移动端数据爬取和12306模拟登陆
移动端数据的抓取
- 抓包工具
- fiddler
- 青花瓷
- miteproxy
- 使用fiddler,环境的搭建
1. 对fiddler进行配置:tools -> options -> connections -> Allow remote等 -> 设置端口
2. 测试端口是否可用:在pc浏览器中访问:本地ip+指定端口
3. pc端开启热点,使用手机连接热点(保证手机和fiddler所在的pc是在同一网段)
4. 在手机浏览器中访问那个ip+指定端口,并且安装证书并且信任证书
5. 在手机中设置代理(在手机连接wifi中设置代理ip和端口 -- 都是基于fiddler)
import requests headers = { 'User-Agent': 'qu tou tiao/3.6.1 (iPhone; iOS 12.3.1; Scale/3.00)/qukan_ios' } url = "fiddler中抓到的url" # verify=False可以忽略证书错误 json_data = requests.get(url=url, headers=headers, verify=False).json() print(json_data)
爬取抖音短视频:
滑动到某一个视频,进入作者所有视频的主页,抓取主页中所有视频的数据(V9)
1. 在fiddler中需要捕获到类似api.amenv开头的数据包(提取url,并且将fiddler中所有请求头信息携带对该url发起请求)
2. 相应回来的是一组json数据,在json数据中查找带有v9或者mp4结尾的视频信息(需要自己分析)
3. 有了对应视频的url就可以获取数据并保存。
selenium模拟登陆QQ空间
from selenium import webdriver from time import sleep bro = webdriver.Chrome(executable_path='chromedriver.exe') url = 'https://qzone.qq.com' bro.get(url) bro.switch_to.frame('login_frame') a_tag = bro.find_element_by_id('switcher_plogin') a_tag.click() bro.find_element_by_id('u').send_keys('1327703464') bro.find_element_by_id('p').send_keys('xxxxxxx') bro.find_element_by_id('login_button').click() sleep(2) # 登陆成功后对应的主页 page_text = bro.page_source
无头浏览器
- phantomJs
无可视化界面的浏览器
举例:谷歌的无头浏览器:
from selenium import webdriver from selenium.webdriver.chrome.options import Options from time import sleep chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('--disable-gpu') bro = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=chrome_options) bro.get('https://www.baidu.com') sleep(3) print(bro.page_source) bro.save_screenshot('1.png') bro.quit()
规避监测
- 由于有的网站会对selenium发起的请求进行监测
- 网站后台可以根据window.navigator,webdriver返回值进行selenium的监测
- undefinded:不是selenium发起的请求
- true:是selenium发起的请求
- 规避监测的方法:
具体看示例(通用的)
from selenium import webdriver from selenium.webdriver import ChromeOptions option = ChromeOptions() option.add_experimental_option('excludeSwitches', ['enable-automation']) # 实现了规避监测 bro = webdriver.Chrome(executable_path='chromedriver.exe', options=option) bro.get('https://www.taobao.com/')
12306模拟登陆
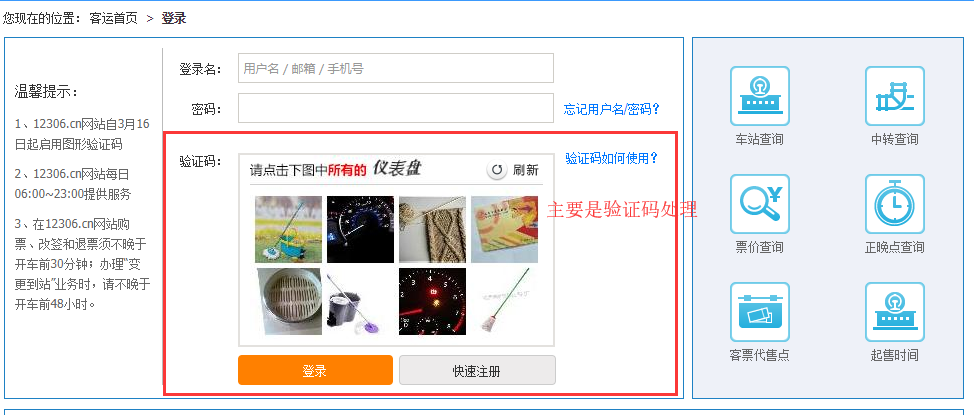
所以再次用到超级鹰(chaojiying.py)
import requests from hashlib import md5 class Chaojiying_Client(object): def __init__(self, username, password, soft_id): self.username = username password = password.encode('utf8') self.password = md5(password).hexdigest() self.soft_id = soft_id self.base_params = { 'user': self.username, 'pass2': self.password, 'softid': self.soft_id, } self.headers = { 'Connection': 'Keep-Alive', 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)', } def PostPic(self, im, codetype): """ im: 图片字节 codetype: 题目类型 参考 http://www.chaojiying.com/price.html """ params = { 'codetype': codetype, } params.update(self.base_params) files = {'userfile': ('ccc.jpg', im)} r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers) return r.json() def ReportError(self, im_id): """ im_id:报错题目的图片ID """ params = { 'id': im_id, } params.update(self.base_params) r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers) return r.json()
也用到了pillow模块
from PIL import Image from time import sleep from selenium import webdriver from selenium.webdriver import ActionChains from chaojiying import Chaojiying_Client def getCode(imgPath, imgType): print(111) chaojiying = Chaojiying_Client('超级鹰账号', '密码', '软件id') # 打开本地保存的截图信息 im = open(imgPath, 'rb').read() print(222) return chaojiying.PostPic(im, imgType)['pic_str'] bro = webdriver.Chrome(executable_path='chromedriver.exe') url = 'https://kyfw.12306.cn/otn/login/init' bro.get(url) sleep(3) # 截图 bro.save_screenshot('main.png') img_ele = bro.find_element_by_xpath('//*[@id="loginForm"]/div/ul[2]/li[4]/div/div/div[3]/img') # location表示的是验证码左上角的坐标 location = img_ele.location print('location', location) # size返回的是图片的长和宽 size = img_ele.size print('size', size) # rangle就是定制好的截图范围 rangle = ( int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height'])) # 根据截取范围进行截图 i = Image.open('main.png') # code_img_name截取下验证码图片的名称 code_img_name = 'code.png' frame = i.crop(rangle) frame.save(code_img_name) # 记录:code.png就是验证码图片,main.png就是当前登录页对应的图片 result = getCode('code.png', 9004) print(result) all_list = [] if '|' in result: list_1 = result.split('|') count_1 = len(list_1) for i in range(count_1): xy_list = [] x = int(list_1[i].split(',')[0]) y = int(list_1[i].split(',')[1]) xy_list.append(x) xy_list.append(y) all_list.append(xy_list) else: x = int(result.split(',')[0]) y = int(result.split(',')[1]) xy_list = [] xy_list.append(x) xy_list.append(y) all_list.append(xy_list) print(all_list) # 基于selenium根据all_list进行定点的点击操作 for l in all_list: x = l[0] y = l[1] # perform()是立即执行的意思 ActionChains(bro).move_to_element_with_offset(img_ele, x, y).click().perform() sleep(0.5) bro.find_element_by_id('username').send_keys('13521980615') sleep(2) bro.find_element_by_id('password').send_keys('xxxxxxx') sleep(2) bro.find_element_by_id('loginSub').click() sleep(10) bro.quit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号