

运维工程师职业技能汇总大全(持续更新)
运维工程师职业技能汇总大全(持续更新)
1. 基础知识
1.1 系统原理
1.1.1 Linux操作系统启动流程
a. 名词解释:
BIOS
基本输入输出系统(Basic Input Output System,BIOS)是一组固化到计算机主板上的只读内存镜像(Read Only Memory image,ROM)芯片上的程序,它保存着计算机最重要的基本输入输出的程序、系统设置信息、开机后自检程序和系统自启动程序。主要功能是为计算机提供最底层的、最直接的硬件设置和控制。
MBR
全新硬盘在使用之前必须进行分区格式化,硬盘分区初始化的格式主要由两种,分别是:MBR格式和GPT格式。
MBR主引导记录扇区(Main Boot Record)是计算机启动最先执行的硬盘上的程序,只有512字节大小,所以不能载入操作系统的核心,只能先载入一个可以载入计算机核心的程序,我们称之为引导程序。MBR分区标准决定了MBR只支持在2TB以下的硬盘。
GPT
GUID全局唯一的标识符(Globally unique identifier,简称GPT),正逐渐取代MBR成为新标准。它和统一的可扩展固件接口 (Unified Extensible Firmware Interface,UEFI)相辅相成。UEFI用于取代老旧的BIOS,而GPT则取代老旧的MBR。GPT支持2T以上磁盘,如果使用Fdisk分区,最大只能建立2TB大小的分区,创建大于2TB的分区,需使用parted,同时必须使用64位操作系统。
GRUB
GNU项目的多操作系统启动程序(GRand Unified Bootloader,GRUB),可以支持多操作系统的引导,它允许用户可以在计算机内同时拥有多个操作系统,并在计算机启动时选择希望运行的操作系统。CentOS 7 Linux默认使用GRUB2引导程序,引导系统启动。
b. 启动流程
我的理解是:
开机质检
加载BIOS
读取MBR
引导GRUB
加载内核
确定启动级别
加载模块
系统初始化
执行对应启动级别自启任务
执行rc.local文件
登录shell
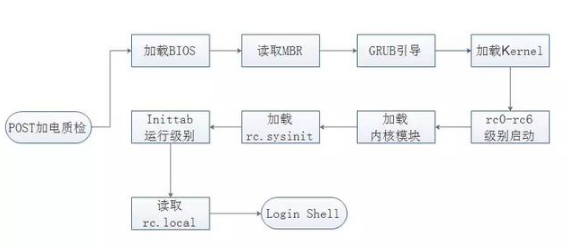
(1)加载BIOS
计算机电源加电质检,首先加载基本输入输出系统(Basic Input Output System,BIOS),BIOS中包含硬件CPU、内存、硬盘等相关信息,包含设备启动顺序信息、硬盘信息、内存信息、时钟信息、即插即用(Plug-and-Play,PNP)特性等。加载完BIOS信息,计算机将根据顺序进行启动。
(2)读取MBR
读取完BIOS信息,计算机将会查找BIOS所指定的硬盘MBR引导扇区,将其内容复制到0x7c00地址所在的物理内存中。被复制到物理内存的内容是Boot Loader,然后进行引导。
(3)GRUB引导
GRUB启动引导器是计算机启动过程中运行的第一个软件程序,当计算机读取内存中的GRUB配置信息后,会根据其配置信息来启动硬盘中不同的操作系统。
(4)加载Kernel
计算机读取内存映像,并进行解压缩操作,屏幕一般会输出“Uncompressing Linux”的提示,当解压缩内核完成后,屏幕输出“OK, booting the kernel”。系统将解压后的内核放置在内存之中,并调用start_kernel()函数来启动一系列的初始化函数并初始化各种设备,完成Linux核心环境的建立。
(5)设定Inittab运行等级
内核加载完毕,会启动Linux操作系统第一个守护进程init,然后通过该进程读取/etc/inittab文件,/etc/inittab文件的作用是设定Linux的运行等级,Linux常见运行级别如下:
- 0:关机模式;
- 1:单用户模式;
- 2:无网络支持的多用户模式;
- 3:字符界面多用户模式;
- 4:保留,未使用模式;
- 5:图像界面多用户模式;
- 6:重新引导系统,重启模式。
(6)加载rc.sysinit
读取完运行级别,Linux系统执行的第一个用户层文件/etc/rc.d/rc.sysinit,该文件功能包括:设定PATH运行变量、设定网络配置、启动swap分区、设定/proc、系统函数、配置Selinux等。
(7)加载内核模块
读取/etc/modules.conf文件及/etc/modules.d目录下的文件来加载系统内核模块。该模块文件,可以后期添加或者修改及删除。
(8)启动运行级别程序
根据之前读取的运行级别,操作系统会运行rc0.d到rc6.d中的相应的脚本程序,来完成相应的初始化工作和启动相应的服务。其中以S开头表示系统即将启动的程序,如果以K开头,则代表停止该服务。S和K后紧跟的数字为启动顺序编号。
(9)读取rc.local文件
操作系统启动完相应服务之后,会读取执行/etc/rc.d/rc.local文件,可以将需要开机启动的任务加入到该文件末尾,系统会逐行去执行并启动相应命令
(10)执行/bin/login程序
执行/bin/login程序,启动到系统登录界面,操作系统等待用户输入用户名和密码,即可登录到Shell终端,输入用户名、密码即可登录Linux操作系统,至此Linux操作系统完整流程启动完毕。
1.2 命令基础
1.2.1 命令行下载工具wget/mwget
wget是一个命令行下载工具,mwget是一个多线程命令行下载工具。后者下载速度有明显提升,建议直接上mwget
wget安装
yum install wget -y
wget使用示例
wget 下载地址URL
mwget安装

#!/bin/bash wget http://jaist.dl.sourceforge.net/project/kmphpfm/mwget/0.1/mwget_0.1.0.orig.tar.bz2 yum install bzip2 gcc-c++ openssl-devel intltool -y bzip2 -d mwget_0.1.0.orig.tar.bz2 tar -xvf mwget_0.1.0.orig.tar cd mwget_0.1.0.orig ./configure make make install #至此,安装完成
mwget使用示例
mwget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.2.5.tgz
wget和mwget下载速度对比
[root@instance-u5vn5wqr ~]# wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.2.5.tgz --2020-03-26 09:41:07-- https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.2.5.tgz 正在解析主机 fastdl.mongodb.org (fastdl.mongodb.org)... 52.222.158.137, 52.222.158.143, 52.222.158.153, ... 正在连接 fastdl.mongodb.org (fastdl.mongodb.org)|52.222.158.137|:443... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:132702741 (127M) [application/gzip] 正在保存至: “mongodb-linux-x86_64-rhel70-4.2.5.tgz” 7% [=====> ] 9,625,799 2.77KB/s 剩余 2h 8m ^C [root@instance-u5vn5wqr ~] mwget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.2.5.tgz --2020-03-26 09:55:58-- https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.2.5.tgz 正在解析主机 fastdl.mongodb.org (fastdl.mongodb.org)... 54.192.151.31, 54.192.151.43, 54.192.151.54, ... 正在连接 fastdl.mongodb.org (fastdl.mongodb.org)|54.192.151.31|:443... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:132702741 (127M) [application/gzip] 正在保存至: “mongodb-linux-x86_64-rhel70-4.2.5.tgz.1” 100%[===========================================================================================>] 132,702,741 4.01MB/s 用时 40s 2020-03-26 09:56:39 (3.19 MB/s) - 已保存 “mongodb-linux-x86_64-rhel70-4.2.5.tgz.1” [132702741/132702741]) [root@instance-u5vn5wqr ~]#
1.2.2 端口查看netstat/ss
netstat/ss都可以用来查看系统当前端口使用情况,哪些程序使用了哪些端口,哪些端口是监听中的
netstat安装
yum install net-tools -y
netstat使用示例
[root@instance-u5vn5wqr ~]# netstat -tlnp Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 127.0.0.1:27017 0.0.0.0:* LISTEN 12196/mongod tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 12004/mysqld tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 1/systemd tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 12658/nginx: master tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1050/sshd tcp 0 0 127.0.0.1:1815 0.0.0.0:* LISTEN 31407/hosteye tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 16391/master tcp6 0 0 :::781 :::* LISTEN 1085/./bcm-agent tcp6 0 0 :::111 :::* LISTEN 1/systemd tcp6 0 0 :::22 :::* LISTEN 1050/sshd tcp6 0 0 ::1:25 :::* LISTEN 16391/master [root@instance-u5vn5wqr ~]#
centos7默认自带ss命令?待验证
ss这个命令我也不熟,用惯了netstat。下面看一下ss怎么用。暂时不知道怎么同时显示服务名和对应的端口的方法 >_<
[root@instance-u5vn5wqr ~]# ss -tl State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 127.0.0.1:27017 *:* LISTEN 0 50 *:mysql *:* LISTEN 0 128 *:sunrpc *:* LISTEN 0 128 *:http *:* LISTEN 0 128 *:ssh *:* LISTEN 0 128 127.0.0.1:mmpft *:* LISTEN 0 100 127.0.0.1:smtp *:* LISTEN 0 128 :::781 :::* LISTEN 0 128 :::sunrpc :::* LISTEN 0 128 :::ssh :::* LISTEN 0 100 ::1:smtp :::* [root@instance-u5vn5wqr ~]# ss -tln State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 127.0.0.1:27017 *:* LISTEN 0 50 *:3306 *:* LISTEN 0 128 *:111 *:* LISTEN 0 128 *:80 *:* LISTEN 0 128 *:22 *:* LISTEN 0 128 127.0.0.1:1815 *:* LISTEN 0 100 127.0.0.1:25 *:* LISTEN 0 128 :::781 :::* LISTEN 0 128 :::111 :::* LISTEN 0 128 :::22 :::* LISTEN 0 100 ::1:25 :::* [root@instance-u5vn5wqr ~]#
1.3 网络基础
1.3.1 网络模型
七层网络协议模型
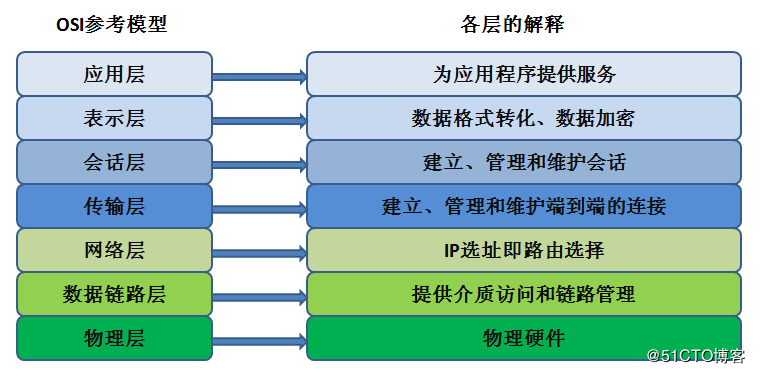
物理层:由于网络传输介质传输的是比特位(01),因此物理层必须定义所使用的传输设备的电压和信号等,同时还必须了解数据帧转换成比特流的编码方式,最后链接实际传输介质并发送/接收比特信号。
数据链路层:硬件部分,主要处理MAC数据帧,传递给物理层转换成比特流;软件部分主要处理来自上层的数据表转换成MAC的格式。相关协议:PPP
网络层:定义IP地址,定义计算机之间的链接建立,终止维护等,数据包的传输路径等。相关协议:IP、ICMP、ARP、RARP
传输层:定义发送端与接收端的链接技术(TCP,UDP)同时包括该技术的数据包格式,数据包的发送,流程的控制等,以确保各个资料数据可以正确无误的到达目的端。相关协议:TCP、UDP
会话层:确定网络服务建立链接的确认。
表示层:定义网络服务(或程序)之间的数据格式的转换,使数据格式标准化,也包括数据的加密解密也是在这层上处理。
应用层:将数据发送给应用程序,并最终展示给用户。相关协议:HTTP、FTP、SMTP等。
虽然OSI七层协议的架构非常严谨,但是由于太过严谨导致程序编写相当不容易,因此产生了TCP/IP协议。
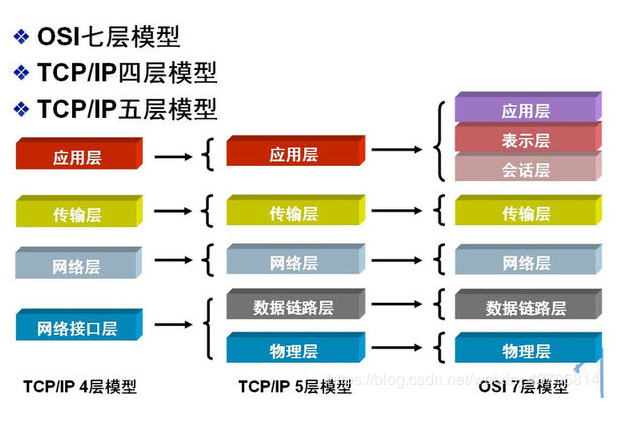
应用层:应用程序间沟通的层,如简单电子邮件传输(SMTP)、文件传输协议(FTP)、网络远程访问协议(Telnet)等。
传输层:在此层中,它提供了节点间的数据传送,应用程序之间的通信服务,主要功能是数据格式化、数据确认和丢失重传等。如传输控制协议(TCP)、用户数据报协议(UDP)等,TCP和UDP给数据包加入传输数据并把它传输到下一层中,这一层负责传送数据,并且确定数据已被送达并接收。
互连网络层:负责提供基本的数据封包传送功能,让每一块数据包都能够到达目的主机(但不检查是否被正确接收),如网际协议(IP)。
网络接口层(主机-网络层):接收IP数据报并进行传输,从网络上接收物理帧,抽取IP数据报转交给下一层,对实际的网络媒体的管理,定义如何使用实际网络(如Ethernet、Serial Line等)来传送数据。
1.3.2 网络划分
IP地址的种类划分:
在IPV4中有两种IP类别
Public IP:公共IP,经由InterNIC统一规划IP,只有这种IP才可链接到Internet。
Private IP:私有IP或保留IP,不能直接连上Internet的IP,主要用于局域网络内的主机链接规划。
Public IP公共IP如下:(注:128+64+32+16+8+4+2+1)
A类地址
定义:第1字节为网络地址,其它3个字节为主机地址(第一个字节1...126都是指网络地址,后面跟的三位数具体到主机)
范围:1.0.0.1 - 126.255.255.254
子网掩码:255.0.0.0
私有地址:10.X.X.X是私有地址(所谓的私有地址就是在互联网上不使用,而被用在局域网络中的地址),范围10.0.0.0-10.255.255.255 ---
保留地址127.X.X.X是保留地址,用做循环测试用的,吗比如常用的 127.0.0.1
B类地址
定义:第1字节和第2字节为网络地址,其它2个字节为主机地址
范围:128.0.0.1 - 191.255.255.254
子网掩码:255.255.0.0
私有地址:172.16.0.0 - 172.31.255.255是私有地址
保留地址:169.254.X.X是保留地址。如果你的IP地址是自动获取IP地址,而你在网络上又没有找到可用的DHCP服务器。就会得到其中一个IP
C类地址
范围:第1字节、第2字节和第3个字节为网络地址,第4个个字节为主机地址。另外第1个字节的前三位固定为110
范围:192.0.0.1 - 223.255.255.254
子网掩码:255.255.255.0
私有地址:192.168.X.X是私有地址。(192.168.0.0 - 192.168.255.255)
D类地址
定义:不分网络地址和主机地址,它的第1个字节的前四位固定为1110
范围:224.0.0.1 - 239.255.255.254
E类地址
定义:不分网络地址和主机地址,它的第1个字节的前五位固定为11110
范围:240.0.0.1 - 255.255.255.254
另外, ip地址后边加个/8(16,24,32),这些数字代表掩码的位数
A类IP地址的默认子网掩码为255.0.0.0(由于255相当于二进制的8位1,所以也缩写成“/8”,表示网络号占了8位);
B类的为255.255.0.0(/16);
C类的为255.255.255.0(/24)
/30就是255.255.255.252
/32就是255.255.255.255
1.3.3 网络计算
已知192.168.1.53/27,计算以下内容
具体的子网掩码
子网数
可用的主机数
最大可容纳主机数
网络地址
广播地址
ip对应的二进制位,只需关注53即可
53对应的二进制位00110101 -》2^5+2^4+2^2+2^0=32+16+4+1=53
子网掩码
根据192.168.1.53/27可知,子网掩码有27个1,对应二进制如下
11111111.11111111.11111111.11100000
转换为十进制11100000 -》2^7+2^6+2^5=224
可得255.255.255.224
最大可容纳主机数
从掩码中可以看出主机号只剩5个, 掩码都变成1,说明达到最大可容纳主机数了
所以最大可容纳主机数为
2^5=32
可用的主机数
最大可容纳主机数减去2(减去全为0或全为1)
32-2=30
子网数
基础网络位和网络位之间的差值,C类网络基础网络位24位(前面三位全为1),现在借了3位,2^3=8
可得8
网络地址-> IP地址和子网掩码进行与运算的结果(掩码前面都为1所以保持不变,只需计算最后一串数字)
00110101
11100000
两者与运算得00100000=2^5=32
可得192.168.1.32
广播地址-》子网掩码取反后与网络地址或运算
00011111(掩码取反)
00100000
或运算得00111111=2^5+2^4+2^3+2^2+2^1+1=63
可得192.168.1.63
可自行在https://tool.520101.com/wangluo/ipjisuan/ 计算答案对比看是否正确。如有问题请反馈
1.3.4 TCP的三次握手及四次挥手详解

三次握手:
第一次握手:客户端发送一个TCP的SYN标志位置1的包指明客户打算连接的服务器的端口。
第二次握手:服务器发回确认包ACK应答,即SYN标志位和ACK标志位均为1。
第三次握手:客户端再次发送确认包ACK,SYN标志位为0,ACK标志位为1。
四次挥手:
第一次挥手:客户端发送一个FIN,用来关闭客户端到服务器的数据传送,客户端进入FIN_WAIT_1状态。
第二次挥手:服务器收到FIN后,发送一个ACK给客户端,确认序号为收到序号+1,服务器进入CLOSE_WAIT状态。
第三次挥手:服务器发送一个FIN,用来关闭Server到Client的数据传送,服务器进入LAST_ACK状态。
第四次挥手:客户端收到FIN后,客户端进入TIME_WAIT状态,接着发送一个ACK给服务器确认序号为收到序号+1,服务器进入CLOSE状态,完成四次挥手
1.4 排错基础
PS:排错前,需要做以下事项的确认,否则你可能会被自己坑惨:
第一坑:确认一下防火墙状态
第二坑:Selinux也十分重要
第三坑:系统时间千万要正常
1.4.1 关于CPU
top
-p 指定pid
-P按照CPU使用率排行
-M按照内存使用率排行
进入top后按q退出top
按m显示内存使用率百分比
top显示内容解释
第一行会显示系统运行时长,当前登录用户,平均负载
load average数据是每隔5秒钟检查一次活跃的进程数。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。相当于有活跃进程在等待CPU执行,而当前逻辑CPU已经都被占用了
第二行可以看到当前运行的进程总数,僵尸进程数
第三行可以看到用户空间占用cpu百分比us,内核空间占用cpu百分比su,空闲cpu百分比id,等待输入输出的CPU时间百分比
在top基本视图中,按键盘数字“1”可以监控每个逻辑CPU的状况
top虽然很强大,但是只能监控到进程,无法监控到线程数和客户连接数等
和top相反,ps可以通过-L选项监控到具体线程
PS:
监控java线程数:ps -eLf | grep java | wc -l
监控网络客户连接数:netstat -n | grep tcp | grep 侦听端口 | wc -l
有时候我们希望ps以树形结构显示进程,可以使用 -axjf 参数。因为有一些可能会有多个进程?
ps -axjf 也可以通过pstree查看树形结构进程
如果想要查看现在有谁登入了你的服务器。可以使用ps命令加上相关参数:
$ ps -eo pid,user,args
参数 -e 显示所有进程信息,-o 参数控制输出。Pid,User 和 Args参数显示PID,运行应用的用户和该应用。
如果希望结果能够每秒刷新一次。为此,我们可以将ps命令和watch命令结合起来。
$ watch -n 1 ‘ps -aux --sort -pmem, -pcpu’ watch可以帮你监测一个命令的运行结果,来监测你想要的一切命令的结果变化。-n指间隔时长
#查看所有cpu核信息
mpstat -P ALL 1
vmstat
#查看cpu使用情况以及平均负载。vmstat reports information about processes, memory, paging, block IO, traps, disks and cpu activity
vmstat 1
pidstat
#具体进程cpu的统计信息
pidstat -u 1 -p pid
perf
#跟踪进程内部函数级cpu使用情况
perf top -p pid -e cpu-clock
1.4.2 关于内存
#查看系统内存使用情况
free -m
#查看系统内存情况
top
#1s采集周期,获取内存的统计信息
pidstat -p pid -r 1
#查看进程的内存映像信息
pmap -d pid
#检测程序内存问题
valgrind --tool=memcheck --leak-check=full --log-file=./log.txt ./程序名
#valgrind的使用具体可以参考https://www.cnblogs.com/leiyun/articles/2550507.html
1.4.3 关于磁盘
#查看所有进程io信息
iotop
#统计io详细信息
iostat -d -x -k 1 10
#查看进程级io的信息
pidstat -d 1 -p pid
#查看系统IO的请求,比如可以在发现系统IO异常时,可以使用该命令进行调查,就能指定到底是什么原因导致的IO异常
#record是开始录制,^C截止,report播放记录
perf record -e block:block_rq_issue -ag
^C
perf report
1.4.4关于网络
显示网络统计信息
netstat -s
显示当前UDP连接状况
netstat -nu
显示UDP端口号的使用情况
netstat -apu
统计机器中网络连接各个状态个数
netstat -a | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
显示TCP连接
ss -t -a
显示sockets摘要信息
ss -s
显示所有udp sockets
ss -u -a
sar(System Activity Reporter系统活动情况报告)是目前 Linux 上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等
#tcp,etcp状态。
sar -n TCP,ETCP 1
查看网络IO
sar -n DEV 1
sar参数-u CPU使用率
1. 若 %iowait 的值过高,表示硬盘存在I/O瓶颈
2. 若 %idle 的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量
3. 若 %idle 的值持续低于1,则系统的 CPU
-v inode、文件和其他内核表监控
-r 内存和交换空间监控
-B 内存分页监控
-b I/O和传送速率监控
-q 进程队列长度和平均负载状态监控
-W 系统交换活动信息监控
-d 设备使用情况监控
抓包以包为单位进行输出。and做且条件
tcpdump -i eth1 host 192.168.1.1 and port 80
抓包以流为单位显示数据内容
tcpflow -cp host 192.168.1.1
1.4.5 关于系统负载
查看负载情况
uptime
top
vmstat
统计系统调用耗时情况
strace -c -p pid
跟踪指定的系统操作例如epoll_wait
strace -T -e epoll_wait -p pid
查看内核日志信息
dmesg
1.4.6 关于火焰图
cpu占用过高,或者使用率提不上来,你能快速定位到代码的哪块有问题吗?
一般的做法可能就是通过日志等方式去确定问题。现在我们有了火焰图,能够非常清晰的发现哪个函数占用cpu过高,或者过低导致的问题。
火焰图的安装
火焰图(flame graph)是性能分析的利器,通过它可以快速定位性能瓶颈点。
perf 命令(performance 的缩写)是 Linux 系统原生提供的性能分析工具,会返回 CPU 正在执行的函数名以及调用栈(stack)。
系统版本:Centos7.6
一、配置JAVA环境
二、安装perf
yum install perf -y
三、下载FlameGraph
yum install git -y
git clone https://github.com/brendangregg/FlameGraph.git
四、假设我们要对pid为3309的进程进行性能分析
perf record -F 99 -p 3309 -g -- sleep 20
perf script -i perf.data &> perf.unfold
./FlameGraph/stackcollapse-perf.pl perf.unfold &> perf.folded
./FlameGraph/flamegraph.pl perf.folded > perf.svg
这个perf.svg是一张图片,里面包含了很多可以用来分析性能的信息,直接在浏览器打开即可
1.5 优化基础
1.5.1 最大文件打开数
1.6 安全基础
2. WEB管理
2.1 Nginx
2.1.1 部署
自动化在线编译安装脚本(已验证)
#!/bin/bash
yum install wget -y
wget -c http://nginx.org/download/nginx-1.14.0.tar.gz #下载nginx安装包,这里需要根据自己的情况修改这个URL
tar -zxvf nginx-1.14.0.tar.gz #解压
cd nginx-1.14.0/
yum -y install gcc-c++ pcre-devel zlib-devel openssl-devel #安装依赖
#prefix选项是指安装位置,--sbin-path指定nginx可运行文件存放位置,--conf-path指定配置存放位置,--pid-path指定pid存放位置,同时启用https模块http_ssl_module
./configure --prefix=/usr/local/nginx --sbin-path=/usr/local/nginx/sbin/nginx --conf-path=/usr/local/nginx/conf/nginx.conf --pid-path=/usr/local/nginx/nginx.pid --with-http_ssl_module
make
make install
cd /usr/local/nginx/sbin
./nginx #启动服务
systemctl stop firewalld #关闭防火墙
setenforce 0 #关闭selinux
echo "-----------Nginx安装完成------------"
echo "-----------Nginx已启动------------"
2.1.2 优化
2.1.3 备份
2.1.4 恢复
2.1.5 架构
2.2 Httpd
2.2.1 部署
yum install httpd -y
2.2.2 优化
2.2.3 备份
2.2.4 恢复
2.2.5 架构
2.3 Tomcat
2.3.1 部署
相关jdk包和tomcat包下载地址
链接:https://pan.baidu.com/s/18QQ0vj1pm_fLrVRPeGOHdA
提取码:3zjx
一键安装脚本
[root@k8s-node02 ~]# cat installtomcat.sh
#!/bin/bash
tar -zxvf jdk-8u111-linux-x64.tar.gz -C /usr/local/
cat >> /etc/profile <<EOF
AVA_HOME=/usr/local/jdk1.8.0_111
JRE_HOME=/usr/local/jdk1.8.0_111/jre
CLASS_PATH=.:/\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar:\$JRE_HOME/lib
PATH=\$PATH:\$JAVA_HOME/bin:\$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
EOF
source /etc/profile
tar -zxvf apache-tomcat-9.0.33.tar.gz -C /usr/local/
cd /usr/local/apache-tomcat-9.0.33/bin
./startup.sh
2.3.2 优化
2.3.3 备份
2.3.4 恢复
2.3.5 架构
2.4 IIS
2.4.1 部署
2.4.2 优化
2.4.3 备份
2.4.4 恢复
2.4.5 架构
3. 数据库
3.1 MySQL
3.1.1 部署
mysql版本5.7
wget https://repo.mysql.com//mysql80-community-release-el7-3.noarch.rpm rpm -Uvh mysql80-community-release-el7-3.noarch.rpm sed -i '21c enabled=1' /etc/yum.repos.d/mysql-community.repo sed -i '28c enabled=0' /etc/yum.repos.d/mysql-community.repo yum clean all yum install mysql-server mysql -y systemctl start mysqld cat /var/log/mysqld.log |grep pass
MyISAM 采用的是表级锁机制,而 InnoDB 是行级锁机制,通常情况下 InnoDB 具有更高的写入效率。
表级锁是 MySQL 中锁定粒度最大的一种锁,表示对当前操作的整张表加锁。
行级锁是 MySQL 中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。
MyISAM 对数据完整性的保护存在缺陷,且这些缺陷会导致数据库数据的损坏甚至丢失。另外,这些缺陷很多是设计问题,无法在不破坏兼容性的前提下修复。
MyISAM 的发展在向 InnoDB 转移,在最新的官方 MySQL 8.0 版本中,系统表均已采用 InnoDB。
MySQL如何确保数据不丢失?
只要 redo log 和 binlog 保证持久化到磁盘,就能确保 MySQL 异常重启后,数据可以恢复。
binlog 的写入逻辑比较简单:事务执行过程中,先把日志写到 binlog cache,事务提交的时候,再把 binlog cache 写到 binlog 文件中。
一个事务的 binlog 是不能被拆开的,因此不论这个事务多大,也要确保一次性写入。系统给 binlog cache 分配了一片内存,每个线程一个,参数 binlog_cache_size 用于控制单个线程内 binlog cache 所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
事务提交的时候,执行器把 binlog cache 里的完整事务写入到 binlog 中,并清空 binlog cache。

可以看到,每个线程有自己 binlog cache,但是共用同一份 binlog 文件。
write,指的就是指把日志写入到文件系统的 page cache,并没有把数据持久化到磁盘,所以速度比较快。
fsync,才是将数据持久化到磁盘的操作。一般情况下,我们认为 fsync 才占磁盘的 IOPS。
write 和 fsync 的时机,是由参数 sync_binlog 控制的:
sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;
sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
因此,在出现 IO 瓶颈的场景里,将 sync_binlog 设置成一个比较大的值,可以提升性能。在实际的业务场景中,考虑到丢失日志量的可控性,一般不建议将这个参数设成 0,比较常见的是将其设置为 100~1000 中的某个数值。
但是,将 sync_binlog 设置为 N,对应的风险是:如果主机发生异常重启,会丢失最近 N 个事务的 binlog 日志。
接下来,我们再说说 redo log 的写入机制。
我们先明确一下InnoDB的修改数据的基本流程,当我们想要修改DB上某一行数据的时候,InnoDB是把数据从磁盘读取到内存的缓冲池上进行修改。这个时候数据在内存中被修改,与磁盘中相比就存在了差异,我们称这种有差异的数据为脏页。InnoDB对脏页的处理不是每次生成脏页就将脏页刷新回磁盘,这样会产生海量的IO操作,严重影响InnoDB的处理性能。对于此,InnoDB有一套完善的处理策略,与我们这次主题关系不大,表过不提。既然脏页与磁盘中的数据存在差异,那么如果在这期间DB出现故障就会造成数据的丢失。为了解决这个问题,redo log就应运而生了。
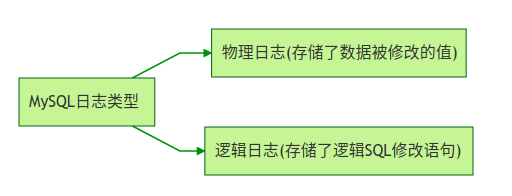
redo log在数据库重启恢复的时候被使用,因为其属于物理日志的特性,恢复速度远快于逻辑日志。而我们经常使用的binlog就属于典型的逻辑日志。
checkpoint
坦白来讲checkpoint本身是比较复杂的,checkpoint所做的事就是把脏页给刷新回磁盘。所以,当DB重启恢复时,只需要恢复checkpoint之后的数据。这样就能大大缩短恢复时间。当然checkpoint还有其他的作用。
LSN(Log Sequence Number)
LSN实际上就是InnoDB使用的一个版本标记的计数,它是一个单调递增的值。数据页和redo log都有各自的LSN。我们可以根据数据页中的LSN值和redo log中LSN的值判断需要恢复的redo log的位置和大小。
工作原理
好的,现在我们来看看redo log的工作原理。说白了,redo log就是存储了数据被修改后的值。当我们提交一个事务时,InnoDB会先去把要修改的数据写入日志,然后再去修改缓冲池里面的真正数据页。
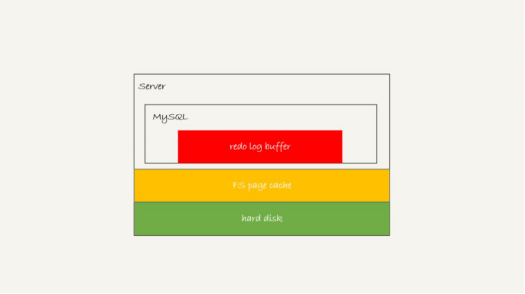
存在 redo log buffer 中,物理上是在 MySQL 进程内存中,就是图中的红色部分;
写到磁盘 (write),但是没有持久化(fsync),物理上是在文件系统的 page cache 里面,也就是图中的黄色部分;
持久化到磁盘,对应的是 hard disk,也就是图中的绿色部分。
日志写到 redo log buffer 是很快的,wirte 到 page cache 也差不多,但是持久化到磁盘的速度就慢多了。
为了控制 redo log 的写入策略,InnoDB 提供了 innodb_flush_log_at_trx_commit 参数,它有三种可能取值:
设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 ;
设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘;
设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 page cache。
InnoDB 有一个后台线程,每隔 1 秒,就会把 redo log buffer 中的日志,调用 write 写到文件系统的 page cache,然后调用 fsync 持久化到磁盘。
注意,事务执行中间过程的 redo log 也是直接写在 redo log buffer 中的,这些 redo log 也会被后台线程一起持久化到磁盘。也就是说,一个没有提交的事务的 redo log,也是可能已经持久化到磁盘的。
宕机恢复
DB宕机后重启,InnoDB会首先去查看数据页中的LSN的数值。这个值代表数据页被刷新回磁盘的LSN的大小。然后再去查看redo log的LSN的大小。如果数据页中的LSN值大说明数据页领先于redo log刷新回磁盘,不需要进行恢复。反之需要从redo log中恢复数据。
MySQL 支持三种数据复制方式:
异步复制
应用发起数据更新(含 insert、update、delete 操作)请求,Master 在执行完更新操作后立即向应用程序返回响应,然后 Master 再向 Slave 复制数据。
数据更新过程中 Master 不需要等待 Slave 的响应,因此异步复制的数据库实例通常具有较高的性能,且 Slave 不可用并不影响 Master 对外提供服务。但因数据并非实时同步到 Slave,而 Master 在 Slave 有延迟的情况下发生故障则有较小概率会引起数据不一致。
(简单理解为,对外完成请求了才进行同步,所以有可能导致数据不一致)
半同步复制
应用发起数据更新(含 insert、update、delete 操作)请求,Master 在执行完更新操作后立即向 Slave 复制数据,Slave 接收到数据并写到 relay log 中(无需执行) 后才向 Master 返回成功信息,Master 必须在接受到 Slave 的成功信息后再向应用程序返回响应。
仅在数据复制发生异常(Slave 节点不可用或者数据复制所用网络发生异常)的情况下,Master 会暂停(MySQL 默认10秒左右)对应用的响应,将复制方式降为异步复制。当数据复制恢复正常,将恢复为半同步复制。
(执行了外部请求,完成同步后,才对应用程序返回响应。但是出现异常的时候,有可能进行降级复制,变为异步复制,导致主从数据不一定完全一致)
强同步复制
应用发起数据更新(含 insert、update、delete 操作)请求,Master 在执行完更新操作后立即向 Slave 复制数据,Slave 接收到数据并执行完 后才向 Master 返回成功信息,Master 必须在接受到 Slave 的成功信息后再向应用程序返回响应。
因 Master 向 Slave 复制数据是同步进行的,Master 每次更新操作都需要同时保证 Slave 也成功执行,因此强同步复制能最大限度的保障主从数据的一致性。但因每次 Master 更新请求都强依赖于 Slave 的返回,因此 Slave 如果仅有单台,它不可用将会极大影响 Master 上的操作。
(主从数据必须完成同步后,才可以对外返回响应)
云数据库 MySQL 使用规范
按需授权:一般应用程序只授权 DML(SELECT、UPDATE、INSERT、DELETE)权限即可。
指定访问源:指定可以访问数据库的IP地址
禁用弱密码:提升数据库实例安全性。
避免实例跑多个业务:耦合度太高会存在业务之间互相影响的风险。
建议关闭事务自动提交:线上操作养成begin,commit,降低误操作导致数据丢失的风险
存在自增列的表,自增列上必须存在一个单独的索引,若在复合索引中,自增列必须置于第一位。
每张表必须要有主键:即使选不出合适的列做主键,亦必须添加一个无意义的列做主键,MySQL 第一范式标准 InnoDB 辅助索引叶子节点会保存一份主键值,推荐用自增短列作为主键,降低索引所占磁盘空间提升效率,binlog_format为 row 的场景下,批量删数据没主键会导致严重的主从延迟。
字段尽量定义为 NOT NULL 并加上默认值:NULL 会给 SQL 开发带来很多问题导致走不了索引,对 NULL 计算时只能用 IS NULL 和 IS NOT NULL 来判断。
建库原则:同一类业务的表放一个库,不同业务的表尽量避免公用同一个库,尽量避免在程序中执行跨库的关联操作
字符集统一使用 utf8mb4 :降低乱码风险,部分复杂汉字和 emoji 表情必须使用 utf8mb4 方可正常显示,修改字符集只对修改后创建的表生效,故建议新购云数据库 MySQL 初始化实例时即选择 utf8mb4。
小数字段推荐使用 decimal 类型:float 和 double 精度不够,特别是涉及金钱的业务,必须使用 decimal。
尽量避免数据库中使用 text/blob 来存储大段文本、二进制数据、图片、文件等内容:而是将这些数据保存成本地磁盘文件,数据库中只保存其索引信息。
尽量不使用外键,建议在应用层实现外键的逻辑,外键与级联更新不适合高并发场景,降低插入性能,大并发下容易产生死锁。
降低业务逻辑和数据存储的耦合度,数据库存储数据为主,业务逻辑尽量通过应用层实现,尽可能减少对存储过程、触发器、函数、event、视图等高级功能的使用,这些功能移植性、可扩展性较差。
短期内业务达不到一个比较大的量级,建议禁止使用分区表。分区表主要用作归档管理,多用于快递行业和电商行业订单表,分区表没有提升性能的作用, 除非业务中80%以上的查询走分区字段。
对读压力较大,且一致性要求较低(接受数据秒级延时)的业务场景,建议购买只读实例从库来实现读写分离策略。
禁止在更新十分频繁、区分度不高的列上建立索引,记录更新会变更 B+ 树,更新频繁的字段建立索引会大大降低数据库性能。
建复合索引时,区分度最高的列放索引的最左边,例如select xxx where a = x and b = x;,a 和 b 一起建组合索引,a 的区分度更高,则建idx_ab(a,b)。存在非等号和等号混合判断条件时,必须把等号条件的列前置,例如,where a xxx and b = xxx那么即使 a 的区分度更高,也必须把 b 放在索引的最前列,因为走不到索引 a。
单表的索引数建议不超过5个,单个索引中的字段数建议不超过5个,太多起不到过滤作用,索引也占空间,管理起来也耗资源。
选择业务中 SQL 过滤走的最多的并且 cardinality 值比较高的列建索引,业务 SQL 不走的列建索引是无意义的,字段的唯一性越高即代表 cardinality 值越高,索引过滤效果也越好,一般索引列的 cardinality 记录数小于10%我们可认为这是一个低效索引,例如性别字段。
varchar 字段上建索引时,建议指定索引长度,不要直接将整个列建索引,一般 varchar 列比较长,指定一定长度作索引已经区分度够高,没必要整列建索引,整列建索引会显得比较重,增大了索引维护的代价,可以用 count(distinct left(列名, 索引长度))/count(*) 来看索引区分度。
拒绝select *:
无法索引覆盖,回表操作,增加 I/O。
额外的内存负担,大量冷数据灌入innodb_buffer_pool_size,降低查询命中率。
额外的网络传输开销。
尽量避免使用大事务,建议大事务拆小事务,规避主从延迟。
业务代码中事务及时提交,避免产生没必要的锁等待。
少用多表 join,大表禁止 join,两张表 join 必须让小表做驱动表,join 列必须字符集一致并且都建有索引。
LIMIT 分页优化,LIMIT 80000,10这种操作是取出80010条记录,再返回后10条,数据库压力很大,推荐先确认首记录的位置再分页,例如SELECT * FROM test WHERE id = ( SELECT sql_no_cache id FROM test order by id LIMIT 80000,1 ) LIMIT 10 ;。
避免多层子查询嵌套的 SQL 语句
监控上发现全表扫描的量比较大,可以在控制台参数设置log_queries_not_using_indexes,分析慢日志文件,但不要开太久以免慢日志暴增。
业务上线之前做有必要的 SQL 审核,日常运维需定期下载慢查询日志做针对性优化。
MySQL CPU 利用率过高,大部分原因与低效 SQL 有关系,通过优化低效 SQL 基本可以解决大部分问题。
MySQL 慢查询时间(long_query_time)的默认值是10s,在遇到性能问题时,若发现没有慢查询,建议将其参数调成1s ,再观察业务周期内的慢查询,进而对其慢查询进行优化。若参数调整后,在其业务周期内依然未发现慢查询,而 CPU 利用率依然偏高,建议升级 CPU 的配置,进而提高数据库的整体性能。
内存利用率过高
一些特殊的 SQL 或字段类型会导致单个线程可能分配多次缓存,因此当出现 OOM 异常,都是由各个连接的私有内存造成的,通过限制数据库的连接数和优化低效 SQL,可降低内存利用率过高的风险,若 MySQL 的内存利用率依然过高,可通过升级内存配置来提升数据库的整体并发量和稳定性。详细的内存参数介绍
主从延迟
若 binlog 为 row 格式且表无主键或二级索引,当对大表进行 DML 操作(例如 delete、update、insert),在从库进行 binlog 日志应用时,会根据主键或者二级索引来检索需要更改的行,如对应表未创建主键或者二级索引,会产生大量的全表扫描进而降低了日志应用速度,从而产生数据延迟。
解决方案
为所有表创建主键,若表无法创建主键,建议选择基数高的列创建二级索引。
建议采用 truncate 命令删除表所有记录。
大事务
原因
当主实例执行大数据量的 DML 操作,大量的 binlog 日志传送到从库时,从库需要花费与主实例相同的时间来完成相应事务,进而导致从库出现数据延迟。
解决方案
建议将大事务拆分为小事务,通过 where 条件限制每次要处理的数据量,有助于从库迅速完成事务的执行,从而避免出现从库数据的延迟。
DDL 操作
原因
与大事务原理类似,若 DDL 操作在主实例的执行时间很长,在从库也会花费相同甚至更长时间来执行该操作,从而阻塞了 DDL 操作。
解决方案
建议在业务低峰期执行 DDL 操作。若因灾备实例、只读实例的查询业务而阻塞了 DDL 操作,建议直接 KILL 掉引起阻塞的会话来恢复主从数据的同步。
实例规格过小
原因
只读实例、灾备实例的规格小于主实例且负载较高,会导致只读实例、灾备实例的数据延迟。
解决方案
建议只读实例、灾备实例规格大于等于主实例,如果只读实例、灾备实例承载了大量的分析类业务导致实例负载过高,需将其实例规格升级至合适的配置或者对其性能低效的 SQL 进行优化。
常见参数修改以及意义
character_set_server
默认值:LATIN1
是否需要重启:是
作用:用于配置 MySQL 服务器的默认字符集。云数据库 MySQL 提供4种字符集,分别为 LATIN1、UTF8、GBK、UTF8MB4,其中 LATIN1 支持英文字符,一个字符占用一个字节;UTF8 包含全世界所有国家需要用到的字符,是国际编码,通用性强,一个字符占用三个字节;GBK 的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示;UTF8MB4 作为 UTF8 的超集,完全向下兼容,一个字符占用四个字节,且支持 emoji 表情。
建议:购买实例后,根据业务所需要支持的数据格式选择适合的字符集,确保客户端与服务器端设置相同的字符集,避免因字符集设置不正确而引发乱码的问题和不必要的重启操作。
lower_case_table_names
默认值:0
是否需要重启:是
作用:创建数据库及表时,存储与查询时是否大小写敏感。该参数可以设置的值为0、1,默认的参数值为0,表示创建数据库及表时,存储与查询均区分大小写,反之则不做区分。
建议:数据库 MySQL 默认大小写敏感,请根据您的业务需求及使用习惯进行合理的配置。
sql_mode
默认值:NO_ENGINE_SUBSTITUTION(5.6版本),ONLY_FULL_GROUP_BY、STRICT_TRANS_TABLES、NO_ZERO_IN_DATE、NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO、NO_AUTO_CREATE_USER、NO_ENGINE_SUBSTITUTION(5.7版本)
是否需要重启:否
作用:MySQL 可以运行在不同 sql 模式,sql 模式定义了 mysql 应该支持的 sql 语法、数据校验等。
该参数5.6版本的默认参数值为NO_ENGINE_SUBSTITUTION,表示使用的存储引擎被禁用或未编译则抛出错误;5.7版本的默认参数值为ONLY_FULL_GROUP_BY、STRICT_TRANS_TABLES、NO_ZERO_IN_DATE、NO_ZERO_DATE、ERROR_FOR_DIVISION_BY_ZERO、NO_AUTO_CREATE_USER、NO_ENGINE_SUBSTITUTION。
其中:
ONLY_FULL_GROUP_BY表示在 GROUP BY 聚合操作时,如果在 SELECT 中的列、HAVING 或者 ORDER BY 子句的列,必须是 GROUP BY 中出现或者依赖于 GROUP BY 列的函数列。
STRICT_TRANS_TABLES为启用严格模式;NO_ZERO_IN_DATE 是否允许日期中的月份和日包含 0,且受是否开启严格模式的影响。
NO_ZERO_DATE数据库不允许插入零日期,且受是否开启严格模式的影响。
ERROR_FOR_DIVISION_BY_ZERO在严格模式下,INSERT 或 UPDATE 过程中,如果数据被零除,则产生错误而非警告,而非严格模式下,数据被零除时 MySQL 返回 NULL。
NO_AUTO_CREATE_USER禁止 GRANT 创建密码为空的用户。
NO_ENGINE_SUBSTITUTION使用的存储引擎被禁用或者未编译则抛出错误。
建议:由于不同的 SQL 模式支持不同的 SQL 语法,建议根据您的业务场景及开发习惯进行合理的配置。
long_query_time
默认值:10
是否需要重启:否
作用:用于指定慢查询的界定时间,默认值为10s。当某个查询执行时间为10s及以上,该查询的执行情况会记录于慢日志中,便于过后对慢查询进行分析。
建议:基于客户业务场景及性能敏感度不同,建议根据各自业务场景设置合理的值,以便事后进行性能分析。
3.1.2 优化
3.1.3 备份
3.1.4 恢复
3.1.5 架构
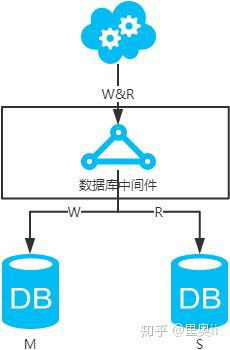
方案一:主备架构,只有主库提供读写服务,备库冗余作故障转移用
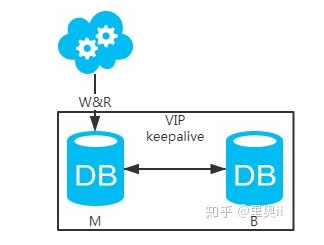
高可用分析:高可用,主库挂了,keepalive(只是一种工具)会自动切换到备库。这个过程对业务层是透明的,无需修改代码或配置。
高性能分析:读写都操作主库,很容易产生瓶颈。大部分互联网应用读多写少,读会先成为瓶颈,进而影响写性能。另外,备库只是单纯的备份,资源利用率50%,这点方案二可解决。
一致性分析:读写都操作主库,不存在数据一致性问题。
扩展性分析:无法通过加从库来扩展读性能,进而提高整体性能。
可落地分析:两点影响落地使用。第一,性能一般,这点可以通过建立高效的索引和引入缓存来增加读性能,进而提高性能。这也是通用的方案。第二,扩展性差,这点可以通过分库分表来扩展。
方案二:双主架构,两个主库同时提供服务,负载均衡
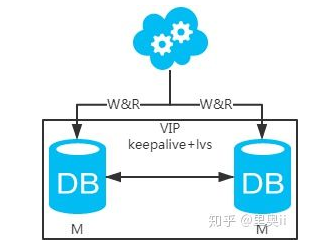
高可用分析:高可用,一个主库挂了,不影响另一台主库提供服务。这个过程对业务层是透明的,无需修改代码或配置。
高性能分析:读写性能相比于方案一都得到提升,提升一倍。
一致性分析:存在数据一致性问题。请看,一致性解决方案。
扩展性分析:当然可以扩展成三主循环,但笔者不建议(会多一层数据同步,这样同步的时间会更长)。如果非得在数据库架构层面扩展的话,扩展为方案四。
可落地分析:两点影响落地使用。第一,数据一致性问题,一致性解决方案可解决问题。第二,主键冲突问题,ID统一地由分布式ID生成服务来生成可解决问题。
方案三:主从架构,一主多从,读写分离
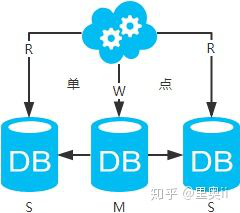
高可用分析:主库单点,从库高可用。一旦主库挂了,写服务也就无法提供。
高性能分析:大部分互联网应用读多写少,读会先成为瓶颈,进而影响整体性能。读的性能提高了,整体性能也提高了。另外,主库可以不用索引,线上从库和线下从库也可以建立不同的索引(线上从库如果有多个还是要建立相同的索引,不然得不偿失;线下从库是平时开发人员排查线上问题时查的库,可以建更多的索引)。
一致性分析:存在数据一致性问题。请看,一致性解决方案。
扩展性分析:可以通过加从库来扩展读性能,进而提高整体性能。(带来的问题是,从库越多需要从主库拉取binlog日志的端就越多,进而影响主库的性能,并且数据同步完成的时间也会更长)
可落地分析:两点影响落地使用。第一,数据一致性问题,一致性解决方案可解决问题。第二,主库单点问题,笔者暂时没想到很好的解决方案。
注:思考一个问题,一台从库挂了会怎样?读写分离之读的负载均衡策略怎么容错?
方案四:双主+主从架构,看似完美的方案

高可用分析:高可用。
高性能分析:高性能。
一致性分析:存在数据一致性问题。请看,一致性解决方案。
扩展性分析:可以通过加从库来扩展读性能,进而提高整体性能。(带来的问题同方案二)
可落地分析:同方案二,但数据同步又多了一层,数据延迟更严重。
一致性解决方案
第一类:主库和从库一致性解决方案
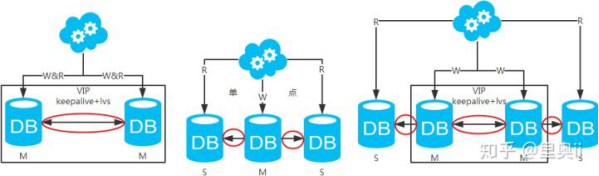
注:图中圈出的是数据同步的地方,数据同步(从库从主库拉取binlog日志,再执行一遍)是需要时间的,这个同步时间内主库和从库的数据会存在不一致的情况。如果同步过程中有读请求,那么读到的就是从库中的老数据。如下图。
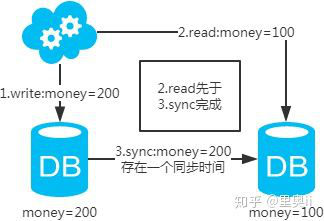
既然知道了数据不一致性产生的原因,有下面几个解决方案供参考:
1、直接忽略,如果业务允许延时存在,那么就不去管它。
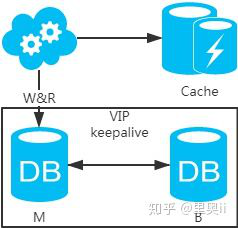
2、强制读主,采用主备架构方案,读写都走主库。用缓存来扩展数据库读性能 。有一点需要知道:如果缓存挂了,可能会产生雪崩现象,不过一般分布式缓存都是高可用的。
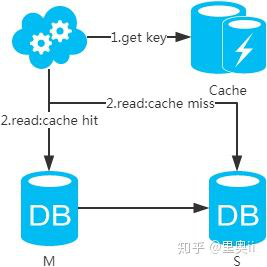
3、选择读主,写操作时根据库+表+业务特征生成一个key放到Cache里并设置超时时间(大于等于主从数据同步时间)。读请求时,同样的方式生成key先去查Cache,再判断是否命中。若命中,则读主库,否则读从库。代价是多了一次缓存读写,基本可以忽略。
4、半同步复制,等主从同步完成,写请求才返回。就是大家常说的“半同步复制”semi-sync。这可以利用数据库原生功能,实现比较简单。代价是写请求时延增长,吞吐量降低。
5、数据库中间件,引入开源(mycat等)或自研的数据库中间层。个人理解,思路同选择读主。数据库中间件的成本比较高,并且还多引入了一层。
第二类:DB和缓存一致性解决方案
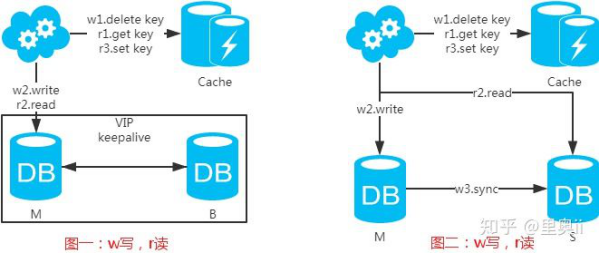
先来看一下常用的缓存使用方式:
第一步:淘汰缓存;
第二步:写入数据库;
第三步:读取缓存?返回:读取数据库;
第四步:读取数据库后写入缓存。
注:如果按照这种方式,图一,不会产生DB和缓存不一致问题;图二,会产生DB和缓存不一致问题,即4.read先于3.sync执行。如果不做处理,缓存里的数据可能一直是脏数据。解决方式如下:
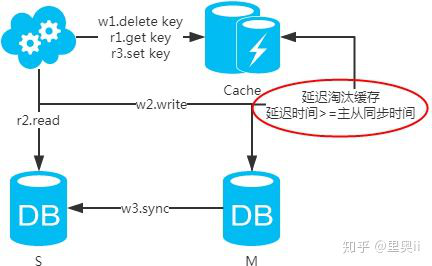
注:设置缓存时,一定要加上失效时间,以防延时淘汰缓存失败的情况!
个人见解
1、加缓存和索引是通用的提升数据库性能的方式;
2、分库分表带来的好处是巨大的,但同样也会带来一些问题,详见MySQL数据库之互联网常用分库分表方案(https://www.cnblogs.com/littlecharacter/p/9342129.html)
3、不管是主备+分库分表还是主从+读写分离+分库分表,都要考虑具体的业务场景。某8到家发展四年,绝大部分的数据库架构还是采用方案一和方案一+分库分表,只有极少部分用方案三+读写分离+分库分表。另外,阿里云提供的数据库云服务也都是主备方案,要想主从+读写分离需要二次架构。
4、记住一句话:不考虑业务场景的架构都是耍流氓。
参考链接:https://zhuanlan.zhihu.com/p/98546065
3.2 Oracle
3.2.1 部署
3.2.2 优化
3.2.3 备份
3.2.4 恢复
3.2.5 架构
3.3 MongoDB
3.3.1 部署
3.3.2 优化
3.3.3 备份
3.3.4 恢复
3.3.5 架构
3.4 Redis
3.4.1 部署
一键部署脚本
#!/bin/bash wget -c http://download.redis.io/releases/redis-3.2.9.tar.gz #下载源码 tar -xvf redis-3.2.9.tar.gz #解压 cd redis-3.2.9/ make #编译,如果报zmalloc.h:50:31: 致命错误:jemalloc/jemalloc.h:没有那个文件或目录之类的错误,执行make MALLOC=libc make install #安装 ./utils/install_server.sh #安装并启动服务,直接回车默认即可
3.4.2 优化
3.4.3 备份
3.4.4 恢复
3.4.5 架构
3.5 Memcached
3.5.1 部署
安装包下载地址
链接:https://pan.baidu.com/s/1vehZ5odzXFKwNjWT9_W0TA
提取码:bsk9
将以上文件下载到root家目录下
一键部署脚本
#!/bin/bash yum install -y apr* autoconf automake bison cloog-ppl compat* cpp curl curl-devel fontconfig fontconfig-devel freetype freetype* freetype-devel gcc gcc-c++ gtk+-devel gd gettext gettext-devel glibc kernel kernel-headers keyutils keyutils-libs-devel krb5-devel libcom_err-devel libpng* libjpeg* libsepol-devel libselinux-devel libstdc++-devel libtool* libgomp libxml2 libxml2-devel libXpm* libtiff libtiff* libX* make mpfr ncurses* ntp openssl openssl-devel patch pcre-devel perl php-common php-gd policycoreutils ppl telnet t1lib t1lib* nasm nasm* wget zlib-devel gmp-devel tar -zxvf libevent-2.0.22-stable.tar.gz cd libevent-2.0.22-stable ./configure --prefix=/usr/local/libevent make make install cdtar -zxvf memcached-1.4.25.tar.gz cd memcached-1.4.25 ./configure --prefix=/usr/local/memcached -with-libevent=/usr/local/libevent make make install groupadd memcached useradd -g memcached memcached -s /bin/false ln -s /usr/local/memcached/bin/memcached /usr/local/bin/memcached /usr/local/memcached/bin/memcached -d -m 4096 -u root -l 127.0.0.1 -p 11211 -c 1024 -P /usr/local/memcached/memcached.pid
3.5.2 优化
3.5.3 备份
3.5.4 恢复
3.5.5 架构
4. 消息队列
4.1 ActiveMQ
4.1.1 部署
4.1.2 优化
4.1.3 备份
4.1.4 恢复
4.1.5 架构
4.2 RabbitMQ
4.2.1 部署
安装包下载地址:
链接:https://pan.baidu.com/s/1dQjSCQz_HmMKHRFEnmvGvA
提取码:4n3a
一键部署脚本
yum install gcc-c++ ncurses-devel fop unixODBC-devel mesa-libGLU-devel gtk3* bzip2 openssl openssl-devel make perl -y #安装依赖 bzip2 -d wxWidgets-3.1.3.tar.bz2 #解压 tar -xvf wxWidgets-3.1.3.tar #解压 cd wxWidgets-3.1.3 ./configure #编译安装 make & make install ldconfig #重新加载动态库 cd .. tar -zxvf otp_src_22.1.tar.gz cd otp_src_22.1 ./configure --prefix=/usr/local/erlang --without-javac make make install echo 'export PATH=$PATH:/usr/local/erlang/bin'>> /etc/profile #加入系统PATH source /etc/profile erl #不报错说明安装成功 cd xz -d rabbitmq-server-generic-unix-3.8.3.tar.xz tar -xvf rabbitmq-server-generic-unix-3.8.3.tar cd rabbitmq_server-3.8.3/ cd sbin/ #相关命令都在这里,可以考虑把这个路径计入系统PATH ./rabbitmq-server #不报错,说明rabbitmq安装成功
4.2.2 优化
4.2.3 备份
4.2.4 恢复
4.2.5 架构
5. 监控
5.1 Zabbix
5.1.1 部署
部署脚本如下
写好如下两个脚本,只需要执行zabbix部署脚本即可。mysql初始化脚本会被自动调用
mysql初始化脚本mysqlpasswd.sh
#!/usr/bin/expect spawn mysql_secure_installation expect "Enter current password for root (enter for none):" send "\r" expect "Set root password? " send "Y\r" expect "New password:" send "123456\r" expect "Re-enter new password:" send "123456\r" expect "Remove anonymous users? " send "y\r" expect "Disallow root login remotely? " send "n\r" expect "Remove test database and access to it? " send "y\r" expect "Reload privilege tables now? " send "y\r" expect eof
zabbix部署脚本
rpm -Uvh https://repo.zabbix.com/zabbix/4.0/rhel/7/x86_64/zabbix-release-4.0-1.el7.noarch.rpm yum clean all yum -y install zabbix-server-mysql zabbix-web-mysql zabbix-agent mariadb mariadb-server httpd php php-fpm systemctl stop firewalld sed -i 's/=enforcing/=disabled/g' /etc/selinux/config #2019.5.6新增,不执行该语句,你会发现重启服务器后,zabbix服务器无法正常启动了 setenforce 0 systemctl start mariadb systemctl enable mariadb #新增,记住,一定要养成将服务器设置为自启动的状态,否则下次服务器重启后,你就得慢慢排错了。。。 yum install expect -y chmod +x mysqlpasswd.sh /root/mysqlpasswd.sh mysql -uroot -p123456 -e "create database zabbix character set utf8 collate utf8_bin;" mysql -uroot -p123456 -e "grant all privileges on zabbix.* to zabbix@localhost identified by 'zabbix'" zcat /usr/share/doc/zabbix-server-mysql*/create.sql.gz | mysql -uzabbix -pzabbix zabbix #如果提示文件不存在就执行find / -name create.sql.gz找到文件对应的位置 sed -i s/'# DBPassword='/'DBPassword=zabbix'/g /etc/zabbix/zabbix_server.conf sed -i s/'Europe\/Riga'/'Asia\/Shanghai'/g /etc/httpd/conf.d/zabbix.conf sed -i s/'# php_value date.timezone Asia\/Shanghai'/'php_value date.timezone Asia\/Shanghai'/g /etc/httpd/conf.d/zabbix.conf systemctl start zabbix-server zabbix-agent httpd #现在通过web访问ip/zabbix就可以看到安装界面了
5.2 Prometheus
5.2.1 部署
下载安装包
https://prometheus.io/download/
开始安装
[root@localhost ~]# tar -xvf prometheus-2.14.0.linux-amd64.tar.gz [root@localhost ~]# cd prometheus-2.14.0.linux-amd64 [root@localhost prometheus-2.14.0.linux-amd64]# cat prometheus.yml |grep 9090 #因为我需要在外部访问,所以把以下部分的localhost修改为服务器IP - targets: ['192.168.100.128:9090'] [root@localhost prometheus-2.14.0.linux-amd64]# ./prometheus
5.3 Cacti
5.4 Nagios
5.4.1 部署
建议一步步执行
yum install -y gcc gcc-c++ httpd php php-gd glibc glibc-common gd gd-devel perl perl-devel traceroute bind-utils ntpdate mtr wget nc mailx wget https://jaist.dl.sourceforge.net/project/nagios/nagios-4.x/nagios-4.1.0/nagios-4.1.0.tar.gz tar zxf nagios-4.1.0.tar.gz cd nagios-4.1.0/ useradd -m nagios passwd nagios groupadd nagcmd usermod -a -G nagcmd nagios usermod -a -G nagcmd apache ./configure –with-command-group=nagcmd make all make install make install-init make install-config make install-commandmode make install-webconf htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin //增加用户,回车后需要输入密码,登录nagios时需要这个帐号和密码 systemctl start httpd //开启服务 getenforce //需要把防火墙和selinux关闭,selinux关闭命令 setenforce 0,防火墙关闭命令systemctl stop firewalld,如何你都没有关闭就执行这两条命令 chkconfig –add nagios //添加到系统服务列表 service nagios start //开启服务,如果不行就使用systemctl start nagios
6. CI/CD
6.1 Jenkins
6.1.1 Jenkins实现CI/CD
使用Jenkins实现CI/CD.这个虽然是非常简单和基础的功能,但是我用了很长时间才摸着石头过了河.
本文使用的技术为:
Jenkins+Git+Maven+Tomcat
简单来说:
通过Jenkins拉取git仓库代码,使用远程命令将maven编译测试好的war包发送(发布)到远程Tomcat服务器上.
我这里是使用两台虚拟机,一台是Jenkins,一台是远程Tomcat
Jenkins/Git/Maven在同一台服务器上,所以下面的内容,需要根据你的具体情况做微调
具体步骤:
以下部分是配置Jenkins服务器
(1)下载安装包
下载jdk/jenkins/maven/tomcat到Jenkins服务器
相关安装包下载地址
链接:https://pan.baidu.com/s/1iMihWl5GKPSRLZ1UKgUXbg
提取码:mb3k
(2)部署java环境
tar -zxvf jdk-8u111-linux-x64.tar.gz
mv jdk1.8.0_111 /usr/local/jdk
修改/etc/profile文件,文件末尾增加以下内容
JAVA_HOME=/usr/local/jdk
JRE_HOME=/usr/local/jdk/jre
CLASS_PATH=.:/$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
添加完毕后,执行source /etc/profile使修改内容立即生效
执行java -version会显示刚刚安装的1.8.0_144那个版本
(3)安装tomcat
tar -zxvf apache-tomcat-9.0.33.tar.gz
(4)部署jenkins
cp jenkins.war apache-tomcat-9.0.33/webapps/
apache-tomcat-9.0.33/bin/startup.sh
(5)配置jenkins
http://Jenkins服务器ip:8080/jenkins
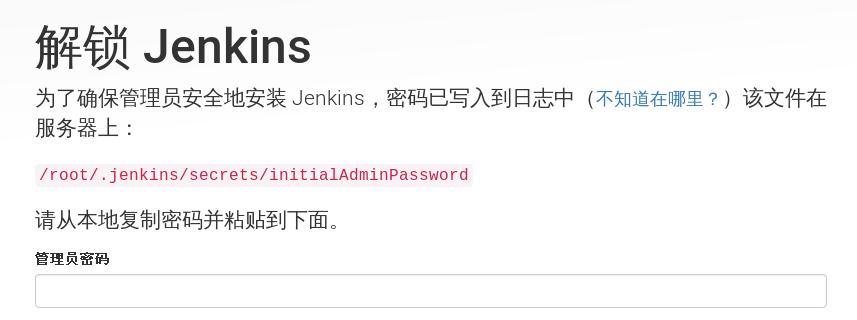
查看密钥
[root@130-node1 ~]# cat /root/.jenkins/secrets/initialAdminPassword
d2b1fcd02b374a6ca213a3e505c939d9
[root@130-node1 ~]#点击确认,在一路默认安装下去即可
建议使用谷歌浏览器进行安装.安装插件时如果提示失败,多重试几次即可
安装好后的jenkins界面
6.Jenkins服务器安装Git和Maven
git安装步骤:
yum install git -y
Maven安装步骤:
tar -zxvf apache-maven-3.6.3-bin.tar.gz
mv apache-maven-3.6.3 /usr/local/maven
配置/etc/profile
[root@130-node1 ~]# tail -n 6 /etc/profile JAVA_HOME=/usr/local/jdk JRE_HOME=/usr/local/jdk/jre CLASS_PATH=.:/$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib MAVEN_HOME=/usr/local/maven PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$MAVEN_HOME/bin export JAVA_HOME JRE_HOME CLASS_PATH PATH MAVEN_HOME [root@130-node1 ~]#
使配置生效source /etc/profile
验证是否安装成功
1 2 3 4 5 6 7 | [root@130-node1 ~]# mvn --versionApache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)Maven home: /usr/local/mavenJava version: 1.8.0_111, vendor: Oracle Corporation, runtime: /usr/local/jdk/jreDefault locale: zh_CN, platform encoding: UTF-8OS name: "linux", version: "3.10.0-1062.el7.x86_64", arch: "amd64", family: "unix"[root@130-node1 ~]# |
获取git和maven的命令所在位置
[root@130-node1 SayHi]# which git
/usr/bin/git
[root@130-node1 SayHi]# which mvn
/usr/local/maven/bin/mvn
[root@130-node1 SayHi]#
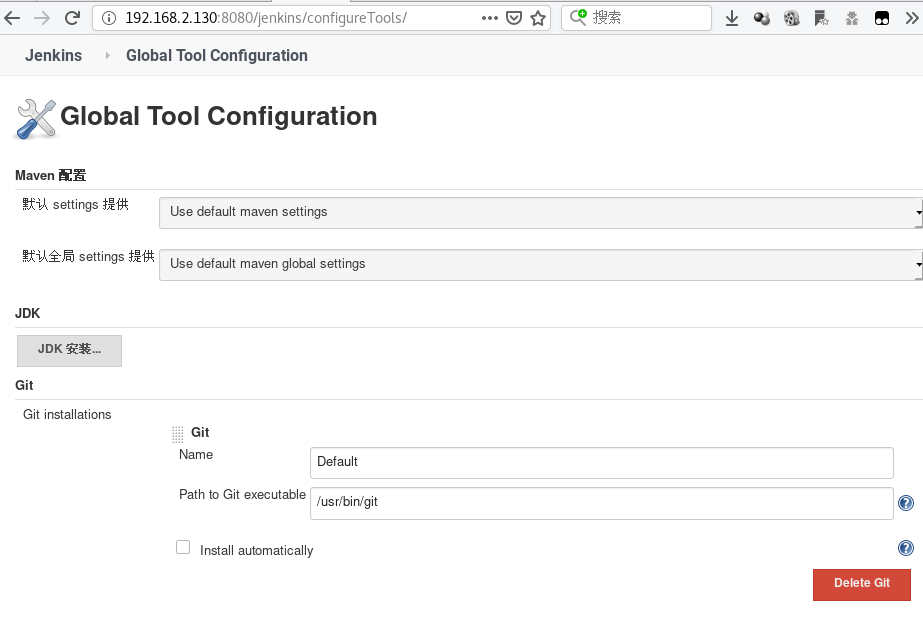
7.进入Jenkins配置git和maven
配置git
Manage Jenkins->Global Tool Configuration
配置maven
注意:要取消勾选自动安装,才会出现对应配置项

直接保存即可
8.Git服务器上新建Maven Web项目
我这里是在Jenkins服务器上执行.第一次执行需要下载很多东西,后面就好你.如果有提示错误,多尝试几次就可以

mvn archetype:generate -DgroupId=com.companyname.automobile -DartifactId=SayHi -DarchetypeArtifactId=maven-archetype-webapp -DinteractiveMode=false -DarchetypeCatalog=internal #SayHi是项目名,可自定义,报错的话可以多执行几次 cd SayHi/ mvn clean package
git init #我们需要将这个项目初始化为代码库
git add ./*
git config --global user.email "126@qq.com" #需要标记git用户,用来识别是谁提交的代码
git config --global user.name "bp"
git commit -m "add first code"
我们来看一下Maven Web项目结构
[root@130-node1 SayHi]# yum install tree -y
[root@130-node1 SayHi]# tree . |-- pom.xml |-- src | `-- main | |-- resources | `-- webapp | |-- index.jsp | `-- WEB-INF | `-- web.xml `-- target |-- classes |-- maven-archiver | `-- pom.properties |-- SayHi | |-- index.jsp | |-- META-INF | `-- WEB-INF | |-- classes | `-- web.xml `-- SayHi.war 12 directories, 7 files [root@130-node1 SayHi]# cat src/main/webapp/index.jsp <html> <body> <h2>Hello World!</h2> </body> </html> [root@130-node1 SayHi]#
我们的Web项目页面内容就是index.jsp.如果CI/CD成功的话,我们可以在远程Tomcat服务器上访问到这个页面
9.在Jenkins新增项目任务
创建一个新任务->选择freestyle project即可.
代码管理:
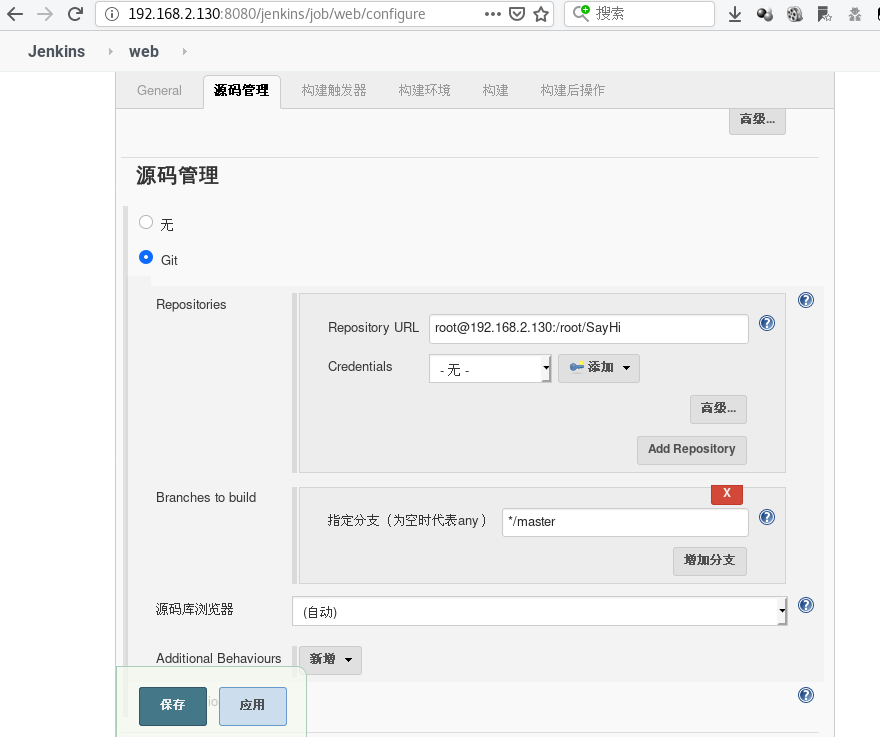
我没有使用用户帐号秘密凭证,直接通过ssh-copy-id免密登陆git服务器实现的(额,我这里直接ssh免密登陆本机...).通过帐号密码的话,一直会报错,搞不懂....
[root@130-node1 SayHi]# ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:76f9AbSe8JwIovcor9/wUJmE3KIKq8PPXoLTa8Jrnjs root@130-node1 The key's randomart image is: +---[RSA 2048]----+ | | | . o | | + o . | | . o o . . | |. . . S . o | | oo. . o o * + | |+o.o..+ o * . | |oE+.=. B . .. . | |+*O=.=+ + oo... | +----[SHA256]-----+ [root@130-node1 SayHi]# ssh-copy-id 192.168.2.130 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" The authenticity of host '192.168.2.130 (192.168.2.130)' can't be established. ECDSA key fingerprint is SHA256:esdK+w3MSmAlYRl8jeApc+l3TPkJT8ZPVgDt1rWxmkQ. ECDSA key fingerprint is MD5:dc:f6:b3:1b:a6:0d:fa:36:21:b8:85:7d:e9:bb:41:a7. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@192.168.2.130's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh '192.168.2.130'" and check to make sure that only the key(s) you wanted were added. [root@130-node1 SayHi]#
配置好git地址.输入git地址后,系统会自动检测地址是否正确,不正确会报错.要配置到不报错为止
我的git仓库地址root@192.168.2.130:/root/SayHi
配置构建:
点击构建,下拉选择Execute shell
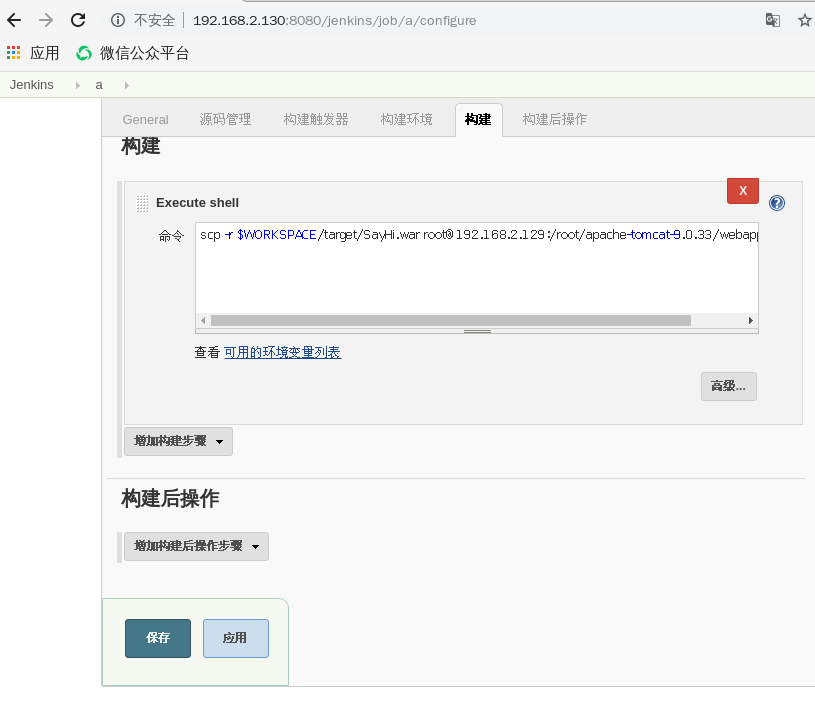
配置执行指定命令将war包发送到远程tomcat的webapp下
PS:请执行配置远程tomcat服务器,安装tomcat即可.可参考以下命令
[root@bp-vm webapps]# tail -n 6 /etc/profile JAVA_HOME=/usr/local/jdk JRE_HOME=$JAVA_HOME/jre CLASS_PATH=.:/$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib PATH=$PATH:$JAVA_HOME/bin:$JAVA_JRE/bin export JAVA_HOME JRE_HOME CLASS_PATh PATH export JAVA_HOME CLASS_HOME PATH [root@bp-vm webapps]# source /etc/profile [root@bp-vm webapps]# java -version java version "1.8.0_111" Java(TM) SE Runtime Environment (build 1.8.0_111-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode) [root@bp-vm webapps]#
继续配置我们的jenkins
因为我们需要使用scp传送文件,所以我们先配置好jenkins服务器可以免密钥登陆远程tomcat服务器
[root@130-node1 SayHi]# ssh-copy-id root@192.168.2.129 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" The authenticity of host '192.168.2.129 (192.168.2.129)' can't be established. ECDSA key fingerprint is SHA256:esdK+w3MSmAlYRl8jeApc+l3TPkJT8ZPVgDt1rWxmkQ. ECDSA key fingerprint is MD5:dc:f6:b3:1b:a6:0d:fa:36:21:b8:85:7d:e9:bb:41:a7. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@192.168.2.129's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'root@192.168.2.129'" and check to make sure that only the key(s) you wanted were added. [root@130-node1 SayHi]#
在构建部分,我使用的命令是scp -r $WORKSPACE/target/SayHi.war root@192.168.2.129:/root/apache-tomcat-9.0.33/webapps
5.开始构建
进入该项目,点击左侧的Build Now

这是我的构建日志.可以看到,构建成功的提示

6.确认是否正常发布到远程Tomcat服务器
在远程Tomcat上查看webapps目录,可以看到有一个SayHi.war,因为Tomcat处于运行状态,所以还自动解压出来你SayHi目录
[root@bp-vm webapps]# pwd
/root/apache-tomcat-9.0.33/webapps
[root@bp-vm webapps]# ls
docs examples host-manager manager ROOT SayHi SayHi.war
[root@bp-vm webapps]#
尝试访问远程Tomcat服务器服务
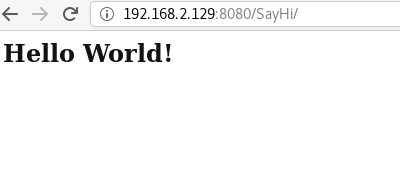
搞定!!!
Git仓库上(我这里的即是Git仓库服务器也是是Jenkins服务器)的Maven Web项目成功编译测试并发布到远程Tomcat服务器上,我们可以直接访问到发布的Web项目服务
7. 日志管理
7.1 ELK
7.1.1 部署
环境:Centos7.6最小化安装
配置:1C2G
下载好jdk和对应的elk包
[root@bp-vm ~]# ls
anaconda-ks.cfg jdk-8u111-linux-x64.tar.gz logstash-7.6.2.rpm
elasticsearch-7.6.2-x86_64.rpm kibana-7.6.2-x86_64.rpm
配置java环境
[root@bp-vm ~]#tar -zxf jdk-8u111-linux-x64.tar.gz -C /usr/local/
[root@bp-vm ~]# tail -n 5 /etc/profile
JAVA_HOME=/usr/local/jdk1.8.0_111
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jre:$JAVA_HOME/lib/tools.jre:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME
[root@bp-vm ~]# source /etc/profile
[root@bp-vm ~]#java -version
部署elasticsearch
[root@bp-vm ~]#yum install elasticsearch-7.6.2-x86_64.rpm -y
[root@bp-vm ~]# tail -n 7 /etc/elasticsearch/elasticsearch.yml #配置该文件
cluster.name: elk-stack
node.name: elk.com
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.2.133:9300"] #这个需要修改为自己的ip
discovery.zen.minimum_master_nodes: 1
cluster.initial_master_nodes: ["elk.com"] #和node.name一致
[root@bp-vm ~]#ss -ntlup| grep -E "9200|9300"

部署logstash
[root@bp-vm ~]#yum install logstash-7.6.2.rpm -y
[root@bp-vm ~]#echo 'path.config: /etc/logstash/conf.d' >>/etc/logstash/logstash.yml
[root@bp-vm ~]# cat /etc/logstash/conf.d/syslog.conf #配置该文件
input {
file {
type => "logtest"
path => "/var/log/messages"
start_position => "beginning"
}
beats {
port => 5044
}
}
#filter { }
output {
stdout {
codec => rubydebug { }
}
elasticsearch {
hosts => ["http://192.168.2.133:9200"] #修改为自己的ip
index => "%{type}-%{+YYYY.MM.dd}"
}
}
[root@bp-vm ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/syslog.conf --path.settings /etc/logstash --config.test_and_exit
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties
[2020-04-18T13:19:00,946][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.queue", :path=>"/var/lib/logstash/queue"}
[2020-04-18T13:19:01,214][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.dead_letter_queue", :path=>"/var/lib/logstash/dead_letter_queue"}
[2020-04-18T13:19:02,193][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2020-04-18T13:19:04,461][INFO ][org.reflections.Reflections] Reflections took 98 ms to scan 1 urls, producing 20 keys and 40 values
Configuration OK
[2020-04-18T13:19:07,196][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash
[root@bp-vm ~]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/syslog.conf --path.settings /etc/logstash #前台运行logstash
稍等一会,就会出现类似以下的内容
部署kibana
[root@bp-vm ~]# yum install kibana-7.6.2-x86_64.rpm -y
[root@bp-vm ~]# egrep -v "^#|^$" /etc/kibana/kibana.yml #配置该文件
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://192.168.2.133:9200"] #修改为自己的ip
[root@bp-vm ~]# yum install -y git
[root@bp-vm ~]#git clone https://github.com/anbai-inc/Kibana_Hanization.git
[root@bp-vm ~]#cd Kibana_Hanization/old
[root@bp-vm ~]#python main.py /usr/share/kibana #汉话kibana
[root@bp-vm ~]#systemctl start kibana
[root@bp-vm ~]# netstat -tlnp|grep 5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 11807/node
[root@bp-vm ~]#
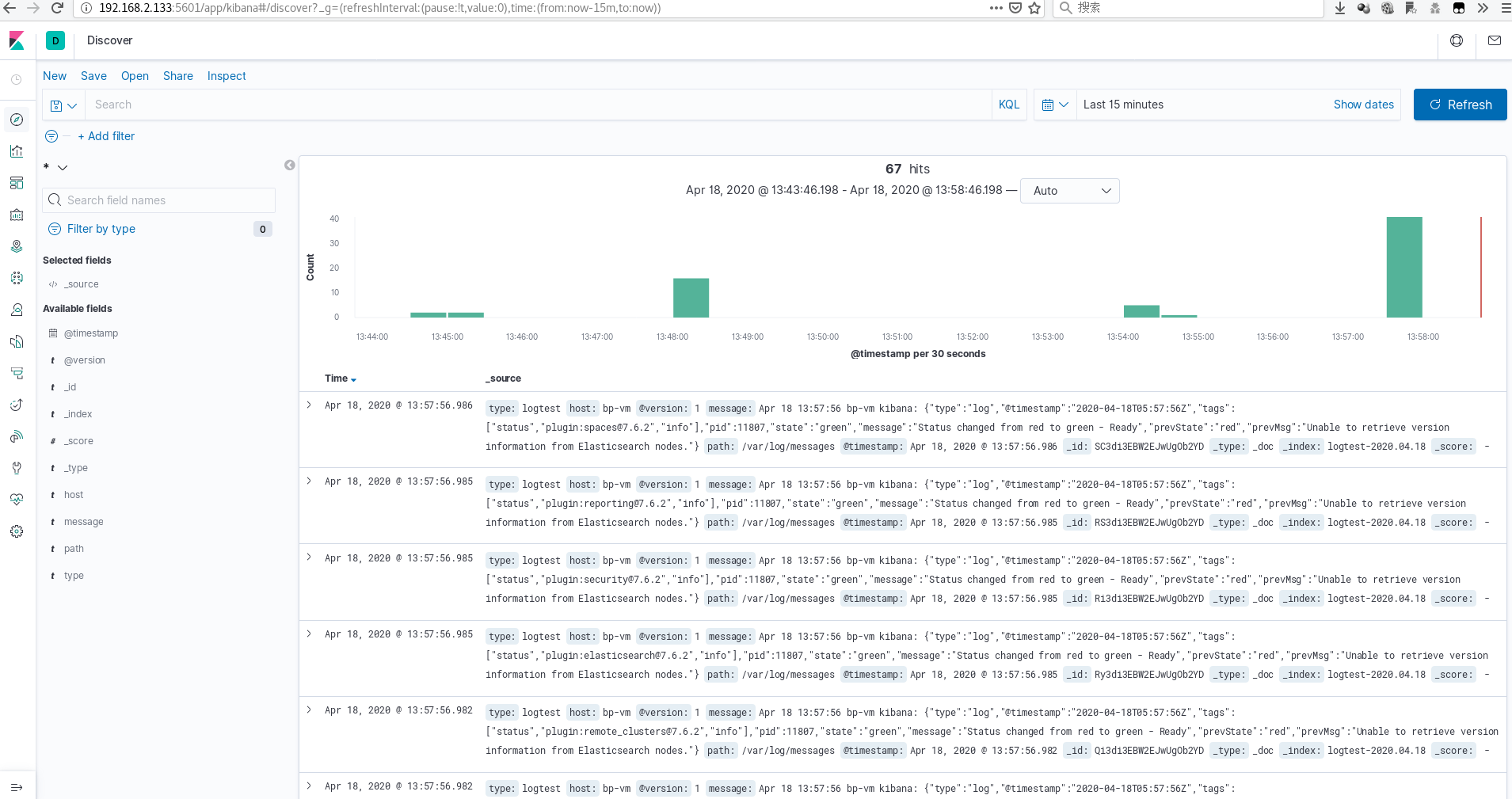
配置kibana
点击左下角那个指针图标->输入*->选择timestamp
最终效果
8. 高可用/集群
8.1 Lvs
8.1.1 部署
执行命令。yum源自带安装源
yum install ipvsadm*
8.2 Keepalived
8.2.1 部署
yum源自带
yum install keepalived -y
8.3 Haproxy
8.3.1 部署
yum -y install gcc tar zxf haproxy-1.4.21.tar.gz mv haproxt-1.4.21 haproxy make TARGET=linux31 PREFIX=/usr/local/haproxy 将haproxy安装到指定目录 make install PREFIX=/usr/local/haproxy
9. 负载均衡
9.1 Nginx
9.1.1 部署
[root@bogon ~]# wget -c http://nginx.org/download/nginx-1.7.9.tar.gz #下载安装包 [root@bogon ~]# tar zxvf nginx-1.7.9.tar.gz #解压 [root@bogon ~]# cd nginx-1.7.9/ [root@bogon nginx-1.7.9]# yum -y install gcc-c++ pcre-devel zlib-devel #安装依赖,主要是安装这些,而接下来的三步则是编译安装必须执行的,其中prefix选项是指安装位置 [root@bogon nginx-1.7.9]# ./configure --prefix=/usr/etc/nginx [root@bogon nginx-1.7.9]# make [root@bogon nginx-1.7.9]# make install [root@bogon nginx-1.7.9]# cd /usr/etc/nginx [root@bogon ngin]# cd sbin [root@bogon sbin]# ./nginx #启动服务,现在访问localhost就能看到nginx的欢迎界面了
9.2 F5
10. 性能测试
10.1 Ab
10.1.1 部署
yum install httpd-tools -y
10.2 LoadRunner
11. 存储技术
11.1 NFS
11.1.1 部署
yum install nfs-utils rpcbind -y #安装NFS相关软件 mkdir /NFS #创建NFS共享目录 echo "/NFS *(rw,no_root_squash,sync)">> /etc/exports #共享该NFS共享目录。建议加上no_root_squash,否则会导致同步时报错(待确认) systemctl start rpcbind #开启rpcbind服务 systemctl start nfs #开启nfs服务 showmount -e 127.0.0.1 #验证NFS共享目录是否共享成功,如下则说明共享成功 Export list for 127.0.0.1: /NFS *
11.2 NAS
12. 版本管理
12.1 SVN
12.1.1 部署
安装包下载地址:
https://pan.baidu.com/s/1miwdBc8
(1)配置java环境
(2)执行以下操作
建议一步步执行
tar xvf CollabNetSubversionEdge-5.1.4_linux-x86_64.tar.gz mkdir /application mv csvn/ /application/ useradd csvn passwd csvn chown -R csvn:csvn /application/ vim /etc/sudoers #添加下面一行使csvn可以使用sudo csvn ALL=(ALL) ALL ln -s /application/csvn/bin/csvn /etc/csvn ln -s /application/csvn-httpd /etc/csvn-httpd #原文这里是错误的,推荐直接find / -name csvn-httpd 启动服务:csvn csvn-httpd service csvn start #这两条语句,我执行时提示无法识别服务,所以我是直接到csvn下的bin目录下执行这两个脚本./csvn start 和 ./csvn-httpd start service csvn-httpd start
访问http://ip:3343/csvn,默认用户名密码为:admin admin 进去之后可以进行其它设置。
12.2 Git
12.2.1 部署
yum install git -y mkdir -p /data/test/bp.git #创建仓库文件 cd /data/test git init bp.git #初始化 useradd git #创建git用户 chown -R git:git /data/test/bp.git #修改权限,因为git用户需要对这个文件夹内容进行增删改查 useradd bp #新建一个用户,我们就用这个用户登录git服务器进行操作 usermod -G git bp #把新用户添加到git组里,因为这个组已经赋予权限了,后续新增用户直接加入git组即可 passwd bp #修改bp密码,因为在windows下git时需要密码
13. 备份工具
13.1 Rsync
13.1.1 Rsync+NFS实现增量备份
(1)架构图

(2)自建NFS服务器
在NFS服务器上执行
yum install nfs-utils rpcbind -y #安装NFS相关软件 mkdir /NFS #创建NFS共享目录 echo "/NFS *(rw,no_root_squash,sync)">> /etc/exports #共享该NFS共享目录。建议加上no_root_squash,否则会导致同步时报错(待确认) systemctl start rpcbind #开启rpcbind服务 systemctl start nfs #开启nfs服务 showmount -e 127.0.0.1 #验证NFS共享目录是否共享成功,如下则说明共享成功 Export list for 127.0.0.1: /NFS *
(3)挂载NFS
在需要挂载NFS的服务器上执行
此处为Jumpserver服务器
yum install nfs-utils rpcbind -y #安装NFS相关软件 mkdir /NFS1 #创建文件夹用来挂载NFS mount -t nfs NFS服务器ip:/NFS /NFS1 #将NFS共享目录/NFS挂载到本地/NFS1 df -Th #查看是否挂载成功 ssh-keygen #创建秘钥 ssh-copy-id root@服务器Node的ip #传输秘钥,免密登录
(4)配置增量备份脚本
#!/bin/bash BackupSource=$1 #远程目标 BackupRoot=$2 #增量备份路径 BackupName=$3 #备份的名字 BackupNum=$4 #保留多少个增量备份(用于每周归档文件) checkDir() { #检查目录 $1 是否存在,不存在则创建 if [ ! -d "${BackupRoot}/$1" ] ; then mkdir -p "${BackupRoot}/$1" fi } for i in `seq $(($BackupNum - 1)) -1 1` #处理增量备份目录的滚动覆盖 do if [ -d "${BackupRoot}/daily/$BackupName.$i" ] ; then /bin/rm -rf "${BackupRoot}/daily/$BackupName.$((i + 1))" mv "${BackupRoot}/daily/$BackupName.$i" "${BackupRoot}/daily/$BackupName.$((i + 1))" fi done checkDir "daily" #检查目录是否存在 checkDir "daily/${BackupName}.0/" #检查全量备份(包含所有最新内容的备份目录) checkDir "daily/${BackupName}.1/" #检查增量备份目录是否存在,不存在则创建 rsync -av --delete -b --backup-dir=${BackupRoot}/daily/${BackupName}.1 $BackupSource ${BackupRoot}/daily/${BackupName}.0
(5)增量备份恢复脚本
[root@VM_16_6_centos ~]# cat rsyncrecover.sh #脚本内容 #!/bin/bash OlderDir="$1" #增量备份目录 BackupRoot="$2" #全量备份目录 BackupName="$3" #输入你的备份名 BackupNum="$4" #总的增量备份数量(用于递归) where="$5" #输入你想要恢复的备份 for i in `seq $BackupNum -1 $where` #从最旧的备份开始,一直恢复到想要的那个备份位置 do rsync -av $OlderDir$BackupName.$i/ $BackupRoot$BackupName.0 done
13.1.2 Rsync+inotify实现实时备份
(1)实验简介
该实验是为了实现服务器S上的文件夹内容变动后,自动同步到服务器C上,使两个服务器S和C文件内容保持一致.原理是当inotify监听到文件内容变动后,自动调用rsync进行文件和文件夹的同步.
系统:Centos7.3
服务器S:192.168.2.128 #需要同步内容的服务器,我们简称为S
客户端C:192.168.2.137 #等待同步内容的服务器,我们简称C
我们的最终目的是实现,将S上的内容实时同步到C上
(2)下载inotify-tools并上传到服务器S
下载地址
https://github.com/rvoicilas/inotify-tools/wiki
(3)关闭防火墙和selinux
在S和C上分别执行:
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i "s/enforcing/disabled/" /etc/selinux/config
(4)配置S
在服务器S上执行以下操作
yum install rsync gcc -y
#设置目录
vi /etc/rsyncd.conf #文件内容如下
[node1] #模块名,可自定义,用来标志和识别rsync同步目录,建议和path的值目录名一致,方便记忆 path = /node1 #我们需要同步的目录,这里我假设为node1 auth user = rsync_backup #指定用户同步,建议在系统里也添加这个用户,并指定该用户位node1的拥有者 secrets file = /etc/rsyncd.secrets #指定保存用户密码文件
执行以下命令
mkdir /node1 useradd rsync_backup #添加rsync用户用于同步 chown -R rsync_backup:rsync_backup /node1 #修改文件夹拥有者 rsync --daemon #启动服务 netstat -anpt|grep 873 #查看rsync是否正常启动 echo "rsync_backup:123456" >/etc/rsyncd.secrets chmod 600 /etc/rsyncd.secrets touch /node1/file{1..3} tar -zxvf inotify-tools* rm -rf *.gz cd inotify-tools* ./configure && make && make install
编辑实时同步脚本/tmp/1.sh
#!/bin/bash /usr/local/bin/inotifywait -mrq -e modify,create,move,delete,attrib /node1 |while read events #-m –monitor始终保持事件监听状态 -r –recursive递归查询目录,-q –quiet打印监控事件的信息,-e –event指定删、增、改等事件 do rsync -a --delete /node1 这里输入服务器C的IP::node2 #-a归档模式,表示以递归方式传输文件,并保持所有文件属性,等价于 --delete 删除那些接收端还有而发送端已经不存在的文件 echo "`date +'%F %T'` 出现事件 $events" >>/tmp/rsync.log 2>&1 done
(5)配置C
yum install rsync
vi /etc/rsyncd.conf #修改文件内容
[node2] path=/node2/ read only=false uid=rsync_backup gid=rsync_backup
继续执行以下命令
useradd rsync_backup #添加rsync用户用于同步 mkdir /node2 chown -R rsync_backup:rsync_backup /node2 #修改文件夹拥有者 rsync --daemon netstat -tlnp|grep 873
(6)测试实时同步功能
在服务器S上执行以下操作
nohup sh /tmp/1.sh & #执行该1.sh脚本,启动监听,当S上有内容变动时,会自动同步到C上
尝试在服务器S上创建一个文件
echo "aaa">>/node1/file1
那么在服务器C上也会自动在对应位置上生产该新文件
14. 虚拟化
14.1 KVM
14.1.1 部署
实验环境:
系统:Centos7.7最小化安装
配置:1C4G
平台:VM
虚机配置成静态IP地址
配置虚拟机,开启VT_x/EPT or AMD-V/RVI
(1)配置虚机支持虚拟化
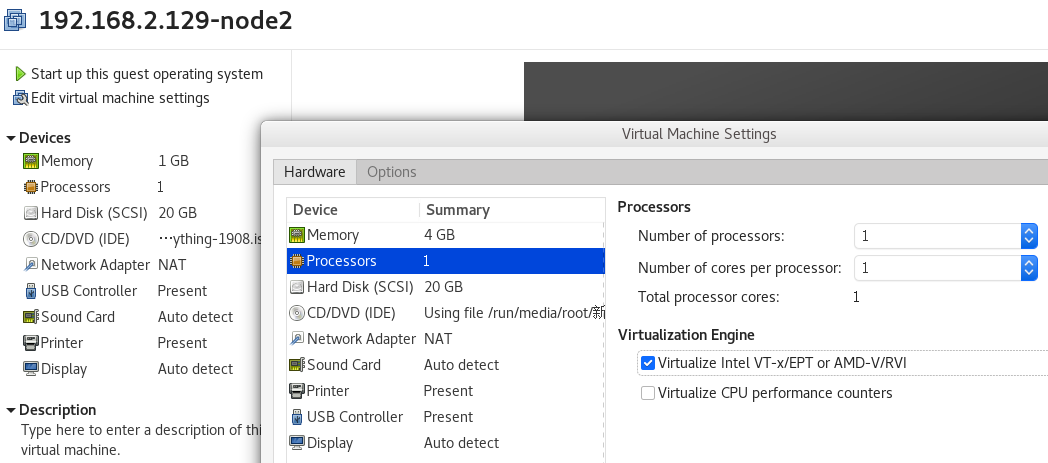
需要确认是否支持虚拟化
grep -E 'vmx|svm' /proc/cpuinfo
出现vmx之类的虚拟化技术字眼即代表支持虚拟化。不同cpu显示的可能不一样

确认支持虚拟化后再执行以下步骤
(2)开始安装
yum install qemu-kvm libvirt libvirt-python libguestfs-tools virt-install -y systemctl enable libvirtd && systemctl start libvirtd lsmod | grep kvm #正常会显示kvm virsh -c qemu:///system list ln -s /usr/libexec/qemu-kvm /usr/bin/qemu-kvm mkdir /vm-images #存放kvm虚拟机目录 mkdir -p /data/iso #存放iso镜像目录 cp /etc/sysconfig/network-scripts/ifcfg-ens33 /etc/sysconfig/network-scripts/ifcfg-br0
注意,还需要修改/etc/sysconfig/network-scripts/ifcfg-br0如下两个参数值 TYPE=Bridge DEVICE=br0 echo "BRIDGE=br0" >>/etc/sysconfig/network-scripts/ifcfg-ens33
注意,还需要注释vi /etc/sysconfig/network-scripts/ifcfg-ens33如下参数值,防止ip冲突 #IPADDR=x.x.x.x #NETMASK=x.x.x.x #GATEWAY=x.x.x.x #DNS1=x.x.x.x echo "net.ipv4.ip_forward = 1" >>/etc/sysctl.conf #做流量转发 sysctl -p /etc/sysctl.conf #使/etc/sysctl.conf配置生效 systemctl restart NetworkManager.service #重启网卡服务,使网卡配置生效
修改配置vi /etc/ssh/sshd_config #ssh开启X11转发,取消以下原有的注释 X11Forwarding yes X11DisplayOffset 10 X11UseLocalhost yes UseDNS yes yum install tigervnc-server -y vncserver #随便输入密码123456,然后n export DISPLAY=bp-vm主机名:1 #以上命令结束后会显示XX:1之类的字眼,按照修改即可 xhost + yum install xorg-x11-apps -y #安装xclock测试是否可以正常弹出图形界面
xclock #执行xclock应该会跳出一个时钟 yum install virt-manager -y 另外需要注意如果系统使用中文编码的话,会有乱码问题.建议直接使用英文编码即可 在windows系统上安装好xshell和Xmanager.必须安装xmanager,否则无法弹出virt-manager界面,对kvm进行管理 配置xshell会话时,需要配置属性→隧道→转发X11到xmanager
virt-manager
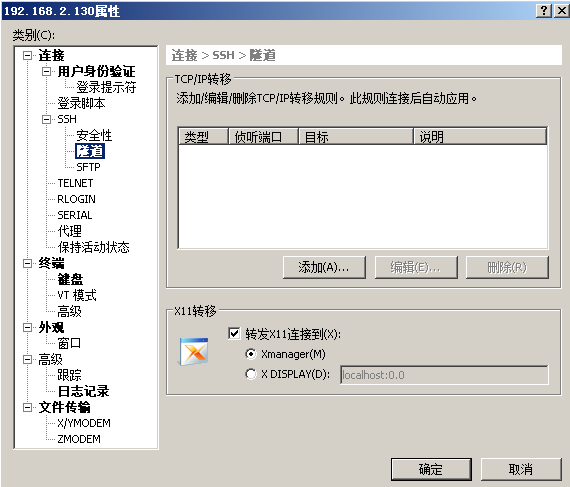
virt-manager弹出的窗口

14.2 Xen
14.2.1 部署
通过官网下载安装镜像即可,像平时安装虚拟机一样。
14.3 VMware
14.4 Hyper-V
15. 容器
15.1 Docker
15.1.1 部署
yum install -y yum-utils device-mapper-persistent-data lvm2 yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo #添加docker的yum源 yum list docker-ce --showduplicates | sort -r #查看可用版本 yum install -y docker-ce-17.12.0.ce #安装指定版本docker
15.2 K8s
15.2.1 部署
以下实验都是在VM虚拟机中进行部署的,仅供个人学习测试,不建议直接上生产环境.
PS:其中,master的CPU核数至少需要2核,否则会直接报错,还没有测试过1G内存是否可以正常安装
部署步骤:
三个节点分别执行以下命令
192.168.2.130执行该命令
hostnamectl set-hostname k8s-master
192.168.2.134执行该命令
hostnamectl set-hostname k8s-node01
192.168.2.135执行该命令
hostnamectl set-hostname k8s-node02
三个节点全部执行以下命令
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
swapoff -a #关闭swap交换分区
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab #禁止swap交换分区开机自启
#配置hosts文件
cat >> /etc/hosts << EOF
192.168.2.130 k8s-master
192.168.2.134 k8s-node01
192.168.2.135 k8s-node02
EOF
#内核调整,将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system #使上一条命令的配置生效
yum install -y ntpdate #安装ntpdate用于校准时间,确保master和node时间同步
ntpdate time.windows.com #校准时间
yum install wget -y
#如果以下安装docker的方式失败,可以参考我的博客https://www.cnblogs.com/biaopei/p/11937292.html
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
yum -y install docker-ce-18.06.1.ce-3.el7
#以下命令用来配置镜像地址..
curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://f1361db2.m.daocloud.io
systemctl enable docker
systemctl start docker
#因为默认k8s镜像仓库需要翻出去,所以配置国内镜像地址
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum install -y kubelet-1.15.0 kubeadm-1.15.0 kubectl-1.15.0
systemctl enable kubelet
以下操作只需要在master中执行
#记得将192.168.2.130修改为master的ip地址,其余不变.需要等待几分钟才可执行完成.会提示[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver.只是警告可忽略.(如果master的cpu核数只有1核,这里还会提示cpu核数达不到要求的2核)
kubeadm init \
--apiserver-advertise-address=192.168.2.130 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.15.0 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16
#执行完上一条语句后,会有类似如下命令的提示,根据提示执行即可.还有一条kubeadm join 192.168.2.130:6443 --token,这个是用来在node上执行,加入到k8s集群中的,我们稍后需要用到
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
以下操作在两个node中执行
#不要直接复制这里的,是kubeadm init执行完成后,后面提示的那条语句.就是我们刚才说的那个
kubeadm join 192.168.2.130:6443 --token c1qboh.pg159xmk61z5rbeg \
--discovery-token-ca-cert-hash sha256:ff09b3a7b0989de094b73e811bf378d8ab1cf3c1e413e3753ebd5de826075931
以下操作在master执行
#配置flannel网络
wget https://raw.githubusercontent.com/coreos/flannel/a70459be0084506e4ec919aa1c114638878db11b/Documentation/kube-flannel.yml
vi kube-flannel.yml
#修改以下行对应内容,注意不能使用tab键,只能使用空格进行对启,注意格式要按照原来的,不能多一个空格,也不能少一个空格
106 image: lizhenliang/flannel:v0.11.0-amd64 120 image: lizhenliang/flannel:v0.11.0-amd64
kubectl apply -f kube-flannel.yml
ps -ef|grep flannel|grep -v grep #可能需要10分钟左右启动初始化完成,才有返回结果.然后再执行下一步
kubectl get nodes #可能需要等待十几分钟,状态才能全部转为ready.然后再执行下一步
kubectl get pod -n kube-system #可能需要等待十几分钟,直至所有状态才能全部转为ready 1/1.然后再执行下一步
kubectl create deployment nginx --image=nginx #创建nginx服务
kubectl expose deployment nginx --port=80 --type=NodePort #暴露nginx服务80端口
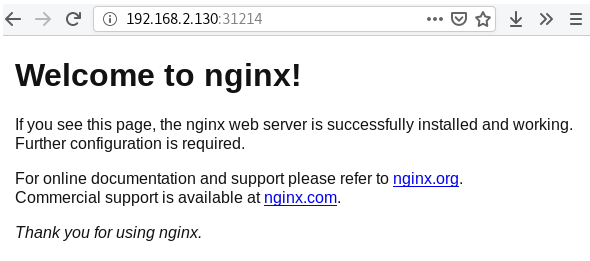
kubectl get pods,svc #查看运行中的服务80:31214/TCP.我们从宿主机访问masterip:31214即可访问到nginx服务.但是也需要等待几分钟,直到该端口可以telnet通..然后再执行下一步
访问nginx,效果:
#配置k8s UI界面
wget https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
vi kubernetes-dashboard.yaml
#修改以下行对应内容,注意不能使用tab键,只能使用空格进行对启,注意格式要按照原来的,不能多一个空格,也不能少一个空格
...... - name: kubernetes-dashboard image: lizhenliang/kubernetes-dashboard-amd64:v1.10.1 # 替换此行 ...... spec: type: NodePort # 增加此行 ports: - port: 443 targetPort: 8443 nodePort: 30001 # 增加此行 selector: k8s-app: kubernetes-dashboard
kubectl apply -f kubernetes-dashboard.yaml #现在访问https://192.168.2.130:30001.当然也需要等一会.注意是https
访问K8S UI界面,效果:
会提示链接不安全,点击高级->接受风险并继续即可
kubectl create serviceaccount dashboard-admin -n kube-system #创建管理员帐号
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin #配置管理员帐号为集群管理员帐号?
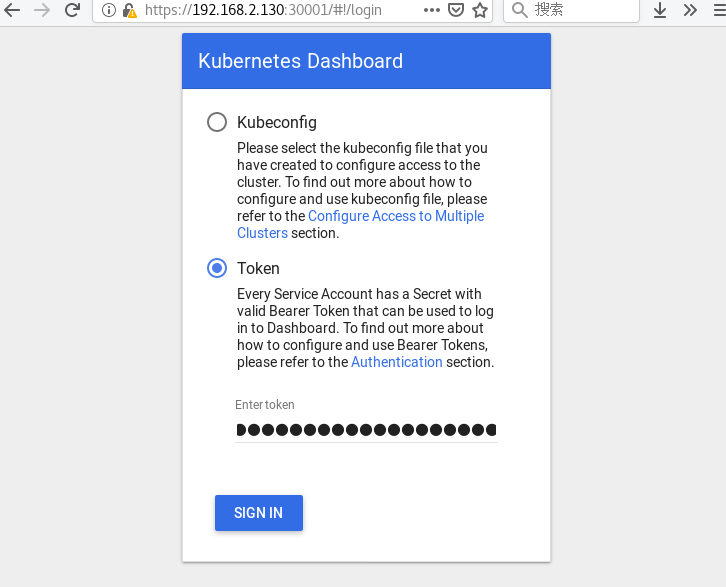
#执行以下命令后,会生成对应的token,在https://192.168.2.130:30001中选择token,输入该token即可登陆k8s管理后台
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
输入Token,登陆K8S UI界面,效果:
登录后

K8S部署完成.
16. 云计算
16.1 OpenStack
16.2 CloudStack
17. 自建服务
17.1 Posfix
17.2 DNS
17.3 VPN
18. CMDB/Wiki
18.1 iTop
18.2 蓝鲸
18.3 Codo
18.4 Confluence
19. 认证
19.1 openLDAP
19.2 域
20. 自动化
20.1 Ansible
20.1.1 部署
可以简单理解为ansible通过ssh连接到被控制端执行相应的命令.
在需要安装ansible的服务器上执行以下操作
[root@130-node1 ~]# yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm -y #安装yum源
[root@130-node1 ~]# yum install ansible -y #安装ansible
[root@130-node1 ~]# ssh-keygen #生成密钥
[root@130-node1 ~]# ssh-copy-id 192.168.2.129 #传输密钥
[root@130-node1 ~]# cat /etc/ansible/hosts|grep -v ^#|grep -v ^$ #配置hosts文件,可以通过定义[test]模块,对被控制主机进行分组
[test]
192.168.2.129
[root@130-node1 ~]#
[root@130-node1 ~]# ansible test -m command -a "ip addre" #直接返回129的ip addre信息,test组名,-m模块类型为command,-a命令
192.168.2.129 | CHANGED | rc=0 >>
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:7a:62:2d brd ff:ff:ff:ff:ff:ff
inet 192.168.2.129/24 brd 192.168.2.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::3c80:13ad:301b:495c/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::3129:687a:1538:d692/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@130-node1 ~]#
20.2 Saltstack
20.3 Puppet
20.3.1 部署
puppet是一种Linux、Unix、windows平台的集中配置管理系统,使用自有的puppet描述语言,可管理配置文件、用户、cron任务、软件包、系统服务等。puppet把这些系统实体称之为资源,puppet的设计目标是简化对这些资源的管理以及妥善处理资源间的依赖关系。
[root@130-node1 ~]# cat /etc/hostname #获取主机名,下面hosts文件需要用到
130-node1
[root@130-node1 ~]# vi /etc/hosts #配置对应的ip和主机名
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.2.130 130-node1
192.168.2.129 bp-vm
[root@130-node1 ~]#yum install puppet-server -y
node default {
file { "/tmp/helloworld.txt" :
content => "Hello World!",
}
}
[root@130-node1 ~]#
bp-vm
[root@bp-vm ~]# vi /etc/hosts #配置对应的ip和主机名
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.2.130 130-node1
192.168.2.129 bp-vm
[main]
logdir = /var/log/puppet
rundir = /var/run/puppet
ssldir = $vardir/ssl
[agent]
classfile = $vardir/classes.txt
localconfig = $vardir/localconfig
server=130-node1 #只需要修改这里即可.指定Puppet的地址
[root@bp-vm ~]# puppet agent --test #开始测试,puppet涉及到认证授权问题,因为Client没正式得到授权,所以这里只是向Server发起认证申请,因此会返回报错,不用管
"bp-vm" (SHA256) 3C:97:3B:C7:EB:5D:D2:67:77:D6:9C:6D:50:90:1E:49:D8:DA:14:40:4D:18:6B:5B:7F:F2:0E:8C:02:98:91:F2
+ "130-node1" (SHA256) 6A:C2:ED:5C:B4:E6:CE:AC:0B:48:CB:48:46:10:10:5D:13:C1:0F:78:D8:86:62:00:98:B8:52:C4:60:46:34:FD
[root@130-node1 ~]# puppet cert sign bp-vm #确认授权给bp-vm
Notice: Signed certificate request for bp-vm
Notice: Removing file Puppet::SSL::CertificateRequest bp-vm at '/var/lib/puppet/ssl/ca/requests/bp-vm.pem'
[root@130-node1 ~]# puppet cert list --all #bp-vm有+号就是得到授权
+ "130-node1" (SHA256) 6A:C2:ED:5C:B4:E6:CE:AC:0B:48:CB:48:46:10:10:5D:13:C1:0F:78:D8:86:62:00:98:B8:52:C4:60:46:34:FD
+ "bp-vm" (SHA256) B7:EE:85:62:BE:C8:BD:46:54:A4:BC:09:D4:F5:94:0A:E0:CC:8B:0E:D9:E2:68:3E:93:56:CD:1D:6B:9E:A7:04
[root@130-node1 ~]#
[root@bp-vm ~]# cat /tmp/helloworld.txt
cat: /tmp/helloworld.txt: 没有那个文件或目录
[root@bp-vm ~]# puppet agent --test #之前没有授权就报错了,授权后执行新增/tmp/helloworld.txt文件
Info: Caching certificate for bp-vm
Info: Caching certificate_revocation_list for ca
Info: Caching certificate for bp-vm
Info: Retrieving pluginfacts
Info: Retrieving plugin
Info: Caching catalog for bp-vm
Info: Applying configuration version '1587394106'
Notice:
/Stage[main]/Main/Node[default]/File[/tmp/helloworld.txt]/ensure:
defined content as '{md5}ed076287532e86365e841e92bfc50d8c'
Info: Creating state file /var/lib/puppet/state/state.yaml
Notice: Finished catalog run in 0.01 seconds
[root@bp-vm ~]# cat /tmp/helloworld.txt
Hello World![root@bp-vm ~]#
21. 开发语言
21.1 Shell
21.2 Python
个人WeChat




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决
2018-03-20 Centos7第三方源的安装与卸载