排序
冒泡排序
第一步:将原始列表中的最大值找出且放置在列表最右侧(将元素两两比较,将数值大的数逐步向后移动
第二步:重复第一步。
代码实现:
def sort(alist): for j in range(len(alist) - 1): # 交换 for i in range(len(alist) - 1 - j): if alist[i] > alist[i + 1]: alist[i], alist[i + 1] = alist[i + 1], alist[i] return alist
选择排序
第一步:将列表中的最大值一次找出,放置在列表最右侧。
同样重复第一步。

代码:
第一步:
#将列表中的最大值的下标找到 def sort(alist): max_index = 0 #最大值的下标 for i in range(1,len(alist)): if alist[max_index] < alist[i]: max_index = i print(max_index)
第二步:
#将列表中的最大值一次找出,放置在列表最右侧 def sort(alist): max_index = 0 #最大值的下标(索引) for i in range(1,len(alist)): if alist[max_index] < alist[i]: max_index = i alist[max_index],alist[len(alist)-1] = alist[len(alist)-1],alist[max_index] return alist
最终版:
def sort(alist): for j in range(len(alist),1,-1): max_index = 0 #最大值的下标 for i in range(1,j): #len(alist) == > j if alist[max_index] < alist[i]: max_index = i alist[max_index],alist[j-1] = alist[j-1],alist[max_index] return alist
插入排序
1.把整个无序列表想象成两个列表:左边是有序的列表,右边是无序的。[5, 3,9,4,1]4
2.依次将右侧无序列表的数和有序列表中的5进行对比
3.对比后进行排序,比有序中小的放在有序列表左侧,大的放在有序列表右侧

第一步:
def sort(alist): i = 1 # 首先将最左侧的当做有序列表 # 所以这里的alist[i-1]就是第一次插入时的有序列表 # alist[i]就是无序列表中的第一个元素,用于和有序列表进行比较 if alist[i] < alist[i - 1]: # 当无序元素小于了有序的元素,所以就需要把该元素放在有序的最左边,更换位置。 alist[i], alist[i - 1] = alist[i - 1], alist[i] # 否则就不更换位置,所以不做处理
第二步:
def sort(alist): i = 3 # alist[i-1]:第一次插入时的有序列表 # alist[i]:乱序列表中的第一个列表元素 while i > 0: if alist[i] < alist[i-1]: alist[i],alist[i-1] = alist[i-1],alist[i] i -= 1 # 进行循环依次和有序列表中的元素进行比较 else: break
最终版:
def sort(alist): for i in range(1, len(alist)): while i > 0: if alist[i] < alist[i - 1]: alist[i], alist[i - 1] = alist[i - 1], alist[i] i -= 1 else: break return alist
希尔排序
增量为1的希尔排序就是插入排序。
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。
和快速排序类似。
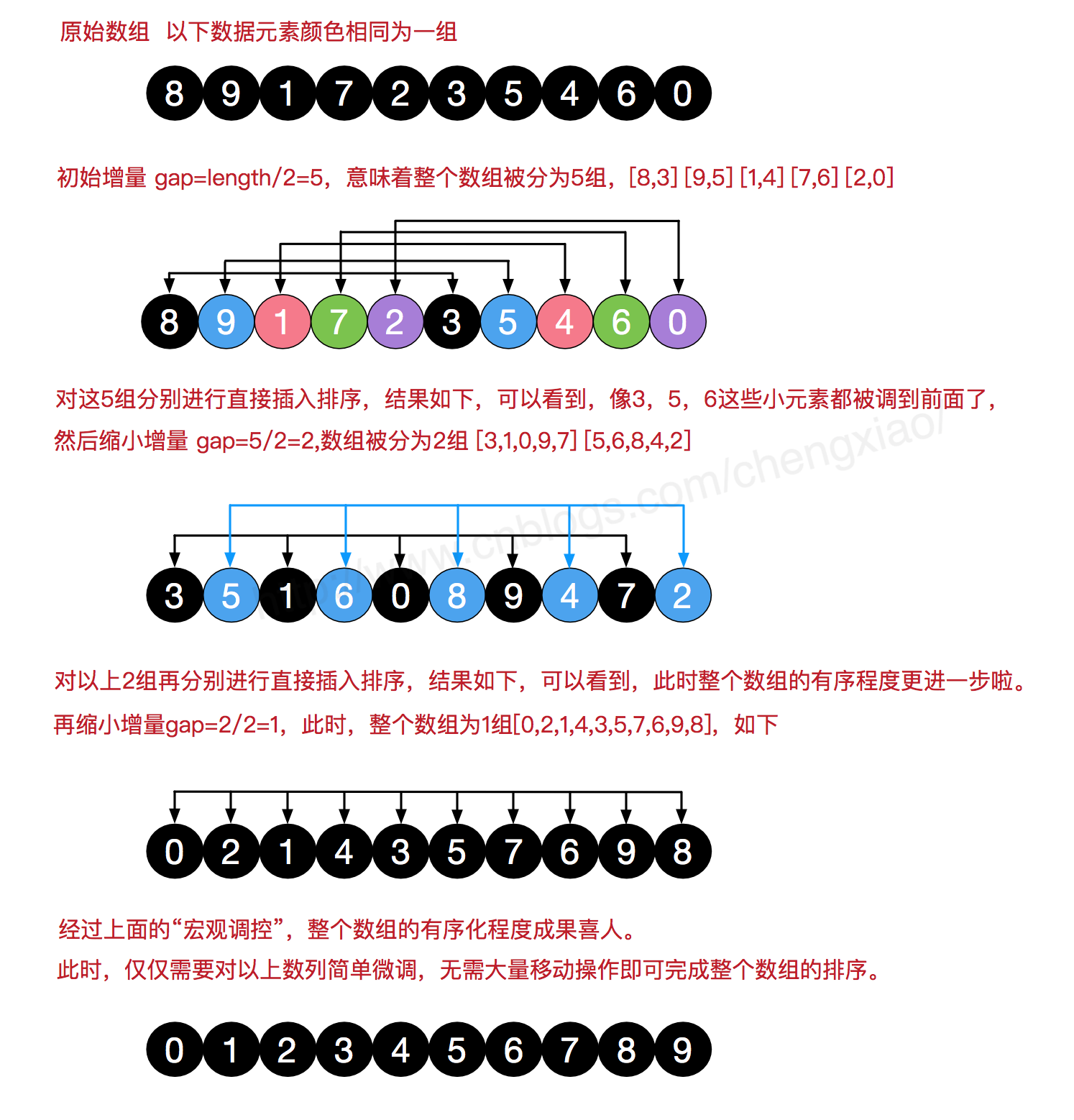
第一步:
# 增量为1的希尔排序(插入排序的核心) def sort(alist): # 设置增量 gap = len(alist) // 2 # 插入排序的源代码 for i in range(1,len(alist)): while i > 0: if alist[i] < alist[i-1]: alist[i],alist[i-1] = alist[i-1],alist[i] i -= 1 else: break return alist
第二步:
# 增量为gap的希尔排序 # 将原插入排序的1更改成增量。 def sort(alist): # 设置增量 gap = len(alist) // 2 for i in range(gap,len(alist)): while i > 0: if alist[i] < alist[i-gap]: alist[i],alist[i-gap] = alist[i-gap],alist[i] i -= gap else: break return alist
最终版:
#继续缩小增量(gap) def sort(alist): # 增量 gap = len(alist) // 2 while gap >= 1 : for i in range(gap,len(alist)): while i > 0: if alist[i] < alist[i-gap]: alist[i],alist[i-gap] = alist[i-gap],alist[i] i -= gap else: break gap //= 2 # 循环缩小增量 return alist
快速排序
- 将列表中第一个元素设定为基准数字,赋值给mid变量,然后将整个列表中比基准小的数值放在基准的左侧,比基准到的数字放在基准右侧。然后将基准数字左右两侧的序列在根据此方法进行排放。
- 定义两个指针,low指向最左侧,high指向最右侧
- 然后对最右侧指针进行向左移动,移动法则是,如果指针指向的数值比基准小,则将指针指向的数字移动到基准数字原始的位置,否则继续移动指针。
- 如果最右侧指针指向的数值移动到基准位置时,开始移动最左侧指针,将其向右移动,如果该指针指向的数值大于基准则将该数值移动到最右侧指针指向的位置,然后停止移动。
- 如果左右侧指针重复则,将基准放入左右指针重复的位置,则基准左侧为比其小的数值,右侧为比其大的数值。
快速排序又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
快速排序的名字起的是简单粗暴,因为一听到这个名字你就知道它存在的意义,就是快,而且效率高!它是处理大数据最快的排序算法之一了。
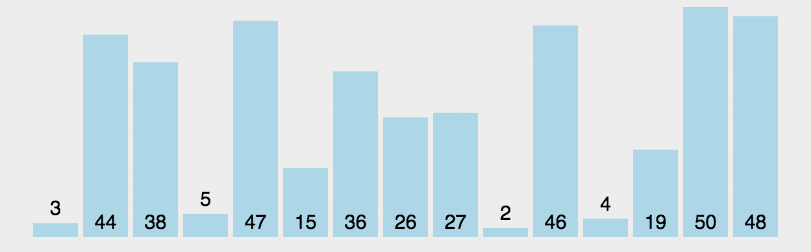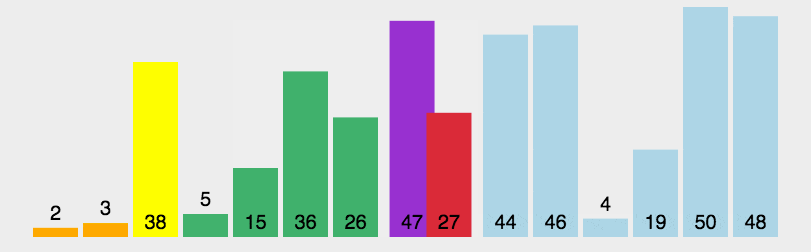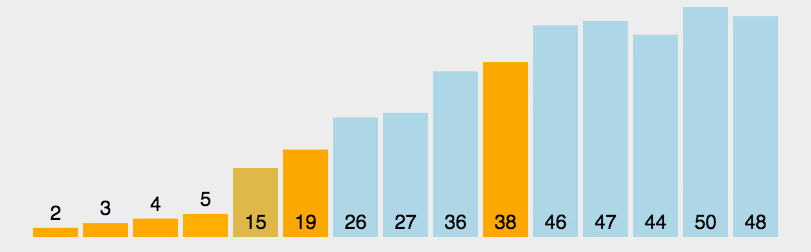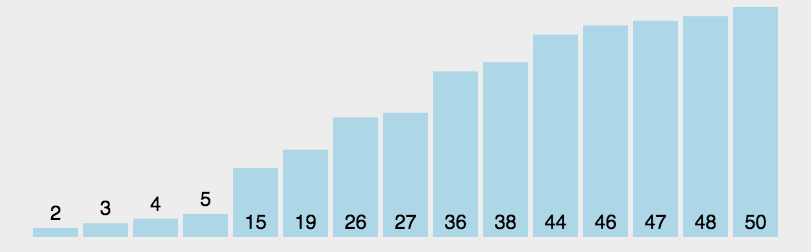
代码:
def sort(alist, start, end): low = start high = end # 结束递归的条件 if low > high: return mid = alist[low] while low < high: while low < high: if alist[high] > mid: high -= 1 else: alist[low] = alist[high] break while low < high: if alist[low] < mid: low += 1 else: alist[high] = alist[low] break alist[low] = mid sort(alist, low + 1, end) # 将基准右侧的子列表进行递归操作 sort(alist, start, high - 1) return alist alist = [2, 4, 5, 1, 3] print(sort(alist, 0, len(alist) - 1))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号