HDFS智能化存储管理:Smart Storage Management
前言
前段时间无意间看了一则Apache Big Data Europe 2016的回顾,感觉挺有意思的。因为本人一直focus在HDFS这个模块上,所以我特意关注了在此次大会中提到的一个issue:HDFS-7343(HDFS smart storage management)。后来本人花了一定的时间对此issue进行了学习,总结下来一句话:这个issue可以说是一个非常大胆而又具有新意的想法。它的目标是解决困扰HDFS使用者已久的一个问题:数据如何存储管理。而在HDFS-7343中,引入了一种“智能化存储”的概念,帮助用户来管理它所拥有的数据。
HDFS目前的数据管理模式
在介绍HDFS-7343中提出的“智能化存储”概念之前,需要了解现有的一个大背景:HDFS现有的数据管理模式。和最早时间段之前相比,现在的HDFS应该来说还是发展地很快的,比如说在最近几年,HDFS能够支持缓存存储(HDFS Cache),异构存储(HSM),还有EC。这些多元的存储方式能够让用户进行更加灵活的选择,当用户面对不同的应用场景时。
对于用户而言,这些数据存储方式的确是有用的,但是它们有一个共同的问题:需要外界主动触发。换句话说,当用户A发现B文件被频繁的访问,于是它需要主动将B文件进行cache,或是将它设置成Hot的存储策略。在这里HDFS是否能做到更加智能化一些,不需要用户的介入呢?因为有些不了解HDFS的用户可能根本不知道有这些特性。如果HDFS能真正做到对此的智能化管理,那无疑这将会是一个新的创举。
HDFS智能化存储管理概述
HDFS智能化存储管理全称叫做Smart Storage Management,简称SSM。凡是要做到智能化、自动化的事情,往往不会特别容易,更可况是在异常复杂的HDFS之内。要想做到智能化的存储管理,首先它的核心原理应该如下:
根据文件历史访问情况数据,例如最近一次访问时间等,作为数据存储的一个评判标准。
上面提到的一点只是我们大家会直接联想到的,如果说要真正做文件存储方式的预测分析,可能还需要结合文件的大小、属性信息等更多因素的信息,然后做一个综合所有因素的一个预测。
SSM是一个智能化管理的机制,但是它是需要一个”智能引擎”,而这个引擎的规则制订者则是来自外界的用户。什么意思呢?因为我们都知道机器是死的,人是活的,之所以它具有智能特性,是需要人们给它设定很多规则,然后它根据这些规则做智能处理的,这就好比一个机器人,你需要给它输入很多命令,它才会执行每一步操作。
HDFS 智能化存储管理方案的设计
在HDFS-7343中,对此方案进行了详细讲述,同时有完整的设计文档。在此,本人进行一个简单的阐述。
SSM服务
考虑到SSM本身将会是一个比较“重”的服务,设计者对其进行了拆分的设计,也就是他不打算把这块内容放在NameNode上来做,而是启单独的服务,在此我们姑且叫做SSM服务。一句话来概括SSM服务的作用:
SSM只对外提供执行操作事件,不做真正的数据管理的动作,这些动作依然由NameNode来完成。
也就是说,SSM只做分析和给出分析结果两件事。一个简单的处理流程如图1-1所示。
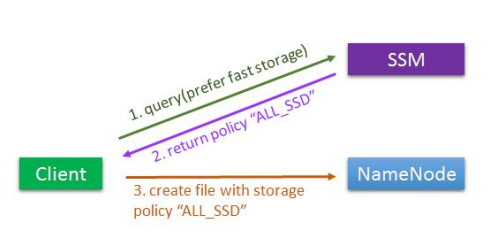
图 1-1 SSM服务简单执行过程
SSM整体架构
了解了SSM单独服务作用之后,我们来看看HDFS SSM的整体结构设计,设计者到底打算如何将此服务应用到HDFS上去呢?总的架构设计如图1-2所示。
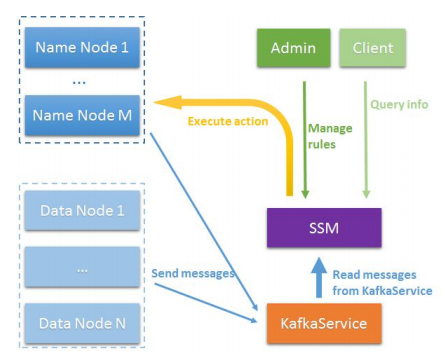
图 1-2 HDFS SSM架构设计
上图的架构设计精准地展示了目前HDFS SSM的一个设计思想。对照图1-2,以下是对HDFS SSM架构设计的两个要点描述:
- 这里引入了Kafaka服务kafkaService来做信息的收集,这类信息就是前面提到的一些文件历史访问等这类的信息。我们可以看到,图中显示的信息收集模式是一种push的模式。由于DataNode,NameNode主动推向Kafka的服务。可能有人会提出质疑,这不是会加重DataNode,NameNode的压力吗,这点的确是一个弊端。但是换个角度思考,如果让采用pull的方式,在集群规模很大的情况下,要逐个遍历节点去获取信息,恐怕也不是一个很高效的方式吧。所以在这里,会有一个权衡。Kafaka收集的信息是要给SSM服务提供数据进行分析的,所以这里会有从KafkaService到SSM的箭头。
- 对于SSM的运行,首先是需要集群管理员输入一些规则,然后SMM经过分析最后把要执行的action动作发给NameNode来执行。下面我们继续进入SSM到NameNode的处理过程,在这个过程中,其实也需要做很多事情。
SSM内部运行过程
从上面的讲述中,我们可以看到SSM服务对于输入“规则”的依赖性,就像一个人工智能背后离不开一个优秀的算法。所以我们可以预见到在SSM内部,会定义一种的新的“规则语言”以及相应的“规则解析器”。外界服务向SSM进行服务查询的时候,会进行规则的判断执行,而这些规则判断执行的时候需要依赖Kafka服务中收集的历史数据,然后给出反馈命令。综上逻辑,SSM内部的执行过程如图1-3所示。
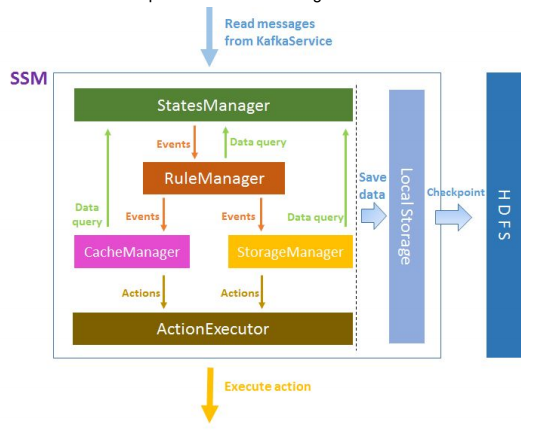
图 1-3 SSM内部结构
图1-3的右侧保存数据的操作指的是保存像“规则”之类的数据,等下次重启集群时还能进行恢复。
SSM的实现难点
这套智能化的存储管理方案看下来的确是一个非常高大上的功能,但是同样本人认为其中将会遇到的困难点也应该不少。比如说下面这个争议点(部分观点来自社区的讨论):
如果仅仅凭借文件的历史访问数据情况或者说仅仅从HDFS层面,就来决定文件的存储类型,是否太过片面?是否能结合YARN层面的应用信息来做决定,是否会是一个更优的选择?因为用户提交执行的应用,往往会带有类似的执行特征。一旦存储策略分析的不准确,到时可能会频繁造成大量数据不必要的迁移,反而起到负面作用。
最后总的来说,个人还是很期待HDFS SSM,这是一个很有想法的feature,对于初学HDFS的用户而言将会是一个很大的帮助。
参考资料
[1].HDFS smart storage management
[2].HDFS-Smart-Storage-Management.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号