网络新闻评论观点挖掘系统实现
前言
网络新闻观点挖掘系统事实上本质是属于文本数据挖掘范畴的,对于文本挖掘的方式,在早期主要是基于Web文本挖掘领域的。当然这个挖掘的尺度是可以控制的,粗粒度的挖掘相对于细粒度的挖掘要简单不少,粗粒度挖掘可以快速的多数网民们对某新闻的观点倾向,这也是我毕设作品所需要达到的目标。
系统设计目标
平时做了许多挖掘算法的研究,一直懒得去做一些能智能分析化的工具,恰好这次可以利用毕业设计的机会,做一个观点挖掘分析系统。系统设计的目标就是能对一则特定的新闻,通过利用千条评论数据,挖掘出其中的观点倾向分类,提供给人们信息参考。
系统设计模块
系统主要模块分为4大模块,下面是主要的模块组成:
字典库与数据源的获取
字典库是利用已经收集好的一个多达2w余条记录的txt文件,这个是比较简单的,但是数据源的获取就需要经过一些步骤,利用了之前我介绍过的QQ爬虫工具,详情点击这里,爬取的数据就是某条新闻页的部分评论数据。QQ评论数据爬虫的原理就是先去获取一个新闻详情页的HTML代码,做正则匹配,获得其中的cmt_id评论id,然后再发送另外一个请求url取获取真正的评论数据,在此次系统设计中,每次最多只能爬取50条数据,爬取总量为1000条,但是时间消耗会略久,30s左右。
文本预处理操作
在实现本次挖掘系统中同样需要有文本预处理的操作,但是文本预处理不会做的那么细,只是会粗糙的过滤一些数字词,连接符,以及一些无效词,比如像"的"这样的词语,这些词的过滤可以减少后面暴力匹配的次数,预处理完毕之后,以标点符号作为分隔符,进行观点子句分割存入一个新的list。
词性识别和词性标注
这个模块是挖掘系统的核心模块,分为2个子步骤,1个步骤是识别,识别是通过里面的子句中的词语与字典库中的观点词去进行暴力匹配,性能上会比较糟糕,但是效果还行,匹配的原理类似于a字符串完全包含b字符串的比较原理,这里面的运算级别已经达到千万级别了。判别出每个观点词之后,会进行词性的标记,每段观点的极性等于其中的各个子句的观点极性的和,而子句中的观点等于内部中出现的所有观点词的极性和。
终端结果展示
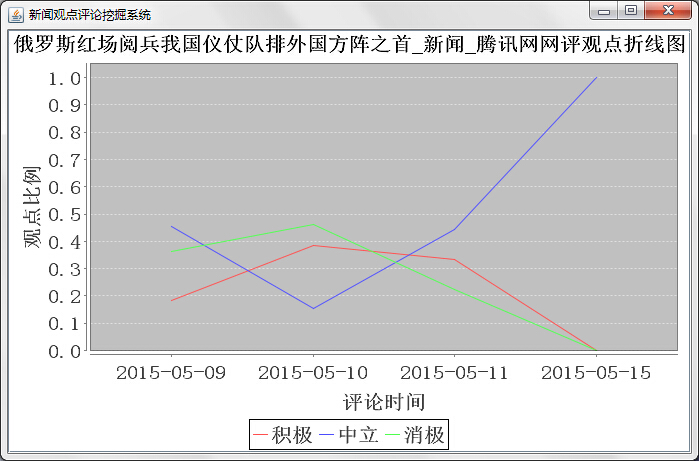
终端结果展示需要利用上个模块中分析出的观点极性列表,分析的结果用到了jfreeChart 图表工具包,我利用了其中的柱形图,饼图图和折线图,前2个图的功能类似,折线图可以用来提取出其中的观点倾向分类走势。饼状图和柱形图中的分类分为了7大类,消极观点弱中强,中立,积极观点弱中强。折线图的分类就稍微简单一点,为消极,中立,积极的观点。
下面是效果图的展现,具体代码请点击我的项目地址opition-mining-system.
系统主界面入口:
填入腾讯新闻链接地址,评论数据输出地址可以不填,默认输出到D盘中,点击开始挖掘,会停顿一段时间,因为这里我犯了一个错误,在ui主线程中调用了网络请求,造成假死状态。

然后是功能页,具体的作用就是上面的按钮文字所描述的意思。点击进去各个具体页面如下:




 浙公网安备 33010602011771号
浙公网安备 33010602011771号