
聊聊副本放置方式对副本持久可用性的影响
前言
在过去的很多时间内,人们在分布式数据存储领域研究关注的一点往往是数据的一致性。因为当数据以多副本的形式分散地存储在集群中,我们当然是要确保每份副本上的数据确保一致,然后我们才能读到最新的数据。所以在另一方面,也就是数据的放置位置选择方面就会缺少相对应的关注度。其实在这块领域也是有许多东西可以值得研究的,比如说副本位置的存放策略在一定程度上会影响其未来的可用性,换个更通俗易懂的说法,就是我的副本位置如何放置,来尽可能减少未来时间内由于节点崩溃导致副本重新复制的风险和成本。笔者最近阅读了相关的文章,打算来简单聊聊这块内容。
HDFS内的副本放置策略
在深入了解这块内容之前,我们不妨先了解一个类似的例子:HDFS内的副本放置。在HDFS内部,对于副本位置的选择是有一定的策略讲究的,首先它并不是全盘的随机选择。而是有一定的策略位置选择,比如说默认的三副本放机制,三副本存放的特殊位置关系可以防止部分节点由于宕机等特殊情况造成副本临时不可用的情况。此块详细内容可以点击之前笔者的相关文章:HDFS副本放置策略。现在我们从一个宏观的角度来看HDFS的副本放置机制,归纳起来有下面的特点:
它是一个集中管理式的,都由NameNode来控制选择,因为NameNode自身内部维护了所有DataNode的位置信息。所以无需DataNode相互之间确认位置关系。
这种中心管理式的方式优劣势都很明显,优势就是管理起来方便,简单,劣势就是会存在单点瓶颈的问题,未来集群规模进一步扩增,性能瓶颈可能就会上来了。
OK ,前面这些都是铺垫内容,下面就要引出本文所要讲述的主要内容了。
SPLAD系统模型
笔者最近学习了一篇相关的论文:SPLAD: scattering and placing data replicas to enhance long-term durability.在这篇论文中,作者提出了一个叫SPLAD系统模型的概念。什么意思呢?就是说在这个模型内,我们可以微调副本块对于存储节点的映射关系以此来加强它的持久性。以下是笔者摘取的部分核心内容。
元数据管理模型
首先我们来看它的元数据管理模型,元数据的管理指的是在此系统中,它是如何管理副本以及其存储节点相应的数据信息的。在SPLAD模型内,它是采用了类似DHT(分布式哈希表)的方式,它会为每个副本块分配一个唯一ID,同样的每个节点也会有这样的一个ID。然后我们定义这样的一个概念:
如果一个节点的ID最接近某个块的ID,则称此节点为此块的根(root)。
可以这么说,这个根节点是对它所存储的块全权负责的,主要做下面几件事情:
- 定期检查此块的其它副本是否都存在,其它存放此块的节点但不是根节点的节点称为存储者(storer)。
- 当根节点发现某个storer失败了,就要从它能选择的范围内选择一个新的节点来替换它。
而相反的存储者干的事情则是在根节点失败的时候,在存储者之间选择一个新的领导者作为根节点。
下图是对上述例子的一个直观展示。
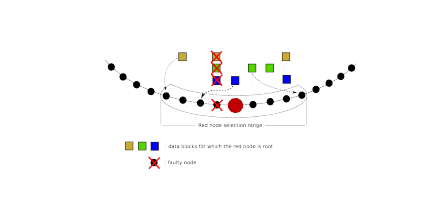
我们可以看到,图中大红的节点是蓝色副本的根节点,当它发现它左侧的小红节点失败了,它上面的3个副本块(黄、绿、蓝副本)被迫转移。此时大红节点就在它所能够选择的节点范围内(也就是虚线框所示的节点范围)选择一个节点,最终它选择了它左侧数第2个节点位置。
从上面的图线中,我们还能得到以下一些关键信息。
- 所有的节点、副本在逻辑上被组织成了一个环状的结构。
- 每个节点内部会维护一定数量节点的位置信息,这个可以通过路由层面来控制。
- 显然这种元数据管理方式并不是一种中心管理式的。
目标节点的选择
下面我们来看第二块比较有意思的内容:目标节点的选择。在SPLAD系统模型的论文中,提到了以下3类主流的节点位置选择算法。
1.随机位置选择。这是一种最简单也是最直接的做法。基于前面根节点,存储节点的概念,这种方法就是根节点在它能选择的节点范围内随机挑选一个节点进行副本数据的存储。这种做法一个很大的缺点是没有考虑节点本身的负载情况,这会导致越来越多的数据被分配到老的节点中,而越新上的节点数据就越少,最终会导致集群内数据的严重不均衡情况。
2.考虑节点负载情况的选择。这种做法就是专门为了解决第一种随机算法导致的数据不均衡的问题的。此选择策略是每次选出它所能选择的节点范围内空间使用率最低的一个节点。此算法看似完美,但是为此需要维护所有的可选节点的相关信息,而且还需要是尽可能时时更新的。这样一来会给根节点带来一定的压力。
3.两阶段随机选择算法。这种做法结合了以上2种策略选择的特点,在一定程度上能够达到相对最优的选择效果。这个算法的步骤如下:
- 1).首先从可选则的节点范围内随机选择2个节点,取名为节点A和节点B。
- 2).比较节点A和节点B,选取其中空间使用率较小的一个节点为目标节点。
在选举过程中,根节点并不需要保存所有的节点信息,只有在需要的时候进行节点信息的查询确认即可。当然了,上面子步骤1中的随机节点选取个数并不一定非得是2个,3个,4个其实也是可以的,如果选择的数量达到了全部的节点,此策略就完全等价于第二种选择策略了。
上面的提到的两阶段随机选择算法在HDFS内部其实也有用到,叫做AvailableSpaceBlockPlacementPolicy,依据的原理就是上面介绍的,感兴趣的同学可以下载最新的hadoop trunk分支的代码进行学习。
节点负载对于数据损坏率的影响
最后我们来看看外界因素对于数据块损坏率的影响,这里以节点负载情况为一个参考指标。从往常的理解上来说,节点负载越高,那么节点出错的可能性就会越大,也就是上面数据损坏的情况概率就会越高。从逻辑上来讲,这个肯定是没有问题的。但这2者是不是线性的关系呢?SPLAD的研究论文告诉我们,答案不是这样的。实际的关系演变如下图所示。
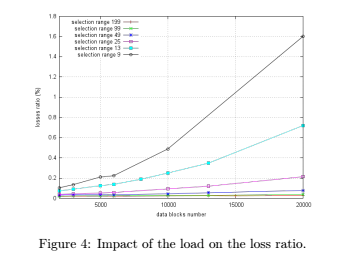
上图中横坐标表示的i节点存储的数据块数,当节点存储的数据块越来越多(也就是负载越来越高)的时候,数据的损坏率是以近似指数级的方式增长的。
其实从上图我们可以看到,节点选取范围也会影响副本数据的损坏率。为什么这也会有影响呢?当可选范围的节点数变多的时候,意味着节点所要维护这些节点的信息变多,这会加大根节点的负载的。
参考资料
[1].SPLAD: scattering and placing data replicas to enhance long-term durability,https://hal.inria.fr/hal-00988374/document

