


NameNode热迁移方案
方案目标
将现有NameNode迁移到新的节点上,期间保证集群对外提供服务.
方案背景
随着集群数据量和规模的扩增,需要将NameNode迁移到性能更优的机器上,以此提高NameNode的请求处理效率.
传统方案: 冷迁移
具体步骤
传统方案的做法比较简单,主要步骤如下:
- 1.停止集群服务,关闭NameNode,DataNode.
- 2.将NameNode元数据拷贝到目标新的机器上.
- 3.在新机器上安装好hadoop客户端,并更新集群中所有的hdfs- site配置,将新的NameNode ip指向新的节点.
- 4.重新启动集群.
传统方案的不足
传统方案在操作上是比较容易执行的,但是它唯一的不足之处在于需要集群对外停止服务.如果集群使用方众多,这样的做法显然不是一个最佳的方案.简单用一句话来形容这种做法:简单了自己,麻烦了他人.所以更好的做法应该是将麻烦留给自己,尽可能对外界不造成影响.
NameNode热迁移操作
当前节点:旧nn1:active; 旧nn2:standby; 新nn1; 新nn2
1.关闭 旧nn2的 namenode服务.
cd $HADOOP_HOME/sbin/; ./hadoop-daemon.sh stop namenode2.将旧nn2上面的元数据目录 ${dfs.namenode.name.dir}同步到新nn1节点的同样目录下.
3.修改旧nn2上的hdfs-site.xml 配置,新nn1 ip地址加入进去.
4.启动旧nn2的namenode服务.
./hadoop-daemon.sh start namenode5.关闭旧nn1的namenode和zkfc服务(关闭旧nn1会触发一次failover切换,将旧nn2切为active). 然后将旧nn1上的元数据同步到新nn2的节点上.
./hadoop-daemon.sh stop zkfc6.重启旧nn2上的zkfc进程,修改hdfs-site.xml 配置文件,同步到 datanode和新nn1机器上
7.启动新的nn1上面的namenode和zkfc服务(等待datanode连接).
8.启动所有datanode机器.
9.关闭旧nn2上面namenode和zkfc服务(关闭旧nn2会触发failover切换,使新nn1变为active).
10.等待新nn1上的namenode服务变成active,同时关闭其 zkfc服务.
11.修改hdfs-site.xml 配置文件,加入新nn2地址.
12.同步hdfs-site.xml 文件到所有 datanode机器和新nn1,新nn2.
13.启动新nn1上的zkfc服务.
14.启动新nn2上的namenode和zkfc服务.
15.重新启动所有datanode服务.
操作步骤图
注:箭头表示对应颜色节点上的zkfc进程所维护的HA关系.

图1 初始状态
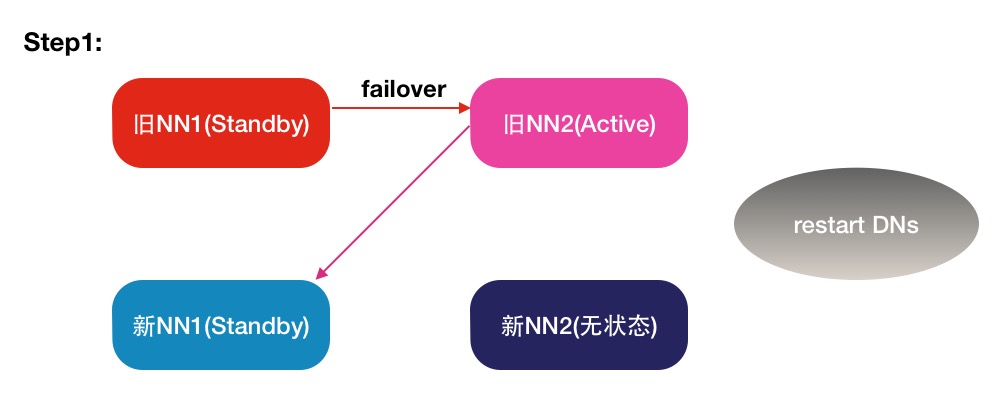
图2 步骤1
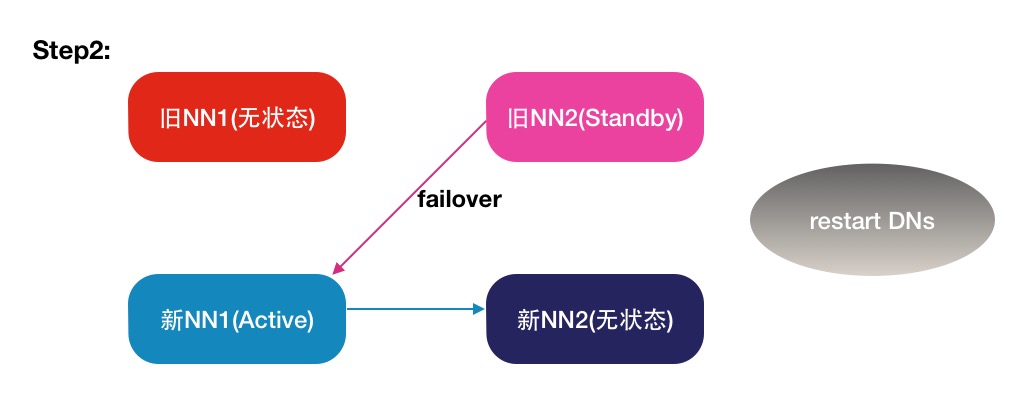
图3 步骤2
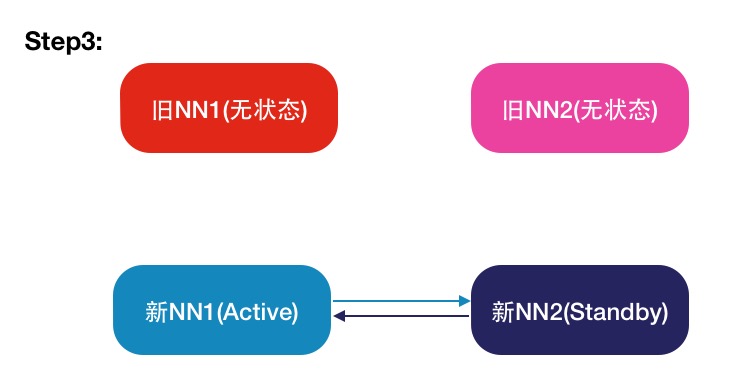
图4 步骤3
方案总结
上述方案之所以可行,关键在于其灵活地利用了HDFS的HA机制以及zkfc的自动切换的原理.里面的操作原理大家可以反复阅读,体会其中的巧妙之处.下面来谈谈本人在操作此方案时遇到的3个问题:
- 1.HA关系变化时nn id的添加.因为在此过程中会涉及多次HA关系的变更,在其中需要注意nn id的设置,避免nn id出现重复的情况.
- 2.zkfc进程启动顺序出错导致Active/Stanby切换失败.这是很容易出错的点.zkfc只有在维护2个相同的NameNode的情况下,才能实现failover,这句话什么意思呢?比如说zkfc1进程在HA模式的nn1,nn2的nn2节点上启动,而另一个zkfc2进程却在HA模式的nn2,新nn1的新nn1上启动,则这个时候,如果停止nn2节点,zkfc将不会切换active状态到新nn1.
- 3.NameNode迁移导致对外服务地址的变更.尽管是集群的热迁移,但是迁移的过程中难免还是发生了NameNode的IP地址的变化,这个时候外部的一些客户端程序必然会出现异常,这个时候比较好的做法是用固定域名代替ip.以后不管NameNode Ip怎么变,域名永远都是同一个.

