HDFS的滚动升级: Rolling Upgrade
前言
目前Hadoop版本更新迭代的速度还是比较快的,每次新版本的发布,都是一件令人期待的事情.因为这意味着用户可以使用新的功能特性,又或者说在新版中某某模块性能得到了巨大提升等等.现在问题来了,如果我们想用新的Hadoop版本,那么我们必须对现有版本进行升级.在一定程度上来讲,Hadoop的升级说白了其实就是HDFS的升级,也就是数据上的升级.在传统的升级方案中,我们往往需要停止集群服务来做这样的操作.如果集群规模已经是非常大的情况下时,这样做的代价实在太高.为了解决这类的问题,HDFS在2.4.0以及以上版本中引入了Rolling Upgrade的概念,也就是滚动升级的意思.Rolling Upgrade升级方式最重要的一点是它可以保证在升级过程中集群依然可以对外提供服务.本文将会从升级原理以及实际步骤操作两方面进行相关内容的阐述.
Rolling Upgrade相关指令以及原理
在讲述Rolling Upgrade实际操作步骤之前,我们有必要事先了解其中相关的使用命令,以及这些命令的作用和原理.主要是下面这6个:
- 1.hdfs dfsadmin下的子命令
- 1.1 hdfs dfsadmin -rollingUpgrade prepare
- 1.2 hdfs dfsadmin -rollingUpgrade query
- 1.3 hdfs dfsadmin -rollingUpgrade finalize
- 2.hdfs namenode下的子命令
- 2.1 hdfs namenode -rollingUpgrade rollback
- 2.2 hdfs namenode -rollingUpgrade started
- 3.hdfs datanode下的子命令
- 3.1 hdfs datanode rollback
下面我们对上面的命令一一做分析.
hdfs dfsadmin下的升级命令
首先是hdfs dfsadmin下的3条命令,这是官方文档对这3条命令的解释:
query: Query the current rolling upgrade status.
prepare: Prepare a new rolling upgrade.
finalize : Finalize the current rolling upgrade.
可能看完官方文档的解释,我们还是会有点迷惑,没有关系,下面我们直接定位到相关代码,来深入了解其背后的操作原理.
hdfs dfsadmin的入口类为DFSAdmin,顺着此类,我们可以找到对应服务端的处理方法,在NameNodeRpcServer类中,如下:
public RollingUpgradeInfo rollingUpgrade(RollingUpgradeAction action) throws IOException {
checkNNStartup();
LOG.info("rollingUpgrade " + action);
// 不同hdfs dfsadmin -rollingUpgrade操作对应不同action处理
switch(action) {
case QUERY:
// 对应hdfs dfsadmin -rollingUpgrade query
return namesystem.queryRollingUpgrade();
case PREPARE:
// 对应hdfs dfsadmin -rollingUpgrade prepare
return namesystem.startRollingUpgrade();
case FINALIZE:
// 对应hdfs dfsadmin -rollingUpgrade finalize
return namesystem.finalizeRollingUpgrade();
default:
throw new UnsupportedActionException(action + " is not yet supported.");
}
}NameNodeRpcServer类的rollingUpgrade方法继而调用FSNamesystem的方法完成最后的操作.我们首先分析Prepare的处理逻辑,代码如下:
RollingUpgradeInfo startRollingUpgrade() throws IOException {
checkSuperuserPrivilege();
checkOperation(OperationCategory.WRITE);
writeLock();
try {
checkOperation(OperationCategory.WRITE);
// 判断是否正处于rolling upgrade状态,如果是,则返回相关信息
if (isRollingUpgrade()) {
return rollingUpgradeInfo;
}
// 如果不是,则执行rolling upgrade开始动作,分为HA和非HA模式
long startTime = now();
if (!haEnabled) { // for non-HA, we require NN to be in safemode
startRollingUpgradeInternalForNonHA(startTime);
} else { // for HA, NN cannot be in safemode
checkNameNodeSafeMode("Failed to start rolling upgrade");
startRollingUpgradeInternal(startTime);
}
// 执行editlog相关记录操作
getEditLog().logStartRollingUpgrade(rollingUpgradeInfo.getStartTime());
if (haEnabled) {
// roll the edit log to make sure the standby NameNode can tail
getFSImage().rollEditLog();
}
} finally {
writeUnlock();
}
...
// 返回升级对象信息
return rollingUpgradeInfo;
}在startRollingUpgrade执行方法中,主要创建了将来用于rollback的镜像文件,但是在实现方式上,HA与非HA模式并不完全相同,以非HA模式为例:
private void startRollingUpgradeInternalForNonHA(long startTime)
throws IOException {
Preconditions.checkState(!haEnabled);
if (!isInSafeMode()) {
throw new IOException("Safe mode should be turned ON "
+ "in order to create namespace image.");
}
checkRollingUpgrade("start rolling upgrade");
getFSImage().checkUpgrade();
// 做一次checkpoint,生成一个新的用于rollback的镜像
// in non-HA setup, we do an extra checkpoint to generate a rollback image
getFSImage().saveNamespace(this, NameNodeFile.IMAGE_ROLLBACK, null);
LOG.info("Successfully saved namespace for preparing rolling upgrade.");
// 离开安全模式,并设置启动rolling upgrade启动时间和创建镜像标识
// leave SafeMode automatically
setSafeMode(SafeModeAction.SAFEMODE_LEAVE);
setRollingUpgradeInfo(true, startTime);
}以上非HA模式的操作非常直观,直接创建rollback镜像,这时我们来看HA模式将执行的startRollingUpgradeInternal方法:
void startRollingUpgradeInternal(long startTime)
throws IOException {
checkRollingUpgrade("start rolling upgrade");
getFSImage().checkUpgrade();
setRollingUpgradeInfo(false, startTime);
}这时我们可能就比较疑惑了,此时并没有创建新fsimage的方法,本人在刚开始阅读的时候,也感到比较疑惑,后来通过追踪创建fsimage的动作方法最终明白了其中十分隐蔽的原理.下面是非HA模式下创建rollback镜像的原理过程:
1.startRollingUpgradeInternal的确是不会创建快照,但是在执行完startRollingUpgradeInternal方法后,还会执行关键的一步操作:
getEditLog().logStartRollingUpgrade(rollingUpgradeInfo.getStartTime());2.此操作会触发needRollbackFsImage标识的改变,代码如下(请留意此方法的注释说明),位于FSNamesystem类:
/**
* Called when the NN is in Standby state and the editlog tailer tails the
* OP_ROLLING_UPGRADE_START.
*/
void triggerRollbackCheckpoint() {
setNeedRollbackFsImage(true);
if (standbyCheckpointer != null) {
standbyCheckpointer.triggerRollbackCheckpoint();
}
}3.此标识继而在StandbyCheckpointer的doWork方法中被调用,代码如下:
private void doWork() {
final long checkPeriod = 1000 * checkpointConf.getCheckPeriod();
// Reset checkpoint time so that we don't always checkpoint
// on startup.
lastCheckpointTime = monotonicNow();
while (shouldRun) {
boolean needRollbackCheckpoint = namesystem.isNeedRollbackFsImage();
...
// 通过needCheckpoint标识判断是否需要进行checkpoint操作
if (needCheckpoint) {
doCheckpoint();
// reset needRollbackCheckpoint to false only when we finish a ckpt
// for rollback image
if (needRollbackCheckpoint
&& namesystem.getFSImage().hasRollbackFSImage()) {
namesystem.setCreatedRollbackImages(true);
namesystem.setNeedRollbackFsImage(false);
}
lastCheckpointTime = now;
...4.最后在doCheckpoint方法中我们终于找到了另外一处创建rollback镜像的操作,
private void doCheckpoint() throws InterruptedException, IOException {
assert canceler != null;
final long txid;
final NameNodeFile imageType;
...
// 如果正处于rollUpgrade状态,并且没有创建rollback镜像
if (namesystem.isRollingUpgrade()
&& !namesystem.getFSImage().hasRollbackFSImage()) {
// if we will do rolling upgrade but have not created the rollback image
// yet, name this checkpoint as fsimage_rollback
imageType = NameNodeFile.IMAGE_ROLLBACK;
} else {
imageType = NameNodeFile.IMAGE;
}
...OK,执行完startRollingUpgrade操作,表明HDFS已处于rolling upgrade状态了.
接着是query命令,query命令查询的主要目的是NameNode是否已经创建完rollback的镜像文件.代码如下:
RollingUpgradeInfo queryRollingUpgrade() throws IOException {
checkSuperuserPrivilege();
checkOperation(OperationCategory.READ);
readLock();
try {
// 如果rollingUpgrade信息不为空
if (rollingUpgradeInfo != null) {
// 判断是否已经存在rollback的镜像文件,并设置入rollingUpgrade信息中
boolean hasRollbackImage = this.getFSImage().hasRollbackFSImage();
rollingUpgradeInfo.setCreatedRollbackImages(hasRollbackImage);
}
// 返回更新过后的rollingUpgradeInfo
return rollingUpgradeInfo;
} finally {
readUnlock();
}
}最后一个命令是finalize,finalize做的是最终升级确认的事情,此命令的执行意味着Rolling Upgrade过程彻底完成,相关代码如下:
RollingUpgradeInfo finalizeRollingUpgrade() throws IOException {
checkSuperuserPrivilege();
checkOperation(OperationCategory.WRITE);
writeLock();
final RollingUpgradeInfo returnInfo;
try {
checkOperation(OperationCategory.WRITE);
if (!isRollingUpgrade()) {
return null;
}
...
if (haEnabled) {
// roll the edit log to make sure the standby NameNode can tail
getFSImage().rollEditLog();
}
getFSImage().updateStorageVersion();
// 将之前建的用于rollback的镜像文件重命名为当前的镜像
getFSImage().renameCheckpoint(NameNodeFile.IMAGE_ROLLBACK,
NameNodeFile.IMAGE);
} finally {
writeUnlock();
}
...
return returnInfo;
}从上面的代码中,我们可以看出finalize动作主要是将rollback镜像重命名为当前fsimage.
综合上述3个命令的调用过程,我们可以看到基本是围绕着rollback fsimage做相关的操作,过程调用简图如下:
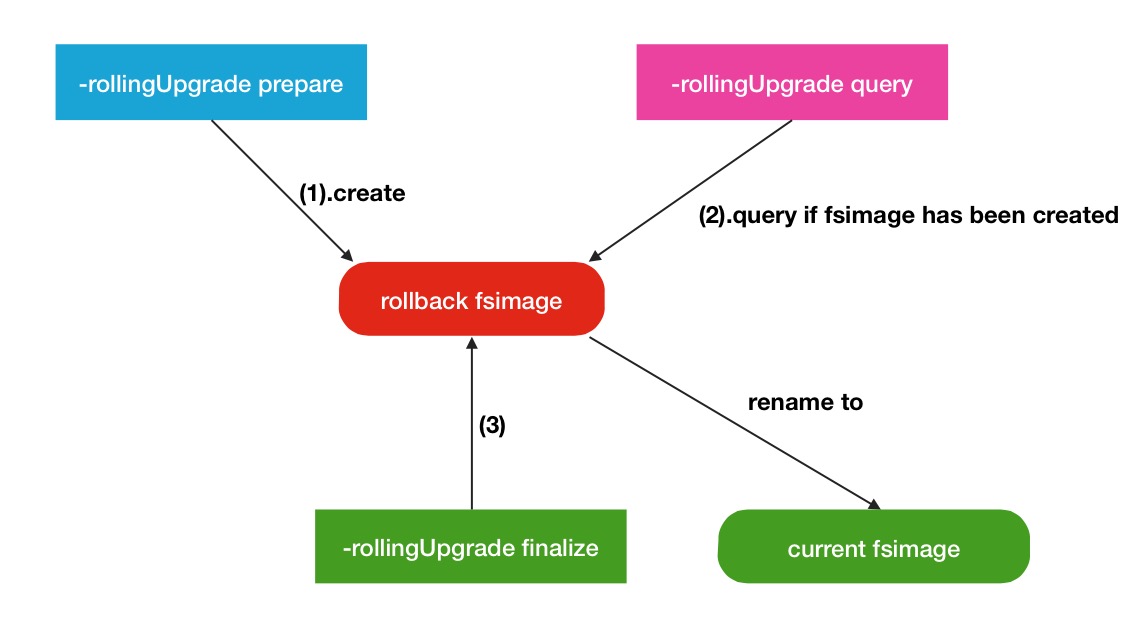
hdfs namenode下的子命令
hdfs namenode -rollingUpgrade rollback或started命令的本质是NameNode启动控制相关指令.我们输入hdfs namenode -help命令可以看到全部的startup option:
$ hdfs namenode -help
Usage: java NameNode [-backup] |
[-checkpoint] |
[-format [-clusterid cid ] [-force] [-nonInteractive] ] |
[-upgrade [-clusterid cid] [-renameReserved<k-v pairs>] ] |
[-upgradeOnly [-clusterid cid] [-renameReserved<k-v pairs>] ] |
[-rollback] |
[-rollingUpgrade <rollback|downgrade|started> ] |
[-finalize] |
[-importCheckpoint] |
[-initializeSharedEdits] |
[-bootstrapStandby] |
[-recover [ -force] ] |
[-metadataVersion ] ]我们输入的额外参数将会被解析到StartupOption内,rollback和started将分别对应到枚举值RollingUpgradeStartupOption.ROLLBACK和RollingUpgradeStartupOption.STARTED.那么这2个参数到底会如何影响NameNode的启动逻辑呢?这才是我们最关心的内容.
通过寻找枚举值RollingUpgradeStartupOption.STARTED的调用方,我们可以找到其中一处调用场景:
private void updateStorageVersionForRollingUpgrade(final long layoutVersion,
StartupOption startOpt) throws IOException {
// 判断是否为rolling upgrade方式的启动
boolean rollingStarted = RollingUpgradeStartupOption.STARTED
.matches(startOpt) && layoutVersion > HdfsConstants
.NAMENODE_LAYOUT_VERSION;
boolean rollingRollback = RollingUpgradeStartupOption.ROLLBACK
.matches(startOpt);
// 对fsImage所在存储目录更新版本
if (rollingRollback || rollingStarted) {
fsImage.updateStorageVersion();
}
}上述方法将在loadFSImage方法中被调用,同理我们可以找到rollback启动参数对应的处理逻辑,代码如下:
private boolean loadFSImage(FSNamesystem target, StartupOption startOpt,
MetaRecoveryContext recovery)
throws IOException {
final boolean rollingRollback
= RollingUpgradeStartupOption.ROLLBACK.matches(startOpt);
final EnumSet<NameNodeFile> nnfs;
// 判断是否为rollback方式的启动,如果是,则从rollback镜像中加载
if (rollingRollback) {
// if it is rollback of rolling upgrade, only load from the rollback image
nnfs = EnumSet.of(NameNodeFile.IMAGE_ROLLBACK);
} else {
// otherwise we can load from both IMAGE and IMAGE_ROLLBACK
nnfs = EnumSet.of(NameNodeFile.IMAGE, NameNodeFile.IMAGE_ROLLBACK);
}
final FSImageStorageInspector inspector = storage
.readAndInspectDirs(nnfs, startOpt);
...后面还有rollback情况下对应的editlog的处理逻辑,感兴趣的同学可自行研究学习.
hdfs datanode下的子命令
最后一个相关命令是hdfs datanode的启动命令,我们同样输入hdfs datanode -h来查看其可选参数.
$ hdfs datanode -h
Usage: java DataNode [-regular | -rollback]
-regular : Normal DataNode startup (default).
-rollback : Rollback a standard or rolling upgrade.
Refer to HDFS documentation for the difference between standard
and rolling upgrades.这里主要关注rollback参数,因为regular其实就是我们平常正常启动的默认参数.启动DataNode之后,依次经过initStorage,initBlockPool等方法,最终调用到下面的doTransition方法,在这个方法内部,我们可以看到此参数控制的逻辑代码:
private void doTransition( DataNode datanode,
StorageDirectory sd,
NamespaceInfo nsInfo,
StartupOption startOpt
) throws IOException {
// 判断DataNode是否为rollback方式的启动
if (startOpt == StartupOption.ROLLBACK) {
doRollback(sd, nsInfo); // rollback if applicable
}
readProperties(sd);
checkVersionUpgradable(this.layoutVersion);
assert this.layoutVersion >= HdfsConstants.DATANODE_LAYOUT_VERSION :
"Future version is not allowed";
...进入doRollback方法:
void doRollback( StorageDirectory sd,
NamespaceInfo nsInfo
) throws IOException {
File prevDir = sd.getPreviousDir();
// This is a regular startup or a post-federation rollback
...
File tmpDir = sd.getRemovedTmp();
assert !tmpDir.exists() : "removed.tmp directory must not exist.";
// rename current to tmp
File curDir = sd.getCurrentDir();
assert curDir.exists() : "Current directory must exist.";
rename(curDir, tmpDir);
// rename previous to current
rename(prevDir, curDir);
// delete tmp dir
deleteDir(tmpDir);
LOG.info("Rollback of " + sd.getRoot() + " is complete");
}在doRollback方法中,主要做了以下3个关于rollback的步骤:
- 1.重命名目录current到removed.tmp.
- 2.重命名目录previous到current.
- 3.删除目录remove.tmp.
在上面的操作中有一点需要注意:
在DataNode的doRollback操作中,并不会涉及到真实数据的保存/恢复等操作,其间只是文件目录链接指向的修改.
HDFS Rolling Upgrade实际操作
下半部分我们将重点关注HDFS Rolling Upgrade部分的操作.HDFS Rolling Upgrade部分的操作并不是就几条命令的事情,它还要考虑集群是否是HA配置的,HA里又分为是否为federated cluster和非federated cluster.我们知道在federated cluster会存在多个namespace的,也就是说在集群中会有多对Active-Standby NameNode.这种情况下,我们应该怎么升级?答案将在后面的内容中揭晓.
说到HDFS的Rolling Upgrade实际操作,如果只有Upgrade的操作,当然不能算是完整的,还应该有Downgrade和Rollback的对应操作.综合这3类操作,才能算是一个系统的Rolling Upgrade方案.下面将会根据集群类型(HA或非HA等)以及升级模块(Upgrade或Downgrade等)进行详细的操作步骤阐述.
Upgrade操作
在HDFS的升级操作过程之前,需要留意部分功能属性的开启/关闭的变更.因为可能部分功能属性在新的发布版本中是默认被开启了,直接由老版本升级后可能会造成功能的不可用,对于这种情况,比较稳妥的做法如下:
1.先关闭此功能
2.执行升级过程
3.重新启用此功能
根据集群类型,我们可以将Upgrade过程分为如下几类:
- HA类型
- Federated Clusters
- Non-Federated Clusters
- Non-HA类型
后面Downgrade和Rollingback过程的分类同上.
Upgrade for Non-Federated Clusters
Non-Federated Clusters的意思就是普通HA模式的集群,一个Active NameNode,一个Standby NameNode.下面是主要的升级步骤:
- 1.Rolling Upgrade前期准备操作
- 1.1 执行hdfs dfsadmin -rollingUpgrade prepare命令,此命令将会创建一个新的fsImage文件用于rollback.
- 1.2 执行hdfs dfsadmin -rollingUpgrade query检查rollback镜像文件是否已经创建完毕,如果出现了”Proceed with rolling upgrade”这样的提示则表明上一步prepare步骤操作完成.
- 2.升级Active/Standby的NameNode,暂且称之为NN1(Active),NN2(Standby).
- 2.1 Shutdown NN2,准备升级NN2.
- 2.2 执行-rollingUpgrade started命令启动NN2,使之成为Standby节点.
- 2.3 做一次failover切换,使得NN2成为Active节点,NN1变为Standby节点.
- 2.4 Shutdown NN1节点.
- 2.5 在NN1节点上同样执行-rollingUpgrade started,使之成为Standby节点.
- 3.升级集群DataNode节点
- 3.1 选择少部分DataNode节点(你可以按照DataNode所在的不同机架来筛选).
- 3.1.1 执行hdfs dfsadmin -shutdownDatanode upgrade命令停止选中的DataNode节点,如果你没有额外设置DataNode的IPC_PORT端口的话,则为默认值50020.
- 3.1.2 执行hdfs dfsadmin -getDatanodeInfo 命令检查目标命令下线DataNode是否已经停止服务.如果通过这个命令,你还是能得到节点信息,意味着此节点还未真正被关闭.
- 3.1.3 升级并重启上步骤中停止的DataNode,这里的升级意味着你需要在节点上用新版本的安装包替换掉老的.
- 3.1.4 重复以上步骤,直到将选中集合中剩余的DataNode节点都升级完毕,如果此部分节点规模足够大的话,我们最好采用并行的方式执行.
- 3.2 在集群剩余其他节点执行3.1步骤所述操作,直到集群中所有节点都执行完upgrade操作.
- 3.1 选择少部分DataNode节点(你可以按照DataNode所在的不同机架来筛选).
- 4.Rolling Upgrade操作完成的确认
- 4.1 执行hdfs dfsadmin -rollingUpgrade finalize来确认此次Rolling Upgrade的过程.一旦执行finalize动作,意味着将不允许rollback.
Upgrade for Federated Clusters
Federated Clusters是拥有多namespace的集群.每个namespace对应一对主备NameNode节点.每个NameNode掌握着一部分的元数据信息.Federated Clusters的升级过程与非Federated Clusters的升级过程比较相似,升级步骤如下:
- 1.执行-rollingUpgrade prepare命令在每个namespace下.
- 2.升级每个namespace下的Active/Standby节点,过程同上.
- 3.升级每个DataNode节点,过程同上.
- 4.升级过程执行完毕,在每个namespace下执行finalize确认命令.
上述过程其实与非Federated Clusters的升级过程没有什么本质区别,只是需要为不同的namespace多重复执行几遍升级操作.
Upgrade for Non-HA Clusters
前面2类都是HA模式下的升级过程,那么非HA模式下的升级过程又是怎样的呢?首先它会有一个明显的不同点:
在升级的过程中,势必会存在服务短暂停止的时间,因为NameNode需要重启,而这段时间并没有备用节点可选.
当然DataNode还是可以一个个升级的.非HA模式的结构与HA模式相比还是有比较大的区别,首先它不再是Active/Standby结构,取而代之的是一个NameNode(NN),一个SecondaryNameNode(SNN).在这里SNN的角色并不是备份节点的意思.非HA模式的升级步骤如下(整体过程同上述普通HA模式的4个步骤,不过上述步骤二的过程要略微修改):
- 升级NN和SNN
- 1.停止SNN
- 2.停止并升级NN
- 3.执行-rollingUpgrade started命令启动NN
- 4.升级并重启SNN
Downgrade操作
当我们在升级的过程中发现了一些异常,或者说我们觉得升级后的版本并不是我们预期所想要的情况下时,我们可以选择downgrade(降级)或rollback(回滚).这2个操作可能有人会觉得二者意思比较接近,下面列出其中几个异同点:
共同点:
- 1.都会将版本退回到升级前的版本
- 2.在Upgrade的finalize动作执行之后,将不允许再执行downgrade和rollback.
不同点:
- 1.Downgrade能支持rollling的方式,可以滚动降级,而rollback需要停止服务一段时间.
- 2.Downgrade过程只会将软件版本还原成升级前的,会保留用户现有的数据状态,而rollback则还会将用户数据还原成升级前的状态模式.
在HDFS升级操作过后,并不是所有新版本都是可降级的,如果在新旧版本中NameNode或DataNode的layout version不一致,则downgrade操作将会失败.下面是HA模式下的downgrade降级步骤:
1.Downgrade降级DataNode
- 1.1 选中部分集合DataNode节点(可以按照机架进行区分)
- 1.1.1 执行hdfs dfsadmin -shutdownDatanode upgrade命令停止其中一个选中的节点.
- 1.1.2 执行hdfs dfsadmin -getDatanodeInfo 命令检查节点是否完全停止.
- 1.1.3 降级并重启DataNode.
- 1.1.4 在选中集合内的其他DataNode节点上重复执行上述操作.
- 1.2 在集群中所有的DataNode节点上重复执行1.1的操作.
- 1.1 选中部分集合DataNode节点(可以按照机架进行区分)
2.Downgrade降级Active NameNode和Standby NameNode
- 2.1 停止并降级NN2.
- 2.2 正常启动NN2,使之为Standby节点.
- 2.3 触发failover切换,使得NN2为Active节点,NN1为Standby节点.
- 2.3 停止并降级NN1.
- 2.4 正常启动NN1,作为Standby节点.
3.Downgrade降级操作的确认
- 3.1 执行hdfs dfsadmin -rollingUpgrade finalize命令进行downgrade操作完毕的确认.
Downgrade与Upgrade在HA模式下操作有一个共同点:
在操作NameNode时,都是先从Standby节点开始操作,等Standby节点升/降结束,做一次切换,使另外一个节点得以进行升/降操作.在全程中,始终保持一个Active节点对外提供服务.
但是如果我们仔细观察Downgrade的过程,我们可以发现其中NameNode与DataNode的操作步骤被颠倒了一下.在Downgrade操作时,变成了Downgrade DN在前,Downloadgrade NN在后,这样的操作步骤是有必要的吗?背后的原因是什么呢?答案如下:
新的软件版本发布一般在协议,API是兼容老版本的,如果先降级NN,那么则会造成DN是新版,NN是旧版,新版DN中的许多协议将会在旧版NN中可能不兼容.
所以这里必须要先降级客户端的DN,然后再把服务端NN进行降级.看似简单的一次顺序颠倒,背后其实是有更深层的原因的.Federated Cluster和非HA模式下的降级操作与升级操作相对应,照着上面HA模式的downgrade步骤,进行相应操作命令的替换即可.
Rollback
最后一部分的操作是rollback回滚操作.在前小节讲述downgrade部分内容的时候已经提到过rollback比较特殊的2点:
- Rollback不支持滚动操作的方式,在操作期间,它需要集群对外停止提供服务.
- Rollback操作不仅会将软件版本退回到升级前的版本,还会将用户数据退回到升级前的状态.
以下是rollback操作步骤:
- 1.停止所有的NameNode和DataNode节点.
- 2.在所有的节点机器上恢复升级前的软件版本.
- 3.在NN1节点上执行-rollingUpgrade rollback命令来启动NN1,将NN1作为Active节点.
- 4.在NN2上执行-bootstrapStandby命令并正常启动NN2,将NN2作为Standby节点.
- 5.以-rollback参数启动所有的DataNode.
以上就是本文所要讲述的HDFS Rolling Upgrade滚动升级的全部内容了,大家可以与传统的升级方案做对比,体会二者之间细微的差异.
参考资料
1.http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsRollingUpgrade.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号