
分布式数据库学习--分布式数据库的设计
前言
分布式系计算作为一个比较复杂的课题,需要读者具备良好的计算机基础知识。有了这些理论知识的支持,我们才能更好的阅读,学习当前各个主流的分布式系统以及框架。笔者最近饶有兴趣的开始学习起了分布式数据库的知识。因为笔者主要研究的方向是HDFS,也就是分布式存储这块,所以学习了解这块内容对笔者来说能在未来更好地贡献于HDFS。OK,转回正题,最近笔者学习了分布式数据库的设计问题,换句话说,也就是分布式数据库在初始设计的时候要考虑哪些因素。考虑到了这些内容之后,我们将会对分布式数据库会有一个大概的了解。
分布式数据库的起源
分布式数据库的起源要归结于当今数据量规模的不断增长以及业务使用场景的日益复杂化。当面对海量数据规模的情况下,传统单一式的、集中式管理的数据库逐渐暴露出许多缺陷,它渐渐地会达到一个瓶颈点,于是我们有了分布式数据库的概念。分布式数据库,顾名思义,它的数据是分散地存储于各个节点之上。如果数据量规模变大,它还能灵活地进行扩展。但是分布式数据库的一个比较大的问题是数据的统一管理。因为数据是分散在各地的(它不像集中式管理数据库那样可以方便地在某一个中心管理器上做统一管理),所以我们会遇到很多挑战,比如数据的一致性问题、数据的容错或者是元数据管理问题等等。
分布式数据库的设计
本文笔者打算简单来聊聊分布式数据库在初始设计的时候需要考虑的几点问题。
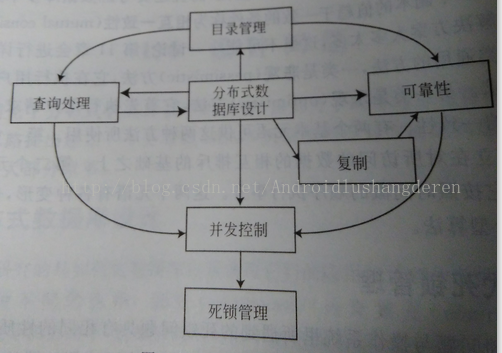
分布式目录管理
分布式目录管理在某种程度上来说可以理解为分布式情况下元数据的管理。因为数据在分散存储的情况下,各个节点存储的数据只是全局数据的一部分。基于此条件下,各个节点最能直接看到的应该是它本地的数据目录信息。所以这里要解决的一个问题是如何让各个节点感知到其它数据信息的存在,包括数据的位置、大小和副本情况等等。只有了解了这些信息后,在单一节点的查询才能访问到非本地节点的数据。可能我们会说,一种简单的做法是将全局元数据信息复制在每个节点上。这种做法的确能解决前面我们提到的问题,但是在操作上还是稍显简单,暴力。首先这种做法开销一定是不小的,而且是否有必要维护庞大的目录树信息在每个节点上呢,特别是当元数据信息急剧增长的情况下时。在HDFS中,采用的做法是一种中心管理的策略,也就是NameNode在做的事情。为了避免NameNode出现单点瓶颈问题,HDFS引入了NameNode Federation的机制。感兴趣的同学可以阅读笔者之前的一篇文章:HDFS Federation机制。这里就不展开过多的介绍了。
分布式数据库的并发控制
分布式数据库在运行的时候,往往会伴随着大量并发执行的事务操作。如果管理不当,就会造成数据执行乱序以及数据出错的情况。这里我们需要考虑并发控制的内容,多线程中的并发控制技巧在这里就派上用场了。目前主流的并发控制方法有这么两类:1.悲观的方法(加锁)。2.乐观的方法(不加锁)。第一种,悲观的方法即加锁的方式,这个我们再日常工作中也会用到很多,想必大家已经有所了解。第二类方式,乐观锁(不加锁)的方式,这种方式的一般做法是通过加时间戳的方式,通过时间戳的先后顺序来执行事务。当然了,在并发控制的情况可能会出现死锁问题。这需要我们在程序实现的时候考虑是否会导致死锁的情况。
分布式数据库的可靠性保障
分布式数据库中的数据在大量分散存储的情况下,是有很大概率可能出现因为机器老化等非软件层面原因导致的某些局部数据不可用的情况。一旦数据出现不可用的情况,这意味着用户无法读取到需要的目标数据。所以这里会引入Replication(副本)的概念,很显然,我们不会把所有的replication都放到同一个节点上,这样会失去副本本身存在的意义。副本在很多成熟的分布式存储系统中都有所应用,比如说非常经典的HDFS三副本策略。当出现个别副本数据出现错误的情况时,系统能够根据其它可用的副本进行快速地恢复。正如一枚硬币有着正反面的区分,副本在带来系统可用性的好处,同时会带来一定的问题。比如说,副本之间的数据一致性保证,还有一点不可忽视的是多副本造成的存储空间使用加倍的问题。
以上是笔者简单想到的几点,本文算是笔者的一个小结,部分观点来自于《分布式数据库系统原理》第一章,下面是章节中与此相关的结构图。
参考资料
[1].分布式数据库系统原理.第一章

