缀末尾
while (j > 0 && s[i] != s[j]) j = ne[j - 1]; //前后缀不相同,去找j前一位的最长相等前后缀
if (s[i] == s[j]) j++; //前后缀相同,j指针后移
ne[i] = j; //更新next数组
}
}
int strSTR(string s, string t) //这个函数是从s中找到t,如果存在返回t出现的位置,如果不存在返回-1
{
if(t.size()==0) return 0;
get_Next(t);
int j = 0;
for(int i = 0; i < s.size(); i++){
while(j>0&&s[i]!= t[j]) j = ne[j-1];
if(s[i]==t[j]) j++;
if(j==t.size()) {
// 找到匹配后的处理
return i - t.size() + 1;
}
}
return -1;
}字符串哈希
const int N = 2e6 + 5; // 最大字符串的个数
const int M = 2e6 + 10; // 题目中字符串的最大长度
const ull base = 131; // 131,13331不容易哈希碰撞
// p[i]:表示p的i次方
// h[i]:表示s[1~i]的哈希值,如h[2]表示字符串s前两个字符组成字符串的哈希值
ull p[N], h[N];
//int n;
// 预处理hash函数的前缀和,时间复杂度O(n)
void init(string s) {
// 下标从1开始
int n = s.size() - 1;
// p^0=1,空串哈希值为0
p[0] = 1, h[0] = 0;
for (int i = 1; i <= n; i++) {
p[i] = p[i - 1] * base;
h[i] = h[i - 1] * base + s[i]; // 前缀和计算公式
}
}
// 计算s[l~r](子串)的hash值,时间复杂度O(1)
ull get(int l, int r) {
return h[r] - h[l - 1] * p[r - l + 1]; // 区间和计算字串的hash值
}
// 判断s中的两个子串是否相同
bool substr(int l1, int r1, int l2, int r2) {
return get(l1, r1) == get(l2, r2);
}
// 求ss的哈希值(下标从0开始)
ull gethash(string ss) {
ull ret = 0;
for (int i = 0; i < ss.size(); ++i)
ret = ret * base + (ull) ss[i];
return ret;
}ac自动机
最原始的问题情境就是“给定n个模式串和1个文本串,求有多少种模式串在文本串里出现过。”
同一个模式串视为一种
const int maxn = 2 * 1e6 + 9;
int trie[maxn][26]; //字典树
int cntword[maxn]; //记录该单词出现次数
int fail[maxn]; //失败时的回溯指针
int cnt = 0;
void insertWords(string s) {
int root = 0;
for (int i = 0; i < s.size(); i++) {
int next = s[i] - 'a';
if (!trie[root][next])
trie[root][next] = ++cnt;
root = trie[root][next];
}
cntword[root]++; //当前节点单词数+1
}
void getFail() {
queue<int> q;
for (int i = 0; i < 26; i++) { //将第二层所有出现了的字母扔进队列
if (trie[0][i]) {
fail[trie[0][i]] = 0;
q.push(trie[0][i]);
}
}
//fail[now] ->当前节点now的失败指针指向的地方
// tire[now][i] -> 下一个字母为i+'a'的节点的下标为tire[now][i]
while (!q.empty()) {
int now = q.front();
q.pop();
for (int i = 0; i < 26; i++) { //查询26个字母
if (trie[now][i]) {
//如果有这个子节点为字母i+'a',则
//让这个节点的失败指针指向(((他父亲节点)的失败指针所指向的那个节点)的下一个节点)
//有点绕,为了方便理解特意加了括号
fail[trie[now][i]] = trie[fail[now]][i];
q.push(trie[now][i]);
} else//否则就让当前节点的这个子节点
//指向当前节点fail指针的这个子节点
trie[now][i] = trie[fail[now]][i];
}
}
}
int query(string s) {
int now = 0, ans = 0;
for (int i = 0; i < s.size(); i++) { //遍历文本串
now = trie[now][s[i] - 'a']; //从s[i]点开始寻找
for (int j = now; j && cntword[j] != -1; j = fail[j]) {
//一直向下寻找,直到匹配失败(失败指针指向根或者当前节点已找过).
ans += cntword[j];
cntword[j] = -1; //将遍历国后的节点标记,防止重复计算
}
}
return ans;
}
void work() {
int n;
cin >> n;
string s;
for (int i = 0; i < n; ++i) {
cin >> s; // 模式串
insertWords(s);
}
getFail();
// 文本串
cin >> s;
cout << query(s) << '\n';
}Pollard Rho
求出x的所有质因子O(n^(1/4))
using f64 = long double;
int p;
f64 invp;
void setmod(int x){
p = x,invp = (f64)1 / x;
}
int mul(int a,int b){
int z = a * invp * b + 0.5;
int res = a * b - z * p;
return res + (res >> 63 & p);
}
int pow(int a,int x,int res = 1){
for (;x;x >>= 1, a = mul(a,a))
if (x & 1) res = mul(res,a);
return res;
}
bool checkprime(int p){
if (p == 1) return 0;
setmod(p);
int d = __builtin_ctzll(p - 1),s = (p - 1) >> d;
for (int a : {2, 3, 5, 7, 11, 13, 82, 373}){
if (a % p == 0)
continue;
int x = pow(a,s),y;
for (int i = 0;i < d;++i,x = y){
y = mul(x,x);
if (y == 1 && x != 1 && x != p - 1){
return false;
}
}
if (x != 1) return false;
}
return 1;
}
int rho(int n){
if (!(n & 1)) return 2;
static std::mt19937_64 gen((size_t)"hehezhou");
int x = 0,y = 0,prod = 1;
auto f = [&](int o){return mul(o,o) + 1;};
setmod(n);
for (int t = 30,z = 0;t % 64 || gcd(prod,n) == 1;++t){
if (x == y) x = ++z,y = f(x);
if (int q = mul(prod,x + n - y)) prod = q;
x = f(x),y = f(f(y));
}
return gcd(prod,n);
}
vector<int> factor(int x){
vector<int> res;
auto f = [&](auto f,int x){
if (x == 1) return;
if (checkprime(x)) return res.push_back(x);
int y = rho(x);
f(f,y),f(f,x / y);
};
f(f,x),sort(res.begin(),res.end());
return res;
}
void work() {
int x;
// 求出x的所有质因子O(n^(1/4))
vector<int> ans = factor(x);
}
