


HDFS自定义小文件分析功能
前言
看完本文的标题,可能有读者会心想:HDFS为什么会与小文件分析挂钩呢?Hadoop的设计初衷不是偏向于存储单位体量规模较大的文件的吗?设计这样的功能有什么实际用途呢?这背后其实是有很多内容可以讲的,说起HDFS中的小文件,我们并不是关心它到底有多小,而是在于它太多.而文件太多的原因往往在于其外部程序写入单个文件的量太小导致,在同样规模待写入数据量的前提下,单位文件过小显然会造成大批量的小文件产生.可能很多人会不以为然,认为小文件多了,但是它的总体数据量还是维持平稳,所以对HDFS影响就不大了.在这个分析过程中,我们往往会忽视小文件带来的间接影响:元数据规模的增多.这直接将会加重NameNode的负载.因为这会使得NameNode需要跟踪这些块并且要将这些文件块的元信息存放在自己的内存中.所以在这里引出了本文的主题:通过改造HDFS小文件分析功能,来处理集群中的小文件,然后达到最终减轻NameNode负载的目标.
背景知识
在讲解自定义小文件分析功能之前,我们有必要对现有HDFS的一些相关内容进行了解,主要包括以下4点:
- NameNode的元数据存放
- NameNode内存过大的影响
- 现有NameNode内存过大解决方案
- HDFS现有文件分析功能
NameNode的元数据存放
很多Hadoop的使用者在日常使用集群的时候往往对写入的文件缺乏管理,造成很多的小文件,有的甚至就是十几字节一个文件.这使HDFS完全被用成了小文件系统,从而难以发挥它本身的优势.这些庞大的元数据信息,我们如何能够查看到呢,近一步的说,我们如何能够查看到这些元数据信息占到NameNode内存的比例值呢?这里教给大家一个简单的方法,直接是java提供的jmap命令,命令如下:
jmap -histo:live <进程ID> | less //堆中活动的对象以及大小 此处进程ID填入NameNode进程ID即可.(大家如果要试的话,建议在Standby NameNode上执行,因为如果NameNode内存过大,jmap一次的时间会比较长,对其进程服务本身会造成影响).下面是我在测试集群上的执行结果:
num #instances #bytes class name
----------------------------------------------
1: xxxx xxxx org.apache.hadoop.hdfs.server.namenode.INodeFile
2: xxxx xxxx [Ljava.lang.Object;
3: xxxx xxxx org.apache.hadoop.hdfs.server.blockmanagement.BlockInfoContiguous
4: xxxx xxxx [B
5: xxxx xxxx [Lorg.apache.hadoop.hdfs.server.blockmanagement.BlockInfoContiguous;
6: xxxx xxxx [Lorg.apache.hadoop.util.LightWeightGSet$LinkedElement;
7: xxxx xxxx org.apache.hadoop.hdfs.server.namenode.INodeDirectory
8: xxxx xxxx java.util.ArrayList
9: xxxx xxxx org.apache.hadoop.hdfs.protocol.HdfsFileStatus
10: xxxx xxxx org.apache.hadoop.ipc.RetryCache$CacheEntryWithPayload
11: xxxx xxxx <constMethodKlass>我们主要关注上面类对象的排序,具体的值大家可以自己在集群中做测试,基本是INodeFile是最多的,如果你有千万级别的文件在集群中,那么这个对象的instances值也将会达到千万级别.紧着着的是BlockInfoContiguous,这个对象类也非常的多,因为它要保存相邻副本块的位置等信息,具体的说就是它的内部会保存当前副本块的上一副本和下一副本的详细信息.当然我们在这里还看到了INodeDirectory对象,这个对应的就是目录的元信息了.最后在这里,我想纠正很多人可能对HDFS内存元数据的一个误解:
很多人可能就觉得在HDFS上新加一个文件,对于NameNode而言,就是增加几k文件元信息的事情,所以加个100w个什么的不会有很大问题,但是我们只看到了表象数据的增加,它潜在相关联对象的数据信息往往被我们忽略了,比如BlockInfoContiguous对象.
NameNode内存过大的影响
NameNode元数据过多会造成它的使用内存过大,而NameNode的内存过大将会很容易引发它的gc操作,从而进一步影响整个集群文件处理的响应速度.尤其在同时请求大规模文件量时,有时你可能会发现NameNode的响应速度非常的慢.
现有NameNode内存过大解决方案
如果NameNode内存已经达到了一个很大的值的情况下时,我们有什么现有的解决方案呢?答案是有的.如下:
用HDFS Federation来做,用多namespace来分担单个NameNode存储元数据的压力
而HDFS Federation的一个简单实现方案可以用ViewFs来做,viewFs相关内容可查看我的另外一篇文章HDFS跨集群数据合并方案之ViewFileSystem.但是话又说回来,如果我们不加以处理小文件这个源头性的问题的话,再多的namespace也没用,NameNode的内存还是会继续迅速增长的,最后又会达到一个瓶颈点.
HDFS现有文件分析功能
在现有HDFS文件分析功能中并不存在小文件分析功能,目前与小文件分析功能最最接近的是hdfs oiv命令下的FileDistribution处理器的功能.你可以理解为是文件分类器功能.它的原理如下:
通过离线分析NameNode的fsimage文件,将解析后的文件按照大小区间进行分类计数统计,然后将统计结果进行输出.
区间的范围和数量是根据用户传入的maxSize文件最大值以及step每个区间的范围大小值所决定的.比如说我们设置maxSize为10m,step为2m,那么划分出的区间将分为5+1份,+1是因为要把0-0多算作一份,区间分别为0-0,0-2,2-4,依次到8-10,超过10m的都算在最后一个区间内,也就是8-10m.在hdfs oiv命令下还有其他别的参数命令,大家可以进行实践使用,因为是离线分析镜像文件,所以不会对线上的NameNode造成任何影响.因为FileDistribution处理器的功能与我们想要的小文件分析功能最贴近,所以我们可以在此命令实现的基础上,进行改造.至于小文件功能如何改造,我们继续看后面的内容.
HDFS小文件分析功能原理设计
这一小节我们来聊聊小文件分析功能的原理设计,我们要以怎样的方式去实现它呢?首先我们要很明确一个原则:
小文件分析功能只是分析,重在分析,并不是处理,分析的结果将帮助于后续的处理.
因为分析出的小文件毕竟是HDFS现有的业务数据文件,直接进行处理显然不是一个合理的做法,分析的结果是用来帮助做后续的改进以及优化的.所以在这次的改造功能中,我们只需要输出我们认为是小文件的信息即可.但是我们还要想清楚里面的一些细节,比如以下几点:
- 1.我们如何保证改造后的功能不会影响到其命令原本的功能?
- 2.我们如何定义小文件的标准,多少范围大小的文件才是我们认为的小文件?
- 3.我们是否可以只统计我们想要路径下的小文件数,而不是说全盘的扫描?
下面我结合自己后来的实现,对此进行一一的阐述:
首先是第一点,我们可以通过添加参数的形式来保证原来的功能,我在FileDistribution处理器参数下新增-printSmallFiles参数代表用户想额外执行小文件分析功能.
第二点,我们可以将除零区间包括零区间以外的第一个区间也就是最小区间内的文件定义为小文件,比如我们定义step为1m,则0-1m大小区间内(包括文件大小为0)的文件我们认为就是小文件,然后我们输出这些文件信息即可.
第三点,指定路径分析的功能,这个我们可以在内部分析统计的时候做文件路径匹配的操作,如果当前分析文件的路径不匹配于命令参数所指定的路径,则直接跳过.在后面的实现中,我以-prefixPath参数作为待匹配的路径参数,后面可接一个或多个待分析的路径,以逗号隔开.
HDFS小文件分析功能实现
如果你已经完全理解上节中的设计原理,那么后面代码实现的部分将会看起来非常简单,这里我做一个简单的介绍,在文章最后会给出基于hadoop-2.7.1的patch以及完整的.java文件代码.
初始化部分
首先是我们新加的2个参数的解析,在OfflineImageViewerPB类中,先添加2个新参数的定义:
private static Options buildOptions() {
Options options = new Options();
...
options.addOption("maxSize", true, "");
options.addOption("step", true, "");
// 新增2个参数的定义,后续才能解析的到
options.addOption("prefixPath", true, "");
options.addOption("printSmallFiles", false, "");
options.addOption("addr", true, "");
...
return options;
}然后是命令参数的解析:
public static int run(String[] args) throws Exception {
Options options = buildOptions();
...
Configuration conf = new Configuration();
try (PrintStream out = outputFile.equals("-") ?
System.out : new PrintStream(outputFile, "UTF-8")) {
switch (processor) {
case "FileDistribution":
long maxSize = Long.parseLong(cmd.getOptionValue("maxSize", "0"));
int step = Integer.parseInt(cmd.getOptionValue("step", "0"));
// 新增参数的解析,并将其传入计算器对象内
String prefixPath = cmd.getOptionValue("prefixPath", "");
boolean printSmallFiles = cmd.hasOption("printSmallFiles");
out.println("MaxSize " + maxSize + ", Step: " + step
+ ", PrintSmallFiles: " + printSmallFiles + ", PrefixPath: "
+ prefixPath);
new FileDistributionCalculator(conf, maxSize, step, out,
printSmallFiles, prefixPath).visit(new RandomAccessFile(inputFile,
"r"));
break;
...接着,我们进入FileDistributionCalculator类的内部,在此对象中,我添加了以下几个新的变量:
final class FileDistributionCalculator {
private final static long MAX_SIZE_DEFAULT = 0x2000000000L; // 1/8 TB = 2^37
private final static int INTERVAL_DEFAULT = 0x200000; // 2 MB = 2^21
private final static int MAX_INTERVALS = 0x8000000; // 128 M = 2^27
...
// Whether print small file infos
// 是否输出小文件信息标志符
private boolean printSmallFiles;
// 目标匹配字符列表
private String[] prefixStrs;
// 小文件信息计数对信息
private HashMap<String, Integer> smallFilesMap;
// 元数据内存存储信息对象
private InMemoryMetadataDB metadataMap = null;
...然后在其构造方法中对以上变量进行了赋值:
FileDistributionCalculator(Configuration conf, long maxSize, int steps,
PrintStream out, boolean printSmallFiles, String prefixPath) {
this.conf = conf;
this.maxSize = maxSize == 0 ? MAX_SIZE_DEFAULT : maxSize;
...
this.printSmallFiles = printSmallFiles;
this.smallFilesMap = new HashMap<String, Integer>();
if (this.prefixPath != null && this.prefixPath.length() > 0) {
out.println("PrefixPath: " + this.prefixPath);
this.prefixStrs = this.prefixPath.split(",");
out.println("prefixStrs: " + prefixStrs);
}
if (this.printSmallFiles) {
this.metadataMap = new InMemoryMetadataDB();
}
}Fsimage解析过程改造
在现有hdfs oiv的FileDistribution解析镜像过程中,只解析到具体文件的相关信息,并没有其所属父目录信息,也就是说,我们将得不到文件全路径的信息,所以我们要对此进行小幅度的改造.
通过参考FsImage完全解析的过程,我添加了下面目录相关信息的解析代码,并保存在内存对象中(此过程会额外加长镜像文件的解析时间):
void visit(RandomAccessFile file) throws IOException {
if (!FSImageUtil.checkFileFormat(file)) {
throw new IOException("Unrecognized FSImage");
}
FileSummary summary = FSImageUtil.loadSummary(file);
try (FileInputStream in = new FileInputStream(file.getFD())) {
// 新添加的解析代码,解析目录相关信息,如果没有传入分析小文件功能标识,则此过程将被忽略
// If we want to print small files info, we should load directory inodes
if (printSmallFiles) {
ImmutableList<Long> refIdList = null;
for (FileSummary.Section section : summary.getSectionsList()) {
if (SectionName.fromString(section.getName()) == SectionName.INODE_REFERENCE) {
in.getChannel().position(section.getOffset());
InputStream is =
FSImageUtil.wrapInputStreamForCompression(conf, summary
.getCodec(), new BufferedInputStream(new LimitInputStream(
in, section.getLength())));
// Load INodeReference so that all INodes can be processed.
// Snapshots are not handled and will just be ignored for now.
out.println("Loading inode references");
refIdList = FSImageLoader.loadINodeReferenceSection(is);
}
}
for (FileSummary.Section s : summary.getSectionsList()) {
if (SectionName.fromString(s.getName()) == SectionName.INODE) {
in.getChannel().position(s.getOffset());
InputStream is =
FSImageUtil.wrapInputStreamForCompression(conf, summary
.getCodec(), new BufferedInputStream(new LimitInputStream(
in, s.getLength())));
loadDirectoriesInINodeSection(is);
}
}
for (FileSummary.Section s : summary.getSectionsList()) {
if (SectionName.fromString(s.getName()) == SectionName.INODE_DIR) {
in.getChannel().position(s.getOffset());
InputStream is =
FSImageUtil.wrapInputStreamForCompression(conf, summary
.getCodec(), new BufferedInputStream(new LimitInputStream(
in, s.getLength())));
buildNamespace(is, refIdList);
}
}
}
...
}
}FileDistribution统计计数改造
统计计数的改造主要在run方法中,代码如下:
private void run(InputStream in) throws IOException {
INodeSection s = INodeSection.parseDelimitedFrom(in);
for (int i = 0; i < s.getNumInodes(); ++i) {
INodeSection.INode p = INodeSection.INode.parseDelimitedFrom(in);
if (p.getType() == INodeSection.INode.Type.FILE) {
...
// 判断是否需要输出小文件标识,并且是否为前2个最小区间内
if (printSmallFiles && (bucket == 1 || bucket == 0)) {
// 进行小文件计数
increaseSmallFilesCount(prefixStrs, p.getId(), p.getName()
.toStringUtf8());
}
} else if (p.getType() == INodeSection.INode.Type.DIRECTORY) {
++totalDirectories;
}
...
}
}这里再次进入increaseSmallFilesCount内部,
private void increaseSmallFilesCount(String[] prefixPaths, long nodeId,
String pathStr) {
int count = 0;
String parentPath = "";
// 对于小文件计数,我们只需要存储文件所对应的父目录即可
try {
parentPath = metadataMap.getParentPath(nodeId);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
boolean isMatch = false;
if (prefixPaths == null || prefixPaths.length == 0) {
isMatch = true;
} else {
// 进行路径匹配,只过滤出我们想要匹配的路径
for (String str : prefixPaths) {
if (str != null && str.length() > 0 && parentPath.startsWith(str)) {
isMatch = true;
break;
}
}
}
// Judge if the parentPath match the target prefixPath
if (!isMatch) {
return;
}
// 取出现有计数
if (!smallFilesMap.containsKey(parentPath)) {
count = 0;
} else {
count = smallFilesMap.get(parentPath);
}
// 更新计数
count++;
smallFilesMap.put(parentPath, count);
}在这里需要指出一点,在存放统计计数的时候,我们并不需要保存真实文件-计数这样的关系,因为那样结果记录会太多,而且文件基本上是不会重名的,这里采用了保存其父目录的策略.意为该目录下的小文件数有多少.
测试结果输出
下面是我在测试集群上的测试结果:
输入测试命令:
hdfs oiv -p FileDistribution -printSmallFiles -prefixPath /user -i inputfile -o outputfile测试输出结果:
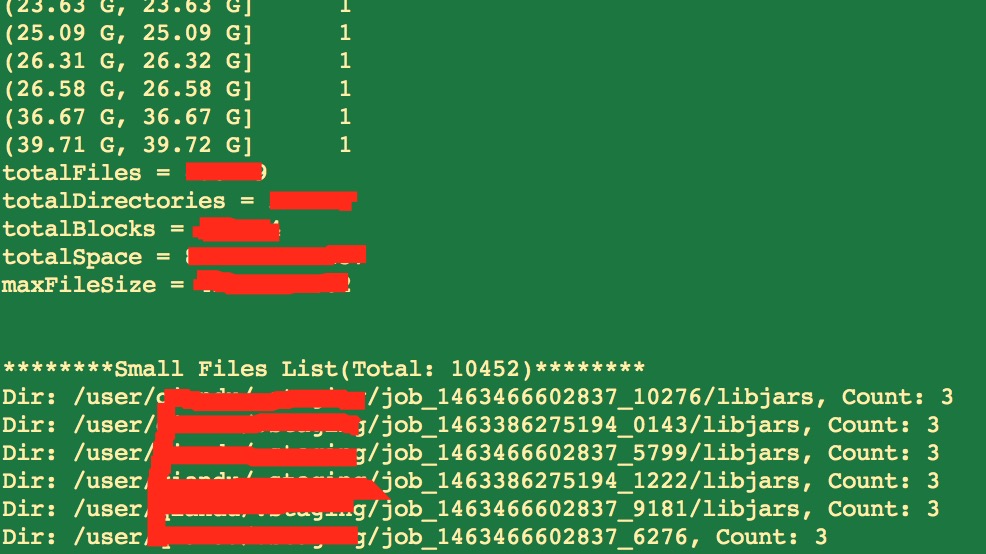
HDFS小文件分析功能的全部代码大家可以点击文章末尾的源码链接,上面有基于hadoop-2.7.1的patch以及完整的类文件,使用的时候可以自行git apply到自己的代码中.
对FileDistribution处理过程的优化
在实现小文件分析功能的过程中,我对FileDistribution的处理过程做了2点优化,
第一,解决FileDistribution统计文件分布时偶尔会出现的数组越界问题,这个越界异常将直接导致当前的解析进程中止,这个对于用户而言,体验是非常糟糕的.我通过添加了以下代码来避免发生这种异常:
private void run(InputStream in) throws IOException {
maxFileSize = Math.max(fileSize, maxFileSize);
totalSpace += fileSize * f.getReplication();
...
int bucket = fileSize > maxSize ? distribution.length - 1 : (int) Math
.ceil((double)fileSize / steps);
if (bucket >= distribution.length) {
bucket = distribution.length - 1;
out.println("Bucket index is out of index, fileSize: " + fileSize
+ ", step: " + steps);
}此异常一般发生于maxSize无法整除尽step值的时候,详细场景介绍可以查看我对此提交的issue HDFS-10691,同样我提供了相应的patch,已被社区接受.
第二,优化统计结果输出,增强其可读性.目前FileDistribution处理器的输出结果给人的第一感觉不是很好理解,如下:
Size NumFiles
0 3982
2097152 444827
4194304 877
6291456 587
8388608 216
10485760 315
12582912 150
14680064 215
16777216 108
18874368 84
...上面就显示了字节大小以及对应的计数值,我在改造的过程中,将其转化成了区间的表示形式,并将字节大小转化为可读的格式,如下:
Size NumFiles
(0, 0] 3937
(0, 2 M] 447105
(2 M, 4 M] 795
(4 M, 6 M] 530
(6 M, 8 M] 171
(8 M, 10 M] 305
(10 M, 12 M] 132
...对于用户而言,上面的展示方式相比原来的还是友好许多的.
相关链接
1.https://issues.apache.org/jira/browse/HDFS-10691
2.实现源码链接: https://github.com/linyiqun/open-source-patch/tree/master/hdfs/others/HDFS-OIV-PrintSmallFiles

