


记两次NameNode响应延时问题
前言
最近一两周,本人在维护公司内部集群的时候,遇到了一些性能问题,(可能这些问题以前也都存在,只是不容易被发现)表现出来的特征就是NameNode响应请求非常慢,然后导致各种超时,用户体验非常糟糕.因为本人目前使用的版本是2.7.1(社区最新发布版本2.7.2),应该算是非常新的版本了,在这个版本目前已经存在这个问题,那么在往前的一些版本中也肯定存在类似问题.下面是本人在最近集群运维过程中出现的2个NameNode响应延时的场景.相信能给其他Hadoop集群维护者带来帮助.
NameNode响应延时背景介绍
这里有必要交代一下NameNode响应延时的背景,因为如果你的集群规模算是比较小的话,可能你根本不会出现类似的问题,所以这里我要特别描述一下此背景下的NameNode的一些状态信息.也就是说,我下面将要提到的NameNode相应延时的问题,是基于什么背景下的呢?如下:
当NameNode维护文件数量过亿级别的时候.
没错,就是上面这个情况,3,4000w的文件数可能不会出现这样的问题.随着数据量规模的上涨,这个问题就会渐渐地浮现出来.那么为什么文件数量多会导致响应延时的问题呢?这其实是一个比较大的话题了,从大的层面来说是以下2点:
- NameNode大规模请求处理.NameNode所要维护的元数据规模过大,导致其负载高,一些大规模的文件查询/删除操作,容易使NameNode一下处理大量请求.
- NameNode的元数据同步更新时间加长.比如NameNode每次做checkpoint生成新fsimage会耗更多的时间,fsimage会很大,fsimage大了会导致每次SNN向ANN同步新镜像时要花更多的时间.这势必会影响ANN的正常请求相应.
当然了,具体的问题得具体地分析,下面是本文所要重点描述的2个异常问题.根本原因与上面提到的2大点还是有一些些的联系的.
异常场景一: HA模式下首节点为Standby导致响应延时
这个标题所描述的场景可能有人第一眼看过去不太理解,它的意思是这样的.我们一般配置HA模式的时候,首先定义一个nameservice,比如testservice,然后在这个service下面配2个nodeId,代表2个NameNode,一般我们都会配成nn1,nn2,如下,
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>一般我们会按照编号顺序,将nn1放在nn2的前面,然后以nn1作为ANN(Active NameNode),nn2作为SNN(Stand NameNode).但是现在提到的异常场景则恰好相反,nn1这时为SNN,而nn2才是ANN.然后问题就来了,NameNode出现了响应延时的问题.
问题追踪
后来我们在客户端通过更改nameservice下的nn1,nn2的顺序,使SNN代表的节点在前来模拟上述异常场景.然后执行hadoop fs -ls命令,随后我们在输出的debug日志中发现了如下的异常信息,
2016-08-04 22:19:51,297 DEBUG ipc.Client (Client.java:setupIOstreams(699)) - Connecting to /xx.xx.xx.xx:9000
2016-08-04 22:19:51,309 DEBUG ipc.Client (Client.java:run(969)) - IPC Client (840054516) connection to /xx.xx.xx.xx:9000 from data: starting, having connections 1
2016-08-04 22:19:51,311 DEBUG ipc.Client (Client.java:run(1032)) - IPC Client (840054516) connection to /xx.xx.xx.xx:9000 from data sending #0
2016-08-04 22:20:54,090 DEBUG ipc.Client (Client.java:receiveRpcResponse(1089)) - IPC Client (840054516) connection to /xx.xx.xx.xx:9000 from data got value #0
2016-08-04 22:20:54,095 INFO retry.RetryInvocationHandler (RetryInvocationHandler.java:invoke(140)) - Exception while invoking getFileInfo of class ClientNamenodeProtocolTranslatorPB over /xx.xx.xx.xx:9000. Trying to fail over immediately.
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category READ is not supported in state standby
at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:87)
at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.checkOperation(NameNode.java:1774)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOperation(FSNamesystem.java:1313)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getFileInfo(FSNamesystem.java:3856)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getFileInfo(NameNodeRpcServer.java:1008)上面所输出的Operation category READ is not supported in state standby这个异常其实很常见,就是我的RPC请求请求向了Standby NameNode,而SNN默认是不处理READ类型的请求的,而WRITE类型的请求则直接不被允许.第一次请求失败了,因为是HA机制嘛,所以自然而然地会去试一试第二个NN,这个时候就会有结果了.总的来说,本质的原因在于其间多请求了一次无效SNN导致响应变慢,当SNN处于忙碌状态或在gc的时候,这个响应会变得更加漫长.而首先请求到SNN的原因是因为SNN所代表的id靠前导致,而客户端发起请求的顺序是按照nameservice下的id顺序进行遍历的.所以这样看来,显然这不是一个合理的做法,我们马上能联想到的一个更好的办法:是否能让客户端每次智能地选择一个当前处于Active状态的NameNode,然后发起请求?这个做法看起来不错,但是不要忘了在这里获取哪个NN为Active状态也是需要发送请求获取的,所以这个做法并不是最好的.这里继续往下看,下面将要介绍一种更优的做法.
问题解决
首先声明此方案来源于Hadoop社区,并不是我的个人解决方案,fix版本在2.8.0.所以想要fix此bug的同学只能自行apply此patch到自己的版本中.OK,回到正题,说说社区中的这个解决方案.下面是这套方案的原理阐述:
RequestHedgingProxyProvider (which, for the first call, concurrently invokes all namenodes to determine the active one, and on subsequent requests, invokes the active namenode until a fail-over happens).
上面的大意是说,这里定义了一个新的ProxyProvider对象类,在客户端第一次请求的时候,会遍历所有的NameNode,决定哪一个为ANN,然后在后面的请求中都直接请求此ANN,直到下一次发生了failover切换了,再重新选择新的ANN.这个方案看起来的确会比之前的假设方案更好,也更合理.此jira编号为HDFS-7858:Improve HA Namenode Failover detection on the client.具体的代码原理,同学们可额外自行研究.
合入此patch之后,修改以下ProxyProvider相关配置项即可,输入hadoop fs -ls命令即可进行测试.
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.RequestHedgingProxyProvider</value>
</property>异常场景二: SNN加载editlog导致响应超时
第二个问题比第一个问题更加隐蔽一些,而且因为是发生在SNN上,所以对于外界用户的使用而言,是基本感觉不到的.但是作为集群的管理维护人员,还是能看到许多的异常情况的.主要有以下2大表象特征:
第一, SNN的50070页面上的Last Contact值经常在4,50以外,说明此时SNN与DN已经长时间没有联系了.
第二, Zkfc日志出现了45s超时的警告信息,从而导致频繁的切换此节点为SNN.如下图:

图1 zkfc连接超时
而且我们在zkfc的日志中,看到了连续的超时记录,我们排查了机器本身是否存在问题,而结果显示一切都是正常的,所以这基本上是HDFS自身内部的问题.
问题跟踪
SNN如果出现了响应慢的问题,尽管它不会直接对使用方造成影响,但是它会影响与ANN直接的通信交互操作.所以这也是一个不容小视的问题.
随后我们在SNN出现zkfc超时记录的时间点上打出了堆栈信息,以及debug信息.如下图:

图2 堆栈信息
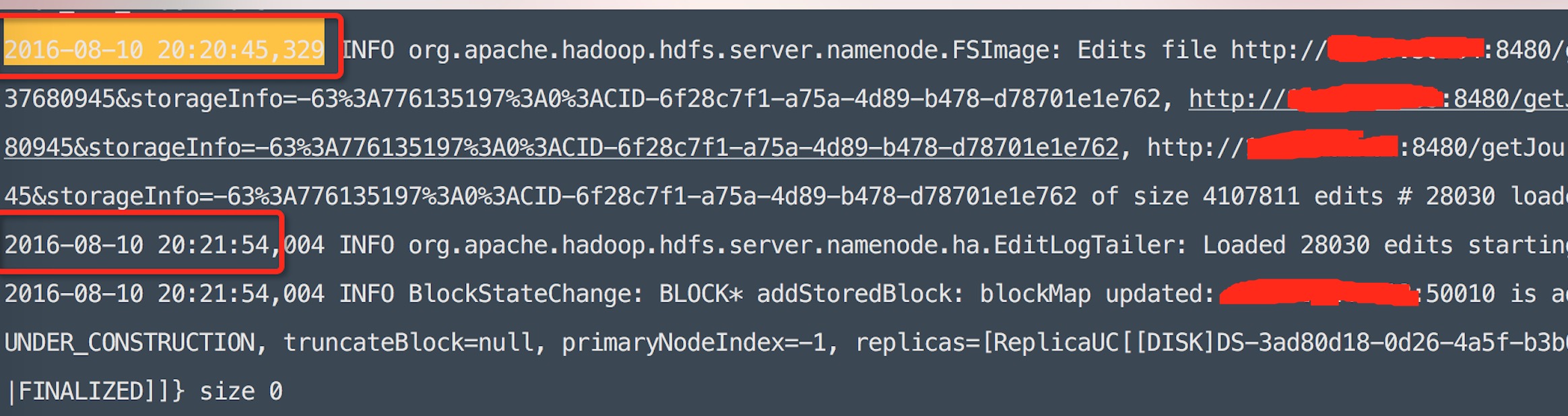
图3 Debug日志信息
综合上述2个信息点,我们大致可以得出2个关键结论:
- SNN超时是因为当时在执行load edit操作导致,从debug信息中,我们可以看到load完edit花了有1分多钟时间,而且中间没有任何别的输出记录.
- 在SNN执行loadEdit方法中,主要卡在了updateCountForQuota方法中,从图2中我们可以得出此信息.
可能有人对SNN为什么要执行load edit操作不太理解,这里简单提一下.这其实就是我们常常提到的HDFS QJM机制,ANN写editlog向各个JN,然后SNN通过网络读取JN上的editlog,并load到自己的内存中,以此保证2个NN的元数据是完全相同的.然后SNN做定期的checkpoint操作生成新的fsimage,然后传向ANN.
那么现在的问题是为什么会卡在updateCountForQuota方法中呢?这个我们得从源码中去找答案.
首先,我们找到FSImage的loadEdits方法,我们的确看到了updateCountForQuota的方法.
private long loadEdits(Iterable<EditLogInputStream> editStreams,
FSNamesystem target, StartupOption startOpt, MetaRecoveryContext recovery)
throws IOException {
LOG.debug("About to load edits:\n " + Joiner.on("\n ").join(editStreams));
StartupProgress prog = NameNode.getStartupProgress();
prog.beginPhase(Phase.LOADING_EDITS);
long prevLastAppliedTxId = lastAppliedTxId;
try {
...
} finally {
FSEditLog.closeAllStreams(editStreams);
// update the counts
updateCountForQuota(target.getBlockManager().getStoragePolicySuite(),
target.dir.rootDir);
}
prog.endPhase(Phase.LOADING_EDITS);
return lastAppliedTxId - prevLastAppliedTxId;
}继续进入updateCountForQuota方法:
static void updateCountForQuota(BlockStoragePolicySuite bsps,
INodeDirectory root) {
updateCountForQuotaRecursively(bsps, root.getStoragePolicyID(), root,
new QuotaCounts.Builder().build());
}
private static void updateCountForQuotaRecursively(BlockStoragePolicySuite bsps,
byte blockStoragePolicyId, INodeDirectory dir, QuotaCounts counts) {
final long parentNamespace = counts.getNameSpace();
final long parentStoragespace = counts.getStorageSpace();
final EnumCounters<StorageType> parentTypeSpaces = counts.getTypeSpaces();
dir.computeQuotaUsage4CurrentDirectory(bsps, blockStoragePolicyId, counts);
for (INode child : dir.getChildrenList(Snapshot.CURRENT_STATE_ID)) {
final byte childPolicyId = child.getStoragePolicyIDForQuota(blockStoragePolicyId);
if (child.isDirectory()) {
updateCountForQuotaRecursively(bsps, childPolicyId,
child.asDirectory(), counts);
} else {
// file or symlink: count here to reduce recursive calls.
child.computeQuotaUsage(bsps, childPolicyId, counts, false,
Snapshot.CURRENT_STATE_ID);
}
}
...
}我们看到上面的更新Quota计数方法并不是很高效,在于下面两点原因:
- 此方法是一个递归方法,以此遍历从根目录到所有的子目录.
- 面对这样一个操作量巨大的方法,此方法还是一个同步方法,并没有将其放入线程池中执行.
问题解决
OK,问题原因我们已经发现了,有什么好的办法可以解决此问题呢?
综合上述的情况,强大的Hadoop社区再次给出了完美的解决方案,以下为2个关键改进点:
第一,是否有必要每次load edit的时候更新一下Quota计数值,改为每次从SNN切换为ANN的时候更新一次,是否会更好?
第二,递归执行的updateCountForQuota是否能采用更高效的方法来执行,当集群数据量非常大的时候,随之而来的editlog也会很多.那SNN load edit的时间将会更长.
相应的jira编号为HDFS-6763:Initialize file system-wide quota once on transitioning to active.此patch直接将此方法从loadEdits方法中进行了移除,同时将updateCountForQuota方法放入ForkJoinPool中进行执行,还可以通过hdfs配置调整ForkJoinPool并行执行线程数.
总结
针对以上2个问题,我们最终都采用了社区的方案,将社区patch合入到了自身的2.7.1版本中进行解决,还好冲突并不是很多,目前看来效果还不错.本文不仅仅是分享最终问题的解决方案,还在于问题的如何发现到跟踪分析,最后到解决的整个过程.
参考资料
1.https://issues.apache.org/jira/browse/HDFS-7858
2.https://issues.apache.org/jira/browse/HDFS-6763

