
Hadoop异常Task发现分析
前言
Hadoop作为一个大型的分布式系统,当他的规模不断的扩大,扩增到一定程度的时候,所使用的业务方自热而然的也会变多,不同的业务方会提交各种各样类型的任务,有人提交hive的查询任务,有人会写MapReduce解析程序的job.于是这就慢慢产生了一个叫"多租户"的概念.多租户最简单直接的理解就是一个大的公共自行车场,被一波人共同使用,自行车被人借光了,你就不能使用了,你就得等.但是,当这个用户越来越多的时候,一个很棘手的问题就会发生,某些不良"用户"独占大部分资源,导致其他的用户根本无法正常使用工作.今天本文所讨论的问题就是这个主题.对于此类问题,一般有2种解决方案,一个是分析管理,人工分析,然后手动操作管理,手动更改配置限定一下个别用户的资源使用上限,第二种则是用户的资源隔离,每位用户都固定分配好多少多少资源,只能用这么多.论难度而言,后者比前者更有技术难度,因为要改核心代码,今天就分析前面1种,就是分析找出这些"大户".
Hadoop现有监控的不足
把上面这个问题对应到Hadoop系统中,就是找出哪个user用的container,memory,cpu-vcores最多.单纯从Hadoop自身提供的一些工具来看,这些其实对于我们的帮助不大,不管说是ResourceManager的后台页还是JobHistory的历史job信息展示页来看,这些信息详细程序还是有的,就是太散,缺乏一个汇总这些数据信息的地方.例如1个finished job,我想要知道他是不是异常的job,那么我当然得需要知道里面的task异常的多不多,于是我就得在页面上继续往里点.这个数量小一点尚可接受,但是对于集群规模1天可达数万个job的集群时,根本难以想象.所以我们的初步目标就是2点,1个是汇总一些数据.2分析汇总后的数据,并做一些处理并展示到页面上,达到最直观的效果.
JobHistory的Task分析
在Hadoop层面,要想做到细粒度层面的分析,task级别的分析是一个不错的切入点.而Task的数据都是存在与JobHistory的.jhist文件中.于是我们可以在JobHistory的job解析的层面做一些加工.首先要知道JobHistory的页面是怎么生成的,首先他是在hadoop-mapredce-client-hs工程下的webapp包下.如下图所示的位置:
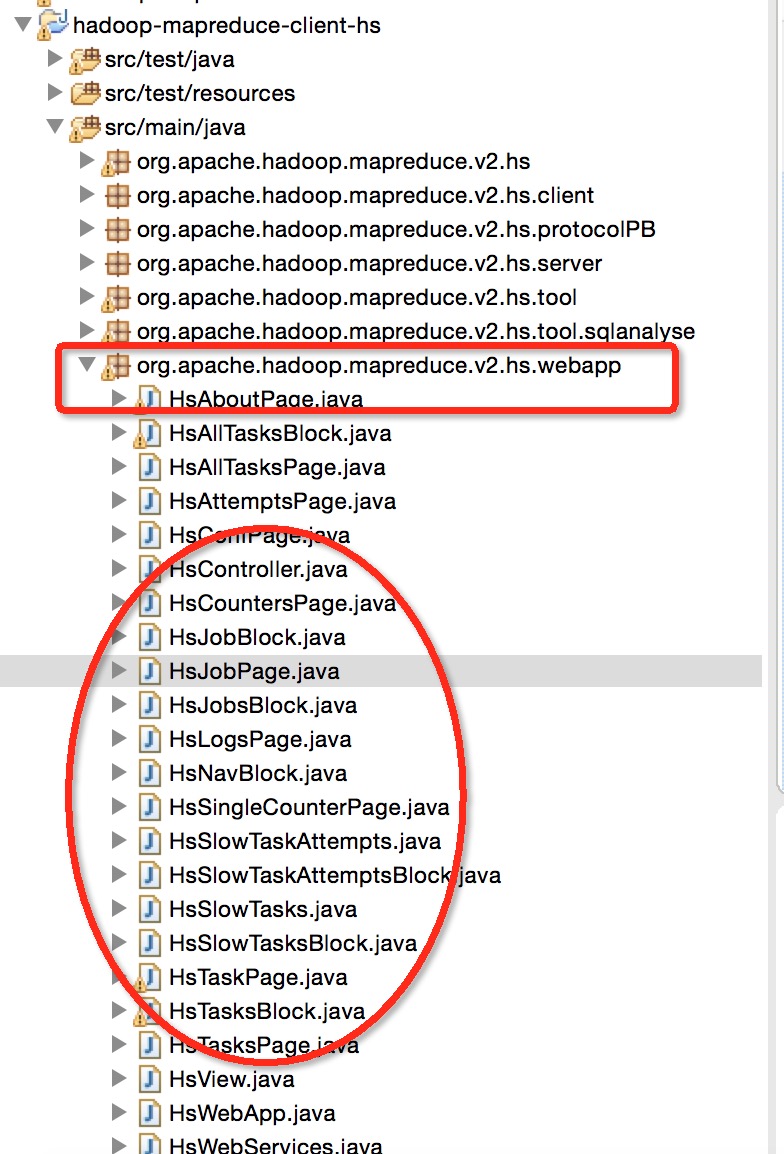
然后下面的Hs打头的类就是负责显示页面数据的逻辑代码.这部分的代码逻辑大致相同,读者可自行研究学习.然后我们找到一个与Job信息显示相关的一个类,HsJobBlock,分析一下里面的代码:
...
/*
* (non-Javadoc)
* @see org.apache.hadoop.yarn.webapp.view.HtmlBlock#render(org.apache.hadoop.yarn.webapp.view.HtmlBlock.Block)
*/
@Override protected void render(Block html) {
String jid = $(JOB_ID);
if (jid.isEmpty()) {
html.
p()._("Sorry, can't do anything without a JobID.")._();
return;
}
JobId jobID = MRApps.toJobID(jid);
Job j = appContext.getJob(jobID);
if (j == null) {
html.
p()._("Sorry, ", jid, " not found.")._();
return;
}
List<AMInfo> amInfos = j.getAMInfos();
JobInfo job = new JobInfo(j);
ResponseInfo infoBlock = info("Job Overview").
_("Job Name:", job.getName()).
_("User Name:", job.getUserName()).
_("Queue:", job.getQueueName()).
_("State:", job.getState()).
_("Uberized:", job.isUber()).
_("Submitted:", new Date(job.getSubmitTime())).
_("Started:", new Date(job.getStartTime())).
_("Finished:", new Date(job.getFinishTime())).
_("Elapsed:", StringUtils.formatTime(
Times.elapsed(job.getStartTime(), job.getFinishTime(), false)));
...
从图中基本可以看出,他的实现类是JobHistory类对象.job信息从AppContext中获取完毕之后,他是如何获取更多的关于内部的task信息的呢,答案在下面这几行代码中.
...
JobId jobID = MRApps.toJobID(jid);
Job j = appContext.getJob(jobID);
if (j == null) {
html.
p()._("Sorry, ", jid, " not found.")._();
return;
}
List<AMInfo> amInfos = j.getAMInfos();
JobInfo job = new JobInfo(j);
ResponseInfo infoBlock = info("Job Overview").
_("Job Name:", job.getName()).
...@XmlRootElement(name = "job")
@XmlAccessorType(XmlAccessType.FIELD)
public class JobInfo {
protected long submitTime;
protected long startTime;
protected long finishTime;
protected String id;
protected String name;
protected String queue;
protected String user;
protected String state;
protected int mapsTotal;
protected int mapsCompleted;
protected int reducesTotal;
protected int reducesCompleted;
...public JobInfo(Job job) {
this.id = MRApps.toString(job.getID());
JobReport report = job.getReport();
....
this.name = job.getName().toString();
this.queue = job.getQueueName();
this.user = job.getUserName();
this.state = job.getState().toString();
this.acls = new ArrayList<ConfEntryInfo>();
if (job instanceof CompletedJob) {
avgMapTime = 0l;
avgReduceTime = 0l;
avgShuffleTime = 0l;
avgMergeTime = 0l;
avgMapGcTime = 0L;
avgMapElapsedTime = 0L;
avgReduceElapsedTime = 0L;
...
countTasksAndAttempts(job);/**
* Go through a job and update the member variables with counts for
* information to output in the page.
*
* @param job
* the job to get counts for.
*/
private void countTasksAndAttempts(Job job) {
numReduces = 0;
numMaps = 0;
final Map<TaskId, Task> tasks = job.getTasks();
if (tasks == null) {
return;
}
for (Task task : tasks.values()) {
// Attempts counts
Map<TaskAttemptId, TaskAttempt> attempts = task.getAttempts();
int successful, failed, killed;
for (TaskAttempt attempt : attempts.values()) {
successful = 0;
failed = 0;
killed = 0;
if (TaskAttemptStateUI.NEW.correspondsTo(attempt.getState())) {
// Do Nothing
} else if (TaskAttemptStateUI.RUNNING.correspondsTo(attempt.getState())) {
// Do Nothing
} else if (TaskAttemptStateUI.SUCCESSFUL.correspondsTo(attempt
.getState())) {
++successful;
} else if (TaskAttemptStateUI.FAILED.correspondsTo(attempt.getState())) {
++failed;
} else if (TaskAttemptStateUI.KILLED.correspondsTo(attempt.getState())) {
++killed;
}
...自定义慢任务,异常任务筛选
我以目前我们公司对这方面的改造为1个例子,让大家真实的了解如何做到自定义的task筛选.分为2大主题,1个是slow taks,慢任务.第二个是error task,异常任务,这个主要针对的是task attempt.OK,下面仔细的描述下.
慢任务
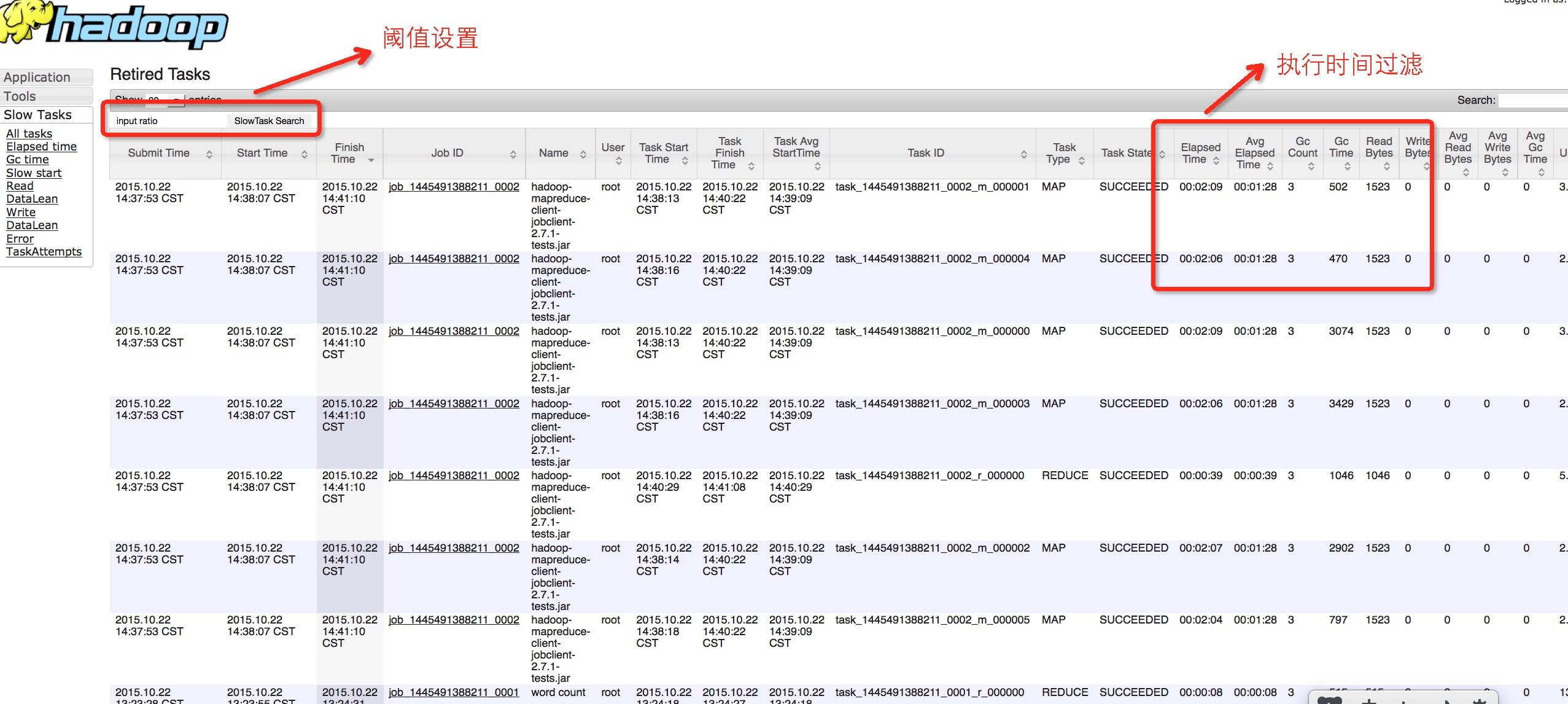
在这里所指的慢任务当然不是仅仅指的是执行时间的长短,只要涉及到时间值的,其他的维度也都是OK的,比如我们做了GC时间慢的,还有1个很关键的是启动时间明显偏慢的,尤其是启动时间偏慢的任务,对于我们发现一些异常的问题将会非常有用.而对于这些慢的任务,我们会在页面上设置一个文本输入框,用户可以传入自己想要设置的时间阈值.然后在JobInfo中进行过滤处理.下面给出一个按照执行时间的慢任务筛选:
public Map<TaskId, Task> getElapsedSlowTasks(Job job, double ratio) {
long tmpElapsedTime;
double mapElapsedThresholdTime;
double reduceElapsedThresholdTime;
Map<TaskId, Task> slowTasks;
slowTasks = new HashMap<TaskId, Task>();
mapElapsedThresholdTime = avgMapElapsedTime * (1 + ratio);
reduceElapsedThresholdTime = avgReduceElapsedTime * (1 + ratio);
final Map<TaskId, Task> tasks = job.getTasks();
if (tasks == null) {
return slowTasks;
}
for (Task task : tasks.values()) {
tmpElapsedTime =
task.getReport().getFinishTime() - task.getReport().getStartTime();
if (task.getType() == TaskType.MAP
&& tmpElapsedTime >= mapElapsedThresholdTime) {
slowTasks.put(task.getID(), task);
} else if (task.getType() == TaskType.REDUCE
&& tmpElapsedTime >= reduceElapsedThresholdTime) {
slowTasks.put(task.getID(), task);
}
}
return slowTasks;
}...
StringBuilder jobsTableData = new StringBuilder("[\n");
for (Job j : appContext.getAllJobs().values()) {
JobId jobId = j.getID();
Job jb = appContext.getJob(jobId);
JobInfo job = new JobInfo(jb);
taskMap = null;
slowRatio = Double.parseDouble($(SLOW_TASKS_RATIO));
if($(SLOW_TASKS_TYPE).equals("elapsedtime")){
taskMap = job.getElapsedSlowTasks(jb, slowRatio);
}else if($(SLOW_TASKS_TYPE).equals("gctime")){
taskMap = job.getGcSlowTasks(jb, slowRatio);
}else if ($(SLOW_TASKS_TYPE).equals("slowstart")) {
taskMap = job.getSlowStartTasks(jb, slowRatio);
}else if ($(SLOW_TASKS_TYPE).equals("readdatalean")) {
taskMap = job.getReadDataLeanTasks(jb, slowRatio);
}else if ($(SLOW_TASKS_TYPE).equals("writedatalean")) {
taskMap = job.getWriteDataLeanTasks(jb, slowRatio);
}
...Error TaskAttempt
异常Task尝试的信息的过滤就比较简单一些,我们可以直接在前台页中进行简单判断,过滤掉状态为SUCCEED状态的记录,一般剩下的就会是KILLED和FAILED,里面会包含了note信息,这个对于帮助我们分析问题非常有用.
...
for(Entry<TaskAttemptId, TaskAttempt> ta: taskAttempts.entrySet()){
taskAttempt = ta.getValue();
if(taskAttempt.getState() == TaskAttemptState.SUCCEEDED){
continue;
}
if (type == TaskType.MAP) {
mapTime = taskAttempt.getFinishTime() - taskAttempt.getLaunchTime();
shuffleTime = 0;
mergeTime = 0;
reduceTime = 0;
} else {
mapTime = 0;
shuffleTime =
taskAttempt.getShuffleFinishTime()
- taskAttempt.getLaunchTime();
mergeTime =
taskAttempt.getSortFinishTime()
- taskAttempt.getShuffleFinishTime();
reduceTime =
taskAttempt.getFinishTime() - taskAttempt.getSortFinishTime();
}
jobsTableData.append("[\"")
.append(jobPrefixInfo)
.append(dateFormat.format(new Date(taskAttempt.getLaunchTime()))).append("\",\"")
.append(dateFormat.format(new Date(taskAttempt.getFinishTime()))).append("\",\"")
.append(taskAttempt.getID()).append("\",\"")
.append(type).append("\",\"")
.append(taskAttempt.getState()).append("\",\"")
...改造的JobHistory效果图展示
新增导航栏:
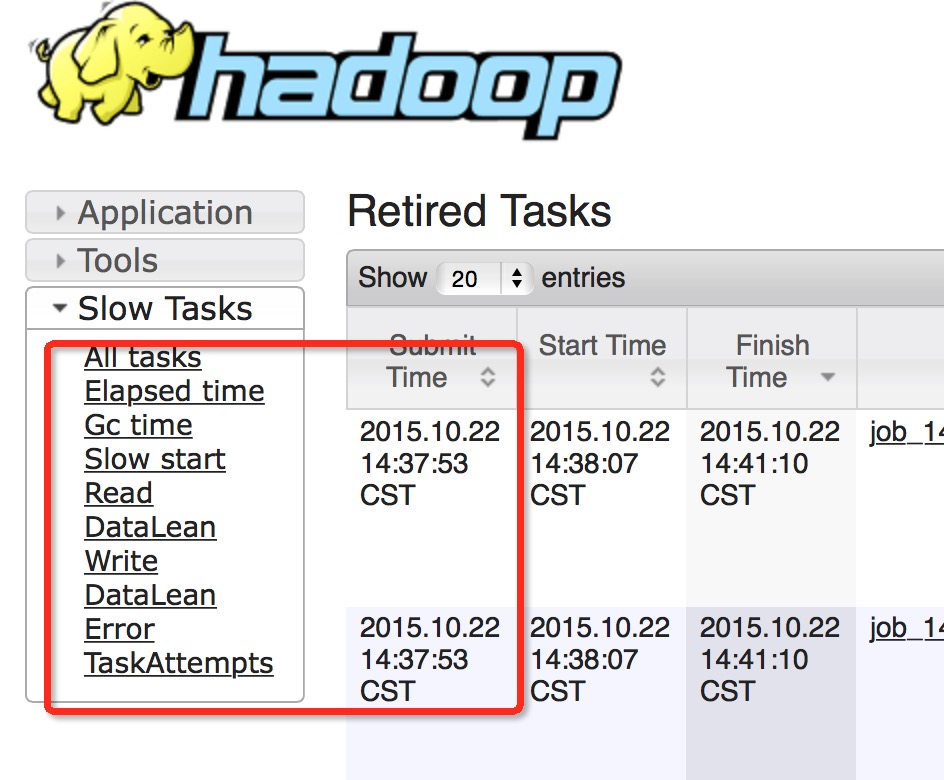
新增SlowTask执行时间等指标:
新增Error TaskAttempt任务尝试:

实现此逻辑的代码链接如下,大家可以仔细阅读这部分的代码,从如何把功能加到导航栏上再到设置链接地址,都在下面的代码链接中:
https://github.com/linyiqun/yarn-jobhistory-crawler/tree/master/slowTask

