
HDFS升级域:Upgrade Domain
前言
在前面的文章HDFS的滚动升级: Rolling Upgrade中,介绍了HDFS滚动升级相关的内容。在HDFS滚动升级的过程中,会涉及到DataNode重启服务的操作。对于这里的DataNode服务重启的操作,其实是有一定讲究的。比如说,我们批量重启部分节点的时候,不能同时重启过多的节点,否则会造成部分块副本所在节点都处于正在重启的机器中,导致数据不可用的情况发生。如果我们想依然保证集群数据的可用性,可能想到的最简单的办法就是逐个重启。但是这又会有一个问题:如果集群规模达到1w个节点,假设集群每个DataNode重启服务大约花2~3分钟,那么重启一次集群估计要花1周的时间了。所以本文将要关注的一个主题是我们如何保证集群重启服务时同时保证高效性与数据可用性。对于此问题,HDFS引入了Upgrade Domain(升级域)的概念。在下文中,将会对此功能进行详细的介绍,包括它的概念的定义,核心原理以及部分关键代码的实现。
HDFS Upgrade Domain概念
HDFS Upgrade Domain本质上来理解指的是HDFS对各个同一个块的各个副本进行了逻辑上的划分,使之位于不同的域下。然后进行升级操作的时候,按照各个域依次进行重启服务即可。因为块的各个副本分别位于不同的域下,就不会存在数据不可用的情况了。升级域对副本块的逻辑划分效果如图1-1所示。
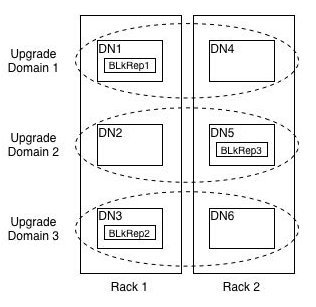
图 1-1 HDFS升级域
从图1-1中可以看出,升级域与机架类似,都是将DataNode进行划分的一个维度,唯一的不同点,是机架位置信息是物理上的,而升级域则表现在逻辑空间上的。DataNode所在机架我们可以用机架名称来表示,那么升级域我们用什么名称表示呢,答案如下:
HDFS节点的升级域可以采用指定升级域的方式,否则用DataNodeId作为当前DataNode的升级域(在这种情况下,每个DataNode的升级域都不相同)。
指定升级域的方式,可以写相应脚本进行获取,与机架感知时的获取脚本完全类似。节点->机架位置->升级域关系映射如图1-2所示。

图 1-2 DataNode节点映射关系
HDFS Upgrade Domain核心实现点
HDFS升级域的引入对于现有HDFS最为核心的影响是副本块的放置选择。因此在此功能中,我们将会引入一种新的副本放置策略:BlockPlacementPolicyWithUpgradeDomain。在此放置策略类中,我们将会多考虑到升级域的影响,保证块的各个副本位于不同的升级域下。
除了以上这个核心需要点外,我们还需要实现周边相关的操作。
第一点,每个块放置策略类会有自身的待删除多余副本的选择逻辑,同样在BlockPlacementPolicyWithUpgradeDomain类中,我们也需要对此进行实现。
第二点,Balancer数据平衡工具在移动块的时候,依然要遵循当前放置策略的原则。目前Balancer在数据平衡时保持的一个原则是保证各个机架内block的数量不变。这个原则表明了它更多的使用场合在于同一机架内的数据平衡。
HDFS Upgrade Domain关键代码实现
根据上节提到的关键实现点,在本节中我们对应核心代码的分析。首先,这里的主要逻辑都是实现在新的放置策略类BlockPlacementPolicyWithUpgradeDomain中的。在这里,我们要重载isGoodDatanode和pickupReplicaSet方法。
升级域放置策略下的放置位置选择
首先是isGoodDatanode方法,为了沿用原本存储节点的选择策略,我们只需额外添加升级域的筛选判断即可,代码如下。
protected boolean isGoodDatanode(DatanodeDescriptor node,
int maxTargetPerRack, boolean considerLoad,
List<DatanodeStorageInfo> results, boolean avoidStaleNodes) {
// 沿用父逻辑来判断当前选择的节点是否为一个好的目标节点
boolean isGoodTarget = super.isGoodDatanode(node,
maxTargetPerRack, considerLoad, results, avoidStaleNodes);
// 如果满足原始逻辑,继续判断升级域的条件,保证当前选择的各个副本的目标存储位置位于不同的升级域下
if (isGoodTarget) {
// 如果当前已选择完毕的节点位置大于0并且小于升级域个数时
if (results.size() > 0 && results.size() < upgradeDomainFactor) {
// 取出当前升级域的去重集合
Set<String> upgradeDomains = getUpgradeDomains(results);
// 如果当前选择的节点已经包含在这个集合中,表明是重复的升级域,则此节点不是一个适合的节点,设置为false
if (upgradeDomains.contains(node.getUpgradeDomain())) {
isGoodTarget = false;
}
}
}
return isGoodTarget;
}这里的upgradeDomainFactor变量时可配置的,默认值为副本系数,也就是说理论情况下,各个副本有对应各自的升级域。
升级域放置策略下的多余副本块的选择
放置策略下的多余副本块的选择过程可以详细阅读本人之前的一篇文章:HDFS如何检测并删除多余副本块。在这篇文章中,有详细的多余副本块的选出以及删除逻辑。而在本小节,我们将主要关注升级域放置策略下的多余副本快的选出逻辑这块,代码如下:
protected Collection<DatanodeStorageInfo> pickupReplicaSet(
Collection<DatanodeStorageInfo> moreThanOne,
Collection<DatanodeStorageInfo> exactlyOne,
Map<String, List<DatanodeStorageInfo>> rackMap) {
// 首先将所有多余的副本位置信息合并
Collection<DatanodeStorageInfo> all = combine(moreThanOne, exactlyOne);
// 在里面选出属于同个升级域的位置信息
List<DatanodeStorageInfo> shareUDSet = getShareUDSet(
getUpgradeDomainMap(all));
// 新建同升级域、同机架的节点位置信息列表
List<DatanodeStorageInfo> shareRackAndUDSet = new ArrayList<>();
// 如果同升级域的列表为空,代表以上节点位置都为独立的升级域,则退一步,沿用父逻辑
if (shareUDSet.size() == 0) {
return super.pickupReplicaSet(moreThanOne, exactlyOne, rackMap);
} else if (moreThanOne != null) {
// 否则遍历共享升级域的列表,用moreThanOne来判断是否此升级域
for (DatanodeStorageInfo storage : shareUDSet) {
// 如果包含,则表明此节点位置既属于同升级域,又属于同一机架下,
// 因为moreThanOne已经代表的意思是当前机架下的副本数大于1个的位置集合
if (moreThanOne.contains(storage)) {
shareRackAndUDSet.add(storage);
}
}
}
// 如果同机架,同升级域对象不为空,则返回此对象,否则返回同升级域的集合
return (shareRackAndUDSet.size() > 0) ? shareRackAndUDSet : shareUDSet;
}归纳一下上面的选出过程:
1)首先选出属于同个升级域的位置信息。
2)如果同升级域的列表信息为空,代表所有节点位置都为独立的升级域,则退一步,沿用父类的选出逻辑。
3)否则在此条件下选出同机架的节点信息。
4)如果同机架,同升级域对象不为空,则返回此对象,否则返回同升级域的集合。
从上面的选出逻辑中我们可以看出,它的一个核心原则是尽可能地让具有高重复属性的副本块优先移除。然后这些副本块选出来了之后,会按照心跳更新时间,磁盘剩余空间再进行删除顺序的选择。
Balancer过程的局部改造
Blancer过程的局部改造在于移动数据块时的放置策略的判断。原始逻辑如下,是一个写死的的判断原则:
private boolean isGoodBlockCandidate(StorageGroup source, StorageGroup target,
StorageType targetStorageType, DBlock block) {
...
// 原始逻辑固定地按照机架属性来判断
if (cluster.isNodeGroupAware()
&& isOnSameNodeGroupWithReplicas(source, target, block)) {
return false;
}
if (reduceNumOfRacks(source, target, block)) {
return false;
}
return true;
}现在优化为以下逻辑:
private boolean isGoodBlockCandidate(StorageGroup source, StorageGroup target,
StorageType targetStorageType, DBlock block) {
...
// 原逻辑此处被更改为按照当前放置策略的逻辑来判断
if (!isGoodBlockCandidateForPlacementPolicy(source, target, block)) {
return false;
}
return true;
}
isGoodBlockCandidateForPlacementPolicy方法如下:
private boolean isGoodBlockCandidateForPlacementPolicy(StorageGroup source,
StorageGroup target, DBlock block) {
// 新建空副本位置信息列表
List<DatanodeInfo> datanodeInfos = new ArrayList<>();
synchronized (block) {
// 遍历当前块的副本存储位置信息,加入到位置信息列表中
for (StorageGroup loc : block.locations) {
datanodeInfos.add(loc.getDatanodeInfo());
}
datanodeInfos.add(target.getDatanodeInfo());
}
// 将当前块的副本位置信息传入放置策略类中,进行是否可移动的判断
return placementPolicies.getPolicy(false).isMovable(
datanodeInfos, source.getDatanodeInfo(), target.getDatanodeInfo());
}当然上述代码的改动,需要BlockPlacementPolicy底层类新加一个isMovable方法,然后其实现子类都需实现整个方法。在此本人进行了省略,读者可自行阅读相关放置策略类的源码进行进一步的学习。
BlockPlacementPolicyWithUpgradeDomain策略类的使用
升级域策略类的使用需要通过配置下面的配置项进行开启。
<property>
<name>dfs.block.replicator.classname</name>
<value>org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyWithUpgradeDomain</value>
<description>
Class representing block placement policy for non-striped files.
</description>
</property>那么现在有个问题来了,原本使用的是默认的放置策略类了,现在使用此策略类能达到效果吗?没错,这里的确会有这样的一个问题,官方设计文档提出的解决办法如下:
1)写好脚本,将集群中的DataNode都指定好对应的升级域中。
2)启用升级域策略类,此时新创建的块将会满足此策略类的放置规则。
3)老的块通过HDFS的mover工具进行再同步,期间会进行副本块的迁移。
4)如果上述过程中出现问题了,可以使用默认副本策略进行退回。
升级域策略类启用完毕之后,我们在下一次的升级操作或是集群服务重启的时候就可以做到按照升级域来做。这样的话,不管集群是1000个节点,还是10000个节点,都将不会导致特别耗时的影响,而不是必须按照一个个节点逐个重启的方式。此功能属性目前暂未发布,预计发布版本2.9,3.0,详见相关JIRAHDFS-7541(Upgrade Domains in HDFS)。

