HDFS数据加密空间--Encryption zone
前言
之前写了许多关于数据迁移的文章,也衍生的介绍了很多HDFS中相关的工具和特性,比如DistCp,ViewFileSystem等等.但是今天本文所要讲的主题转移到了另外一个领域数据安全.数据安全一直是用户非常重视的一点,所以对于数据管理者,务必要做到以下原则:
数据不丢失,不损坏,数据内容不能被非法查阅.本文所主要描述的方面就是上面原则中最后一点,保证数据不被非法查阅.在HDFS中,就有专门的功能来做这样的事情,Encryption zone,数据加密空间,
Encryption zone综述
HDFS Encryption zone加密空间是一种end-to-end(端到端)的加密模式.其中的加/解密过程对于客户端来说是完全透明的.数据在客户端读操作的时候被解密,当数据被客户端写的时候被加密,所以HDFS本身并不是一个主要的参与者,形象的说,在HDFS中,你看到的只是一堆加密的数据流.
Encryption zone原理介绍
了解HDFS数据加密空间的原理对我们使用Encryption zone有很大的帮助.Encryption zone是HDFS中的一个抽象概念,它表示在此空间的内容在写的时候会被透明的加密,同时在读的时候,被透明的解密.这就是核心所在.具体到细小的细节.
- 1.每个encryption zone 会与每个encryption zone key相关联,而这个key就是会在创建encryption zone的时候同时被指定.
- 2.每个encryption zone中的文件会有其唯一的data encryption key数据加密key,简称就是DEK.
- 3.DEK不会被HDFS直接处理,取而代之的是,HDFS只处理经过加密的DEK, 就是encrypted data encryption key,缩写就是EDEK.
- 4.客户端询问KMS服务去解密EDEK,然后利用解密后得到的DEK去读/写数据.
在第四步骤有一个很重要的过程:
在客户端向KMS服务请求时候,会有相关权限验证,不符合要求的客户端将不会得到解密好的DEK.而且KMS的权限验证是独立于HDFS的,是自身的一套权限验证.下面是对应的原理展示图:
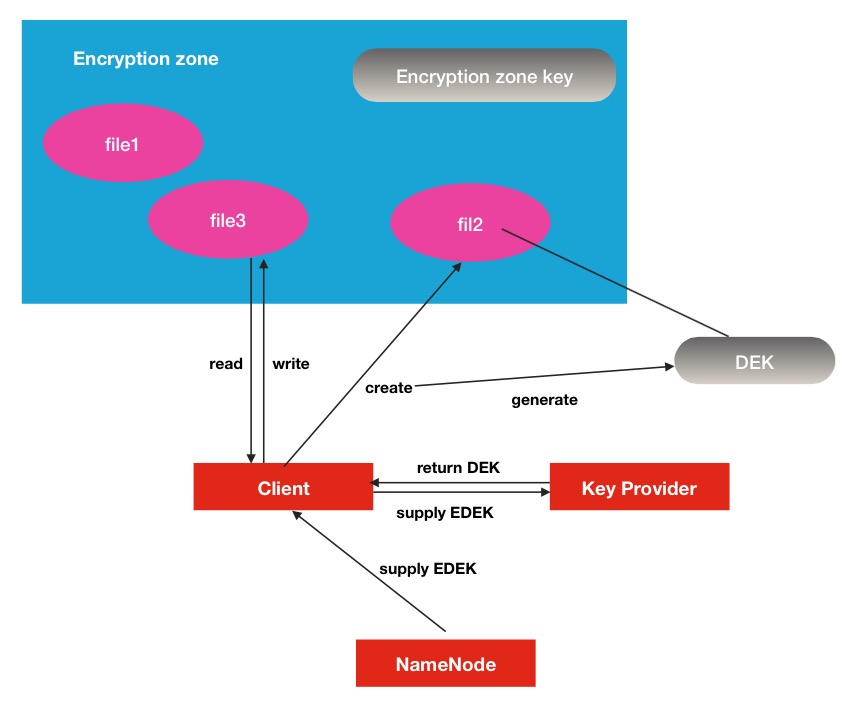
Key Provider可以理解为是一个key store的保存库,其中KMS是其中的一个实现.
Encryption zone源码实现
这个小节,我们将从源码的层面对上述原理做跟踪分析.这里可以分为2大方向,1个是创建文件,并且写文件数据;2.读文件数据内容.
Encryption zone下的写文件
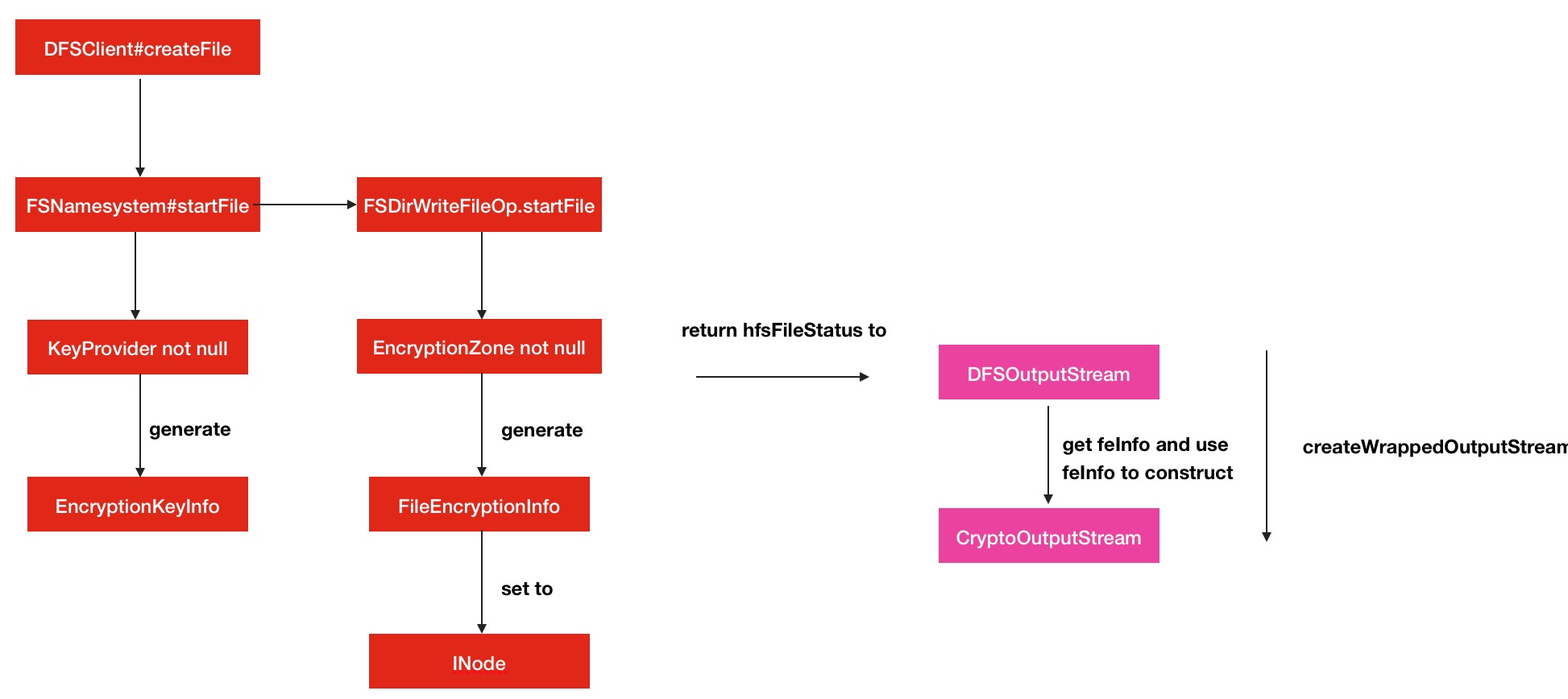
首先客户端发起createFile请求,到了NameNode这边,会调用startFile方法,里面就会有DEK,EDEK的生成
private HdfsFileStatus startFileInt(final String src,
PermissionStatus permissions, String holder, String clientMachine,
EnumSet<CreateFlag> flag, boolean createParent, short replication,
long blockSize, CryptoProtocolVersion[] supportedVersions,
boolean logRetryCache)
throws IOException {
...
FSDirWriteFileOp.EncryptionKeyInfo ezInfo = null;
// 判断key provider是否为空
if (provider != null) {
readLock();
try {
checkOperation(OperationCategory.READ);
// 不为空,就生成EncryptionKey info.
ezInfo = FSDirWriteFileOp
.getEncryptionKeyInfo(this, pc, src, supportedVersions);
} finally {
readUnlock();
}
// Generate EDEK if necessary while not holding the lock
if (ezInfo != null) {
// 然后根据ezInfo的key名称生成EDEK信息在ezInfo中
ezInfo.edek = FSDirEncryptionZoneOp
.generateEncryptedDataEncryptionKey(dir, ezInfo.ezKeyName);
}
EncryptionFaultInjector.getInstance().startFileAfterGenerateKey();
}
...
try {
// 继续调用startFile方法
stat = FSDirWriteFileOp.startFile(this, pc, src, permissions, holder,
clientMachine, flag, createParent,
replication, blockSize, ezInfo,
toRemoveBlocks, logRetryCache);
...继续方法的调用
static HdfsFileStatus startFile(
FSNamesystem fsn, FSPermissionChecker pc, String src,
PermissionStatus permissions, String holder, String clientMachine,
EnumSet<CreateFlag> flag, boolean createParent,
short replication, long blockSize,
EncryptionKeyInfo ezInfo, INode.BlocksMapUpdateInfo toRemoveBlocks,
boolean logRetryEntry)
throws IOException {
assert fsn.hasWriteLock();
...
CipherSuite suite = null;
CryptoProtocolVersion version = null;
KeyProviderCryptoExtension.EncryptedKeyVersion edek = null;
// 取出ezInfo中的关键信息
if (ezInfo != null) {
edek = ezInfo.edek;
suite = ezInfo.suite;
version = ezInfo.protocolVersion;
}
...
FileEncryptionInfo feInfo = null;
final EncryptionZone zone = FSDirEncryptionZoneOp.getEZForPath(fsd, iip);
if (zone != null) {
// The path is now within an EZ, but we're missing encryption parameters
if (suite == null || edek == null) {
throw new RetryStartFileException();
}
// Path is within an EZ and we have provided encryption parameters.
// Make sure that the generated EDEK matches the settings of the EZ.
final String ezKeyName = zone.getKeyName();
if (!ezKeyName.equals(edek.getEncryptionKeyName())) {
throw new RetryStartFileException();
}
// 传入到FileEncryptionInfo中,feInfo将会被设置到INode文件中
feInfo = new FileEncryptionInfo(suite, version,
edek.getEncryptedKeyVersion().getMaterial(),
edek.getEncryptedKeyIv(),
ezKeyName, edek.getEncryptionKeyVersionName());
}
...OK,完成了这些操作之后,将会返回一个HDFSFileStatus对象,此对象将会被DFSOutputstream利用.下面就是客户端的解密DEDK,并加密数据的过程了.
public HdfsDataOutputStream createWrappedOutputStream(DFSOutputStream dfsos,
FileSystem.Statistics statistics, long startPos) throws IOException {
// 取出文件中的加密信息
final FileEncryptionInfo feInfo = dfsos.getFileEncryptionInfo();
if (feInfo != null) {
// 文件是被加密的,需要包装数据流为加密流
// File is encrypted, wrap the stream in a crypto stream.
// Currently only one version, so no special logic based on the version #
getCryptoProtocolVersion(feInfo);
final CryptoCodec codec = getCryptoCodec(conf, feInfo);
// 解密feInfo中的EDEK的信息,其中会向KerProvider进行请求
KeyVersion decrypted = decryptEncryptedDataEncryptionKey(feInfo);
// 然后解密后的信息作为参数,构造出加密输出流
final CryptoOutputStream cryptoOut =
new CryptoOutputStream(dfsos, codec,
decrypted.getMaterial(), feInfo.getIV(), startPos);
return new HdfsDataOutputStream(cryptoOut, statistics, startPos);
} else {
// No FileEncryptionInfo present so no encryption.
return new HdfsDataOutputStream(dfsos, statistics, startPos);
}
}我们可以继续完decryptEncryptedDataEncryptionKey方法,验证是否有向KeyProvider方法请求服务.
private KeyVersion decryptEncryptedDataEncryptionKey(FileEncryptionInfo
feInfo) throws IOException {
try (TraceScope ignored = tracer.newScope("decryptEDEK")) {
// 获取keyProvider服务实例
KeyProvider provider = getKeyProvider();
if (provider == null) {
throw new IOException("No KeyProvider is configured, cannot access" +
" an encrypted file");
}
// 获取加密的key version
EncryptedKeyVersion ekv = EncryptedKeyVersion.createForDecryption(
feInfo.getKeyName(), feInfo.getEzKeyVersionName(), feInfo.getIV(),
feInfo.getEncryptedDataEncryptionKey());
try {
KeyProviderCryptoExtension cryptoProvider = KeyProviderCryptoExtension
.createKeyProviderCryptoExtension(provider);
// 进行解密操作
return cryptoProvider.decryptEncryptedKey(ekv);
} catch (GeneralSecurityException e) {
throw new IOException(e);
}
}
}构造完加密输出流对象之后CryptoOutputStream之后,在随后的写操作中,数据都会额外经过一步加密算法的操作.此部分的过程调用图如下:
Encryption zone下的读文件
读文件部分的操作与写文件非常类似.
首先是构造出目标文件的HDFSFileStatus对象,然后取出其中的FileEncryptionInfo,在此过程中FileEncryptionInfo会被设置到LocatedBlocks中.
private static HdfsLocatedFileStatus createLocatedFileStatus(
FSDirectory fsd, byte[] path, INodeAttributes nodeAttrs,
byte storagePolicy, int snapshot,
boolean isRawPath, INodesInPath iip) throws IOException {
...
// 然后设置到LocatedBlocks中
loc = fsd.getBlockManager().createLocatedBlocks(
fileNode.getBlocks(snapshot), fileSize, isUc, 0L, size, false,
inSnapshot, feInfo, ecPolicy);
...然后这些Blocks信息会以参数的信息传入到DFSInputStream,并在方法fetchLocatedBlocksAndGetLastBlockLength被设置到变量中.
private long fetchLocatedBlocksAndGetLastBlockLength(boolean refresh)
throws IOException {
LocatedBlocks newInfo = locatedBlocks;
...
// 将locatedBlocks中的EncryptionInfo信息设置到变量中
fileEncryptionInfo = locatedBlocks.getFileEncryptionInfo();
return lastBlockBeingWrittenLength;
}然后此信息同样会被取出用到加密输入流中
public HdfsDataInputStream createWrappedInputStream(DFSInputStream dfsis)
throws IOException {
// 获取文件加密信息
final FileEncryptionInfo feInfo = dfsis.getFileEncryptionInfo();
if (feInfo != null) {
// File is encrypted, wrap the stream in a crypto stream.
// Currently only one version, so no special logic based on the version #
getCryptoProtocolVersion(feInfo);
final CryptoCodec codec = getCryptoCodec(conf, feInfo);
// 解密DEDK
final KeyVersion decrypted = decryptEncryptedDataEncryptionKey(feInfo);
// 构造加密输入流
final CryptoInputStream cryptoIn =
new CryptoInputStream(dfsis, codec, decrypted.getMaterial(),
feInfo.getIV());
return new HdfsDataInputStream(cryptoIn);
} else {
// No FileEncryptionInfo so no encryption.
return new HdfsDataInputStream(dfsis);
}
}与之前的过程非常的类似,在加密输入流中,就会对读取的数据进行解密,使得用户能看到正常的数据.同样给出过程图:

Encryption zone的管理
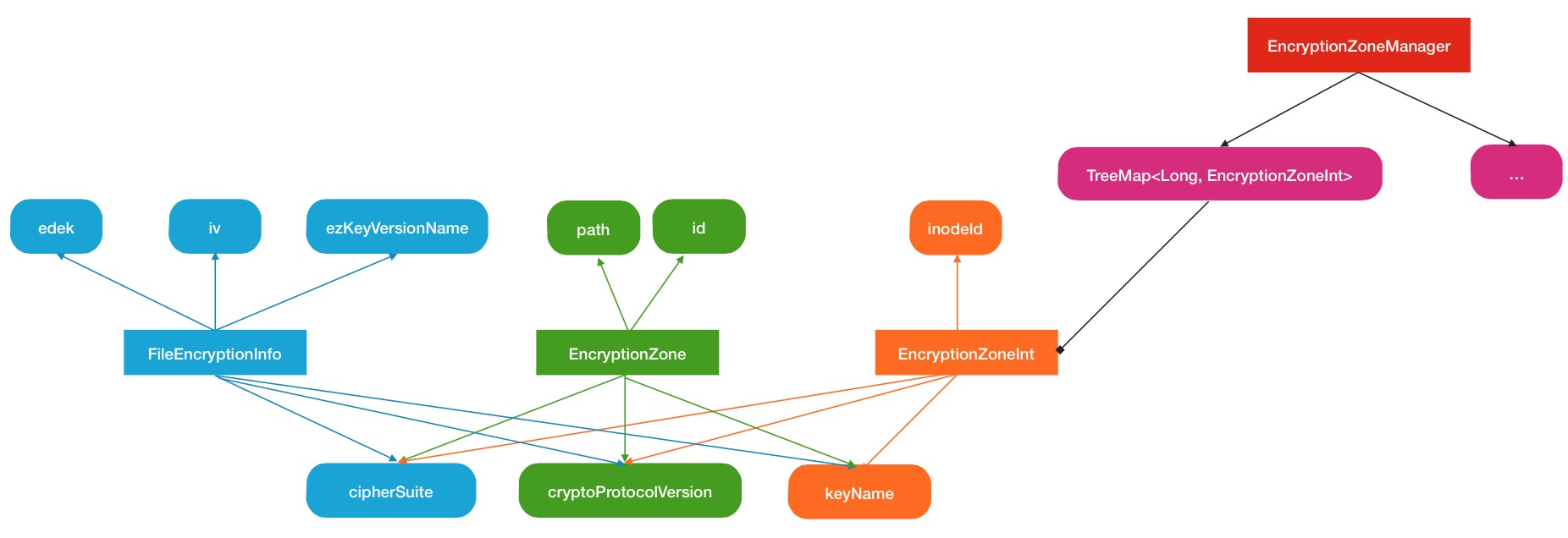
在源码分析的最后部分,这里再简单描述一下HDFS的Encryption zone的中心管理.同样是一个叫做EncryptionZoneManager的类来专门做这个事情的,但是有一点不同,他保存的对象不是EncryptionZone,而是EncryptionZoneInt.
public class EncryptionZoneManager {
public static Logger LOG = LoggerFactory.getLogger(EncryptionZoneManager
.class);
...
// 用TreeMap保存的Encryption zone列表
private final TreeMap<Long, EncryptionZoneInt> encryptionZones;
private final FSDirectory dir;
private final int maxListEncryptionZonesResponses;
...这里的TreeMap的key位置保存的encryption zone的对应目录的indeed.
EncryptionZoneInt与EncryptionZone有什么微妙的关系呢?
在具体使用的时候,EncryptionZoneInt会被用来构造EncryptionZone如下代码
EncryptionZone getEZINodeForPath(INodesInPath iip) {
final EncryptionZoneInt ezi = getEncryptionZoneForPath(iip);
if (ezi == null) {
return null;
} else {
return new EncryptionZone(ezi.getINodeId(), getFullPathName(ezi),
ezi.getSuite(), ezi.getVersion(), ezi.getKeyName());
}
}通过判断目标路径是否在encryption zone列表中,来判断此文件是否为加密文件,以为inodeId作为key去map中取出.
下面给出Encryption zone管理的结构图:
Encryption zone的使用
最后再介绍以下Encryption zone功能的具体配置使用.总的来说,住需要完成几个相关的配置项即可.
第一步: 完成keyProveider的配置
将已存在的keyProvider的URL地址配置到下面的配置中
dfs.encryption.key.provider.uri第二步: 加密算法相关的配置
主要有以下的一些配置
hadoop.security.crypto.codec.classes.EXAMPLECIPHERSUITE
hadoop.security.crypto.codec.classes.aes.ctr.nopadding
hadoop.security.crypto.cipher.suite
hadoop.security.crypto.jce.provider
hadoop.security.crypto.buffer.size当然这些配置并不需要额外配置,采用默认配置也是可以的.
第三步: 配置listZone响应回复的个数
此配置会在listZones的命令中起到作用.
dfs.namenode.list.encryption.zones.num.responses第四步: 创建Encryption zone加密空间
这里的加密空间是针对目录级别的,并且还需要设置一个key名称,使用的命令如下
hdfs crypto -createZone -keyName <keyName> -path <path>这里的path是要已经建好的目录,此命令的作用相当于将目标目录作为一个加密空间,在此目录下的文件在读写的过程中,被加/解密.
以上操作完成之后,加密空间就基本创建好了,可以用listZones的命令查看当前已创建的加密空间
hdfs crypto -listZones然后此目录文件数据的加解密过程对于客户端来说完全是透明的了.
Encryption zone使用范例
下面举出官方的使用例子
# 以普通用户的身份创建一个加密key
hadoop key create myKey
# 以超级用户的身份创建一个空目录,并使之成为加密空间
hadoop fs -mkdir /zone
hdfs crypto -createZone -keyName myKey -path /zone
# 修改此目录权限为普通用户的
hadoop fs -chown myuser:myuser /zone
# 以普通用户的身份进行put上传文件和cat查看文件操作
hadoop fs -put helloWorld /zone
hadoop fs -cat /zone/helloWorld参考链接
1.http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/TransparentEncryption.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号