基础内容记录(概念类)
基础
变量的命名:
1,字母,数字,下划线组成 2,不能以数字开头 3,不能使用python的关键字 4,变量名不要过长 5,变量要具有可描述性 6,不使用中文和拼音作为变量 7,推荐使用下划线,驼峰体
python2和python3
python2
input() 获取到的是输入的数据类型
raw_input() 获取到都是字符串
python3
input() 获取到的都是字符串
比较运算符 python2 <> -- 不等于 python3 != -- 不等于
python2
有整型和long长整型
python3
全都是整型
格式化
%s -- 占字符串 %d|%i -- 占数字 %% 转义成%
循环注意
break : 终止当前循环 continue: 跳出本次循环继续下次循环 break 和 continue 的共同点: 两个关键字下方的代码都不执行 也可以修改while关键字后方的条件结束循环
逻辑运算符
and or not () > not > and > or
编码
ascii 不支持中文
gbk 英文 1字节 中文 2字节
unicode 英文和中文都是4个字节
utf-8 英文 1 欧洲 2 亚洲 3
字符串方法:
upper、lower、startswith、endswith、count、index、find(-1)、split、strip、replace、join isdigit() # 判断是不是阿拉伯数字 isdecimal() # 判断是不是十进制 isalpha() # 字母,中文, isalnum() # 字母,中文,数字
for循环
for i in range(5): pass # 过 print(i) for i in range(5): ... # 过 print(i)
列表
可变数据类型 通过哈希判断是否可变
有序:支持索引
列表:用于存储不同数据类型
append insert extend
pop remove clear del lst del lst[0]
for循环和索引查询
sort()排序,reverse()反转
lst = [1,2,[]] lst1 = lst * 5 lst1[-1].append(9) print(lst1) # [1, 2, [9], 1, 2, [9], 1, 2, [9], 1, 2, [9], 1, 2, [9]]
lst = [1,2,[]] lst1 = lst * 5 lst1[-1] = 9 print(lst1) # [1, 2, [], 1, 2, [], 1, 2, [], 1, 2, [], 1, 2, 9]
元组就是一个不可变的列表
字典
无序,可变 键:唯一,不可变数据类型 值:任意 # 定义: # dic = {"key":1} # dict(k=1,a=10,b=22) # print(dict([(1,2),(2,3),(3,4)]))
增 dic.setdefault("key1",2) # 有就不添加,没有再添加 dic["键"] = 值 删 dic.pop(键) 返回值 dic.popitem() 随机删除 python3.6 默认删除最后一个 dic.clear() del dic["键"] 改 update dic[键] = 值 查 dic.get(键,指定返回值) 默认返回None dic[键] dic.setdefault(键) dic.setdefault(键,值)
dic = {} dic.fromkeys("abc",[]) print(dic) # {} dic = {} dic = dic.fromkeys("abc",[]) dic["a"] = 11 print(dic) # {'a': 11, 'b': [], 'c': []} dic = {} dic = dic.fromkeys("abc",[]) dic["a"].append(10) print(dic) # {'a': [10], 'b': [10], 'c': [10]}
小数据池和代码块
一个文件是一个代码块.(函数,类都是一个代码块.) 交互命令中一行就是一个代码块. # 同一个代码块驻留机制的目的: ''' 1,节省内存空间. 2,提升性能. ''' # 驻留机制针对的对象: int bool str ()空元组. int: 范围 -5~正无穷 bool True Fasle str:几乎所有的字符串都会符合缓存机制, 乘法时总长度不能超过20位 python3.6 python3.7 4096 # 不同的代码块之间: 小数据池. # 小数据池是针对 不同代码块 之间的缓存机制!!! # 小数据池的目的: ''' 1,节省内存空间. 2,提升性能. ''' # 小数据池针对的对象: int bool str ()空元组. # int: -5 ~256 # str: 一定规则的字符串 乘法时总长度不能超过20位 python3.6 python3.7 4096
深浅拷贝
# 浅拷贝: 只拷贝第一层元素 # 深拷贝: 不可变数据类型共用一个内存空间的值,可变数据类型重新开辟空间,不管嵌套多深 lst[:] # 浅拷贝
文件操作
# r读(文本) rb读(字节) # read() 读取全部 # read(3)读取3个字符 # readline 读取一行 # readlines 一行一行读取完,存放在列表中 # a和 w都具有创建文件的功能 # a 是追加写 # w 是清空写 # 1.在open时将文件中的内容清空 # 2.清空后写入内容 # 移动光标: # seek(0,0) # 文件头 # seek(0,1) # 当前位置 # seek(0,2) # 文件尾 # seek(3) # 移动3个字节 # 查看光标: # tell #返回的就是字节 # f = open("a","w",encoding="utf-8") # f 是一个迭代器
函数
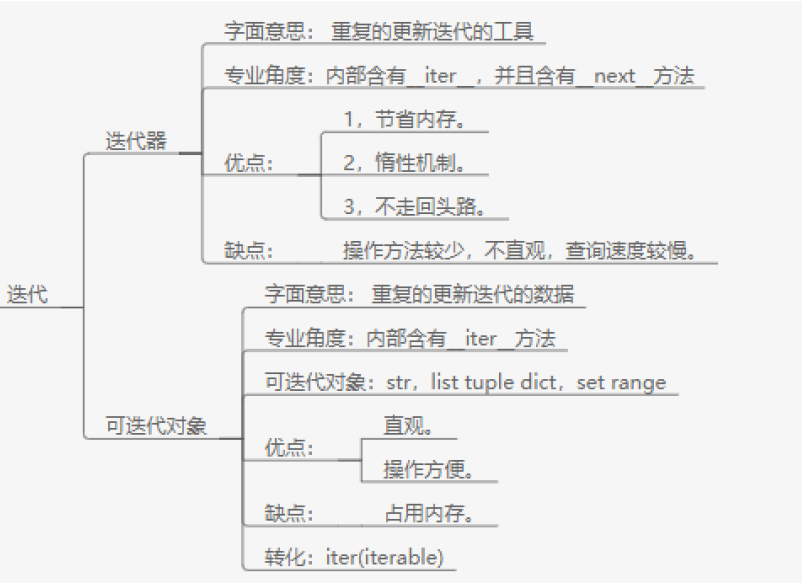
1.迭代器:能够从中一个一个按照顺序取值,并且具有惰性机制的特点,且只能从头取到尾
2.迭代器协议:具有__iter__和__next__方法的对象
3.生成器和迭代器的关系:生成器就是迭代器
4.获得生成器的两种方法:生成器表达式(推导式)和生成器函数
5.生成器的特点:a.惰性机制 b.只能从头到尾取一次 c.能够使用for next 从中一个一个取值
6.闭包:在一个嵌套函数的内部引用外部函数内的变量就是闭包
7.内置函数中可以接收一个函数名作为参数的所有函数:filter,map,sorted,max,min,callable,print
8.python中递归的最大深度是:1000
9.修改递归深度的方法:sys.setrecursionlimit()
补充:
def func(a,b,*args,c,sex='男',**kwargs): print(c) # 仅限关键字参数 func(1,2,4,5,6,c=666)
def func(a,l=[]): l.append(a) return l ret1 = func(1) ret2 = func('太白',[]) ret3 = func(22) print(ret1) print(ret2) print(ret3) # [1, 22] # ['太白'] # [1, 22]
def foo(a,b,*args,c,sex=None,**kwargs): print(a,b) print(c) print(sex) print(args) print(kwargs) foo(1,2,3,4,c=6) foo(1,2,sex='男',name='alex',hobby='old_woman') foo(1,2,3,4,name='alex',sex='男') foo(1,2,c=18) foo(2, 3, [1, 2, 3],c=13,hobby='喝茶') foo(*[1, 2, 3, 4],**{'name':'太白','c':12,'sex':'女'})
*处理剩余元素
# *处理剩余元素 # a,*b,c = [1, 2, 3, 4, 5] # a,*b, c = range(5) # print(a,b,c)
闭包:
1. 内层函数对外层函数非全局变量的引用。
2. 存在嵌套函数中。
3. 内层函数的函数名必须作为返回值返回。
闭包的作用?
被引用的变量被称为自由变量,不会随着函数的结束而消失,保证数据安全。
闭包的应用: 装饰器。
装饰器
手写一个装饰器
def wrapper(func): # f=fun def inner(*args, **kwargs): """执行之前的代码""" print(111) # 3 ret = func(*args,**kwargs) """执行之后的代码""" print(222) # 5 return ret return inner @wrapper # f = wrapper(f) 1 f = inner def f(): print('in f') # 4 f() # inner() # 2
利用装饰器手写一个登陆认证。
多个装饰器装饰同一个函数的流程。
def wrapper1(func): def inner1(*args, **kwargs): print('in inner1') # 2 ret = func(*args,**kwargs) print(555) # 4 return ret return inner1 def wrapper2(func): def inner2(*args, **kwargs): print('in inner2') # 1 ret = func(*args,**kwargs) print(777) # 5 return ret return inner2 @wrapper2 @wrapper1 def func(): print(666) # 3 # in inner2 # in inner1 # 666 # 555 # 777
迭代器
生成器
1.生成器本质上就是迭代器,
2.生成器与迭代器区别:迭代器是python直接给你提供的,或者通过iter()转化的,生成器是自己通过python代码构建。
3.构建生成器的几种方式:
1 通过生成器函数。(yield) 2 生成器推导式。 3 有一部分是python给你提供的。
推导式
print(list(i*i for i in range(1,11))) # [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
循环模式:
[变量(加工后的变量) for 变量 in iterable]
筛选模式:
[变量(加工后的变量) for 变量 in iterable if 条件]
yield from
yield from 代替了生成器的内层循环,提高效率。
yield from
def func():
# yield 1
# yield from [1,2,3]
for i in range(1,4):
yield i
obj = func()
print(next(obj))
print(next(obj))
print(next(obj))
def chain(*iterables):
for it in iterables:
yield from it
# for i in it:
# yield i
g = chain('abc', (0, 1, 2))
print(list(g)) # 将迭代器转化成列表
内置函数
max, min,filter,map,zip,sorted,reduce
def func():
for num in range(10):
pass
v4 = [lambda :num+10,lambda :num+100,lambda :num+100,]
result1 = v4[1]()
result2 = v4[2]()
print(result1,result2)
func()
# 109 109
def num(): return [lambda x:i*x for i in range(4)] print([m(2)for m in num()]) # [6, 6, 6, 6]
[m(2) for m in num()] 第一步: num() ---> [lambda x:i*x, lambda x:i*x, lambda x:i*x, lambda x:i*x] 循环完毕之后,内存中的 i = 3 第二步: [m(2) for m in [lambda x:3*x, lambda x:3*x, lambda x:3*x, lambda x:3*x]] [lambda 2:3*2, lambda 2:3*2, lambda 2:3*2, lambda 2:3*2] [6,6,6,6]
def num(): return (lambda x:i*x for i in range(4)) print([m(2)for m in num()]) # [0, 2, 4, 6] ''' 第一步: num() ---> gen = (lambda x:i*x for i in range(4)) 第二步: [m(2) for m in gen] '''
def demo(): for i in range(4): yield i g = demo() g1 = (i for i in g) g2 = (i for i in g1) print(list(g1)) print(list(g2)) # [0, 1, 2, 3] # []
模块
1.贪婪匹配:默认的,在量词范围内尽量多的匹配 \d+
2.非贪婪匹配:在量词范围内尽量少的匹配,在量词后面加上?\d+?
3.re模块中常用的方法:search\findall\finditer\compile
4.序列化:把其他数据类型转换成 str\bytes 的过程就是序列化
5.序列化应用场景:文件存储\网络传输
6.python中的序列化模块:json pickle shelve
7.json:所有语言通用,能处理的数据类型有限(list\dict\数字\str)
8.pickle:python语言专用,能处理几乎所有的数据类型
9.简述hashilib模块的作用以及它提供的常用算法
作用:密文登录验证,文件一致性校验
算法:md5\sha
补充:
列举你使用的内置模块,不少于10个.
os sys random time datetime hashlib logging json pickle re uuid socket socketserver threading mutiprocess collections functiontools
列举一下第三方模块
requests beatifusoup Django flask pillow pandas gevent greenlet redis pymysql .....
面向对象
1.类:一类具有相同属性和相似方法的事物
2.对象:一个具有具体属性值的事物,也是实例
3.实例化:通过类创造对象\实例的过程
4.面向对象的三大特性:继承、封装、多态
5.继承:解决代码的重复问题,将重复的代码写到父类中,就可以减少代码的冗余
6.封装:将属于这一类事物的属性和方法装到类中---广义的封装
将不想在类的外部被使用的方法和属性私有化---狭义的封装
7.多态:python中处处是多态
8.反射:通过字符串数据类型的变量名来操作变量的值
9.反射中的内置函数:hasattr getattr steattr delattr
10.类中的成员:静态属性,静态方法,类方法,对象方法,property方法
11.对象的成员:对象属性
12.类的调用习惯:静态属性,静态方法,类方法
13.对象的调用习惯:对象方法,property方法,对象属性
14.新式类:继承object,有mro方法,有super方法,继承顺序广度优先,遵循C3算法
15.经典类:不继承object,没有mro方法,没有super方法,继承顺序深度优先
补充:
1.面向对象的优势:
结构分析: 相似功能的集合.代码更加清晰化,标准化.
站在上帝的角度: 构建类, 一切以对象为核心,得到对象的天下.(得到对象可以得到对象属性,从属于类的属性,方法,可以得到父类的属性方法.)
2.实例化对象发生了三件事:
__str__ : print(obj)调用这个对象的__str__方法,打印的实际上是__str__的返回值 __repr__: 如果打印一个对象,该对象没有实现str,就会调用repr,并打印它的返回值 __new__:构造方法,开辟空间,创建了对象/self -- 单例模式 __del__:析构方法,在删除对象的之前调用,回收一些资源(f,sk等) __call__ : obj()调用__call__方法 __enter__: 上下文管理,with语句中代码块之前执行的代码 __exit__ : with语句中代码块之后执行的代码 __eq__ : == __gt__:> __lt__:< __getitem__:实现对象通过__dict__可以通过字典键取值 __getattr__:没有这个属性时会执行
# 伪代码 class A: def __init__(self): sk = socket.socket() sk.bind('127.0.0.1',9000) self.sk = sk self.f = open('file') def __del__(self): self.f.close() self.sk.close() a = A() del a


class A: def __init__(self,name,age): self.name = name self.age = age def __eq__(self, other): return self.name==other.name a1 = A('alex',84) a2 = A('alex',84) a3 = A('wusir',73) print(a1==a2)
class A: def __init__(self,name,age): self.name = name self.age = age def __gt__(self, other): return self.age>other.age a1 = A('alex3',85) a2 = A('alex',84) a3 = A('wusir',73) print(a1>a3)
class A: def __init__(self,name,age): self.name = name self.age = age def __getitem__(self, item): return self.__dict__[item] a = A('alex',84) print(a.name) print(a['age'])
class A: def __getattr__(self, item): print(item) a = A() a.name
不同方式实现单例模式:
网编
1.请写出osi五层协议,并写出你知道的三层物理设备和四层协议
应用层 http https ftp snmp
传输层 tcp协议/udp协议 四层路由器 四层交换机
网络层 ip 路由器、三层交换机
数据链路层 arp 交换机 网卡
物理层
2.请描述三次握手和四次挥手的过程,这个过程属于哪层协议
三次握手:
TCP协议在建立连接的时候经历的过程,第一次由Client端向Server端发送SYN请求,Server端再发送ACK回复,在回复时顺便发送SYN请求,Client端收到回复和请求后再确认发送一次ACK请求,这样就建立了一个全双工通信
四次挥手:
TCP协议在断开连接的时候经历的过程,第一次由Client或者Server端发起FIN请求,对方收到后回复ACK,对方再次发送FIN请求,发送方接收并回复ACK,连接断开。
3.tcp协议和udp协议各自的特点,并说明什么是粘包现象,哪一种协议会出现粘包为什么。
tcp协议:
是一个面向连接的,流式传输,可靠的,效率低,全双工通信,一对一双向通信
udp协议
是一个面向数据报的,无连接的,不可靠的,速度快的,能完成一对一,一对多,多对一,多对多的高效通讯协议tcp协议由于它无边界的流式传输特点容易出现黏包现象。
udp协议会丢包,发送的数据长度有限
在哪里用过这两个协议
tcp:发送邮件、http协议的web程序
udp:即时通信类 cdn
cdn:请求分发,内容分发网络
4.arp协议
地址解析协议,通过ip地址找到mac地址,通过交换机完成的,使用到交换机的广播和单播
补充:
应用层的协议:DNS、FTP、HTTP、电子邮件协议SMTP、POP3:邮件读取协议、telnet远程终端协议(https://www.cnblogs.com/liaopeng123/p/11280473.html)
并发编程
1.什么是进程,什么是线程,在python中各有什么特点,区别是什么
进程是一个运行中的程序,是计算机中最小的资源分配单位,在进程之间数据隔离。
线程是进程中的一个代码执行单位,是计算机中内被cpu调度的最小单位,在同一个进程中的多个线程是数据共享。
在python中,cpython解释器下的GIL锁导致了线程不能利用多核
cpython中的进程:创建、销毁、切换开销大,数据隔离,利用多核,操作系统级别,资源分配的最小单位
cpython中的线程:创建、销毁、切换开销小,数据共享,利用多核,操作系统级别,被cpu调度的最小单位
2.什么是IPC,请简述你了解的IPC机制
inter process communication
进程之间通信
IPC机制:管道 队列 第三方工具(redis,memcache,rabbitmq)
3.什么是GIL,GIL导致了什么
全局解释器锁。该锁是Cpython解释器中特有的。
保证了同一个python进程中的多个线程同一时刻只能有一条线程访问CPU。
4.什么是协程,协程和线程的区别
协程是单线程下的并发,又称微线程,纤程。英文名Coroutine。协程是一种用户态的轻量级线程,即协程是有用户程序自己控制调度的。
协程:用户8级的切换,协程的本质是一条线程,数据安全。
线程:操作系统级别的切换,数据不安全
补充:
# 进程 # 特点:操作系统级别 开销大 数据隔离 # 资源分配的最小单位 数据不安全 # 可以利用多核 # 线程 # 特点:操作系统级别 开销小 数据共享 # 被cpu调度的最小单位 数据不安全 # 可以利用多核 # 协程 # 特点:用户级别 开销极小 数据共享的 # 不能利用多核 从代码级别来看数据安全 # 你用过什么起进程的模块么? multprocessing concurrent.futrues 进程池 # 为什么要起进程? 首先进程多用在高计算的地方,因为Cpython解释器无法在多线程里利用多核的,所以在计算比较多的情况下,为了加快速度,考虑用到多进程。 爬虫测试中尝试过,执行爬取任务的时候开多线程去规避IO,分析爬取到的数据的时候,想着大部分就是内存里的操作,就没有网络交互和文件交互了,需要高计算, 做数据分析时尝试起了多进程,不过可能数据量比较小,开进程开销大,所以效果不明显,还导致程序开了进程后更慢了,所以就去掉了。不过之后如果数据比较复杂,比较多时候可以考虑开启多进程。
# 你用过多线程么? 用过,在爬虫爬取数据时候用到了,并且,在django(默认就是多线程),socketserver(多线程+io多路复用),flask(默认用协程,协程找不到就用线程) # 你写代码的时候用到过哪些锁 互斥锁和递归锁,互斥锁和递归锁的区别,互斥锁只能acquire一次,且对应一次release,而递归锁是在一个线程中acquire多次也不会死锁。 不过我只用过互斥锁,因为互斥锁效率高,并且大部分情况下互斥锁就能解决我的问题了,所以没怎么用过递归锁。 # logging queue list 是否线程安全 logging queue 线程安全 list 的所有方法都是线程安全的 append insert extend pop,list[0] += 1 线程不安全了 dict update setdefault 都是线程安全的,dic[key] += 1 线程不安全
# 你用过协程么? 用过的,因为知道了线程的一些问题,比如不能使用多核,所以就研究下,发现还有协程,也是爬虫中用到了aiohttp模块,还有个web项目是sanic,也是基于asyncio。 # 线程和协程的区别 操作系统控制线程 程序员代码用户控制协程 协程的本质就是一条线程 线程对于IO操作的感知力更强 :打开文件 网络操作 时间模块 协程对于IO操作的感知力弱很多 :网络操作 时间操作 文件操作频繁的情况下 协程无法规避掉这部分io操作 # 协程有哪些模块? gevent acyncio :aiohttp sanic
数据库
1.请简述mysql中常用的储存引擎,以及他们各自的特点
myisam:mysql5.5之前的默认引擎,表级锁,支持以插入和查询为主,对事物完整性要求不高的场景,辅助索引
innodb:mysql5.6之后的默认引擎支持事务外键和行级锁对并发的删改操作有良好的支持,聚集索引和辅助索引
memory:数据存储在内存,因此速度非常快,但断电消失你为什么要用innodb的存储引擎
支持事务外键行级锁
行级锁:并发的修改数据
外键:
2.请简述你常用的关系型数据库和非关系型数据库
关系型数据库:sql server、mysql、oracle
非关系型数据库:mongo db、redis
3.mysql数据库中有哪些约束关键字?(如何使用,有什么效果)
primary key 主键约束唯一+非空约束自带索引
unique 唯一约束,自带索引
not null 非空约束
foreign key外键约束
4.什么是索引?请简述索引的种类和特点?
主键primary key
唯一unique
普通index
联合索引(联合主键,联合唯一,联合普通索引)
5.请简述char和varchar的区别
char:定长,浪费空间,读写速度快
varchar:变长,节省空间,读写速度慢
6.请写出mysql中的常用函数(至少6个)
password()
user()
database()
min()
max()
avg()
sum()
count()
concat()
concat_ws()
group_concat()
now()
7.请列举创建索引但是无法命中的6种情况
1.条件的范围过大
2.使用了or
3.like%x'
4.没有符合最左前缀规则
5.索引列区分度不高
6.索引列参计算
7.在条件中使用函数
8.索引类型与sql条件中类型不匹配
8.请简述mysql innodb存储引擎中的约束关键字,以及你用过的基础数据类型
int,float,char,varchar,datetime,set,enum
primary key,unique,not null,foreign key

 浙公网安备 33010602011771号
浙公网安备 33010602011771号