大话NoSql
之前看过一本名叫<<大数据挑战的书>>,里面主要讲了NOSQL的内容,感觉讲得确实不错,今天来重新温习一下,我们大话NOSQL。说道NOSQL,我们肯定联想到的内容就是BigData大数据了,不错,当今的时代就是大数据的时代了。如果放在前几年,互联网还没有这么发达的情况下,也许谁也不会听过这个名词。在讲正题的时候,我做了张图来看看一般服务端架构在面对业务发展的需要时候,一般的演变趋势:

所以如果公司的数据量发展到一定规模的话,可以采用NoSql.好了终于引出了NoSql这个今天的主题了。NoSql可以理解为”Not Only Sql”,主要指的是非关系型,分布式,不提供ACID的数据库设计模式,强调的是类似于Map的“键值存储”,和”文档存储“。面对海量数据,NoSql 采用了一种弱类型的数据,采用更加简单的数据模型,一般都是用字符串表示所有的数据类型。但是他可能不会像关系型数据库一样有那么好的强一致性,应该nosql是一种最终一致性。NoSql也避免了许多诸如联表查询等复杂操作,基本就是简单的赋值,取值等,
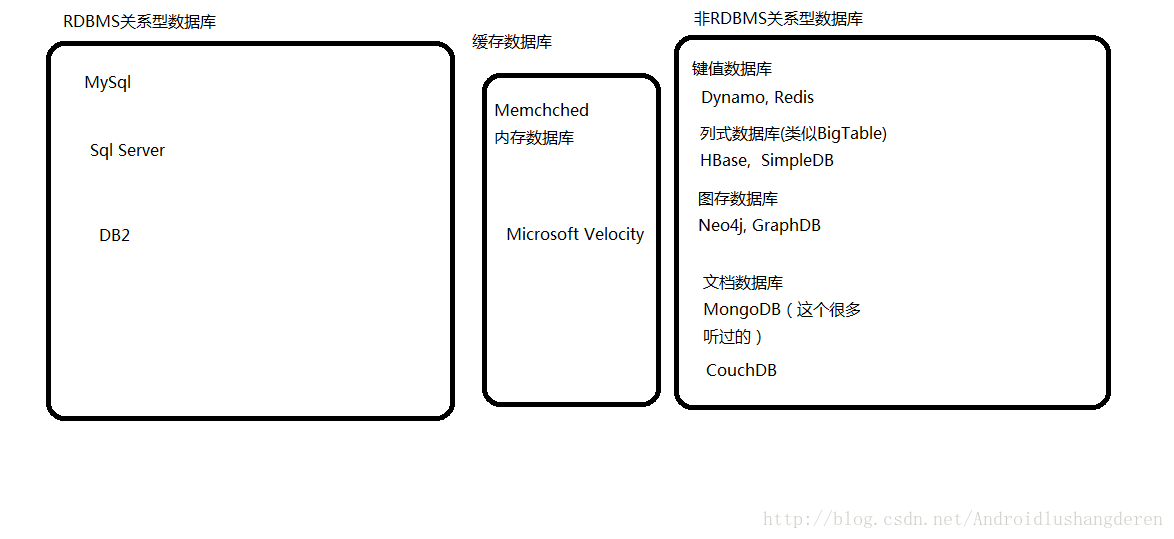
可以实现比较难高的吞吐量。现在的数据库系统可谓是五彩缤纷,来张图看看:
在介绍nosql之前,要知道的一些海量数据的理论性知识,CAP理论,C,(Consistency)强一致性,A(Available)可用性,P(Partition Tolerance)分区容忍性,可以理解为系统在存在网络分区的情况下仍然可以接受请求。自然这让我们联系到了另一个理论ACID,A(Atomic)原子性,C(Consistent)一致性, I(Isolation)隔离性, D(Durablitity)持续性。还有一个比较重要的协议2PC两阶段提交协议,许多分布式关系数据库采用此协议来完成分布式事务。下面我们来真正了解一下具体的NOSQL。
K-V数据库
首先我们来了解是Redis,Redis是一个开源的,高级key-value的数据库。他的value不仅支持String类型,而且还有list,set等结构,Redis采用的是内存进行数据存储,等数据到达一定规模后,在持久化到文件或磁盘中。基于Redis的特点,新浪微博采用的就是Redis,对于微博这样的结构清晰,数据规模庞大的应用来说,Redis当然最适合不过了。
Column-Oriented列式数据库
说到列式数据库,我们不得不提到他的始祖,Bigtable数据库,在后来衍射出的很多数据库都能看到他的影子,列式数据库强调的是一种面向列的稀疏存储,还有一个列族的概念,跟关系型数据库的单行单列,不一样,比较典型的Hadoop采用的HBase数据库。
文档型数据库
文档型数据,我这里说的有2种,MongoDB,还有一个CouchDB,两者有很多共同点存储的都是JSON类型数据类型,在文档数据库中文档成为了数据存储的一个基本单位,因此,所存储的数据,甚至可以要求是无结构的,文档可长,可短,每一个都以类似于”{“”id”: 200, “msg”:”haha”}这样的json格式保存在数据库中。我们重点关注一下MongoDB,在MongoDB中存在着类似于SQL查询语句的操作,但是又不是跟SQL语句完全相同,比如db,user,find(),MongoDB支持Map/Reduce模型,CouchDB具体RestFul API,可以实现用Http请求实现操作。二者数据库都借助了Map/Reduce,技术提高了数据处理的效率,这对于与存储非结构化,和半结构化的数据都有很大的帮助。
图存数据库
图存数据库我刚刚听说这个名词的时候,也是觉得难以理解,官方给出的定义:图存数据库使用基础的数据结构,来存储代表一个图形的数据,能够通过非常方便的方式优雅的呈现任何类型的数据。图存数据库现在一般有3类,Neo4j数据库,GraphDB图存数据库,OrientDB,图存数据库的查询会模仿图的遍历实现查找,通过朋友找到朋友的朋友,最终找到目标。
NoSql就是分为上述的4种类型,突然心血来潮,相到一个比较重要的知识点,数据处理,数据处理平常也总是有人在提起,我就提提,我说的数据处理指的是传统的压缩算法的实现,一般有2种,一个哈弗曼编码,学过计算机的,数据结构都上过的吧,另一个L.Z算法系列的,现在应该已经很多版本了吧,是基于窗口互动的,核心思想就是复用相同的字符串,如果后面的字符串出现了前面重复,用一个标记代替,可以大大节省压缩数量。
好了,花了1000多字,理了理思路,也起到了复习的效果了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号