
高级数据结构研究-B树系列以及红黑树
程序员做的越久,越发觉得基本功显得越来越重要了。基本功不扎实会潜移默化的影响你的程序开发,这不是,上次浏览博客,看到了一篇运用B+树实现数据库索引的功能,当时就不明白了,看似毫无关系的两者,怎么会有联系呢,所以想把大学时学的数据结构拿来看看,这到底怎么回事,当然了,看过了之后,顺便把另一种高级树结构-红黑树也看了一下,红黑树,说起来,容易,实现起来那代码看的人真是眼花。红黑树的插入,删除实现,同学们自行研究,哈哈。
首先说说B树系列,为什么是B字母开头,应该是Binary的意思,二分嘛,B树分为B树,B-,B+树,普通的二叉搜索树,比较简单的,不是我说的重点,再看B-树,来个图直接明了,
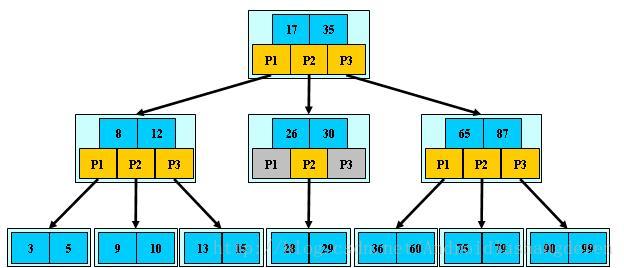
B-树的性质如下:
是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
B-树的查找关键字一般分为两2步;
(1)在B-树中查找结点
(2)在结点中查找关键字
因B-树通常存储在磁盘上,操作(1)一般在磁盘上进行,操作(2)在内存中进行,换句话说,在磁盘上查找到某结点所在的磁盘块,将此磁盘块中的内容调入到内存中,然后再利用内查找的算法(如,二分查找,顺序查找等)查找关键字。
B+树的出现其实是B-树的一个变种。同样上图片
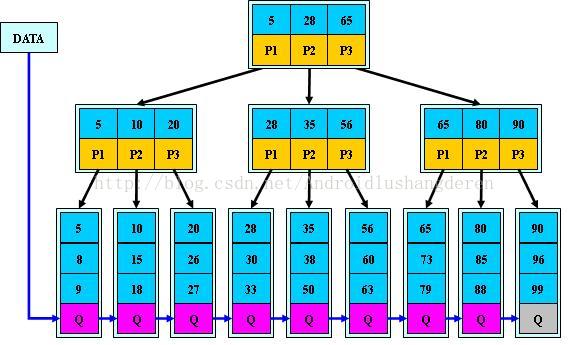
B+树的相关性质:
1.非叶子结点的子树指针与关键字个数相同;
2.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
3.为所有叶子结点增加一个链指针;
4.所有关键字都在叶子结点出现;
B+树也存在一些与B-树不一样的地方
(1).所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
(2).不可能在非叶子结点命中;
(3).非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
(4).更适合文件索引系统;
B-,B+树都是比较典型的动态索引结构,在数据库的索引上用得比较多,相比之下,有人肯定会说,那红黑树是用在什么地方的呢,红黑树到底是什么呢
先给出红黑树在维基百科上的定义:
红黑树是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。它是在1972年由鲁道夫·贝尔发明的,他称之为"对称二叉B树",它现代的名字是在 Leo J. Guibas 和 Robert Sedgewick 于1978年写的一篇论文中获得的。它是复杂的,但它的操作有着良好的最坏情况运行时间,并且在实践中是高效的: 它可以在O(log n)时间内做查找,插入和删除,这里的n是树中元素的数目。
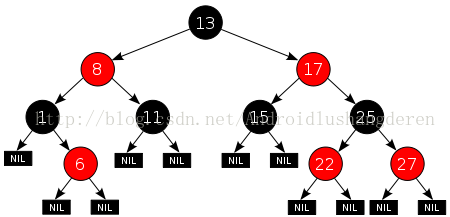
红黑树是每个节点都带有颜色属性的二叉查找树,颜色为红色或黑色。在二叉查找树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:
性质1. 节点是红色或黑色。
性质2. 根是黑色。
性质3. 所有叶子都是黑色(叶子是NIL节点)。
性质4. 每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
性质5. 从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
根据性质5所有最长的路径都有相同数目的黑色节点,又因为性质4说的是不可能出现连续2个红色的结点,那基本就是黑红交替结点的了,如果是黑黑同时出现,就不满足性质5了,这就表明了没有路径能多于任何其他路径的两倍长。正式因为有了这些特殊的要求约束,所以红黑树是一个比较高性能的树,基本是上平衡的,左右子树的深度不会超过1,查找,删除,时间基本控制O(logn)的水准上。
那么红黑树与B树系列到底有什么微小的区别,或者说适用的场合又有哪些不一样呢?答案是红黑树多用在内部排序,即全放在内存中的,微软STL的map和set的内部实现就是红黑树,(最近看的Linux进程管理采用的结构也是用的红黑树的,红黑树无处不在啊),B树多用在内存里放不下,大部分数据存储在外存上时。因为B树层数少,因此可以确保每次操作,读取磁盘的次数尽可能的少。
说了这么多,实际的操作显然比我这里写的要难很多,尤其是红黑树的调整操作,要维持他的这种属性,还要涉及树的旋转,以及结点的相关操作。

