


HDFS源码分析(二)-----元数据备份机制
前言
在Hadoop中,所有的元数据的保存都是在namenode节点之中,每次重新启动整个集群,Hadoop都需要从这些持久化了的文件中恢复数据到内存中,然后通过镜像和编辑日志文件进行定期的扫描与合并,ok,这些稍微了解Hadoop的人应该都知道,这不就是SecondNameNode干的事情嘛,但是很多人只是了解此机制的表象,内部的一些实现机理估计不是每个人都又去深究过,你能想象在写入编辑日志的过程中,用到了双缓冲区来加大并发量的写吗,你能想象为了避免操作的一致性性,作者在写入的时候做过多重的验证操作,还有你有想过作者是如何做到操作中断的处理情况吗,如果你不能很好的回答上述几个问题,那么没有关系,下面来分享一下我的学习成果。
相关涉及类
建议读者在阅读本文的过程中,结合代码一起阅读, Hadoop的源码可自行下载,这样效果可能会更好。与本文有涉及的类包括下面一些,比上次的分析略多一点,个别主类的代码量已经在上千行了。
1.FSImage--命名空间镜像类,所有关于命名空间镜像的操作方法都被包括在了这个方法里面。
2.FSEditLog--编辑日志类,编辑日志类涉及到了每个操作记录的写入。
3.EditLogInputStream和EditLogOutputStream--编辑日志输入类和编辑日志输出类,编辑日志的许多文件写入读取操作都是在这2个类的基础上实现的,这2个类是普通输入流类的继承类,对外开放了几个针对于日志读写的特有方法。
4.Storage和StorageInfo--存储信息相关类。其中后者是父类,Storage继承了后者,这2个类是存储目录直接相关的类,元数据的备份相关的很多目录操作都与此相关。
5.SecondaryNameNode--本来不想把这个类拉进去来的,但是为了使整个备份机制更加完整的呈现出来,同样也是需要去了解这一部分的代码。
ok,介绍完了这些类,下面正式进入元数据备份机制的讲解,不过在此之前,必须要了解各个对象的具体操作实现,里面有很多巧妙的设计,同时也为了防止被后面的方法绕晕,方法的确很多,但我会挑出几个代表性的来讲。
命名空间镜像
命名空间镜像在这里简称为FsImage,镜像这个词我最早听的时候是在虚拟机镜像恢复的时候听过的,很强大,不过在这里的镜像好像比较小规模一些,只是用于目录树的恢复。镜像的保存路径是由配置文件中的下面这个属性所控制
${dfs.name.dir}当然你可以不配,是有默认值的。在命名空间镜像中,FSImage起着主导的作用,他管理着存储空间的生存期。下面是这个类的基本变量定义
/**
* FSImage handles checkpointing and logging of the namespace edits.
* fsImage镜像类
*/
public class FSImage extends Storage {
//标准时间格式
private static final SimpleDateFormat DATE_FORM =
new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//
// The filenames used for storing the images
// 在命名空间镜像中可能用的几种名称
//
enum NameNodeFile {
IMAGE ("fsimage"),
TIME ("fstime"),
EDITS ("edits"),
IMAGE_NEW ("fsimage.ckpt"),
EDITS_NEW ("edits.new");
private String fileName = null;
private NameNodeFile(String name) {this.fileName = name;}
String getName() {return fileName;}
}
// checkpoint states
// 检查点击几种状态
enum CheckpointStates{START, ROLLED_EDITS, UPLOAD_START, UPLOAD_DONE; }
/**
* Implementation of StorageDirType specific to namenode storage
* A Storage directory could be of type IMAGE which stores only fsimage,
* or of type EDITS which stores edits or of type IMAGE_AND_EDITS which
* stores both fsimage and edits.
* 名字节点目录存储类型
*/
static enum NameNodeDirType implements StorageDirType {
//名字节点存储类型定义主要有以下4种定义
UNDEFINED,
IMAGE,
EDITS,
IMAGE_AND_EDITS;
public StorageDirType getStorageDirType() {
return this;
}
//做存储类型的验证
public boolean isOfType(StorageDirType type) {
if ((this == IMAGE_AND_EDITS) && (type == IMAGE || type == EDITS))
return true;
return this == type;
}
}
protected long checkpointTime = -1L;
//内部维护了编辑日志类,与镜像类配合操作
protected FSEditLog editLog = null;
private boolean isUpgradeFinalized = false;//目录迭代器
private class DirIterator implements Iterator<StorageDirectory> {
//目录存储类型
StorageDirType dirType;
//向前的指标,用于移除操作
int prevIndex; // for remove()
//向后指标
int nextIndex; // for next()
DirIterator(StorageDirType dirType) {
this.dirType = dirType;
this.nextIndex = 0;
this.prevIndex = 0;
}
public boolean hasNext() {
....
}
public StorageDirectory next() {
StorageDirectory sd = getStorageDir(nextIndex);
prevIndex = nextIndex;
nextIndex++;
if (dirType != null) {
while (nextIndex < storageDirs.size()) {
if (getStorageDir(nextIndex).getStorageDirType().isOfType(dirType))
break;
nextIndex++;
}
}
return sd;
}
public void remove() {
...
}
}根据传入的目录类型,获取不同的目录,这些存储目录指的就是editlog,fsimage这些目录文件,有一些共有的信息,如下
/**
* Common class for storage information.
* 存储信息公告类
* TODO namespaceID should be long and computed as hash(address + port)
* 命名空间ID必须足够长,ip地址+端口号做哈希计算而得
*/
public class StorageInfo {
//存储信息版本号
public int layoutVersion; // Version read from the stored file.
//命名空间ID
public int namespaceID; // namespace id of the storage
//存储信息创建时间
public long cTime; // creation timestamp
public StorageInfo () {
//默认构造函数,全为0
this(0, 0, 0L);
}下面从1个保存镜像的方法作为切入口
/**
* Save the contents of the FS image to the file.
* 保存镜像文件
*/
void saveFSImage(File newFile) throws IOException {
FSNamesystem fsNamesys = FSNamesystem.getFSNamesystem();
FSDirectory fsDir = fsNamesys.dir;
long startTime = FSNamesystem.now();
//
// Write out data
//
DataOutputStream out = new DataOutputStream(
new BufferedOutputStream(
new FileOutputStream(newFile)));
try {
//写入版本号
out.writeInt(FSConstants.LAYOUT_VERSION);
//写入命名空间ID
out.writeInt(namespaceID);
//写入目录下的孩子总数
out.writeLong(fsDir.rootDir.numItemsInTree());
//写入时间
out.writeLong(fsNamesys.getGenerationStamp());
byte[] byteStore = new byte[4*FSConstants.MAX_PATH_LENGTH];
ByteBuffer strbuf = ByteBuffer.wrap(byteStore);
// save the root
saveINode2Image(strbuf, fsDir.rootDir, out);
// save the rest of the nodes
saveImage(strbuf, 0, fsDir.rootDir, out);
fsNamesys.saveFilesUnderConstruction(out);
fsNamesys.saveSecretManagerState(out);
strbuf = null;
} finally {
out.close();
}
LOG.info("Image file of size " + newFile.length() + " saved in "
+ (FSNamesystem.now() - startTime)/1000 + " seconds.");
}/*
* Save one inode's attributes to the image.
* 保留一个节点的属性到镜像中
*/
private static void saveINode2Image(ByteBuffer name,
INode node,
DataOutputStream out) throws IOException {
int nameLen = name.position();
out.writeShort(nameLen);
out.write(name.array(), name.arrayOffset(), nameLen);
if (!node.isDirectory()) { // write file inode
INodeFile fileINode = (INodeFile)node;
//写入的属性包括,副本数,最近修改数据,最近访问时间
out.writeShort(fileINode.getReplication());
out.writeLong(fileINode.getModificationTime());
out.writeLong(fileINode.getAccessTime());
out.writeLong(fileINode.getPreferredBlockSize());
Block[] blocks = fileINode.getBlocks();
out.writeInt(blocks.length);
for (Block blk : blocks)
//将数据块信息也写入
blk.write(out);
FILE_PERM.fromShort(fileINode.getFsPermissionShort());
PermissionStatus.write(out, fileINode.getUserName(),
fileINode.getGroupName(),
FILE_PERM);
} else { // write directory inode
//如果是目录,则还要写入节点的配额限制值
out.writeShort(0); // replication
out.writeLong(node.getModificationTime());
out.writeLong(0); // access time
out.writeLong(0); // preferred block size
out.writeInt(-1); // # of blocks
out.writeLong(node.getNsQuota());
out.writeLong(node.getDsQuota());
FILE_PERM.fromShort(node.getFsPermissionShort());
PermissionStatus.write(out, node.getUserName(),
node.getGroupName(),
FILE_PERM);
}
}在这里面会写入更多的关于文件目录的信息,此方法也会被saveImage()递归调用
/**
* Save file tree image starting from the given root.
* This is a recursive procedure, which first saves all children of
* a current directory and then moves inside the sub-directories.
* 按照给定节点进行镜像的保存,每个节点目录会采取递归的方式进行遍历
*/
private static void saveImage(ByteBuffer parentPrefix,
int prefixLength,
INodeDirectory current,
DataOutputStream out) throws IOException {
int newPrefixLength = prefixLength;
if (current.getChildrenRaw() == null)
return;
for(INode child : current.getChildren()) {
// print all children first
parentPrefix.position(prefixLength);
parentPrefix.put(PATH_SEPARATOR).put(child.getLocalNameBytes());
saveINode2Image(parentPrefix, child, out);
....
}// Helper function that writes an INodeUnderConstruction
// into the input stream
// 写入正在操作的文件的信息
//
static void writeINodeUnderConstruction(DataOutputStream out,
INodeFileUnderConstruction cons,
String path)
throws IOException {
writeString(path, out);
out.writeShort(cons.getReplication());
out.writeLong(cons.getModificationTime());
out.writeLong(cons.getPreferredBlockSize());
int nrBlocks = cons.getBlocks().length;
out.writeInt(nrBlocks);
for (int i = 0; i < nrBlocks; i++) {
cons.getBlocks()[i].write(out);
}
cons.getPermissionStatus().write(out);
writeString(cons.getClientName(), out);
writeString(cons.getClientMachine(), out);
out.writeInt(0); // do not store locations of last block
}public void format() throws IOException {
this.layoutVersion = FSConstants.LAYOUT_VERSION;
//对每个目录进行格式化操作
format(sd);
}
}
/** Create new dfs name directory. Caution: this destroys all files
* 格式化操作,会创建一个dfs/name的目录
* in this filesystem. */
void format(StorageDirectory sd) throws IOException {
sd.clearDirectory(); // create currrent dir
sd.lock();
try {
saveCurrent(sd);
} finally {
sd.unlock();
}
LOG.info("Storage directory " + sd.getRoot()
+ " has been successfully formatted.");
}编辑日志
下面开始另外一个大类的分析,就是编辑日志,英文名就是EditLog,这个里面将会有许多出彩的设计。打开这个类,你马上就看到的是几十种的操作码
/**
* FSEditLog maintains a log of the namespace modifications.
* 编辑日志类包含了命名空间各种修改操作的日志记录
*/
public class FSEditLog {
//操作参数种类
private static final byte OP_INVALID = -1;
// 文件操作相关
private static final byte OP_ADD = 0;
private static final byte OP_RENAME = 1; // rename
private static final byte OP_DELETE = 2; // delete
private static final byte OP_MKDIR = 3; // create directory
private static final byte OP_SET_REPLICATION = 4; // set replication
//the following two are used only for backward compatibility :
@Deprecated private static final byte OP_DATANODE_ADD = 5;
@Deprecated private static final byte OP_DATANODE_REMOVE = 6;
//下面2个权限设置相关
private static final byte OP_SET_PERMISSIONS = 7;
private static final byte OP_SET_OWNER = 8;
private static final byte OP_CLOSE = 9; // close after write
private static final byte OP_SET_GENSTAMP = 10; // store genstamp
/* The following two are not used any more. Should be removed once
* LAST_UPGRADABLE_LAYOUT_VERSION is -17 or newer. */
//配额设置相关
private static final byte OP_SET_NS_QUOTA = 11; // set namespace quota
private static final byte OP_CLEAR_NS_QUOTA = 12; // clear namespace quota
private static final byte OP_TIMES = 13; // sets mod & access time on a file
private static final byte OP_SET_QUOTA = 14; // sets name and disk quotas.
//Token认证相关
private static final byte OP_GET_DELEGATION_TOKEN = 18; //new delegation token
private static final byte OP_RENEW_DELEGATION_TOKEN = 19; //renew delegation token
private static final byte OP_CANCEL_DELEGATION_TOKEN = 20; //cancel delegation token
private static final byte OP_UPDATE_MASTER_KEY = 21; //update master key//日志刷入的缓冲大小值512k
private static int sizeFlushBuffer = 512*1024;
//编辑日志同时有多个输出流对象
private ArrayList<EditLogOutputStream> editStreams = null;
//内部维护了1个镜像类,与镜像进行交互
private FSImage fsimage = null;
// a monotonically increasing counter that represents transactionIds.
//每次进行同步刷新的事物ID
private long txid = 0;
// stores the last synced transactionId.
//最近一次已经同步的事物Id
private long synctxid = 0;
// the time of printing the statistics to the log file.
private long lastPrintTime;
// is a sync currently running?
//是否有日志同步操作正在进行
private boolean isSyncRunning;
// these are statistics counters.
//事务相关的统计变量
//事务的总数
private long numTransactions; // number of transactions
//未能即使被同步的事物次数统计
private long numTransactionsBatchedInSync;
//事务的总耗时
private long totalTimeTransactions; // total time for all transactions
private NameNodeInstrumentation metrics;//事物ID对象类,内部包含long类型txid值
private static class TransactionId {
//操作事物Id
public long txid;
TransactionId(long value) {
this.txid = value;
}
}
// stores the most current transactionId of this thread.
//通过ThreadLocal类保存线程私有的状态信息
private static final ThreadLocal<TransactionId> myTransactionId = new ThreadLocal<TransactionId>() {
protected synchronized TransactionId initialValue() {
return new TransactionId(Long.MAX_VALUE);
}
};,代码被我简化了一些
/**
* A generic abstract class to support journaling of edits logs into
* a persistent storage.
*/
abstract class EditLogOutputStream extends OutputStream {
// these are statistics counters
//下面是2个统计量
//文件同步的次数,可以理解为就是缓冲写入的次数
private long numSync; // number of sync(s) to disk
//同步写入的总时间计数
private long totalTimeSync; // total time to sync
EditLogOutputStream() throws IOException {
numSync = totalTimeSync = 0;
}
abstract String getName();
abstract public void write(int b) throws IOException;
abstract void write(byte op, Writable ... writables) throws IOException;
abstract void create() throws IOException;
abstract public void close() throws IOException;
abstract void setReadyToFlush() throws IOException;
abstract protected void flushAndSync() throws IOException;
/**
* Flush data to persistent store.
* Collect sync metrics.
* 刷出时间方法
*/
public void flush() throws IOException {
//同步次数加1
numSync++;
long start = FSNamesystem.now();
//刷出同步方法为抽象方法,由继承的子类具体
flushAndSync();
long end = FSNamesystem.now();
//同时进行耗时的累加
totalTimeSync += (end - start);
}
abstract long length() throws IOException;
long getTotalSyncTime() {
return totalTimeSync;
}
long getNumSync() {
return numSync;
}
}
/**
* An implementation of the abstract class {@link EditLogOutputStream},
* which stores edits in a local file.
* 所有的写日志文件的操作,都会通过这个输出流对象实现
*/
static private class EditLogFileOutputStream extends EditLogOutputStream {
private File file;
//内部维护了一个文件输出流对象
private FileOutputStream fp; // file stream for storing edit logs
private FileChannel fc; // channel of the file stream for sync
//这里设计了一个双缓冲区的设计,大大加强并发度,bufCurrent负责写入写入缓冲区
private DataOutputBuffer bufCurrent; // current buffer for writing
//bufReady负载刷入数据到文件中
private DataOutputBuffer bufReady; // buffer ready for flushing
static ByteBuffer fill = ByteBuffer.allocateDirect(512); // preallocation/**
* Create empty edit log files.
* Initialize the output stream for logging.
*
* @throws IOException
*/
public synchronized void open() throws IOException {
//在文件打开的时候,计数值都初始化0
numTransactions = totalTimeTransactions = numTransactionsBatchedInSync = 0;
if (editStreams == null) {
editStreams = new ArrayList<EditLogOutputStream>();
}
//传入目录类型获取迭代器
Iterator<StorageDirectory> it = fsimage.dirIterator(NameNodeDirType.EDITS);
while (it.hasNext()) {
StorageDirectory sd = it.next();
File eFile = getEditFile(sd);
try {
//打开存储目录下的文件获取输出流
EditLogOutputStream eStream = new EditLogFileOutputStream(eFile);
editStreams.add(eStream);
} catch (IOException ioe) {
fsimage.updateRemovedDirs(sd, ioe);
it.remove();
}
}
exitIfNoStreams();
} /**
* Shutdown the file store.
* 关闭操作
*/
public synchronized void close() throws IOException {
while (isSyncRunning) {
//如果同正在进行,则等待1s
try {
wait(1000);
} catch (InterruptedException ie) {
}
}
if (editStreams == null) {
return;
}
printStatistics(true);
//当文件关闭的时候重置计数
numTransactions = totalTimeTransactions = numTransactionsBatchedInSync = 0;
for (int idx = 0; idx < editStreams.size(); idx++) {
EditLogOutputStream eStream = editStreams.get(idx);
try {
//关闭将最后的数据刷出缓冲
eStream.setReadyToFlush();
eStream.flush();
eStream.close();
} catch (IOException ioe) {
removeEditsAndStorageDir(idx);
idx--;
}
}
editStreams.clear();
}/**
* All data that has been written to the stream so far will be flushed.
* New data can be still written to the stream while flushing is performed.
*/
@Override
void setReadyToFlush() throws IOException {
assert bufReady.size() == 0 : "previous data is not flushed yet";
write(OP_INVALID); // insert end-of-file marker
//交换2个缓冲区
DataOutputBuffer tmp = bufReady;
bufReady = bufCurrent;
bufCurrent = tmp;
} /**
* Flush data to persistent store.
* Collect sync metrics.
* 刷出时间方法
*/
public void flush() throws IOException {
//同步次数加1
numSync++;
long start = FSNamesystem.now();
//刷出同步方法为抽象方法,由继承的子类具体
flushAndSync();
long end = FSNamesystem.now();
//同时进行耗时的累加
totalTimeSync += (end - start);
}/**
* Flush ready buffer to persistent store.
* currentBuffer is not flushed as it accumulates new log records
* while readyBuffer will be flushed and synced.
*/
@Override
protected void flushAndSync() throws IOException {
preallocate(); // preallocate file if necessary
//将ready缓冲区中的数据写入文件中
bufReady.writeTo(fp); // write data to file
bufReady.reset(); // erase all data in the buffer
fc.force(false); // metadata updates not needed because of preallocation
//跳过无效标志位,因为无效标志位每次都会写入
fc.position(fc.position()-1); // skip back the end-of-file marker
}/**
* Add set replication record to edit log
*/
void logSetReplication(String src, short replication) {
logEdit(OP_SET_REPLICATION,
new UTF8(src),
FSEditLog.toLogReplication(replication));
}
/** Add set namespace quota record to edit log
*
* @param src the string representation of the path to a directory
* @param quota the directory size limit
*/
void logSetQuota(String src, long nsQuota, long dsQuota) {
logEdit(OP_SET_QUOTA, new UTF8(src),
new LongWritable(nsQuota), new LongWritable(dsQuota));
}
/** Add set permissions record to edit log */
void logSetPermissions(String src, FsPermission permissions) {
logEdit(OP_SET_PERMISSIONS, new UTF8(src), permissions);
}/**
* Write an operation to the edit log. Do not sync to persistent
* store yet.
* 写入一个操作到编辑日志中
*/
synchronized void logEdit(byte op, Writable ... writables) {
if (getNumEditStreams() < 1) {
throw new AssertionError("No edit streams to log to");
}
long start = FSNamesystem.now();
for (int idx = 0; idx < editStreams.size(); idx++) {
EditLogOutputStream eStream = editStreams.get(idx);
try {
// 写入操作到每个输出流中
eStream.write(op, writables);
} catch (IOException ioe) {
removeEditsAndStorageDir(idx);
idx--;
}
}
exitIfNoStreams();
// get a new transactionId
//获取一个新的事物Id
txid++;
//
// record the transactionId when new data was written to the edits log
//
TransactionId id = myTransactionId.get();
id.txid = txid;
// update statistics
long end = FSNamesystem.now();
//在每次进行logEdit写入记录操作的时候,都会累加事物次数和耗时
numTransactions++;
totalTimeTransactions += (end-start);
if (metrics != null) // Metrics is non-null only when used inside name node
metrics.addTransaction(end-start);
}//
// Sync all modifications done by this thread.
//
public void logSync() throws IOException {
ArrayList<EditLogOutputStream> errorStreams = null;
long syncStart = 0;
// Fetch the transactionId of this thread.
long mytxid = myTransactionId.get().txid;
ArrayList<EditLogOutputStream> streams = new ArrayList<EditLogOutputStream>();
boolean sync = false;
try {
synchronized (this) {
printStatistics(false);
// if somebody is already syncing, then wait
while (mytxid > synctxid && isSyncRunning) {
try {
wait(1000);
} catch (InterruptedException ie) {
}
}
//
// If this transaction was already flushed, then nothing to do
//
if (mytxid <= synctxid) {
//当执行的事物id小于已同步的Id,也进行计数累加
numTransactionsBatchedInSync++;
if (metrics != null) // Metrics is non-null only when used inside name node
metrics.incrTransactionsBatchedInSync();
return;
}
// now, this thread will do the sync
syncStart = txid;
isSyncRunning = true;
sync = true;
// swap buffers
exitIfNoStreams();
for(EditLogOutputStream eStream : editStreams) {
try {
//交换缓冲
eStream.setReadyToFlush();
streams.add(eStream);
} catch (IOException ie) {
FSNamesystem.LOG.error("Unable to get ready to flush.", ie);
//
// remember the streams that encountered an error.
//
if (errorStreams == null) {
errorStreams = new ArrayList<EditLogOutputStream>(1);
}
errorStreams.add(eStream);
}
}
}
// do the sync
long start = FSNamesystem.now();
for (EditLogOutputStream eStream : streams) {
try {
//同步完成之后,做输入数据操作
eStream.flush();
....
}/**
* Load an edit log, and apply the changes to the in-memory structure
* This is where we apply edits that we've been writing to disk all
* along.
* 导入编辑日志文件,并在内存中构建此时状态
*/
static int loadFSEdits(EditLogInputStream edits) throws IOException {
FSNamesystem fsNamesys = FSNamesystem.getFSNamesystem();
//FSDirectory是一个门面模式的体现,所有的操作都是在这个类中分给里面的子系数实现
FSDirectory fsDir = fsNamesys.dir;
int numEdits = 0;
int logVersion = 0;
String clientName = null;
String clientMachine = null;
String path = null;
int numOpAdd = 0, numOpClose = 0, numOpDelete = 0,
numOpRename = 0, numOpSetRepl = 0, numOpMkDir = 0,
numOpSetPerm = 0, numOpSetOwner = 0, numOpSetGenStamp = 0,
numOpTimes = 0, numOpGetDelegationToken = 0,
numOpRenewDelegationToken = 0, numOpCancelDelegationToken = 0,
numOpUpdateMasterKey = 0, numOpOther = 0;
long startTime = FSNamesystem.now();
DataInputStream in = new DataInputStream(new BufferedInputStream(edits));
try {
// Read log file version. Could be missing.
in.mark(4);
// If edits log is greater than 2G, available method will return negative
// numbers, so we avoid having to call available
boolean available = true;
try {
// 首先读入日志版本号
logVersion = in.readByte();
} catch (EOFException e) {
available = false;
}
if (available) {
in.reset();
logVersion = in.readInt();
if (logVersion < FSConstants.LAYOUT_VERSION) // future version
throw new IOException(
"Unexpected version of the file system log file: "
+ logVersion + ". Current version = "
+ FSConstants.LAYOUT_VERSION + ".");
}
assert logVersion <= Storage.LAST_UPGRADABLE_LAYOUT_VERSION :
"Unsupported version " + logVersion;
while (true) {
....
//下面根据操作类型进行值的设置
switch (opcode) {
case OP_ADD:
case OP_CLOSE: {
...
break;
}
case OP_SET_REPLICATION: {
numOpSetRepl++;
path = FSImage.readString(in);
short replication = adjustReplication(readShort(in));
fsDir.unprotectedSetReplication(path, replication, null);
break;
}
case OP_RENAME: {
numOpRename++;
int length = in.readInt();
if (length != 3) {
throw new IOException("Incorrect data format. "
+ "Mkdir operation.");
}
String s = FSImage.readString(in);
String d = FSImage.readString(in);
timestamp = readLong(in);
HdfsFileStatus dinfo = fsDir.getFileInfo(d);
fsDir.unprotectedRenameTo(s, d, timestamp);
fsNamesys.changeLease(s, d, dinfo);
break;
}
...整个函数代码非常长,大家理解思路即可。里面的很多操作都是在FSDirectory中实现的,你可以理解整个类为一个门面模式,各个相关的子系统都包括在这个类中。
NameNode元数据备份机制
有了以上的方法做铺垫,元数据的备份机制才得以灵活的实现,无非就是调用上述的基础方法进行各个文件的拷贝,重命名等操作。整体上需要发生文件状态变化的操作如下:
1.原current镜像目录-->lastcheckpoint.tmp
2.第二名字节点上传新的镜像文件后fsimage.ckpt-->fsimage,并创建新的current目录
3.lastcheckpoint.tmp变为previous.checkpoint
4.日志文件edit.new-->edit文件
大体上是以上4条思路。
首先镜像文件的备份都是从第二名字节点的周期性检查点检测开始的
//
// The main work loop
//
public void doWork() {
long period = 5 * 60; // 5 minutes
long lastCheckpointTime = 0;
if (checkpointPeriod < period) {
period = checkpointPeriod;
}
//主循环程序
while (shouldRun) {
try {
Thread.sleep(1000 * period);
} catch (InterruptedException ie) {
// do nothing
}
if (!shouldRun) {
break;
}
try {
// We may have lost our ticket since last checkpoint, log in again, just in case
if(UserGroupInformation.isSecurityEnabled())
UserGroupInformation.getCurrentUser().reloginFromKeytab();
long now = System.currentTimeMillis();
long size = namenode.getEditLogSize();
if (size >= checkpointSize ||
now >= lastCheckpointTime + 1000 * checkpointPeriod) {
//周期性调用检查点方法
doCheckpoint();
...
}
}
/**
* Create a new checkpoint
*/
void doCheckpoint() throws IOException {
// Do the required initialization of the merge work area.
//做初始化的镜像操作
startCheckpoint();
// Tell the namenode to start logging transactions in a new edit file
// Retuns a token that would be used to upload the merged image.
CheckpointSignature sig = (CheckpointSignature)namenode.rollEditLog();
// error simulation code for junit test
if (ErrorSimulator.getErrorSimulation(0)) {
throw new IOException("Simulating error0 " +
"after creating edits.new");
}
//从名字节点获取当前镜像或编辑日志
downloadCheckpointFiles(sig); // Fetch fsimage and edits
//进行镜像合并操作
doMerge(sig); // Do the merge
//
// Upload the new image into the NameNode. Then tell the Namenode
// to make this new uploaded image as the most current image.
//把合并好后的镜像重新上传到名字节点
putFSImage(sig);
// error simulation code for junit test
if (ErrorSimulator.getErrorSimulation(1)) {
throw new IOException("Simulating error1 " +
"after uploading new image to NameNode");
}
//通知名字节点进行镜像的替换操作,包括将edit.new的名称重新改为edit,镜像名称fsimage.ckpt改为fsImage
namenode.rollFsImage();
checkpointImage.endCheckpoint();
LOG.info("Checkpoint done. New Image Size: "
+ checkpointImage.getFsImageName().length());
}/**
* Moves fsimage.ckpt to fsImage and edits.new to edits
* Reopens the new edits file.
* 完成2个文件的名称替换
*/
void rollFSImage() throws IOException {
if (ckptState != CheckpointStates.UPLOAD_DONE) {
throw new IOException("Cannot roll fsImage before rolling edits log.");
}
//
// First, verify that edits.new and fsimage.ckpt exists in all
// checkpoint directories.
//
if (!editLog.existsNew()) {
throw new IOException("New Edits file does not exist");
}
Iterator<StorageDirectory> it = dirIterator(NameNodeDirType.IMAGE);
while (it.hasNext()) {
StorageDirectory sd = it.next();
File ckpt = getImageFile(sd, NameNodeFile.IMAGE_NEW);
if (!ckpt.exists()) {
throw new IOException("Checkpoint file " + ckpt +
" does not exist");
}
}
editLog.purgeEditLog(); // renamed edits.new to edits//
// Renames new image
// 重命名新镜像名称
//
it = dirIterator(NameNodeDirType.IMAGE);
while (it.hasNext()) {
StorageDirectory sd = it.next();
File ckpt = getImageFile(sd, NameNodeFile.IMAGE_NEW);
File curFile = getImageFile(sd, NameNodeFile.IMAGE);
// renameTo fails on Windows if the destination file
// already exists.
if (!ckpt.renameTo(curFile)) {
curFile.delete();
if (!ckpt.renameTo(curFile)) {
editLog.removeEditsForStorageDir(sd);
updateRemovedDirs(sd);
it.remove();
}
}
}
editLog.exitIfNoStreams();//
// Updates the fstime file on all directories (fsimage and edits)
// and write version file
//
this.layoutVersion = FSConstants.LAYOUT_VERSION;
this.checkpointTime = FSNamesystem.now();
it = dirIterator();
while (it.hasNext()) {
StorageDirectory sd = it.next();
// delete old edits if sd is the image only the directory
if (!sd.getStorageDirType().isOfType(NameNodeDirType.EDITS)) {
File editsFile = getImageFile(sd, NameNodeFile.EDITS);
editsFile.delete();
}
// delete old fsimage if sd is the edits only the directory
if (!sd.getStorageDirType().isOfType(NameNodeDirType.IMAGE)) {
File imageFile = getImageFile(sd, NameNodeFile.IMAGE);
imageFile.delete();
}这个过程本身比较复杂,还是用书中的一张图来表示好了,图可能有点大。
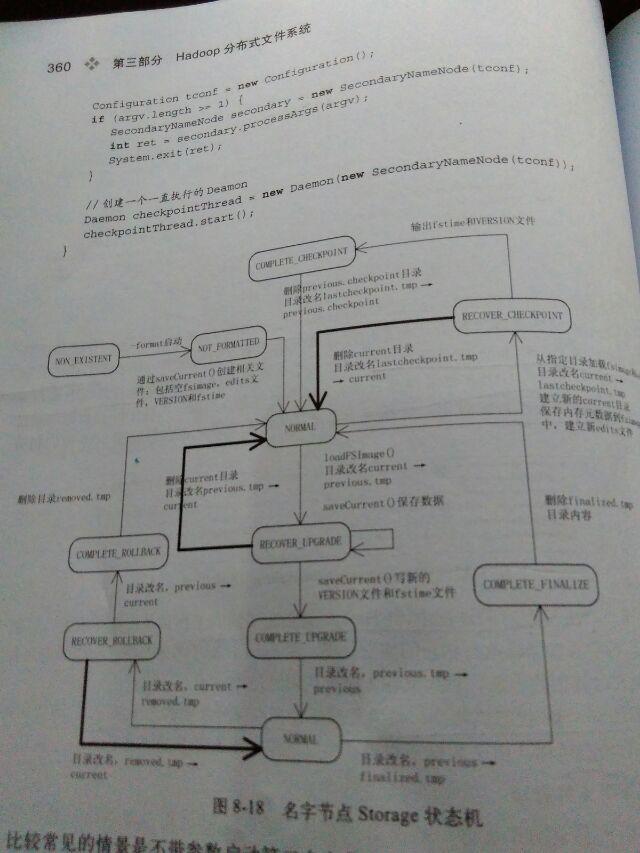
总结
至此,本篇内容阐述完毕,其实我还是忽略了许多细节部分,还是主要从主要的操作一步步的理清整个线索。建议可以在Hadoop运行的时候,跑到name和edit目录下观察各个目录的情况以此验证这整套机制了,或直接做upgrade测试升级工作也是可以的。全部代码的分析请点击链接
https://github.com/linyiqun/hadoop-hdfs,后续将会继续更新HDFS其他方面的代码分析。
参考文献
《Hadoop技术内部–HDFS结构设计与实现原理》.蔡斌等

